مثال (۲) : بهبود کارایی الگوریتم سیستم ایمنی مصنوعی در مسائل بهینهسازی
برخی مسائل وجود دارند که به دلیل گستردگی و پیچیدگی بیش از حد فضای حالت مساله ، دستیابی به یک پاسخ بهینه در مدت زمان معقول و با استفاده از ابزارهای متعارف امکان پذیر نمیباشد. در این مثال الگوریتم های سبستم ایمنی به عنوان متاهیوریستیک استفاده شده است. همانند متاهیوریستیکهای رایج الگوریتم سیستم ایمنی در گامهای نخست ، ناحیههایی از فضای حالت مساله که بهینههای محلی و سرارسری را در بر می گیرند را شناسایی نموده و در ادامه مسیر با همگرا شدن به بهینههای سراسری ، روند بهینهسازی متوقف می گردد. به بیان دیگر کاهش تنوع ژنتیکی در طی فرآیند تکامل باعث میشود تا روند جستجوی حالت مساله مختل گردد. دومین مشکلی که الگوریتمهای سیستم ایمنی مصنوعی با آن مواجه میباشند ، عدم پایداری این الگوریتمها در اجراهای مختلف میباشد. ماهیت اتفاقی بودن این الگوریتم ها باعث می شود تا کیفیت پاسخهایی که الگوریتم در اجراهای مختلف نتیجه میدهد بسیار متنوع باشد.
در مثال ارائه شده جوادزاده و میبدی تلاش در تقویت الگوریتمهای سیستم ایمنی مصنوعی با استفاده از استراتژی ترکیب دارند. بدین صورت که از یک هیوریستیک جستجوی محلی در آنتیبادی های حافظه استفاده میشود.
ترکیب الگوریتم سیستم ایمنی مصنوعی و جستجوی محلی
یکی از مهمترین جنبههای الگوریتمهای سیستم ایمنی مصنوعی ، انتخاب و جامعه سلولهایی که بیشترین سطح تحریک را دارند که متناسب با میزان وابستگی آنتیژنی است و همچنین از بین رفتن سلولهایی که تحریک نمی شوند می باشد. بر اساس این الگوریتمها ، آنتیبادیها بر اساس اعضاء جامعه با جهش و تکامی شناسگرهایشان تکامل می یابند و بهترین آنها وارد حافظه می شوند. به بیان دیگر آنتی بادی سلول های حافظه با استفاده از آنتی بادی هایی که در روند اجرای الگوریتم در برابر آنتی ژن ها ارزیابی و بهبود یافته اند ، بروزرسانی می شوند. بنابراین آنتی بادی سلول های حافظه بیشترین شایستگی را کسب می نمایند.
جهت بهبود دقت الگوریتم از روش جستجوی محلی در ناحیه آنتی بادی سلول های حافظه استفاده شده است. علت نامگذاری جستجو به جستجوی محلی ، انجام جستجو فقط در اطراف آنتی بادی سلول های حافظه در مقیاس کوچک می باشد. بنابراین با جستجوی محلی در ناحیه آنتی بادی های سلول های حافظه با مقیاس کوچک در اطراف بهترین آنتی بادی سلول های حافظه ، دقت الگوریتم افزایش یافته و شایستگی های آنتی بادی های سلول های حافظه افزایش یافته و بر سرعت همگرایی افزوده می شود.
جوادزاده و میبدی برای جستجوی محلی از جستجوی تپه نوردی و الگوریتم های ژنتیک استفاده نموده اند. در مسائلی که ابعاد فضای مسئله کوچک باشد جستجوی تپه نوردی دقت بالایی دارد و با بالا رفتن ابعاد فضای مسئله ، زمان اجراء به صورت نمایی افزایش می یابد. الگوریتم پیشنهادی به صورت زیر می باشد.

