مغر انسان، به اذعان بسیاری از دانشمندان، پیچیده ترین سیستمی است که تا کنون در کل گیتی مشاهده شده و مورد مطالعه قرار گرفته است. اما این پیچیده ترین سیستم، نه ابعادی در حد کهشکشان دارد و نه تعداد اجزای سازنده اش، بیشتر از پردازنده های ابر کامپیوترهای امروزی است. پیچیدگی راز آلود این سیستم بی نظیر، به ارتباط های فراوان موجود میان عناصر آن بر می گردد. چیزی که، مغز 1400 گرمی انسان را، از همه سیستم های دیگر، متمایز می کند.
فرایندهای خودآگاه و ناخودآگاهی که در حدود جغرافیایی بدن انسان رخ می دهند، همگی تحت مدیریت مغز هستند. برخی از این فرایندها آن قدر پیچیده هستند، که هیچ کامپیوتر یا اَبَر کامپیوتری در جهان، امکان پردازش و انجام آن را ندارد. با این حال، تحقیقات نشان می دهند که واحدهای سازنده مغز انسان، از نظر سرعت عملکرد، حدود یک میلیون بار، کندتر از ترانزیستورهای مورد استفاده در تراشه های سیلیکونی CPU هستند.
سرعت و قدرت پردازش بسیار بالای مغز انسان، به ارتباط های بسیار انبوهی بر می گردد که در میان سلول های سازنده مغز وجود دارد و اساسا، بدون وجود این لینک های ارتباطی، مغز انسان هم به یک سیستم معمول کاهش می یابد، که قطعا امکانات فعلی را نخواهد داشت.
گذشته از همه این ها، عملکرد عالی مغز در حل انواع مسائل و کارایی بالای آن، شبیه سازی مغز و قابلیت های آن را، به مهم ترین آرمان معماران سخت افزار و نرم افزار تبدیل کرده است. در واقع، اگر روزی فرا برسد (که البته ظاهرا خیلی هم دور نیست)، که ما بتوانیم کامپیوتری در حد و اندازه های مغز انسان را بسازیم، قطعا یک انقلاب بزرگ در علم، صنعت و االبته زندگی انسان ها، رخ خواهد داد.
در راستای شبیه سازی رفتار محاسباتی مغز انسان، از چند دهه گذشته، که کامپیوترها امکان پیاده سازی الگوریتم های محاسباتی را فراهم نمودند، کارهای پژوهشی توسط متخصصین علوم کامپیوتر، مهندسین و ریاضی دان ها شروع شده است، که ما حصل کار آن ها، در شاخه ای از علم هوش مصنوعی، و در زیر شاخه هوش محاسباتی، تحت عنوان موضوع «شبکه های عصبی مصنوعی» یا Artificial Neural Networks (به اختصار: ANNs) طبقه بندی شده است. در مبحث شبکه های عصبی مصنوعی، مدل های ریاضی و نرم افزاری متعددی با الهام گرفتن از مغز انسان پیشنهاد شده اند، که برای حل گستره وسیعی از مسائل علمی، مهندسی و کاربردی، در حوزه های مختلف کاربرد دارند.
کاربردهای شبکه های عصبی مصنوعی
امروز به قدری استفاده از سیستم های هوشمند، به ویژه شبکه عصبی مصنوعی گسترده شده است، که می توان این ابزارها را، در ردیف عملیات پایه ریاضی و به عنوان ابزارهای عمومی و مشترک طبقه بندی کرد. چرا که کمتر رشته دانشگاهی است که نیازی به تحلیل، تصمیم گیری، تخمین، پیش بینی، طراحی و ساخت داشته باشد، و در آن از موضوع شبکه های عصبی استفاده نشده باشد. فهرستی که در ادامه آمده است، یک فهرست نه چندان کامل است، اما گستردگی کاربردهای شبکه های عصبی مصنوعی را، تا حدود زیادی به تصویر می کشد.
زمینه کلی
کاربرد
علوم کامپیوتر
طبقه بندی اسناد و اطلاعات در شبکه های کامپیوتری و اینترنت
توسعه نرم افزارهای نظارتی و ویروس کش ها
علوم فنی و مهندسی
مهندسی معکوس و مدل سازی سیستم ها
پیش بینی مصرف بار الکتریکی
عیب یابی سیستم های صنعتی و فنی
طراحی انواع سیستم های کنترل
طراحی و بهینه سازی سیستم های فنی و مهندسی
تصمیم گیری بهینه در پروژه های مهندسی
علوم پایه و نجوم
پیش بینی نتایج آزمایش ها
ارزیابی و تخمین صحت فرضیه ها و نظریه ها
مدل سازی پدیده های فیزیکی پیچیده
علوم پزشکی
مدل سازی فرایندهای زیست-پزشکی
تشخیص بیماری ها با توجه به نتایج آزمایش پزشکی و تصویر برداری
پیش بینی نتایج درمان و عمل جراحی
پیاده سازی ادوات و الگوهای درمانی اختصاصی بیمار
علوم تجربی و زیستی
مدل سازی و پیش بینی پدیده های زیستی و محیطی
پیش بینی سری های زمانی با کاربرد در علوم زیست-محیطی
طبقه بندی یافته های ناشی از مشاهدات تجربی
شناسایی الگوهای مخفی و تکرار شونده در طبیعت
علوم اقتصادی و مالی
پیش بینی قیمت سهام و شاخص بورس
طبقه بندی علایم و نمادهای بورس
تحلیل و ارزیابی ریسک
تخصیص سرمایه و اعتبار
علوم اجتماعی و روانشناسی
طبقه بندی و خوشه بندی افراد و گروه ها
مدل سازی و پیش بینی رفتارهای فردی و اجتماعی
هنر و ادبیات
پیش بینی موفقیت و مقبولیت عمومی آثار هنری
استخراج مولفه های اساسی از متون ادبی و آثار هنری
طبقه بندی و کاوش متون ادبی
علوم نظامی
هدف گیری و تعقیب در سلاح های موشکی
پیاده سازی سیستم های دفاعی و پدافند هوشمند
پیش بینی رفتار نیروی مهاجم و دشمن
پیاده سازی حملات و سیستم های دفاعی در جنگ الکترونیک (جنگال)
انواع شبکه های عصبی مصنوعی
انواع مختلفی از مدل های محاسباتی تحت عنوان کلی شبکه های عصبی مصنوعی معرفی شده اند، که هر یک برای دسته ای از کاربردها قابل استفاده اند و در هر کدام، از وجه مشخصی از قابلیت ها و خواص مغز انسان، الهام گرفته شده است.
در همه این مدل ها، یک ساختار ریاضی، که البته به صورت گرافیکی هم قابل نمایش دادن است، در نظر گرفته می شود که یک سری پارامترها و پیچ های تنظیم دارد. این ساختار کلی، توسط یک الگوریتم یادگیری یا تربیت (Training Algorithm) آن قدر تنظیم و بهینه می شود، که بتواند رفتار مناسبی را از خود نشان دهد.
نگاهی به فرایند یادگیری در مغز انسان نیز، نشان می دهد که در واقع ما نیز در مغزمان فرایندی مشابه با این را تجربه می کنیم و همه مهارت ها، دانسته ها و خاطرات ما، در اثر تضعیف یا تقویت ارتباط میان سلول های عصبی مغز شکل می گیرند. این تقویت و تضعیف، در زبان ریاضی خودش را به صورت تنظیم یک پارامتر (موسوم به وزن یا Weight) مدل سازی و توصیف می شود.
اما طرز نگاه مدل های مختلف شبکه های عصبی مصنوعی کاملا متفاوت است و هر یک، بخشی از قابلیت های یادگیری و تطبیق مغز انسان را هدف قرار داده و تقلید نموده اند. در ادامه، یک بررسی مروری از انواع مختلف شبکه های عصبی آمده است که مطالعه آن، در ایجاد یک آشنایی اولیه، بسیار موثر خواهد بود.
پرسپترون چند لایه یا MLP
یکی از پایه ای ترین مدل های عصبی موجود، مدل پرسپترون چند لایه یا Multi-Layer Perceptron (به اختصار MLP) است که عملکرد انتقالی مغز انسان را شبیه سازی می کند. در این نوع شبکه عصبی، رفتار شبکه ای مغز انسان و انتشار سیگنال در آن بیشتر مد نظر بوده است و از این رو، گهگاه با نام شبکه های پیشرو (Feedforward Networks) نیز خوانده می شوند. هر یک از سلول های عصبی مغز انسان، موسوم به نورون (Neuron)، پس از دریافت ورودی (از یک سلول عصبی یا غیر عصبی دیگر)، پردازشی روی آن انجام می دهند و نتیجه را به یک سلول دیگر (عصبی یا غیر عصبی) انتقال می دهد. این رفتار تا حصول نتیجه ای مشخص ادامه دارد، که احتمالا منجر به یک تصمیم، پردازش، تفکر و یا حرکت خواهد شد.
شبکه های عصبی شعاعی یا RBF
مشابه با الگوی شبکه های عصبی MLP، نوع دیگری از شبکه های عصبی وجود دارند که در آن ها، واحدها پردازنده، از نظر پردازشی بر موقعیت خاصی متمرکز هستند. این تمرکز، از طریق توابع شعاعی یا Radial Basis Functions (به اختصار RBF) مدل سازی می شود. از نظر ساختار کلی، شبکه های عصبی RBF تفاوت چندانی با شبکه های MLP ندارند و صرفا نوع پردازشی که نورون ها روی ورودهایشان انجام می دهند، متفاوت است. با این حال، شبکه های RBF غالبا دارای فرایند یادگیری و آماده سازی سریع تری هستند. در واقع، به دلیل تمرکز نورون ها بر محدوده عملکردی خاص، کار تنظیم آن ها، راحت تر خواهد بود.
ماشین های بردار پشتیبان یا SVM
در شبکه های عصبی MLP و RBF، غالبا توجه بر بهبود ساختار شبکه عصبی است، به نحوی که خطای تخمین و میزان اشتباه های شبکه عصبی کمینه شود. اما در نوع خاصی از شبکه عصبی، موسوم به ماشین بردار پشتیبان یا Support Vector Machine (به اختصار SVM)، صرفا بر روی کاهش ریسک عملیاتی مربوط به عدم عملکرد صحیح، تمرکز می شود. ساختار یک شبکه SVM، اشتراکات زیادی با شبکه عصبی MLP دارد و عملا تفاوت اصلی آن، در شیوه یادگیری است.
نگاشت های خود سازمان ده یا SOM
شبکه عصبی کوهونن (Kohonen) و یا نگاشت خود سازمان ده یا Self-Organizing Map (به اختصار SOM) نوع خاصی از شبکه عصبی که از نظر شیوه عملکرد، ساختار و کاربرد، کاملا با انواع شبکه عصبی که پیش از این مورد بررسی قرار گرفتند، متفاوت است. ایده اصلی نگاشت خود سازمان ده، از تقسیم عملکردی ناحیه قشری مغز، الهام گرفته شده است و کاربرد اصلی آن در حل مسائلی است که به مسائل «یادگیری غیر نظارت شده» معروف هستند. در واقع کارکرد اصلی یک SOM، در پیدا کردن شباهت ها و دسته های مشابه در میان انبوهی از داده هاست که در اختیار آن قرار گرفته است. مشابه با کاری که قشر مغز انسان انجام داده است و انبوهی از ورودی های حسی و حرکتی به مغز را، در گروه های مشابهی طبقه بندی (یا بهتر است بگوییم: خوشه بندی) کرده است.
