کد الگوریتم سوبل – متد سوبل لبه ها را با استفاده از تخمین زدن مشتق پیدا می کند، که لبه ها را در آن نقاطی بر می گرداند که گرادیان تصویر I ، max است. پیشنهاد می کنیم جهت آشنایی با الگوریتم های لبه یابی، مطلب «الگوریتم های لبه یابی و انواع آن» را مشاهده نمایید. در فیلتر سوبل دو ماسک به صورت زیر وجود دارد:


ماسک سوبل افقی بیشتر لبه هاي افقی را مشخص میکند و ماسک سوبل عمودي،لبه هاي عمودي را مشخص میکند.
براي مشخص شدن کلیه لبه ها:
اگر Gx و Gy تصاویر فیلتر شده به وسیله ماسک افقی و عمودي باشند، آنگاه تصویر 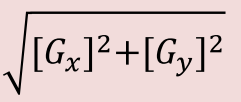 لبه هاي تصویر را بهتر نشان میدهد. روال فوق به عملگر یا الگورریتم سوبل موسوم است.
لبه هاي تصویر را بهتر نشان میدهد. روال فوق به عملگر یا الگورریتم سوبل موسوم است.
در عمل، به منظور کاهش هزینه محاسبات، به جاي میتوان از تقریب [Gx] + [Gy] استفاده میشود. توجه شود که نتیجه این دو فرمول تقریبا یکسان است ولی فرمول دوم با هزینه کمتري قابل محاسبه می باشد.

کد الگوریتم سوبل( Sobel ) در Matlab:
clc; clear; close all; warning off;
I=imread('lena.bmp');
I=im2double(I);
I=imnoise(I, 'gaussian', 0, 0.001);
figure(1);
imshow(I);title('org img');
[height width R]=size(I);
for i=2:height-1
for j=2:width-1
Dx(i,j)=[I(i+1,j-1)-I(i-1,j-1)]+2*[I(i+1,j)-I(i-1,j)]+[I(i+1,j+1)-I(i-1,j+1)];
Dy(i,j)=[I(i-1,j+1)-I(i-1,j-1)]+2*[I(i,j+1)-I(i,j-1)]+[I(i+1,j+1)-I(i+1,j-1)];
S(i,j)=sqrt(Dx(i,j)^2+Dy(i,j)^2);
if Dx(i,j)<1
Dx(i,j)=0;
else Dx(i,j)=1;
end
if Dy(i,j)<1
Dy(i,j)=0;
else Dy(i,j)=1;
end
end
end
figure(2);
imshow(Dx,[]);
figure(3);
imshow(Dy,[]);
for i=1:255
for j=1:255
if (S(i,j)<1)
S(i,j)=0;
else S(i,j)=1;
end
end
end
figure(4);
imshow(S,[]);
دانلود کد فوق از طریق لینک زیر:
رمز فایل : behsanandish.com
کد الگوریتم سوبل( Sobel ) در #C:
1.کد برای فیلتر کانولوشن: بخش اول این تابع برای گرفتن اطلاعات تصویر و ذخیره آن به آرایه اختصاص داده شده است.
private static Bitmap ConvolutionFilter(Bitmap sourceImage,
double[,] xkernel,
double[,] ykernel, double factor = 1, int bias = 0, bool grayscale = false)
{
//Image dimensions stored in variables for convenience
int width = sourceImage.Width;
int height = sourceImage.Height;
//Lock source image bits into system memory
BitmapData srcData = sourceImage.LockBits(new Rectangle(0, 0, width, height), ImageLockMode.ReadOnly, PixelFormat.Format32bppArgb);
//Get the total number of bytes in your image - 32 bytes per pixel x image width x image height -> for 32bpp images
int bytes = srcData.Stride * srcData.Height;
//Create byte arrays to hold pixel information of your image
byte[] pixelBuffer = new byte[bytes];
byte[] resultBuffer = new byte[bytes];
//Get the address of the first pixel data
IntPtr srcScan0 = srcData.Scan0;
//Copy image data to one of the byte arrays
Marshal.Copy(srcScan0, pixelBuffer, 0, bytes);
//Unlock bits from system memory -> we have all our needed info in the array
sourceImage.UnlockBits(srcData);
2.کد تبدیل سیاه و سفید: از آنجایی که اپراتور Sobel اغلب برای تصاویر سیاه و سفید استفاده می شود، در اینجا یک کد برای تبدیل به سیاه و سفید است که توسط پارامتر boolean شما می توانید انتخاب کنید تبدیل کردن را یا نه.