در ادامه روند الگوریتم ، پس از بهبود آنتی بادی های سلول های حافظه ، علاوه بر اضافه نمودن تعداد آنتی بادی ها به صورت تصادفی به جمعیت آنتی بادی ها ، بخشی از آنتی بادی های حافظه برای افزایش سرعت همگرایی به جمعیت آنتی بادی ها افزوده می شود. برای اعمال عملگر ابرجهش از رابطه های (۷) و (۸) و برای تعیین اندازه جمعیت برای n آنتی بادی از رابطه (۹) استفاده شده است.

در رابطه (۷) متغیر c’ تعداد آنتی بادی هایی است که تحت تاثیر عملگر ابرجهش قرار گرفته اند. و (N(0,1 عدد تصادفی تابع گوسین با میانگین صفر و انحراف معیار δ=1 می باشد.
در رابطه (۸) پارامتر β، پارامتری برای کنترل ضریب کاهش تابع نمایی و *f مقدار شایستگی است که در بازه [۰,۱] نرمال شده است.

در رابطه (۹) متغیر Nc مجموع اعضاء جمعیت تولید شده برای آنتی بادی ها، ضریب تکثیر، N تعداد آنتی بادی ها و ()round عملگری است که آرگومان ورودی خود را به نزدیکترین عدد گرد می نماید.
نتایج آزمایش ها
در این قسمت شبیه سازی راهکار پیشنهادی برای چهار تابع محک استاندارد یعنی روابط (۱۰) تا (۱۳) به ازاء کیفیت جواب بدست آمده بر اساس روش های مختلف جستجوی محلی توسط جوادزاده و میبدی مورد مطالعه قرار گرفته است.
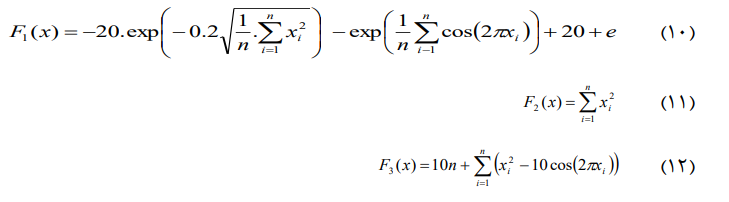

جهت ارزیابی راهکارهای پیشنهادی (بجز در مورد جستجوی محلی تپه نوردی) توابع مورد آزمایش به صورت سی بُعدی و آنتی بادی ها به صورت اعداد حقیقی استفاده شده و راهکار پیشنهادی با ۱۰۰ بار تکرار برای بدست اوردن پاسخ بهینه مورد آزمون قرار گرفتند.
راهکار پیشنهادی با جستجوی محلی تپه نوردی
راهکار پیشنهادی از جستجوی تپه نوردی به عنوان جستجوی محلی استفاده می نماید و آنتی بادی های حافظه با استفاده از آن بهبود می یابند.جستجوی تپه نوردی مورد استفاده ، جستجوی تپه نوردی کامل است که در این روش مام همسایه ها در شعاع همسایگی معین بررسی و بهترین همسایه ، جایگزین حالت فعلی می گردد.
جواد زاده و میبدی در ادامه برای مطالعه روند همگرایی راهکار پیشنهادی با جستجوی محلی تپه نوردی ، بهترین ، بدترین ، میانگین و انحراف معیار ارزش تمام آنتی بادی های حافظه برای تمام توابع (روابط ۱۰ تا ۱۳) را آزمایش نموده اند. در جدول ۴ نتایج شیه سازی شده را برای راهکار پیشنهادی مشاهده می نمائید.

با توجه به این که تعداد تکرارهای مورد نیاز برای هربار اجرای جستجوی تپه نوردی از قبل قابل پیش بینی نبوده و پیچیدگی زمانی هر تکرار نیز نمایی می باشد ، زمان لازم برای اجرای الگوریتم در تکرارهای مختلف یکسان نبوده و حتی ممکن است در یک حالت خاص ، الگوریتم تقلیدی تبدیل به یک جستجوی کامل گردد و با بالا رفتن ابعاد فضای مسئله عملا این روش کارایی مناسبی نخواهد داشت.