یادگیرنده رقمی ساز بردار یا LVQ
این نوع خاص شبکه عصبی، تعمیم ایده شبکه های عصبی SOM برای حل مسائل یادگیری نظارت شده است. از طرفی شبکه عصبی LVQ (یا Learning Vector Quantization)، می تواند به این صورت تعبیر شود که، گویا شبکه عصبی MLP با یک رویکرد متفاوت کاری را که باید انجام بدهد، یاد می گیرد. اصلی ترین کاربرد این نوع شبکه عصبی، در حل مسائل طبقه بندی است، که گستره وسیعی از کاربردهای سیستم های هوشمند را پوشش می دهد.
شبکه عصبی هاپفیلد یا Hopfield
این نوع شبکه عصبی، بیشتر دارای ماهیتی شبیه به یک سیستم دینامیکی است، که دو یا چند نقطه تعادل پایدار دارد. این سیستم با شروع از هر شرایط اولیه، نهایتا به یکی از نقاط تعادلش همگرا می شود. همگرایی به هر نقطه تعادل، به عنوان تشخیصی است که شبکه عصبی آن را ایجاد کرده است و در واقع می تواند به عنوان یک رویکرد برای حل مسائل طبقه بندی استفاده شود. این سیستم، یکی از قدیمی ترین انواع شبکه های عصبی است، که دارای ساختار بازگشتی است و در ساختار آن، فیدبک های داخلی وجود دارند.
روال کار به این صورت است که کامپیوترها با استفاده از دوربینها تصویربرداری میکنند، به کمک الگوریتمهای بینایی ماشین تصاویر را پردازش و سپس تصاویر پردازش شده را تحلیل میکنند، در نهایت اشیای موجود در تصویر را میفهمند و بر اساس نوع اشیای موجود در تصویر، تصمیم گیری لازم را انجام میدهند. معمولا به هر سیستم بینایی ماشین یک یا چنددوربین، مبدل آنالوگ به دیجیتال و غیره متصل است و خروجی این سیستم به یک کنترلر کامپیوتر یا یک ربات میرود.
پردازشهای بینایی ماشین را در سه سطح دسته بندی میکنند:
بینایی سطح پایین (Low Level Vision)
در بینایی سطح پایین، پردازش تصویر به منظور استخراج ویژگی (لبه، گوشه، یا جریان نوری) انجام میشود.
بینایی سطح میانی (Mid Level Vision)
بینایی سطح میانی با بهره گیری از ویژگیهای استخراج شده از بینایی سطح پایین تشخیص اشیا، تحلیل حرکت و بازسازی سه بعدی صورت میگیرد.
بینایی سطح بالا (High Level Vision)
بینایی سطح بالا وظیفه تفسیر اطلاعات مهیا شده به وسیله بینایی سطح میانی را بر عهده دارد، این تفسیرها ممکن است شامل توصیفهای مفهومی از صحنه مانند فعالیت، قصد و رفتار باشند. این سطح هم چنین مشخص میکند بینایی سطح پایین و میانی چه کارهایی باید انجام دهند.
کاربردهای بینایی ماشین
امروزه میتوان ردپای بینایی ماشین را در صنعت، هواشناسی، شهرسازی، کشاورزی، نجوم و فضا نوردی، پزشکی و غیره که در ادامه درباره هرکدام مختصرا بحث شده است، مشاهده کرد.
صنعت (Industry)
امروزه کمتر کارخانه پیشرفتهای وجود دارد که بخشی از خط تولید آن توسط برنامههای هوشمند بینایی ماشین کنترل نشود.
خطای بسیار کم، سرعت زیاد، هزینه نگهداری بسیار پایین، عدم نیاز به حضور ٢۴ ساعته اپراتور و خیلی مزایای دیگر باعث شده که صنایع و کارخانهها بهسرعت به سمت پردازش تصویر و بینایی ماشین روی بیاورند. برای مثال: دستگاهی ساختهشده که قادر است نانهای پخته را از نانهایی که نیاز به پخت مجدد دارند، تشخیص دهد و آنها را به صورت اتوماتیک به بسته بندی بفرستد و نانهایی که نیاز به پخت دارند را دوباره برای پختن ارسال کند.
هواشناسی (Meteorology)
در علم هواشناسی تشخیص و پیش بینی آب و هوا اکثرا از طریق تصاویر هوایی و ماهوارهای انجام میگیرد. پردازش تصویر در این علم کاربرد زیادی دارد و دقت و سرعت پیش بینی آب و هوا را بسیار بالا میبرد.
شهرسازی (Urbanization)
با مقایسه عکسهای مختلف از سالهای مختلف یک شهر میتوان میزان گسترش و پیشرفت آن را مشاهده کرد. کاربرد دیگر پردازش تصویر میتواند در کنترل ترافیک باشد. با گرفتن عکسهای هوایی از زمین ترافیک هر قسمت از شهر مشخص میشود.
همچنین قبل از ساختن یک شهر میتوان آن را توسط کامپیوتر شبیهسازی کرد که به صورت دوبعدی از بالا و حتی بهصورت سهبعدی از دیدهای مختلف، یک شهرک چطور ممکن است به نظر برسد. تصاویر ماهوارهای که از شهرها گرفته میشود، میتواند توسط فیلترهای مختلف پردازش تصویر فیلتر شود و اطلاعات مختلفی از آن استخراج شود. به طور مثال این که شهر در چه قسمتهایی دارای ساختمانها، آبها یا راههای بیشتری است و همینطور میتوان جادههایی که داخل یا خارج از شهر کشیده شدهاند را تحلیل کرد.
کشاورزی (Agricultural)
این علم در بخش کشاورزی معمولا در دو حالت کاربرد دارد. یکی در پردازش تصاویر گرفتهشده از ارتفاعات بالا مثلا از هواپیما و دیگری در پردازش تصاویر نزدیک به زمین .
در تصاویر دور به عنوان مثال میتوان تقسیمبندی اراضی را تحلیل کرد. همچنین میتوان با مقایسه تصاویر دریافتی در زمانهای متفاوت میزان صدمات احتمالی وارد به محیطزیست را دید. به عنوان مثال میتوان برنامهای نوشت که با توجه به محل رودخانهها و نوع خاک مناطق مختلف، به صورت اتوماتیک بهترین نقاط برای کشت محصولات مختلف را تعیین میکند.
تصاویر نزدیک در ساخت ماشینهای هرز چین اتوماتیک کاربرد دارد. امروزه ماشینهای بسیار گرانقیمت کشاورزی وجود دارند که میتوانند علفهای هرز را از گیاهان تشخیص بدهند و بهصورت خودکار آنها را نابود کنند. برای مثال یکی از پروژههای جالب در بخش کشاورزی، تشخیص خودکار گل زعفران برای جداسازی پرچم قرمزرنگ آن بوده است. این پردازش توسط نرمافزار Stigma detection انجام گرفته است.
نظامی (Martial)
پردازش تصویر بخصوص بینایی ماشین، کاربردهای نظامی بسیاری دارد و این کاربرد برای دولت اکثر کشورها بسیار مهم است. به عنوان مثال موشک هدایت شونده خودکاری وجود دارد که میتواند روی یک ساختمان قفل کند و حتی میتواند به درز بین در و دیوار آن ساختمان که حساس ترین جای ساختمان است به راحتی نفوذ کند. این موشک به صورت اتوماتیک این قسمت را شناسایی کرده و به سمت آن حمله میکند.
امنیتی (Security)
در مسائل امنیتی هم کاربرد بینایی ماشین کاملا در زندگی ما مشهود است. از سیستمهای امنیتی میتوان سیستم تشخیص اثر انگشت اتوماتیک را نام برد. در گوشی ها و لپ تاپ های جدید قابلیت finger print به آنها اضافه شده و میتواند صاحب خود را توسط اثر انگشت شناسایی کند.
کد امنیتی دیگری که همیشه همراه انسان حمل می شود، چشم انسان است. دانشمندان ثابت کرده اند که بافتهای (Pattern) موجود در مردمک چشم هر انسان منحصر به فرد است و هیچ دو فردی در دنیا وجود ندارند که پترن هایی که در مردمک چشم آنها وجود دارد دقیقا مثل هم باشد. از همین روش برای شناخت افراد و سیستم های امنیتی استفاده میشود.
نجوم و فضا نوردی (Astronomy and Space Exploration)
ساخت دستگاههای اتوماتیک رصد آسمان و ثبت وقایع آسمانی به صورت خودکار از کاربردهای بینایی ماشین است که امروزه روی آن کار میشود.
از پروژههای جدید در بخش نجوم که بخشی از آن توسط سیستم پردازش تصویر انجام میشود، تهیه نقشه سهبعدی از کل عالم کائنات است. پردازش تصویر در فضانوردی هم کاربرد زیادی دارد. در تصاویر دور میتوان سطح سیارات و همچنین سطح قمرها را اسکن کرده و اطلاعات بسیار ریزی از آنها استخراجکنیم.
کاربرد دیگر پردازش تصویر در فـیلتر کردن عکسهایی است که توسط تلسکوپهای فضایی مختلف مانند هابل، از فضا گرفته میشود.
کاربرد دیگر آن حذف گردوخاک و جو سیارهها از تصاویر به کمک تصویربرداری IR و X-RAY بهصورت همزمان و ترکیب این تصاویر است.
پزشکی (Medic)
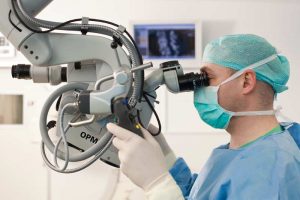
یکی از مهمترین کاربردهای پردازش تصویر در مهندسی پزشکی است. درجایی که ما نیاز داریم تمام عکسها با نهایت شفافیت و وضوح گرفته شوند زیرا دیدن تمام جزئیات لازم است. جراحیهای ریز Microsurgery با ایجاد یک سوراخ کوچک و فقط دیدن محل جراحی توسط پزشک، از راه دور و توسط بازوهای رباتیک بسیار دقیق انجام میشوند.
فناوریهای علمی (Scientific Technology)
بینایی ماشین در افزایش سرعت پیشرفتهای علمی تاثیر فوقالعاده داشته است. اولین و مشخصترین تاثیر آن را میتوان در علم عکاسی یا هنر دید. شکار لحظههای شگفتآوری که در کسری از ثانیه اتفاق میافتد، بالا بردن وضوح عکسهای گرفتهشده و ایجاد افکتهای خیرهکننده، از دستاوردهای پردازش تصویر است.
بینایی ماشین در توسعه فناوری پیشرفته Global Positioning Systems) GPS) نقش زیادی داشته و تهیه نقشههای سهبعدی از جادهها در تمام نقاط جهان، از کاربردهای دیگر آن است. هم چنین با به وجود آمدن این علم، مسابقات رباتهای فوتبالیست بهصورت جدی دنبال شد.