//Convert your image to grayscale if necessary
if (grayscale == true)
{
float rgb = 0;
for (int i = 0; i < pixelBuffer.Length; i += 4)
{
rgb = pixelBuffer[i] * .21f;
rgb += pixelBuffer[i + 1] * .71f;
rgb += pixelBuffer[i + 2] * .071f;
pixelBuffer[i] = (byte)rgb;
pixelBuffer[i + 1] = pixelBuffer[i];
pixelBuffer[i + 2] = pixelBuffer[i];
pixelBuffer[i + 3] = 255;
}
}
3.کد برای تنظیم متغیرهای مورد استفاده در فرآیند کانولوشن:
/Create variable for pixel data for each kernel
double xr = 0.0;
double xg = 0.0;
double xb = 0.0;
double yr = 0.0;
double yg = 0.0;
double yb = 0.0;
double rt = 0.0;
double gt = 0.0;
double bt = 0.0;
//This is how much your center pixel is offset from the border of your kernel
//Sobel is 3x3, so center is 1 pixel from the kernel border
int filterOffset = 1;
int calcOffset = 0;
int byteOffset = 0;
//Start with the pixel that is offset 1 from top and 1 from the left side
//this is so entire kernel is on your image
for (int OffsetY = filterOffset; OffsetY < height - filterOffset; OffsetY++)
{
for (int OffsetX = filterOffset; OffsetX < width - filterOffset; OffsetX++)
{
//reset rgb values to 0
xr = xg = xb = yr = yg = yb = 0;
rt = gt = bt = 0.0;
//position of the kernel center pixel
byteOffset = OffsetY * srcData.Stride + OffsetX * 4;
4. اعمال کانولوشن هسته به پیکسل فعلی:
//kernel calculations
for (int filterY = -filterOffset; filterY <= filterOffset; filterY++)
{
for (int filterX = -filterOffset; filterX <= filterOffset; filterX++)
{
calcOffset = byteOffset + filterX * 4 + filterY * srcData.Stride;
xb += (double)(pixelBuffer[calcOffset]) * xkernel[filterY + filterOffset, filterX + filterOffset];
xg += (double)(pixelBuffer[calcOffset + 1]) * xkernel[filterY + filterOffset, filterX + filterOffset];
xr += (double)(pixelBuffer[calcOffset + 2]) * xkernel[filterY + filterOffset, filterX + filterOffset];
yb += (double)(pixelBuffer[calcOffset]) * ykernel[filterY + filterOffset, filterX + filterOffset];
yg += (double)(pixelBuffer[calcOffset + 1]) * ykernel[filterY + filterOffset, filterX + filterOffset];
yr += (double)(pixelBuffer[calcOffset + 2]) * ykernel[filterY + filterOffset, filterX + filterOffset];
}
}
//total rgb values for this pixel
bt = Math.Sqrt((xb * xb) + (yb * yb));
gt = Math.Sqrt((xg * xg) + (yg * yg));
rt = Math.Sqrt((xr * xr) + (yr * yr));
//set limits, bytes can hold values from 0 up to 255;
if (bt > 255) bt = 255;
else if (bt < 0) bt = 0;
if (gt > 255) gt = 255;
else if (gt < 0) gt = 0;
if (rt > 255) rt = 255;
else if (rt < 0) rt = 0;
//set new data in the other byte array for your image data
resultBuffer[byteOffset] = (byte)(bt);
resultBuffer[byteOffset + 1] = (byte)(gt);
resultBuffer[byteOffset + 2] = (byte)(rt);
resultBuffer[byteOffset + 3] = 255;
}
}
5. کد خروجی تصویر پردازش شده:
//Create new bitmap which will hold the processed data
Bitmap resultImage = new Bitmap(width, height);
//Lock bits into system memory
BitmapData resultData = resultImage.LockBits(new Rectangle(0, 0, width, height), ImageLockMode.WriteOnly, PixelFormat.Format32bppArgb);
//Copy from byte array that holds processed data to bitmap
Marshal.Copy(resultBuffer, 0, resultData.Scan0, resultBuffer.Length);
//Unlock bits from system memory
resultImage.UnlockBits(resultData);
//Return processed image
return resultImage;
}
6. کد برای هسته سوبل:
//Sobel operator kernel for horizontal pixel changes
private static double[,] xSobel
{
get
{
return new double[,]
{
{ -1, 0, 1 },
{ -2, 0, 2 },
{ -1, 0, 1 }
};
}
}
//Sobel operator kernel for vertical pixel changes
private static double[,] ySobel
{
get
{
return new double[,]
{
{ 1, 2, 1 },
{ 0, 0, 0 },
{ -1, -2, -1 }
};
}
}
همه این کد در اینجا موجود است (پروژه با ویژوال استودیو 2015 ایجاد شد):
SobelOperatorInC#
رمز فایل : behsanandish.com

کد الگوریتم سوبل( Sobel ) در ++C:
در ادامه دو کد برای الگوریتم Sobel در ++C آماده کردیم:
1.