بنابراین برای ارزیابی این راهکار پیشنهادی ، توابع مود آزمایش به صورا دو بعدی و آنتی بادی ها به صورت اعداد حقیقی کد گذاری می شوند.
راهکار پیشنهادی با جستجوی محلی ژنتیک
در این قسمت جوادزاده و میبدی از الگوریتم ژنتیکی استاندارد جهت جستجوی محلی استفاده نموده اند و آنتی بادی های حافظه را با استفاده از آن بهبود می بخشند. برای مطالعه روند همگرایی راهکار پیشنهادی با جستجوی محلی ژنتیک ، بهترین ، بدترین میانگین و انحراف معیار ارزش صآنتی باتدی های حافظه برای تمام توابع ۱۰ تا ۱۳ گزارش شده اند.
جدول ۵ نتایج شبیه سازی راهکار پیشنهادی را نشان می دهد. نتایج نشان می دهند که راهکار پیشنهادی با جستجوی محلی ژنتیک به جواب های بهینه همگرا می شوند و برای مقایسه ، نتایج الگوریتم سیستم ایمنی مصنوعی استاندارد در جدول ۶ مشاهده می شود.

در راهکار پیشنهادی از الگوریتم ژنتیکی استاندارد با مشخصات ارائه شده در جدول ۷ به منظور بهبود در آنتی بادی های حافظه استفاده شده است. همچنین در این الگوریتم از مکانیزم انتخاب چرخ رولت به منظور انتخاب والدها در عملگر پیوند استفاده شده است.

با توجه به نتایج حاصله در جدول های ۵ و ۶ جوادزاده و میبدی نتیجه گیری کرده اند که کارایی راهکار پیشنهادی نسبت به الگوریتم سیستم ایمنی مصنوعی تائید شده است.
نتیجه گیری
از مهمترین مشکلاتی که الگوریتم های سیستم ایمنی مصنوعی رایج با آن مواجه می باشند ، می توان به همگرایی کند به بهینه سراسری و همچنین عدم پایداری در اجراهای مختلف اشاره نمود. در مقاله جوادزاده و میبدی برای علبه بر این مشکلات از یک جستجوی محلی در اطراف آنتی بادی های حتافظه استفاده شده است. نتایج حاصل از شبیه سازی توسط این دو نفر نشان می دهد که این راهکار پاسخ های بهتری را در مقایسه با الگوریتم استاندارد یسیتم ایمنی مصنوعی نتیجه می دهد. اجرای مکرر شبیه سازی ها توسط این دو نفر نشان داده است که راهکار پیشنهادی از پایداری قابل قبولی برخوردار است.
برای دریافت مقاله به صورت pdf بر روی لینک کلیک کنید: Artificial-Immune-System-AIS
منبع
سیستم ایمنی مصنوعی به طور موفقیت آمیزی برای دامنه وسیعی از مسائل مانند تشخیص نفوذ به شبکه تا مدل های دسته بندی داده، یادگیری مفهوم، خوشه بندی داده، رباتیک، شناسایی الگو، داده کاوی، همچنین برای مقدار دهی اولیه وزن ها در شبکه عصبی و بهینه سازی توابع چند وجهی استفاده می شود.
هدف اصلی سیستم ایمنی طبیعی در بدن انسان، تمایز بین بافت خودی و عامل خارجی (غیر خودی یا آنتی ژن) است. سیستم ایمنی بدن، به مواد خارجی یا مواد بیماری زا (معروف به آنتی ژن) عکسل العمل نشان می دهد. در حین این واکنش، سیستم ایمنی برای تشخیص بهتر آنتی ژن دیده شده، تطبیق یافته و حافظه ای برای ثبت آنتی ژن های رایج ایجاد می کند. حافظه ایجاد شده باعث بهبود و سرعت بخشیدن به واکنش سیستم ایمنی تطبیق پذیر در برخوردهای آینده با همان آنتی ژن خواهد شد. شناسایی آنتی ژن ها منجر به تولید سلول های خاصی می شود که آنتی ژن را غیر فعال و یا نابود می کند. سیستم ایمنی بدن، همانند یک سیستم تشخیص الگو کار می کند، برای تشخیص الگوهای غیر خودی از الگوهای خودی.