باستانشناسی (Archaeology)
در علم باستانشناسی تنها مدارک باقیمانده از دوران باستان، دستنوشتهها، نقاشیها و غار نگاریهای قدیمی است. تهیه تصاویر از بناهای گذشته و بازسازی مجازی این بناهای تاریخی یکی از کاربردهای پردازش تصویر در این علم است. همچنین میتوان نقاشیها و غارنگاریها را مورد پردازش دقیق قرار داد و شکل آنها را همان طور که در ابتدا بوده اند، شبیهسازی کرد. حتی میتوان مکانهای باستانی را از زوایایی که تصاویر مستندی از آنها وجود ندارد، شبیه سازی کرد.
سینما (Cinema)
اولین علمی که پردازش تصویر در آن مورد استفاده قرار گرفت، هنر و سینما بود. یکی از تکنولوژی های برتر دنیا Motion Capture است که در آن یک کاراکتر انیمیشنی قادر است حرکات دست انسان را تقلید کند. امروزه این سیستم جهت ساخت فیلم ها و بازی های کامپیوتری مورد استفاده قرار میگیرد.
اقتصاد (Economy)
در دنیای امروز تمام نوآوریها، به نوعی مستقیم یا غیر مستقیم باعث تغییراتی در اقتصاد گروهی از کشورها و یا کل دنیا میشوند. پردازش تصویر هم به صورت مستقیم و غیر مستقیم در اقتصاد تاثیر گذار است. از تاثیر مستقیم آن در اقتصاد، میتوان به وجود شعبههای بانک بدون کارمند اشاره کرد. این شعبهها قادرند به صورت خودکار سریال چک ها و قبوض پرداختی را بخوانند، نوع اسکناسها را تشخیص دهند و تا حد زیادی از کارهای یک بانک عادی را انجام دهند.
زمین شناسی (Geology)
با پردازش تصویر میتوان کانیهای مختلف را از روی رنگ و اندازه آن ها شناسایی و دسته بندی کرد. همچنین درزمینشناسی برای پی بردن به مواد تشکیل دهنده کانی ها از روش پرتونگاری (Tomography) استفاده میکنند و پردازش تصویر در این بخش میتواند سرعت و دقت این روش را بسیار بالا ببرد.
تشخیص پلاک از جمله کاربردهای فراگیر بینایی ماشین میباشد. با شناساندن کاراکترهای پلاک هر کشور به سیستم پردازشی و جستجوی شباهت میان آنها و تصاویر ورودی دوربین میتوان پلاک موجود در تصویر را خواند. این سیستمها در پارکینگهای هوشمند،ورودی و خروجی سازمانها و مجتمعهای بزرگ جهت کنترل تردد مورد استفاده قرار میگیرد. علاوه بر اینها در صورت پلاک خوانی یک خودرو در ابتدا و انتهای یک مسیر میتوان سرعت میانگین آن را محاسبه و متخلفین را اعمال قانون کرد.
سرعت سنج (Speedometer)
در نوعی از سرعت سنجهای بزرگراهی از بینایی ماشین جهت استخراج سرعت استفاده میشود. این سیستمها در نوع ثابت و متحرک طراحی میشوند. سیستمهای ثابت در کنار خیابان، جاده و یا بزرگراه نصب شده و سیستمهای متحرک بر روی خودرویهای پلیس نصب میشوند. از این سیستمها میتوان به عنوان تردد شمار و سیستم کنترل ترافیک نیز بهره برد.
ثبت تخلف (Submit an Infringement)
با پردازش تصاویر دوربینهای نصب شده در تقاطعها میتوان زمان، سرعت، جهت حرکت و پلاک خودروها را بدست آورد و بدین ترتیب تخلفات متنوعی از جمله عبور از چراغ قرمز، توقف روی خط عابر پیاده، گردش به چپ و راست و تخطی از سرعت مجاز هنگام عبور از تقاطع را ثبت کرد.
ایمنی در رانندگی (Driving Safety)
برای افزایش سطح ایمنی در رانندگی، ماشینهای جدید مجهز به سیستمهای بینایی ماشینی شدهاند که به راننده در حفظ هوشیاری و دقت کمک میکنند. از جمله این سیستمها میتوان به سیستمهای تشخیص مانع، آینه کنار هشدار دهنده، هشدار دهنده تابلوهای راهنمایی و رانندگی و هشدار دهنده خارج شدن از خطوط جاده اشاره کرد.
تشخیص حجم (Volume Detection)
با توجه به اینکه سیستمهای بینایی ماشین قادرند مشخصات مکانی نقاط تصاویر را استخراج کنند، میتوان از آنها به عنوان سیستمهای تشخیص حجم بهره برد. این سیستم در محلهای دفن زباله پسماند و یا نخاله ساختمانی، معادن و کارخانجات تولید مصالح ساختمانی کاربرد دارد.
از سالها پیش نرم افزارهای زیادی برای تسهیل کاربردهای پردازش تصویر و بینایی ماشین توسعه یافتهاند که شاید معروف ترین آنها جعبه ابزار پردازش تصویر نرم افزار MATLAB باشد.
اما کسانی که تجربه کار با این نرم افزار را دارند به خوبی میدانند که با وجود سهولت برنامه نویسی با آن، سرعت اجرای MATLAB به خصوص برای کار با ویدیو بسیار آزاردهنده است. همچنین این نرم افزار متن باز (Open Source) نیست.
یکی از پروژههای پر سر و صدای بازسازی بناهای باستانی، بازسازی شهر روم باستان توسط دانشمندان ایتالیایی است. هم اکنون با کمک پردازش تصویر، توریستها با زدن عینکهای مخصوص میتوانند در خیابانهای شهر روم باستان قدم بزنند.
امروزه با پیشرفت علم و تکنولوژی، بشر سعی در استفاده حداکثری از دستآوردهای خود را دارد و بینایی ماشین یکی از ابزارهایی است که او را در این مسیر کمک میکند. بینایی ماشین علمی است وسیع با کاربردهای فراوان.
در اوایل دهه ۶۰ متعلق به ناسا شروع به ارسال تصاویر تلویزیونی مبهمی از سطح ماه به زمین کرد. استخراج جزئیات تصویر برای یافتن محلی برای فرود سفینه آپولو نیازمند اعمال تصمیماتی روی تصاویر بود. این کار مهم به عهده لابراتوار Jet Propulsion قرار داده شد. بدین ترتیب زمینه تخصصی پردازش تصاویر رقومی آغاز گردید و مثل تمام تکنولوژی های دیگر سریعاً استفاده های متعدد پیدا کرد.
از سال ۱۹۶۴ تاکنون، موضوع پردازش تصویر، رشد زیادی کرده است.
پردازش تصویر روشی برای تبدیل یک تصویر به صورت دیجیتال و انجام برخی از عملیات بر روی آن، به منظور دریافت یک تصویر بهبود یافته و یا برای استخراج برخی از اطلاعات مفید از آن است.
این کار درواقع یک نوع تبدیل سیگنال است که ورودی آن تصویر است، مانند ( ویدئوها و عکس ها ) و خروجی ها ممکن است تصویر یا ویژگی های مرتبط با آن تصویر باشند.
امروزه با پیشرفت و توسعه سریع تکنولوژی، پردازش تصویر کاربرد بیشتری در جنبه های مختلف کسب و کار و علوم مهندسی و علوم کامپیوتر از خود به نمایش گذاشته است.
پردازش تصویر اساسا شامل سه مرحله زیر است:
۱) گرفتن تصویر با اسکنر های نوری یا با دوربین ها و حسگرهای دیجیتال.
۲) تجزیه و تحلیل و دستکاری تصویر ، شامل: فشرده سازی داده ها ، ترمیم تصویر و استخراج اطلاعات خاص از تصویر توسط فرآیند پردازش تصویر.
۳) آخرین مرحله که در آن نتیجه خروجی می تواند تصویر یا گزارشی از اطلاعاتی که در مرحله تجزیه و تحلیل تصویر در مرحله قبل بدست آمد، باشد.
عملیات اصلی در پردازش تصویر :
تبدیلات هندسی: همانند تغییر اندازه، چرخش و…
رنگ: همانند تغییر روشنایی، وضوح و یا تغییر فضای رنگ
ترکیب تصاویر: ترکیب دو یا چند تصویر
فشرده سازی پرونده: کاهش حجم تصویر
ناحیه بندی پرونده: تجزیهٔ تصویر به نواحی با معنی
بهبود کیفیت پرونده: کاهش نویز، افزایش کنتراست، اصلاح گاما و …
سنجش کیفیت تصویر
ذخیره سازی اطلاعات در تصویر
انطباق تصاویر
هدف از پردازش تصویر :
هدف از پردازش تصویر را می توان به ۴ گروه تقسیم کرد.
۱٫ تشدید تصویر و بهبود
۲٫ بازیابی تصویر
۳٫ اندازه گیری الگو
۴٫ تشخیص تصویر
پردازش تصویر با نرم افزار MATLAB :
از جمله نرم افزار های قوی و توانمند در خصوص پردازش تصویر به نرم افزار متلب می توان اشاره کرد که دانستن دانش آن برای متخصصین گرایش های مختلف علوم مهندسی و پزشکی هر روز پررنگ تر می شود.
کاربردهای پردازش تصویر :
ابتدایی ترین کاربردهای پردازش تصاویر رقومی در دهه ۶۰ و۷۰ جنبه های نظامی و جاسوسی بود که باعث شد نیاز به تصاویر با کیفیت بالاتر بوجود آید. پس از آن مصارف دیگری برای تصاویر رقومی سطح زمین پیدا شد که کاربرد تصاویر چند طیفی (Multi Spectral) در کشاورزی و جنگل داری از آن جمله است. همچنین با استفاده از تصاویر رقومی عملیاتهایی مثل کنکاش نفت در سرزمین های دور افتاده و یا ردیابی منابع آلودگی شهری از داخل دفتر کار متخصصین آنها انجام شد.
بزودی کاربردهای زمینی زیادتری برای پردازش تصاویر رقومی پیدا شد . از اواسط دهه ۷۰ تا اواسط دهه ۸۰ اختراع اسکنر ها ی CAT یا (Computerized Arial Topography ) و اسکنر های MRI یا (Magnetic Resonance Imagery ) پزشکی را متحول کردند. صنعت چاپ استفاده کننده بعدی بود. در اواخر دهه ۸۰ پردازش تصاویر رقومی وارد دنیای سرگرمی شد بطوریکه امروزه این نقش به امر عادی تبدیل شده است. بهمین ترتیب دنیای صنعت با روباتهایی که عملا می بینند یعنی در واقع با ظهور تکنولوژی Machine Vision متحول شد و هنوز هم در حال تحول است.
هر ساله با سریعتر و ارزانتر شدن کامپیوتر ها و ایجاد امکان پخش تصاویر با استفاده از تکنولوژی ارتباطات، افراد بیشتری به این تصاویر دسترسی پیدا می کنند. کنفرانس های ویدئویی یک روش زنده برای انجام کسب و کار شده اند و کامپیوترها ی خانگی توانایی نمایش و مدیریت تصاویر را به خوبی پیدا کرده اند. خوشبختانه با بالاتر رفتن سرعت پردازش و فضای حافظه کامپیوترها دیگر از بابت امکانات پردازش تصاویر نگرانی ها کمتر شده است و روز به روز این روند رو به رشد ادامه پیدا می کند.