#include<iostream>
#include<cmath>
#include<opencv2/imgproc/imgproc.hpp>
#include<opencv2/highgui/highgui.hpp>
using namespace std;
using namespace cv;
// Computes the x component of the gradient vector
// at a given point in a image.
// returns gradient in the x direction
int xGradient(Mat image, int x, int y)
{
return image.at<uchar>(y-1, x-1) +
2*image.at<uchar>(y, x-1) +
image.at<uchar>(y+1, x-1) -
image.at<uchar>(y-1, x+1) -
2*image.at<uchar>(y, x+1) -
image.at<uchar>(y+1, x+1);
}
// Computes the y component of the gradient vector
// at a given point in a image
// returns gradient in the y direction
int yGradient(Mat image, int x, int y)
{
return image.at<uchar>(y-1, x-1) +
2*image.at<uchar>(y-1, x) +
image.at<uchar>(y-1, x+1) -
image.at<uchar>(y+1, x-1) -
2*image.at<uchar>(y+1, x) -
image.at<uchar>(y+1, x+1);
}
int main()
{
Mat src, dst;
int gx, gy, sum;
// Load an image
src = imread("lena.jpg", CV_LOAD_IMAGE_GRAYSCALE);
dst = src.clone();
if( !src.data )
{ return -1; }
for(int y = 0; y < src.rows; y++)
for(int x = 0; x < src.cols; x++)
dst.at<uchar>(y,x) = 0.0;
for(int y = 1; y < src.rows - 1; y++){
for(int x = 1; x < src.cols - 1; x++){
gx = xGradient(src, x, y);
gy = yGradient(src, x, y);
sum = abs(gx) + abs(gy);
sum = sum > 255 ? 255:sum;
sum = sum < 0 ? 0 : sum;
dst.at<uchar>(y,x) = sum;
}
}
namedWindow("final");
imshow("final", dst);
namedWindow("initial");
imshow("initial", src);
waitKey();
return 0;
}
دانلود کد فوق از طریق لینک زیر:
رمز فایل : behsanandish.com
2.
#include "itkImage.h"
#include "itkImageFileReader.h"
#include "itkImageFileWriter.h"
#include "itkSobelEdgeDetectionImageFilter.h"
int main( int argc, char* argv[] )
{
if( argc != 3 )
{
std::cerr << "Usage: "<< std::endl;
std::cerr << argv[0];
std::cerr << "<InputFileName> <OutputFileName>";
std::cerr << std::endl;
return EXIT_FAILURE;
}
constexpr unsigned int Dimension = 2;
using InputPixelType = unsigned char;
using InputImageType = itk::Image< InputPixelType, Dimension >;
using ReaderType = itk::ImageFileReader< InputImageType >;
ReaderType::Pointer reader = ReaderType::New();
reader->SetFileName( argv[1] );
using OutputPixelType = float;
using OutputImageType = itk::Image< OutputPixelType, Dimension >;
using FilterType = itk::SobelEdgeDetectionImageFilter< InputImageType, OutputImageType >;
FilterType::Pointer filter = FilterType::New();
filter->SetInput( reader->GetOutput() );
using WriterType = itk::ImageFileWriter< OutputImageType >;
WriterType::Pointer writer = WriterType::New();
writer->SetFileName( argv[2] );
writer->SetInput( filter->GetOutput() );
try
{
writer->Update();
}
catch( itk::ExceptionObject & error )
{
std::cerr << "Error: " << error << std::endl;
return EXIT_FAILURE;
}
return EXIT_SUCCESS;
}
دانلود کد فوق از طریق لینک زیر:
رمز فایل : behsanandish.com
کد الگوریتم سوبل( Sobel ) در C:
/* sobel.c */
#include <stdio.h>
#include <stdlib.h>
#include <float.h>
#include "mypgm.h"
void sobel_filtering( )
/* Spatial filtering of image data */
/* Sobel filter (horizontal differentiation */
/* Input: image1[y][x] ---- Outout: image2[y][x] */
{
/* Definition of Sobel filter in horizontal direction */
int weight[3][3] = {{ -1, 0, 1 },
{ -2, 0, 2 },
{ -1, 0, 1 }};
double pixel_value;
double min, max;
int x, y, i, j; /* Loop variable */
/* Maximum values calculation after filtering*/
printf("Now, filtering of input image is performed\n\n");
min = DBL_MAX;
max = -DBL_MAX;