در سیستم ایمنی طبیعی، آنتی ژن ها موادی هستند که می توانند پاسخ ایمنی را ایجاد کنند. پاسخ ایمنی واکنش بدن به آنتی ژن است، بنابراین از صدمه زدن آنتی ژن به بدن جلوگیری می کند. آنتی ژن ها می توانند باکتری، قارچ، انگل و یا ویروس باشند. یک آنتی ژن باید به عنوان یک خارجی تشخیص داده شود.
وظیفه تشخیص آنتی ژن ها بر عهده گلبول سفید با نام لنفوسیت است. دو نوع لنفوسیت وجود دارد: T-Cell و B-Cell، که هر دو در مغز استخوان تولید می شوند. B-Cell ها در تماس با آنتی ژن ها، آنتی بادی هایی تولید می کند که در مقابل آنتی ژن ها موثر است. آنتی بادی ها پروتئین های شیمیایی هستند و دارای شکل Y مانند هستند.
آنتی بادی ها دارای گیرنده های خاص برای تشخیص آنتی ژن ها هستند. زمانی که تماس بین آنتی بادی با یک B-Cell و آنتی ژن برقرار می شود، تکثیر کلونی در سطح B-Cell اتفاق می افتد و به کمک T-Cell تقویت می شود. در صورت آنکه یک آنتی بادی به جای تشخیص آنتی ژن، بافت خودی را به عنوان عامل خارجی تشخیص داد خودش را نابود می کند.
در حین تکثیر کلونی، دو نوع از سلول شکل می گیرد: سلول های پلاسما و سلول های حافظه. وظیفه سلول های حافظه تکثیر سلول های پلاسما برای واکنش سریعتر در مواجه تکراری با آنتی ژن ها و تولید آنتی بادی برای آن هاست. سلول پلاسما یک سلول B-Cell است که آنتی بادی تولید می کند.
بخش کوچکی از یک آنتی ژن اپیتپ و بخش کوچکی از آنتی بادی ها پاراتپ نامیده می شود. اپیتپ ها پاسخ ایمنی خاصی را طلب می کنند و پاراتپ ها در آنتی بادی ها می توانند به این اپیتپ با یک توان پیوند مشخص، پیوند بخورند. بعد از برقراری پیوند، بین پاراتپ یک آنتی بادی و اپیتپ یک آنتی ژن، ترکیب آنتی بادی-آنتی ژن تشکیل می شود که منجر به از کار افتادن آنتی ژن می شود.
از عملکرد سیستم ایمنی بدن در تشخیص و انهدام عوامل خارجی برای طراحی الگوریتم های متنوعی در بهینه سازی، یادگیری ماشین و شناسایی الگو بهره برداری شده است. سیستم ایمنی مصنوعی یا AIS مخفف Artificial Immune System است که اولین بار به عنوان یک الگوریتم توسط دی کاسترو و زوبن تحت نام الگوریتم کلونی ارائه شد.