با استفاده از پردازش تصویر، شمارش و اندازه گیری اشیا، تشخیص عیوب، تشخیص ترک، دسته بندی اشیا و عملیات بیشمار دیگری را انجام میدهند:
۱٫ اندازه گیری و کالیبراسیون
۲٫ جداسازی پینهای معیوب
۳٫ بازرسی لیبل و خواندن بارکد
۴٫ بازرسی عیوب چوب
۵٫ بازرسی قرص و بلیسترها
۶٫ بازرسی و دسته بندی
۷٫ درجه بندی و دسته بندی کاشی
۸٫ بازرسی و درجه بندی میوه
۹٫ بازرسی عیوب ورق های فلزی، پلیمری و …
۱۰٫ بازرسی لوله ها
۱۱٫ میکروسکوپ های دیجیتال
۱۲٫ اسکن سه بعدی
۱۳٫ بازرسی کمی بطری ها
۱۴٫ هدایت روبات ها
کاربرد پردازش تصویر در اتوماسیون صنعتی
با استفاده از تکنیکهای پردازش تصویر میتوان دگرگونی اساسی در خطوط تولید ایجاد کرد. بسیاری از پروسههای صنعتی که تا چند دهه پیش پیاده سازیشان دور از انتظار بود، هم اکنون با بهرگیری از پردازش هوشمند تصاویر به مرحله عمل رسیدهاند. از جمله منافع کاربرد پردازش تصویر به شرح زیر است.
پردازش تصویر روشی برای تبدیل یک تصویر به صورت دیجیتال و انجام برخی از عملیات بر روی آن، به منظور دریافت یک تصویر بهبود یافته و یا برای استخراج برخی از اطلاعات مفید از آن است.
تاریخچه:
در اوايل دهه 60 سفينه فضايي رنجر 7 متعلق به ناسا شروع به ارسال تصاوير تلويزيوني مبهمي از سطح ماه به زمين کرد. استخراج جزئيات تصوير براي يافتن محلي براي فرود سفينه آپولو نيازمند اعمال تصميماتي روي تصاوير بود. اين کار مهم به عهده لابراتوار Jet Propulsion قرار داده شد. بدين ترتيب زمينه تخصصي پردازش تصاوير رقومي آغاز گرديد و مثل تمام تکنولوژي های ديگر سريعاً استفاده هاي متعدد پيدا کرد.
از سال 1964 تاكنون، موضوع پردازش تصوير، رشد فراواني كرده است. علاوه بر برنامه تحقيقات فضايي، اكنون از فنون پردازش تصوير، در موارد متعددي استفاده مي شود. براي نمونه در پزشكي شيوه هاي رايانه اي Contrast تصوير را ارتقا مي دهند يا اين كه براي تعبير آسانتر تصاوير اشعه ايكس يا ساير تصاوير پزشكي، سطوح شدت روشنايي را با رنگ، نشانه گذاری می کنند. متخصصان جغرافيايي نيز از اين روش ها يا روش هاي مشابه براي مطالعه الگوهاي آلودگي هوا كه با تصوير برداري هوايي و ماهواره اي بدست آمده است، استفاده مي كنند. در باستان شناسی برای تصویربرداری سه بعدی از اجسام و فسیل ها مورد استفاده قرار می گیرد. در موزه های نيز روش هاي پردازش تصوير براي بازيابي عكس هاي مات شده اي كه تنها باقي مانده آثار هنري نادر هستند، مورد استفاده قرار مي گيرد. كاربردهاي موفق ديگري از پردازش تصوير را نيز مي توان در نجوم، زيست شناسي، پزشكي هسته ای، صنعت بيان كرد. پردازش تصویر در صنایع مختلف از جمله صنايع هوافضا،صنایع بستهبندي و چاپ، صنايع خودرو، داروسازي و پزشكي، صنايع الكترونيك، صنايع غذايي، صنایع فولاد، آلومينيوم، مس و …،صنایع سلولوزي(كاغذ، مقوا، كارتن)، صنایع لوله، پروفيل فلزي، لوله پليمري و كابل، صنایع منسوجات (پارچه، موكت، فرش و بافتههاي صنعتي)، صنایع كاشي، سراميك کاربردهای فراوانی دارد.
پردازش تصویر اساسا شامل سه مرحله زیر است.
گرفتن تصویر با اسکنر های نوری یا با دوربین ها و حسگرهای دیجیتال.
تجزیه و تحلیل تصویر که شامل فشرده سازی اطلاعات، بهبود تصویر، تشخیص الگوها
آخرین مرحله خروجی است که می تواند تصویر یا گزارش باشد که از نتیجه تجزیه و تحلیل تصویر حاصل شده است.
هدف از پردازش تصویر
هدف از پردازش تصویر را می توان به 4 گروه تقسیم کرد.
1. تشدید تصویر و بهبود
2. بازیابی تصویر
3. اندازه گیری الگو
4. تشخیص تصویر
انواع پردازش تصویر
دو نوع از روش های مورد استفاده برای پردازش تصویر پردازش تصویر آنالوگ و دیجیتال می باشد. تکنیک های بصری آنالوگ از پردازش تصویر را برای نسخه های سخت مانند چاپ و عکس استفاده می شود و پردازش تصویر دیجیتال که امروز بیشتر شناخته شده است دارای کاربردهای متعددی از تجزیه و تحلیل تصاویر ماهوارهای تا کنترل ابعادی قطعات میکروسکوپی می باشد.
ماشین بینایی و پردازش تصویر در اتوماسیون صنعتی
کنترل ماشین آلات و تجهیزات صنعتی یکی از وظایف مهم در فرآیندهای تولیدی است. بکارگیری کنترل خودکار و اتوماسیون روزبه روز گسترده تر شده و رویکردهای جدید با بهره گیری از تکنولوژیهای نو امکان رقابت در تولید را فراهم میسازد. لازمه افزایش کیفیت و کمیت یک محصول، استفاده از ماشین آلات پیشرفته و اتوماتیک میباشد. ماشین آلاتی که بیشتر مراحل کاری آنها به طور خودکار صورت گرفته و اتکای آن به عوامل انسانی کمتر باشد. امروزه استفاده از تکنولوژی ماشین بینایی و تکنیکهای پردازش تصویر کاربرد گستردهای در صنعت پیدا کردهاست و کاربرد آن بویژه در کنترل کیفیت محصولات تولیدی، هدایت روبات و مکانیزمهای خود هدایت شونده روز به روز گسترده تر میشود.
عدم اطلاع کافی مهندسین از تکنولوژی ماشین بینایی و عدم آشنایی با توجیه اقتصادی بکارگیری آن موجب شدهاست که در استفاده از این تکنولوژی تردید و در بعضی مواقع واکنش منفی وجود داشته باشد. علی رغم این موضوع، ماشین بینایی روز به روز کاربرد بیشتری پیدا کرده و روند رشد آن چشمگیر بودهاست. عملیات پردازش تصویر در حقیقت مقایسه دو مجموعه عدد است که اگر تفاوت این دو مجموعه از یک محدوده خاص فراتر رود، از پذیرفتن محصول امتناع شده و در غیر اینصورت محصول پذیرفته میشود. در زیر پروژههایی که در زمینه پردازش تصاویر پیاده سازی شدهاست، توضیح داده میشود. این پروژهها با استفاده از پردازش تصویر، شمارش و اندازه گیری اشیا، تشخیص عیوب، تشخیص ترک، دسته بندی اشیا و عملیات بیشمار دیگری را انجام میدهند:
https://behsanandish.com/wp-content/uploads/2019/08/tozin-300x300-2.jpg288288dalirihttps://behsanandish.com/wp-content/uploads/2020/09/logo-farsi-englisi-300x195-1.pngdaliri2019-10-01 14:30:092019-10-01 14:30:09نرم افزار باسکول بهسان توزین در شرکت کاروان جنوب
https://behsanandish.com/wp-content/uploads/2018/06/taradod1.jpg288288dalirihttps://behsanandish.com/wp-content/uploads/2020/09/logo-farsi-englisi-300x195-1.pngdaliri2019-09-28 14:30:002019-09-28 14:30:00سامانه کنترل تردد خودرو در شهرک صنعتی سجزی
https://behsanandish.com/wp-content/uploads/2018/06/taradod1.jpg288288dalirihttps://behsanandish.com/wp-content/uploads/2020/09/logo-farsi-englisi-300x195-1.pngdaliri2019-09-22 13:26:132019-09-22 13:26:13اجرای سامانه کنترل تردد در مجتمع مس سرچشمه
استفاده از حس گرها برای دریافت سیگنال هایی که تشکیل دهنده تصویر یک شی هستند که توسط کامپیوتر و یا سایر وسایل پردازش سیگنال برای تفسیر و تحلیل سیگنالهای دریافت شده از قطعه مورد استفاده قرار می گیرد. ماشین بینایی به عنوان یک ابزار مهندسی در ابزارهای دیجیتال و در شبکههای کامپیوتری، برای کنترل ابزارهای صنعتی دیگر از قبیل کنترل بازوهای روبات و یا خارج کردن تجهیزات معیوب به کار می رود.
در حقیقت ماشین بینایی شاخه ای از علم مهندسی است که به رشتههای علوم کامپیوتری (Computer science) و علم نورشناسی و مهندسی مکانیک و اتوماسیون صنعتی ارتباط دارد. یکی از مهمترین پر استفادهترین کاربردهای آن در بازبینی و بررسی کالاهای صنعتی از جمله نیمه هادیها، اتومبیل ها، مواد خوراکی و دارو می باشد. همانند نیروی انسانی که با چشم غیر مسلح در خط تولید کالاها را برای تعیین کیفیت و نوع ساخت آنها بازبینی می کنند، ماشین بینایی از دوربینهای دیجیتال و دوربینهای هوشمند و نرمافزارهای image processing (پردازش تصویر) برای این کار استفاده می کند.
دستگاههای مربوطه (ماشین بینایی) برای انجام دادن وظایفی خاص از جمله شمردن اشیاء در بالابرها، خواندن شماره سریالها (Serial numbers)، جستجوی سطحهای معیوب به کار می روند. در حال حاضر صنعت استفاده زیادی از سیستم ماشین بینایی برای بازبینی تصویری اشیاء (Visual inspection) که نیاز به سرعت بالا و دقت بالا و کار 24 ساعته و تکرار محابات بالا دارد، وجود دارد.
اگرچه انسان عملکرد بهتر و قابلیت تطبیق دهی بیبشتری برای خطاهای تازه در زمان کوتاه دارد ولی با توجه به ویژگیهای ذکر شده این دستگاهها به مرور جای نیروی انسانی را که به دلیل انحراف و شرایط بد دارای خطا می باشند، در صنعت پر می کند. کامپیوترها به همان صورتی که انسان می بیند نمی توانند ببینند. دوربینها همانند سیستم بینایی انسان نیستند و در حالی که انسان می تواند بر استنباط و فرضیات اتکا کند، تجهیزات کامپیوتری باید به وسیله آزمودن و تجزیه و تحلیل کردن جداگانه پیکسلها و تلاش کردن برای انجام نتیجه گیری با توجه به پشتوانه اطلاعاتی و روش هایی مانند شناسایی الگو مشاهده کنند.