for (y = 1; y < y_size1 - 1; y++) {
for (x = 1; x < x_size1 - 1; x++) {
pixel_value = 0.0;
for (j = -1; j <= 1; j++) {
for (i = -1; i <= 1; i++) {
pixel_value += weight[j + 1][i + 1] * image1[y + j][x + i];
}
}
if (pixel_value < min) min = pixel_value;
if (pixel_value > max) max = pixel_value;
}
}
if ((int)(max - min) == 0) {
printf("Nothing exists!!!\n\n");
exit(1);
}
/* Initialization of image2[y][x] */
x_size2 = x_size1;
y_size2 = y_size1;
for (y = 0; y < y_size2; y++) {
for (x = 0; x < x_size2; x++) {
image2[y][x] = 0;
}
}
/* Generation of image2 after linear transformtion */
for (y = 1; y < y_size1 - 1; y++) {
for (x = 1; x < x_size1 - 1; x++) {
pixel_value = 0.0;
for (j = -1; j <= 1; j++) {
for (i = -1; i <= 1; i++) {
pixel_value += weight[j + 1][i + 1] * image1[y + j][x + i];
}
}
pixel_value = MAX_BRIGHTNESS * (pixel_value - min) / (max - min);
image2[y][x] = (unsigned char)pixel_value;
}
}
}
main( )
{
load_image_data( ); /* Input of image1 */
sobel_filtering( ); /* Sobel filter is applied to image1 */
save_image_data( ); /* Output of image2 */
return 0;
}
دانلود کد فوق از طریق لینک زیر:
رمز فایل : behsanandish.com
کد الگوریتم سوبل( Sobel ) در Visual Basic:
Private Sub bEdge_Click(sender As Object, e As EventArgs) _
Handles bEdge.Click
'Sobel Edge'
Dim tmpImage As Bitmap = New Bitmap(picOriginal.Image)
Dim bmpImage As Bitmap = New Bitmap(picOriginal.Image)
Dim intWidth As Integer = tmpImage.Width
Dim intHeight As Integer = tmpImage.Height
Dim intOldX As Integer(,) = New Integer(,) {{-1, 0, 1}, _
{-2, 0, 2}, {-1, 0, 1}}
Dim intOldY As Integer(,) = New Integer(,) {{1, 2, 1}, _
{0, 0, 0}, {-1, -2, -1}}
Dim intR As Integer(,) = New Integer(intWidth - 1, _
intHeight - 1) {}
Dim intG As Integer(,) = New Integer(intWidth - 1, _
intHeight - 1) {}
Dim intB As Integer(,) = New Integer(intWidth - 1, _
intHeight - 1) {}
Dim intMax As Integer = 128 * 128
For i As Integer = 0 To intWidth - 1
For j As Integer = 0 To intHeight - 1
intR(i, j) = tmpImage.GetPixel(i, j).R
intG(i, j) = tmpImage.GetPixel(i, j).G
intB(i, j) = tmpImage.GetPixel(i, j).B
Next
Next
Dim intRX As Integer = 0
Dim intRY As Integer = 0
Dim intGX As Integer = 0
Dim intGY As Integer = 0
Dim intBX As Integer = 0
Dim intBY As Integer = 0
Dim intRTot As Integer
Dim intGTot As Integer
Dim intBTot As Integer
For i As Integer = 1 To tmpImage.Width - 1 - 1
For j As Integer = 1 To tmpImage.Height - 1 - 1
intRX = 0
intRY = 0
intGX = 0
intGY = 0
intBX = 0
intBY = 0
intRTot = 0
intGTot = 0
intBTot = 0
For width As Integer = -1 To 2 - 1
For height As Integer = -1 To 2 - 1
intRTot = intR(i + height, j + width)
intRX += intOldX(width + 1, height + 1) * intRTot
intRY += intOldY(width + 1, height + 1) * intRTot
intGTot = intG(i + height, j + width)
intGX += intOldX(width + 1, height + 1) * intGTot
intGY += intOldY(width + 1, height + 1) * intGTot
intBTot = intB(i + height, j + width)
intBX += intOldX(width + 1, height + 1) * intBTot
intBY += intOldY(width + 1, height + 1) * intBTot
Next
Next
If intRX * intRX + intRY * intRY > intMax OrElse
intGX * intGX + intGY * intGY > intMax OrElse
intBX * intBX + intBY * intBY > intMax Then
bmpImage.SetPixel(i, j, Color.Black)
Else
bmpImage.SetPixel(i, j, Color.Transparent)
End If
Next
Next
picModified.Image = bmpImage
End Sub
دانلود کد فوق از طریق لینک زیر:
رمز فایل : behsanandish.com

پیشنهاد می کنیم جهت آشنایی با الگوریتم های لبه یابی، مطلب «الگوریتم های لبه یابی و انواع آن» را مشاهده نمایید.