ایده اصلی در سیستم ایمنی مصنوعی، برگرفته از فرآیند تکثیر سلولی پس از تشخیص عامل خارجی در سیستم ایمنی طبیعی است. این فرآیند در سیستم ایمنی مصنوعی با نام انتخاب کلونی شناخته می شود و شامل سه مرحله است. در مرحله اول، گروهی از بهترین سلول ها ( سلول هایی که آنتی بادی مربوط به آنها بیشترین تطابق را با آنتی ژن ها داشته باشد) انتخاب می شود. در اینجا عملا هر سلول معادل یه پاسخ مساله است همانند کروموزوم در یک الگوریتم ژنتیک. در مرحله دوم، سلول های انتخاب شده تحت عملیات کلون قرار گرفته و با توجه به یک پارامتر با نام نرخ تکثیر، مورد تکثیر واقع می شود. تعداد کپی هایی که از هر سلول تولید می شود بستگی به ارزش آن سلول دارد. هر چقدر برازش یک سلول بیشتر باشد، تعداد کپی های بیشتری از آن ایجاد خواهد شد. در مرحله سوم، سلول تکثیر شده تحت عملگری با نام فراجهش قرار می گیرد. این عملگر که مشابه عملگر جهش در الگوریتم ژنتیک است، با توجه به پارامتری با نام Pm که نرخ جهش است، تغییر کوچکی را به هر سلول تکثیر شده اعمال می کند. (شبیه عملگر جهش در GA). تفاوتی که عملگر فراجهش با عملگر جهش در GA دارد آن است که در فراجهش، اندازه تغییراتی که در سلول ایجاد می شود بستگی به برازش آن سلول دارد. هر چقدر یک سلول برازنده تر باشد، تغییرات کمتری به آن اعمال خواهد شد.
سیستم ایمنی مصنوعی به طور موفقیت آمیزی برای دامنه وسیعی از مسائل به کار رفته است. از مسائل تشخیص نفوذ به شبکه تا مدل های دسته بندی داده، یادگیری مفهوم، خوشه بندی داده، رباتیک، شناسایی الگو، داده کاوی، همچنین از سیستم ایمنی مصنوعی برای مقدار دهی اولیه وزن ها در شبکه عصبی و بهینه سازی توابع چند وجهی استفاده می شود.
خصوصیات مهم سیستم ایمنی مصنوعی به شرح زیر است:
1- استفاده از نمایش رشته بیتی
2- طول ثابت و یکسان برای هر سلول
3- به کارگیری یک جمعیت یا تعداد اعضا ثابت، البته در سیستم ایمنی مصنوعی می توان با تعریف طول عمر برای سلول های جمعیت، از یک جمعیت با تعداد اعضای متغیر نیز بهره برد.
4- در شبه کد، Selectionsize نشان گر تعداد سلول هایی است که برای انجام عملیات تکثیر، از جمعیت دور جاری در حلقه while انتخاب می شوند. به خاطر وجود همین مرحله در سیستم ایمنی مصنوعی، ماهیتی مشابه انتخاب داروینی وجود دارد.
5- برای تعیین عدد تکثیر سلولی برای یک سلول ایمنی انتخاب شده در تابع Clone از رابطه (Nc=Round(β,N,R استفاده می شود. در این رابطه Nc بیانگر تعداد کپی سلول β مبین نرخ تکثیرClonerate، همچنین N نشان گر تعداد سلول های جمعیت (Populationsize) و R بیانگر برازش مبتنی بر رتبه سلول مورد تکثیر است.
6- استفاده از جهش معکوش سازی بیت در عملگر فراجهش (عملگر جهش در AIS عملگر اصلی است).
7- برخلاف الگوریتم های تکاملی که معمولا احتمال جهش مقداری ثابت است، احتمال فراجهش Phm در سیستم ایمنی مصنوعی مقداری متغیر داشته و اندازه آن بستگی به برازش سلول ایمنی (عضو جمعیت) دارد. برای محاسبه احتمال فراجهش داریم: (Phm=exp(-Pm.f، در این رابطه Pm نرخ جهش بوده و f برازش سلول ایمنی مورد جهش است.

منبع
سیستم ایمنی مصنوعی (AIS) قسمت 1
سیستم ایمنی مصنوعی (AIS) قسمت 2
سیستم ایمنی مصنوعی (AIS) قسمت 3
سیستم ایمنی مصنوعی (AIS) قسمت 4
سیستم ایمنی مصنوعی (AIS) قسمت 5
سیستم ایمنی مصنوعی (AIS) قسمت 6