علی رغم اینکه بعضی الگوریتمهای ماشین بینایی برای تقلید کردن از سیستم بینایی انسان توسعه یافته اند، تعداد معدودی روش برای تحلیل و شناسایی ویژگیهای مرتبط تصاویر به صورت مؤثر و ثابت توسعه یافته اند. سیستمهای Machine vision و computer vision قادر هستند به صورت ثابت تصاویر را تجزیه و تحلیل کنند، ولی image processing بر پایهٔ کامپیوتر به صورت کلی برای انجام کارهای تکراری طراحی می شوند و علی رغم پیشرفتهای صورت گرفته در این زمینه، هیچ سیستم machine vision و computer vision قادر نیست با برخی از ویژگیهای سیستم بینایی انسان در قالب درک تصویر، تلرانس به تغییرات نور، تضعیف قدرت تصویر و تغییرات اجزا و… تطبیق پیدا کند.
اجزای یک ماشین بینایی
اگرچه ماشین بینایی بیشتر به عنوان یک پروسهٔ به کار بستنٍ “Machine vision” در کاربردهای صنعتی شناخته شده است، برای لیست کردن اجزای سختافزاری و نرمافزاری به کار برده شده نیز مفید می باشد. معمولاً یک ماشین بینایی از اجزای زیر ساخته میشود :
1. یک و یا چند دوربین دیجیتال یا آنالوگ ( سیاه-سفید یا رنگی ) با اپتیک مناسب برای گرفتن عکس.
2. واسطه ای که عکسها را برای پردازش آماده می سازد. برای دوربینهای آنالوگ این واسطه شامل یک دیجیتال کننده عکس است. هنگامی که این واسطه یک سختافزارٍ جدا باشد، به آن Frame grabber ( کارتی که برای دریافت سیگنال تصویری و فرستادن آن به کامپیوتر استفاده می شود)می گویند.
3. یک پردازشگر ( گاهی یک PC یا پردازنده تعبیه شده ( Embedded Processor ) مانند DSP
4. نرمافزار ماشین بینایی : این نرمافزار امکاناتی برای توسعه یک برنامه نرمافزاری که برای کاربردی مشخص است را فراهم می کند.
5. سختافزار ورودی / خروجی ( مثلا I/O دیجیتال ) یا حلقههای ارتباطی ( مثلا ارتباط شبکه ای یا RS-232 ) برای گزارش نتایج.
6. یک دوربین هوشمند : یک وسیله ساده که همه موارد فوق را داراست.
7. لنزهایی که بتواند به مقدار مطلوبی روی سنسور تصویر زوم کند.
8. منابع نوری مناسب و گاهی خیلی مخصوص ( مثلا چراغهای LED، فلورسنت، لامپهای هالوژن و . . . )
9. یک برنامهٔ مشخص که بتواند تصاویر را پردازش کرده و مشخصههای مربوط و مناسب را شناسایی کند.
10. یک سنسور همزمان ساز برای شناسایی اجزا ( گاهی یک سنسور نوری و یا یک سنسور مغناطیسی ) : این سنسور برای راه اندازی سیستمٍ استخراج و پردازش تصویر می باشد.
سنسور همزمان ساز تعیین میکند که چه زمانی یک بخش ( که معمولاً روی یک حمل کننده حرکت می کند) در موقعیتی قرار گرفته است که باید مورد بررسی واقع شود. این سنسور هنگامیکه از زیر دوربین می گذرد و یک پالس نوری برای ثابت نگهداشتن تصویر ایجاد میکند، دوربین را برای گرفتن عکس فعال می کند. نوری که برای روشن کردن آن بخش به کار می رود در واقع برای آن است که مشخصههای مطلوب را برجسته و مشخصات نامطلوب ( مثل سایهها و یا انعکاس ها) را به حداقل برساند. معمولاً پنلهای LED با اندازه و طراحی مناسب برای این هدف مورد استفاده قرار می گیرند. تصویر دوربین یا توسط یک frame grabber و یا توسط یک حافظه کامپیوتری (که در آن از frame grabber استفاده نشده است) گرفته می شود.
frame grabber یک وسیله دیجیتال کننده است ( یا در داخل دوربین هوشمند و یا بطور جداگانه) که خروجی دوربین را به فرمت دیجیتال تبدیل کرده ( معمولاً این فرمت از یک آرایه دو بعدی از اعداد تشکیل شده که هر عدد متناظر شدت روشنایی نقطه متناظر در آن تصویر می باشد. به این نقاط پیکسل می گویند.) و سپس تصویر را به منظور پردازش توسط نرمافزارٍ ماشین بینایی در حافظه کامپیوتر ذخیره می کند. به طور معمول نرمافزار، اقدامات متفاوتی را برای پردازش تصویر انجام می دهد. گاهی در ابتدا تصویر برای کاهش نویز و یا تبدیل سایههای خاکستری به ترکیب ساده ای از رنگهای سیاه و سفید دستکاری میشود ( Binarization ).
در قدم بعدی نرمافزار عمل شمردن، اندازه گیری و شناسایی اجسام، ابعاد، کاستیها و مشخصات دیگر تصویر را انجام می دهد. در نهایت با توجه به ضوابط و معیارهای برنامه ریزی شده ممکن است بخشی را بپذیرد و یا رد کند. اگر یک بخش رد شد، نرمافزار به یک دستگاه مکانیکی فرمان می دهد تا آن بخش را خارج کند و همچنین سیستم خط تولید را قطع کرده و به کارگر هشدار می دهد تا مشکلی که باعث ایجاد خطا شده را رفع نماید. اگرچه اکثر ماشین بینایی ها بر مبنای دوربینهای سیاه–سفید بنا نهاده شده اند، استفاده از دوربینهای رنگی در حال رایج شدن است.
همچنین امروزه شاهد شیوع فراوان استفاده از تجهیزات دوربینهای دیجیتال به جای یک دوربین و یک frame grabber جداگانه در ماشین بینایی هستیم. استفاده از یک دوربین دیجیتال به منظور برقراری ارتباط مستقیم، باعث صرفه جویی در هزینه و نیز سادگی سیستم خواهد شد. دوربینهای هوشمند که در داخل آنها embedded processorها تعبیه شده اند، در حال تسخیر سهم بالایی از بازار ماشین بینایی ها هستند. استفاده از یک embedded processor ( و یا یک پردازنده بهینه ) نیاز ما به frame grabber و یک کامپیوتر خارجی را از بین می برد. به همین خاطر این پردازندهها باعث کاهش هزینه، کاهش پیچیدگی سیستم و همچنین اختصاص توان پردازشی مشخص به هر دوربین می شود. دوربینهای هوشمند معمولاً ارزان تر از سیستمهای شامل یک دوربین و یک برد و یک کامپیوتر خارجی هستند. همچنین توان بالای embedded processor و DSPها منجر به بالا رفتن عملکرد و توانایی آنها نسبت به سیستمهای مرسوم ( که بر مبنای PC هستند ) شده است. منبع
در ادامه معرفی الگوریتمهای ضروری یادگیری ماشین، به بررسی مفاهیم پایه درخت تصمیم می پردازیم که یکی از الگوریتمها و روشهای محبوب در حوزه طبقهبندی یا دستهبندی دادهها، است و در این مقاله سعی شده است به زبان ساده و بهدوراز پیچیدگیهای فنی توضیح داده شود. درخت تصمیم که هدف اصلی آن، دستهبندی دادههاست، مدلی در دادهکاوی است که مشابه فلوچارت، ساختاری درختمانند را جهت اخذ تصمیم و تعیین کلاس و دسته یک داده خاص به ما ارائه میکند. همانطور که از نام آن مشخص است، این درخت از تعدادی گره و شاخه تشکیلشده است بهگونهای کهبرگها کلاسها یا دستهبندیها را نشان میدهند و گرههای میانی هم برای تصمیمگیری با توجه به یک یا چند صفت خاصه بهکارمیروند. در زیر ساختار یک درخت تصمیم جهت تعیین نوع بیماری (دسته) بر اساس نشانگان مختلف، نمایش دادهشده است:
درخت تصمیم یک مدل خودتوصیف است یعنی بهتنهایی و بدون حضور یک فرد متخصص در آن حوزه، نحوه دستهبندی را به صورت گرافیکی نشان میدهد و به دلیل همین سادگی و قابلفهم بودن، روش محبوبی در دادهکاوی محسوب میشود. البته به خاطر داشته باشید در مواردی که تعداد گرههای درخت زیاد باشد، نمایش گرافیکی و تفسیر آن میتواند کمی پیچیده باشد.
برای روشن شدن مطالب، به مثال زیر توجه کنیدکه در آن قصد داریم به کمک ساخت یک درخت تصمیم، بازیکردن کریکت را برای یک دانشآموز، پیشبینی کنیم:
فرض کنید نمونهای شامل ۳۰ دانشآموز با سه متغیر جنسیت (پسر/ دختر)، کلاس (X / IX) و قد (۵ تا ۶ فوت) داریم. ۱۵ نفر از ۳۰ نفر در اوقات فراغت خود کریکت بازی میکنند. حال میخواهیم با بررسی خصوصیات این پانزده نفر، پیشبینی کنیم چه کسانی در اوقات فراغت خود کریکت بازی میکنند.برای این کار ابتدا باید براساس خصوصیات ۱۵ نفری که کریکت بازی میکنند، یک الگو برای دستهبندی به دست آوریم. از آنجا که درخت تصمیم یک ساختار سلسله مراتبی شرطی دارد (شکل فوق) و در هر مرحله باید بر اساس مقدار یک خصوصیت تصمیم بگیریم، مهمترین کاری که در ساخت این درخت تصمیم باید انجام دهیم، این است که تعیین کنیم کدام خصوصیت دادهها، تفکیککنندگی بیشتری دارد. سپس این خصوصیتها را اولویتبندی کرده و نهایتاً با لحاظ این اولویتها از ریشه به پایین در اتخاذ تصمیم، ساختاری درختمانند برای دستهبندی دادهها بنا کنیم. الگوریتمهای مختلف ساخت درخت تصمیم، مهم-ترین تفاوتی که با هم دارند، در انتخاب این اولویت و روشی است که برای انتخاب اولویت خصوصیتها در نظر میگیرند.
برای سنجش میزان تفکیککنندگی یک خصوصیت، سادهترین روش این است که دانشآموزان را براساس همهٔ مقادیر هر سه متغیر تفکیک کنیم. یعنی مثلاً ابتدا بر اساس جنسیت، دادهها را جدا کنیم و سپس مشخص کنیم چند نفر از دختران و چندنفر از پسران، کریکت بازی میکنند. سپس همین کار را برای قد و کلاس تکرار کنیم. با این کار، میتوانیم درصد بازیکنان هر مقدار از یک خصوصیت (درصد بازیکنان دختر از کل دخترها و درصد بازیکنان پسر از کل پسرها) را محاسبه کنیم. هر خصوصیتی که درصد بیشتری را تولید کرد، نشانگر تفکیککنندگی بیشتر آن خصوصیت (و البته آن مقدار خاص) است.
جور دیگری هم به این موضوع میتوان نگاه کرد: این متغیر، بهترین مجموعه همگن از دانشآموزان از لحاظ عضویت در گروه بازیکنان را ایجاد میکند یعنی در گروه بازیکنان، بیشترین خصوصیتی که بین همه مشترک است، پسر بودن است. میزان همگنی و یکنواختی ایجاد شده توسط هر خصوصیت هم، شکل دیگر میزان تفکیککنندگی آن خواهد بود.
در تصویر زیر شما میتوانید مشاهده کنید که متغیر جنسیت در مقایسه با دو متغیر دیگر، قادر به شناسایی بهترین مجموعهٔ همگن هست چون میزان مشارکت دانشآموزان پسر دربازی کریکت ۶۵ درصد است که از تمام متغیرهای دیگر بیشتر است:
برای متغیر قد که یک متغیر عددی بود از یک نقطه معیار که میتواند میانگین قد افراد باشد، استفاده کردیم. کار با متغیرهای عددی در درخت تصمیم را در ادامه، به تفصیل مورد بررسی قرار خواهیم داد. همانطور که در بالا ذکر شد، الگوریتمهای ساخت درخت تصمیم، تفکیککنندهترین متغیر که دستههای بزرگتری از دادهها را براساس آن میتوانیم ایجاد کنیم یا به عبارت دیگر، بزرگترین مجموعهٔ همگن از کل دادهها را ایجاد میکند، شناسایی میکنند، سپس به سراغ متغییر تفکیککننده بعدی میروند و الی آخر تا بر اساس آنها، ساختار درخت را مرحله به مرحله بسازند. حال سؤالی که پیش میآید این است که در هر مرحله، چگونه این متغیر شناساییشده و عمل تقسیم انجام گیرد؟ برای انجام این کار، درخت تصمیم از الگوریتمهای متنوعی استفاده میکند که در بخشهای بعدی به آنها خواهیم پرداخت.
درخت تصمیم چگونه کار میکند؟
در درخت تصمیم با دنبال کردن مجموعهای از سوالات مرتبط با خصوصیات دادهها و نگاه به داده جاری برای اتخاذ تصمیم، طبقه یا دسته آنرا تعیین میکنیم. در هر گره میانی درخت، یک سؤال وجود دارد و با مشخص شدن پاسخ هر سؤال به گره مرتبط با آن جواب میرویم و در آنجا هم سؤال دیگری پرسیده میشود.
هدف از الگوریتمهای درخت تصمیم هم انتخاب درست این سؤالات است به گونهای که یک دنباله کوتاه از سؤالات برای پیشبینی دستهٔ رکورد جدید تولید کنند.
هر گره داخلی متناظر با یک متغیر و هر یال، نمایانگر یک مقدار ممکن برای آن متغیر است. یک گره برگ، مقدار پیشبینیشدهٔ متغیر هدف (متغیری که قصد پیشبینی آنرا داریم)، را نشان میدهد یعنی برگها نشاندهندهٔ دستهبندی نهایی بوده و مسیر پیموده شده تا آن برگ، روند رسیدن به آن گره را نشان میدهند.
فرآیند یادگیری یک درخت که در طی آن، گرهها و یالها مشخص میشوند و درادامه به آن خواهیم پرداخت، معمولاً با بررسی مقدار یک خصوصیت در مرحله اول، به تفکیک کردن مجموعه داده به زیرمجموعههایی مرتبط با مقدار آن صفت، کار خود را شروع میکند. این فرآیند به شکل بازگشتی در هر زیرمجموعهٔ حاصل از تفکیک نیز تکرار میشود یعنی در زیرمجموعهها هم مجدداً براساس مقدار یک صفت دیگر، چند زیرمجموعه ایجاد میکنیم. عمل تفکیک، زمانی متوقف میشود که تفکیک بیشتر، سودمند نباشد یا بتوان یک دستهبندی را به همه نمونههای موجود در زیرمجموعهٔ بهدستآمده، اعمال کرد. در این فرآیند، درختی که کمترین میزان برگ و یال را تولید کند، معمولاً گزینه نهایی ما خواهد بود.
انواع متغیرها در درخت تصمیم
در مسائل مرتبط با درختهای تصمیم با دو نوع کلی از متغیرها مواجه هستیم:
متغیرهای عددی یا پیوسته: مانند سن، قد، وزن و… که مقدار خود را از مجموعهٔ اعداد حقیقی میگیرند.
متغیرهای ردهای یا گسسته : مانند نوع، جنس، کیفیت و… که بهصورت دو یا چند مقدار گسسته هستند. در مواردی مانند آیا این شخص دانشآموز است؟ که دو جواب بله و خیر داریم، این متغیر از نوع طبقهای خواهد بود.
از طرفی میتوانیم متغیرها را به دون گروه کلی، متغیرهای مستقل و متغیرهای وابسته تقسیم کنیم. متغیرهای مستقل، متغیرهایی هستند که مقدار آنها، مبنای تصمیم گیری ما خواهند بود و متغیر وابسته، متغیری است که بر اساس مقدار متغیرهای مستقل، باید مقدار آنرا پیشبینی کنیم. متغیرهای مستقل با گرههای میانی نشان داده میشوند و متغیرهای وابسته، با برگ نشان داده میشوند. حال هر یک از این دو نوع متغیر مستقل و وابسته، میتواند گسسته یا پیوسته باشد. چنانچه متغیری وابستهٔ عددی باشد دسته بندی ما یک مسالهٔ رگرسیون و چنانچه طبقهای باشد، دسته بندی از نوع، ردهبندی (Classification) است. به عبارتی دیگر، هنگامیکه خروجی یک درخت، یک مجموعه گسسته از مجموعه مقادیر ممکن است؛ به آن درخت دستهبندی میگوییم (مثلاً مؤنث یا مذکر، برنده یا بازنده). این درختها تابع X→C را بازنمایی میکنند که در آن C مقادیر گسسته میپذیرد. هنگامیکه بتوان خروجی درخت را یک عدد حقیقی در نظر گرفت آن را، درخت رگرسیون مینامیم (مثلاً قیمت خانه یا طول مدت اقامت یک بیمار در یک بیمارستان). این درختان اعداد را در گرههای برگ پیشبینی میکنند و میتوانند از مدل رگرسیون خطی یا ثابت (یعنی میانگین) یا مدلهای دیگر استفاده کنند. وظیفهٔ یادگیری در درختان رگرسیون، شامل پیشبینی اعداد حقیقی بجای مقادیر دستهای گسسته است که این عمل را با داشتن مقادیر حقیقی در گرههای برگ خود نشان میدهند. بدینصورت که میانگین مقادیر هدف نمونههای آموزشی را در این گره برگ به دست میآورند. این نوع از درختان، تفسیر آسان داشته و میتوانند توابع ثابت تکهای را تقریب بزنند.
درخت CART (Classification And Regression Tree) نامی است که به هر دو روال بالا اطلاق میشود. نام CART سرنام کلمات درخت رگرسیون و دستهبندی است. البته نوع دیگری از درختهای تصمیم هم داریم که برای خوشهبندی (clustering) دادهها به کار میروند و به دلیل کاربرد محدود، در این مجموعه مقالات به آنها نخواهیم پرداخت (بیشتر تحقیقات در یادگیری ماشین روی درختان دستهبندی متمرکز است).
اصطلاحات مهم مربوط به درخت تصمیم
در این بخش به معرفی اصطلاحات مهم در حوزهٔ کار با درخت تصمیم میپردازیم. گره ریشه: این گره حاوی تمام نمونههای موجود هست و سطح بعدی اولین تقسیم مجموعهٔ اصلی به دو مجموعهٔ همگنتر است. در مثال قبل، گره ریشه دارای ۳۰ نمونه است. گره تصمیم: زمانی که یک گره به زیرگرههای بعدی تقسیم میشود، آن را یک گره تصمیم مینامیم. برگ / گره پایانه: گرههایی که تقسیم نمیشوند یا به عبارتی تقسیم پیاپی از طریق آنها پایان مییابد، برگ یا گره پایانه نام دارند.
در تصویر زیر، گره ریشه (Root Node) با رنگ آبی، شاخه، انشعاب (Branch) یا به عبارتی زیر درخت (Sub-Tree) با رنگ گلبهی، تقسیم (Splitting) و هرس (Pruning) نمایش دادهشدهاند. برگها هم به رنگ سبز در انتهای شاخههای مختلف درخت، قرار گرفتهاند.
هرس کردن: هنگامیکه ما از یک گره تصمیم، زیر گرهها را حذف کنیم، این عمل هرس کردن نامیده میشود. درواقع این عمل متضاد عمل تقسیم کردن است.
انشعاب / زیردرخت: بخشی از کل درخت را انشعاب یا زیر درخت میگویند. گرههای پدر و فرزند: گرهای که به چندین زیر گره تقسیم میشود را گره والد یا گره پدر برای زیر گرههای آن میگویند. درحالیکه زیر گرههایی که والد دارند، بهعنوان گرههای فرزند شناخته میشوند.
این اصطلاحات، عبارات پرکاربردی در استفاده از درخت تصمیم هستند.
قبل از پرداختن به الگوریتمهای مختلف ساخت درخت تصمیم، به مزایا و معایب و ویژگیهای این نوع از مدلهای دستهبندی دادهها میپردازیم.
مزایا و معایب درخت تصمیم
مزایای درختان تصمیم نسبت به روشهای دیگر دادهکاوی
۱) قوانین تولیدشده و بهکاررفته شده قابلاستخراج و قابلفهم میباشند.
۲) درخت تصمیم، توانایی کار با دادههای پیوسته و گسسته را دارد. (روشهای دیگر فقط توان کار با یک نوع رادارند. مثلاً شبکههای عصبی فقط توان کار با دادههای پیوسته را دارد و قوانین رابطهای با دادههای گسسته کار میکنند)
۳) مقایسههای غیرضروری در این ساختار حذف میشود.
۴) از ویژگیهای متفاوت برای نمونههای مختلف استفاده میشود.
۵) احتیاجی به تخمین تابع توزیع نیست.
۶) آمادهسازی دادهها برای یک درخت تصمیم، ساده یا غیرضروری است. (روشهای دیگر اغلب نیاز به نرمالسازی داده یا حذف مقادیر خالی یا ایجاد متغیرهای پوچ دارند)
۷) درخت تصمیم یک مدل جعبه سفید است. توصیف شرایط در درختان تصمیم بهآسانی با منطق بولی امکانپذیر است درحالیکه شبکههای عصبی به دلیل پیچیدگی در توصیف نتایج آنها یک جعبه سیاه میباشند.
۸) تائید یک مدل در درختهای تصمیم با استفاده از آزمونهای آماری امکانپذیر است. (قابلیت اطمینان مدل را میتوان نشان داد)
۹) ساختارهای درخت تصمیم برای تحلیل دادههای بزرگ در زمان کوتاه قدرتمند میباشند.
۱۰) روابط غیرمنتظره یا نامعلوم را مییابند.
۱۱) درختهای تصمیم قادر به شناسایی تفاوتهای زیرگروهها میباشند.
۱۲) درختهای تصمیم قادر به سازگاری با دادههای فاقد مقدار میباشند.
۱۳) درخت تصمیم یک روش غیرپارامتریک است و نیاز به تنظیم خاصی برای افزایش دقت الگوریتم ندارد.
معایب درختان تصمیم
۱) در مواردی که هدف از یادگیری، تخمین تابعی با مقادیر پیوسته است مناسب نیستند.
۲) در موارد با تعداد دستههای زیاد و نمونه آموزشی کم، احتمال خطا بالاست.
۳) تولید درخت تصمیمگیری، هزینه محاسباتی بالا دارد.
۴) هرس کردن درخت هزینه بالایی دارد.
۵) در مسائلی که دستهها شفاف نباشند و همپوشانی داشته باشند، خوب عمل نمیکنند.
۶) در صورت همپوشانی گرهها تعداد گرههای پایانی زیاد میشود.
۷) درصورتیکه درخت بزرگ باشد امکان است خطاها از سطحی به سطحی دیگر جمع میشوند (انباشته شدن خطای لایهها و تاثیر بر روی یکدیگر).
۸) طراحی درخت تصمیمگیری بهینه، دشوار است و کارایی یک درخت دستهبندی کننده به چگونگی طراحی خوب آن بستگی دارد.
۹) احتمال تولید روابط نادرست وجود دارد.
۱۰) وقتی تعداد دستهها زیاد است، میتواند باعث شود که تعداد گرههای پایانی بیشتر از تعداد دستههای واقعی بوده و بنابراین زمان جستجو و فضای حافظه را افزایش میدهد.
مقایسه درخت تصمیم و درخت رگرسیون
تا اینجا متوجه شدیم که درخت تصمیم ساختاری بالا به پایین دارد و بر خلاف تصوری که از یک درخت داریم، ریشه در بالای درخت قرارگرفته و شاخهها مطابق تصویر در پایین هستند.
هر دو نوع درخت تصمیم و رگرسیون تقریباً مشابه هستند. در زیر به برخی شباهتها و تفاوتهای بین این دو میپردازیم:
ویژگیهای درخت رگرسیون و درخت دستهبندی:
• زمانی که متغیر هدف ما پیوسته و عددی باشد، از درخت رگرسیون و زمانی که متغیر هدف ما گسسته یا غیرعددی باشد، از درختان تصمیم استفاده میکنیم.
• معیار تقسیم و شاخه زدن در درختان رگرسیون بر اساس معیار خطای عددی است.
• گرههای برگ در درختان رگرسیون حاوی مقادیر عددی هستند که هر عدد، میانگین مقادیر دستهای است که داده جاری، بیشترین شباهت را با آنها داشته است اما در درختان تصمیم، مقدار برگ، متناظر با دستهایست که بیشترین تکرار را با شرایط مشابه با داده داده شده، داشته است.
ن هر دو درخت، رویکرد حریصانهٔ بالا به پایین را، تحت عنوان تقسیم باینری بازگشتی دنبال میکنند. این روش از بالای درخت، جایی که همهٔ مشاهدات در یک بخش واحد در دسترس هستند شروع میشود و سپس تقسیم به دوشاخه انجامشده و این روال بهصورت پیدرپی تا پایین درخت ادامه دارد، به همین دلیل این روش را بالا به پایین میخوانیم. همچنین به این دلیل این روش را حریصانه میخوانیم که تلاش اصلی ما در یافتن بهترین متغیر در دسترس برای تقسیم فعلی است و در مورد انشعابات بعدی که به یک درخت بهتر منتهی شود، توجهی نداریم. (به عبارتی همواره بهترین انتخاب در لحظه، بهترین انتخاب در سراسر برنامه نیست و اثرات این تقسیم در تقسیمهای آینده را در نظر نمیگیرد). به یاد دارید که درروش حریصانه و در مورد کولهپشتی نیز مورد مشابه را دیدهایم. در شیوه حریصانه در هر مرحله عنصری که بر مبنای معیاری معین ((بهترین)) به نظر میرسد، بدون توجه به انتخابهای آینده، انتخاب میشود.
• در هر دو نوع درخت، در فرآیند تقسیم این عمل تا رسیدن به معیار تعریفشدهٔ کاربر برای توقف عملیات، ادامه دارد. برای مثال، ما میتوانیم به الگوریتم بگوییم که زمانی که تعداد مشاهدات در هر گره کمتر از ۵۰ شود، عملیات متوقف گردد.
• در هر دو درخت، نتایج فرآیند تقسیم، تا رسیدن به معیارهای توقف، باعث رشد درخت میشود. اما درخت کاملاً رشد یافته بهاحتمالزیاد باعث بیشبرازش دادهها (over fit) خواهد شد که در این صورت، شاهدکاهش صحت و دقت بر روی دادههای آینده که قصد دستهبندی آنها را داریم، خواهیم بود. در این زمان هرسکردن را بکار میبریم. هرس کردن، روشی برای مقابله با بیش-برازش دادههاست که در بخش بعد بیشتر به آن خواهیم پرداخت.
نحوهٔ تقسیم یک درخت تصمیم
تصمیمگیری دربارهٔ نحوهٔ ساخت شاخهها در یک درخت یا به عبارتی تعیین ملاک تقسیم بندی در هر گره، عامل اصلی در میزان دقت یک درخت است که برای درختهای رگرسیون و تصمیم، این معیار، متفاوت است.
درختهای تصمیم از الگوریتمهای متعدد برای تصمیمگیری دربارهٔ تقسیم یک گره به دو یا چند گره استفاده میکنند. در حالت کلی، هدف از ساخت هر زیرگره، ایجاد یک مجموعه جدید از دادههاست که با همدیگر همگن بوده و به هم شبیهترند اما نسبت به سایر شاخهها، قابل تفکیک و تمایز هستند بنابراین ایجاد زیر گرهها در هر مرحله، یکنواختی دادهها را در زیرگرههای حاصل افزایش میدهد. بهعبارتدیگر، خلوص گره در هر مرحله، با توجه به شباهت آن با متغیر هدف، افزایش مییابد. درخت تصمیم، گرهها را بر اساس همهٔ متغیرهای موجود تقسیمبندی میکند و سپس تقسیمی که بیشترین یکنواختی را در دادههای حاصل (همگن بودن) ایجاد کند، انتخاب میکند. شکل زیر، این مفهوم را به خوبی نشان میدهد.
انتخاب الگوریتم، به نوع متغیرهای هدف نیز بستگی دارد.
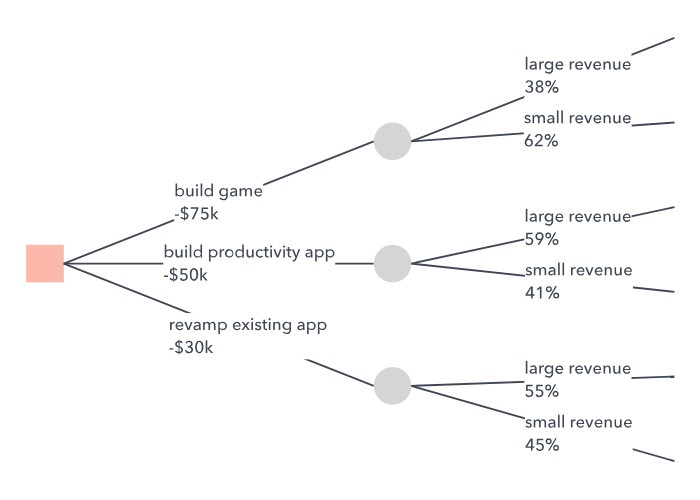
بگذارید برای تبیین بهتر مفهوم «درخت تصمیم (decision tree)» یک مثال کاربردی را بررسی کنیم؛ مدیریت شرکت «Stygian Chemical Industries, Ltd» میخواهد بین انتخاب این دو گزینه تصمیمگیری کند: ساخت یک واحد تولیدی کوچک یا یک واحد تولیدی بزرگ برای ساخت یک محصول شیمیایی با عمر بازار (market life) برابر با ده سال. توضیح اینکه اتخاذ این تصمیم مبتنی بر تخمین اندازه بازار در آینده است.
احتمالا تقاضا برای این محصول طی دو سال اول بسیار بالا باشد اما اگر مصرفکنندگان اولیه از محصول رضایت کافی نداشته باشند، تقاضا به تبع کاهش خواهد یافت. این احتمال نیز وجود دارد که تقاضای بالا در سالهای اولیه نشان از یک بازار پررونق دائمی باشد. اگر تقاضا بعد از دو سال همچنان بالا بماند و شرکت نتواند تولیدات را افزایش دهد، احتمالا شرکتهای رقیب به سرعت وارد بازار خواهند شد.
اگر شرکت یک واحد تولیدی با ظرفیت عظیم ایجاد کند، بدون توجه به رفتار بازار باید تا پایان ده سال با تولیدات زیاد کنار بیاید. اگر شرکت یک واحد تولیدی کوچک در اختیار داشته باشد و بازار بعد از دو سال رشد کند، مدیریت این انتخاب را خواهد داشت که ظرفیت را توسعه دهد. در صورتی که اندازه بازار بعد از دو سال اولیه رشد نکند، شرکت با ظرفیت کنونی ادامه خواهد داد.
هیئت مدیره با تردید و نگرانی زیادی دستوپنجه نرم میکند. شرکت طی سالهای 1۹4۰ تا 1۹۵۰ رشد مناسبی داشته و با سرعت مطابق با نیاز بازار رشد کرده است. اگر بازار محصول جدید واقعا بزرگ باشد این شانس برای شرکت وجود دارد تا به سرعت وارد عرصه عظیمی از سود سرشار گردد. مهندس پروژه توسعه (development project engineer) مصرانه به دنبال ترغیب مدیریت به ساخت واحد تولیدی با ظرفیت زیاد است. این واحد علاقه دارد اولین واحد غولپیکر طراحی شده توسط خود را به جهان معرفی نماید.
رئیس که خود یک سهامدار عمده نیز هست، نگران ایجاد ظرفیتی بیش از ظرفیت بازار به شرایط مینگرد. او مایل است ابتدا واحد کوچکتر تاسیس شود اما میداند هزینه توسعه ظرفیت در آینده بسیار زیاد و بهرهبرداری آن نیز مشکلتر از یک واحد یکدست بزرگ است. او همچنین میداند اگر نتواند به سرعت به اندازه نیاز بازار تولید کند، رقبا با کمال میل جای او را پر خواهند کرد.
مسئله کارخانه Stygian که کاملا سادهسازی شده، نشان از نگرانیها و چالشهایی است که مدیریت باید در اتخاذ تصمیمات مرتبط با سرمایهگذاری، با آنها روبهرو شود (در این مطلب از واژه سرمایهگذاری نه تنها برای ایجاد یک واحد تولیدی جدید بلکه به شکل عام برای ایجاد ساختمانهای بزرگ، هزینه سنگین تحقیقات و تصمیمات با ریسک بالا استفاده شده است). اهمیت تصمیمات همزمان و پیچیدگی آنها هر روز بیشتر میشود. خیل عظیم مدیران میخواهند بهتر تصمیم بگیرند، اما چگونه؟
در این نوشته در مورد مفهوم درخت تصمیم که ابزار بسیار مفیدی برای تصمیمگیری است، توضیح داده خواهد شد. درخت تصمیم بهتر از هر ابزار دیگری میتواند گزینههای ممکن، اهداف، سود مالی و اطلاعات مورد نیاز برای یک سرمایهگذاری را به مدیریت نشان دهد. در سالهای روبهرو درباره درخت تصمیم بسیار خواهیم شنید. به جز تازگی و خلاقیت نهفته در درخت تصمیم، این عبارت تا سالیان زیادی در کلیشه سخنان همیشگی مدیران وجود خواهد داشت.
نمایش گزینهها
بیایید خود را در یک صبح شنبه ابری تصور کنید که برای بعد از ظهر همان روز تعداد ۷۵ نفر را به صرف نوشیدنی دعوت کردهاید. خانه شما خیلی بزرگ نیست اما باغ چشمنواز جلوی آن میتواند در صورتی که هوا بارانی نشود، مهمانپذیر مناسبی باشد. در باغ به میهمانان بیشتر خوش میگذرد و شما رضایت بیشتری خواهید داشت. اما اگر ناگهان در بین جشن باران بگیرد، تدارکات از بین میرود و برای مهمانها و شما خاطرهای تلخ از روز شنبه باقی خواهد ماند (البته امکان پیچیدهتر کردن مسئله وجود دارد. برای مثال، امکان پیشبینی هوا بر اساس شرایط چند روز گذشته و امکان تدارک میهمانی در باغ و خانه به صورت همزمان را میتوان اضافه کرد. اما همین مسئله ساده کار ما را راه خواهد انداخت!).
این تصمیم خاص را میتوان در یک جدول انتخاب/نتیجه (payoff table) نشان داد.
انتخاب
باران بیاید
باران نیاید
برگزاری جشن در باغ
فاجعه
لذت فروان و به یاد ماندنی
برگزاری جشن در خانه
لذت نسبی، شادی
لذت نسبی، پشیمانی
سوالات بسیار پیچیده تصمیمگیری را میتوان در چنین جدولهایی خلاصه کرد. با اینحال، بهویژه برای تصمیمات پیچیده سرمایهگذاری روش مناسب دیگری برای بررسی اثرات و احتمالات تصمیمگیری به همراه نتایج وجود دارد: درخت تصمیم. پیر ماسی ( Pierre Massé)، مامور عالیرتبه آژانس تصمیمگیری برای تولیدات و تجهیزات فرانسه (Commissioner General of the National Agency for Productivity and Equipment Planning in France)، میگوید:
مشکل تصمیمگیری را نمیتوان به عنوان یک مشکل مجزا (چراکه تصمیمات کنونی بر اساس آنچه در آینده پیش خواهد آمد، اتخاذ میشوند) یا به شکل یک زنجیر متوالی از تصمیمات (به دلیل اینکه تحت تاثیر عدم اطمینانها، تصمیمات آینده مبتنی بر آنچه در طول زمان میآموزیم تغییر خواهند کرد) انگاشت. مشکل تصمیمگیری در واقع خود را به شکل یک درخت تصمیم نشان میدهد.
نگاره شماره یک، درخت تصمیم میهمانی را نشان میدهد. درخت در واقع راه دیگری برای نمایش جدول انتخاب/نتیجه است. با این حال درخت تصمیم راه بهتری برای نشان دادن احتمالات و اطلاعات تصمیمگیری در مسائل پیچیده است.
درخت از یک سری نقاط و شاخهها تشکیل شده است. در اولین نقطه از سمت چپ، میزبان امکان انتخاب برگزاری جشن را داخل یا بیرون از منزل دارد. هر شاخه نماینده یک اتفاق ممکن یا یک مرحله تصمیمگیری است. در انتهای هر شاخه یک نقطه وجود دارد که یک اتفاق محتمل – آمدن یا نیامدن باران- را نشان میدهد. پیامد هر اتفاق ممکن در منتهیالیه سمت راست یا نقطه پایانی هر شاخه آمده است.
در هنگام رسم یک درخت تصمیم، میتوان تصمیم یا عمل را با نقاط مربعشکل و اتفاقات محتمل را با نقاط دایرهایشکل نشان داد. از دیگر نمادها نیز میتوان استفاده کرد. برای نمونه شاخههای یکخطی یا دوخطی، حروف خاص و رنگهای مختلف میتوانند برای نشان دادن جزئیات مورد استفاده قرار گیرند. یک درخت تصمیم با هر اندازهای شامل: الف) انتخابها و ب) پیشامدهای محتمل یا نتیجه انتخابها است که تحت تاثیر احتمالات یا شرایط غیرقابل کنترلاند.
زنجیره تصمیم – پیشامد (Decision-event chains)
مثال قبل با اینکه تنها یک مرحله از تصمیمگیری را نشان میدهد، شامل پایههای ابتدایی تمام درختهای تصمیمگیری پیچیده است. بیایید نگاهی به شرایط پیچیدهتر بیندازیم.
شما قرار است در مورد تایید یا رد اختصاص بودجه به توسعه یک محصول تقویتشده تصمیمگیری کنید. اینکه در صورت موفقیت، اختصاص بودجه میتواند به شما مزیت بسیاری در رقابت با رقیبان اعطا کند نکتهای مثبت است. اما اگر نتوانید محصول خود را توسعه یا بهروزرسانی کنید، ضربه سختی از رقیبان در بازارهای مالی خواهید خورد. درخت تصمیم مربوط به این مسئله را در نگاره شماره دو میبینید.
در سمت چپ اولین تصمیم شما نشان داده شده است. در ادامه تصمیم برای اجرای پروژه، در صورتیکه توسعه موفقیتآمیز باشد، به مرحلهی دوم تصمیمگیری میرسید (نقطه A). با فرض عدم تغییرات عمده بین زمان حاضر و نقطه A، در این نقطه باید در مورد گزینههای مختلف تصمیمگیری نمایید. میتوانید تصمیم به عرضه محصول جدید بگیرید یا فعلا دست نگه دارید. در قسمت راست هر درخت تصمیم، نتایج زنجیر تصمیمات و پیشامدها نشان داده شده است. این نتایج بر مبنای اطلاعات حال حاضر تنظیم شده است. در واقع شما میگویید:
اگر آنچه در حال حاضر میدانم، در آن زمان هم درست باشد، چه پیشامدی رخ خواهد داد.
البته شما قادر به پیشبینی تمام پیشامدها و تصمیمات مورد نیاز در آینده در رابطه با موضوع مورد بحث نیستید. در درخت تصمیم تنها تصمیمات و پیشامدهای مهم و اثربخش را برای مقایسه در نظر میگیرید.
اضافه کردن دادههای مالی
حالا میتوانیم به مسئله شرکت شیمیایی Stygian برگردیم. درخت تصمیم متناسب با مسئله در نگاره شماره سه نشان داده شده است. در تصمیم شماره یک، شرکت باید بین احداث یک واحد با ظرفیت پایین یا یک واحد با ظرفیت بالا یکی را انتخاب کند. هماکنون تنها در این مورد باید تصمیمگیری شود. اما اگر بعد از تاسیس واحد کوچکتر، شرکت با تقاضای مناسب بازار روبرو شد میتواند طی دو سال طرح توسعه واحد را اجرا کند (تصمیم شماره دو).
اما بیایید از گزینههای لخت و عاری از داده عبور کنیم. در تصمیمگیری، مجریان باید به اعداد و ارقام مالی سود، ضرر و میزان سرمایه اتکا کنند. با توجه به شرایط کنونی و فرض عدم تغییرات ناگهانی و مهم، استدلال تیم مدیریت به شکل زیر است.
بررسی بازار نشان میدهد که شانس یک بازار بزرگ در بلند مدت برابر با ۶۰٪ و شانس یک بازار کوچک در بلند مدت برابر با 4۰٪ (ردیف دو و سه جدول) است.
پیشامد
شانس یا احتمال (٪)
تقاضای اولیه بالا، تقاضای درازمدت بالا
60
تقاضای اولیه بالا، تقاضای درازمدت پایین
10
تقاضای اولیه پایین، تقاضای درازمدت پایین
30
تقاضای اولیه پایین، تقاضای درازمدت بالا
0
در نتیجه، شانس اینکه بازار با تقاضای بالای اولیه روبهرو شود برابر با ۷۰٪ (۶۰ + 1۰) است. اگر تقاضا در ابتدا بالا باشد، شرکت پیشبینی میکند که احتمال ادامهی میزان بالای تقاضا برابر با ۸۶٪ (۷۰ ÷ ۶۰) است. مقایسه ۸۶٪ با ۶۰٪ نشان میدهد که تقاضای بالای اولیه، محاسبهی احتمال ادامه بازار با تقاضای بالا را دستخوش تغییر میکند. به شکل مشابه اگر تقاضا در دوره دو ساله ابتدائی پایین باشد، شانس پایین بودن تقاضا در ادامه برابر با 1۰۰٪ (3۰ ÷ 3۰) است. در نتیجه میزان فروش در دوره اولیه میتواند نشانگر خوبی برای سطح تقاضا در ادامه دوره ده ساله باشد.
تخمین درآمد در صورت پیشامد هر سناریو در ادامه آمده است.
1. یک واحد تولیدی بزرگ با تقاضای بالا درآمدی برابر با یک میلیون دلار در سال به صورت نقد خواهد داشت.
2. یک واحد تولیدی بزرگ با تقاضای پایین به دلیل هزینههای عملیاتی ثابت و بازده پایین تنها 1۰۰ هزار دلار در سال درآمد خواهد داشت.
3. یک واحد تولیدی کوچک با تقاضای پایین اقتصادی است و سالانه درآمدی معادل 4۰۰ هزار دلار خواهد داشت.
4. یک واحد تولیدی کوچک با تقاضای اولیه بالا در سال برابر با 4۵۰ هزار دلار درآمد خواهد داشت که در سالهای سوم به بعد با توجه به افزایش حضور رقبا به میزان 3۰۰ هزار دلار کاهش پیدا خواهد کرد. (بازار بزرگتر خواهد شد اما بین رقبای جدید تقسیم میشود.)
۵. اگر واحد کوچک مطابق با افزایش تقاضا در سالهای آتی رشد کند، سالانه ۷۰۰ هزار دلار درآمد سالانه به ارمغان خواهد آورد که کمتر از درآمد یک واحد بزرگ با درآمد یک میلیون دلار خواهد بود.
۶. اگر واحد کوچک توسعه پیدا کند اما بازار کوچک شود، درآمد حاصل سالانه برابر با ۵۰ هزار دلار خواهد بود.
در ادامه با محاسبات انجام گرفته خواهیم داشت: یک واحد بزرگ نیاز به سه میلیون دلار سرمایهگذاری دارد. یک واحد کوچک در ابتدا 1.3 میلیون دلار و در صورت ادامه توسعه نیاز به 2.2 میلیون دلار خواهد داشت.
اگر اطلاعات جدید را به درخت تصمیم وارد کنیم، نگاره شماره چهار به دست خواهد آمد. به خاطر داشته باشید که تمام اطلاعات موجود بر اساس دانستههای شرکت Stygian به دست آمدهاند اما بدون درخت تصمیم این اطلاعات ارزش و مفهوم کنونی را به دست نمیداند. کمکم متوجه میشوید که درخت تصمیم چه تاثیر شگرفی بر توانایی مدیران در تحلیل سیستماتیک (systematic analysis) و تصمیمگیری بهتر میگذارد. در نهایت برای ایجاد یک درخت تصمیم به موارد زیر نیازمندیم.
1. شناسایی نقاط تصمیم و انتخابهای ممکن در هر سطح
2. شناسایی احتمالات و بازه یا نوع پیشامدها در هر سطح
3. تخمین مقادیر عددی برای تحلیل بهویژه احتمال نتایج عملکرد، هزینهها و سود حاصل
4. تحلیل ارزش انتخابها برای انتخاب یک مسیر
انتخاب مسیر عملکرد (Choosing Course of Action)
هم اکنون آمادهی برداشتن قدم بعدی برای مقایسه نتایج هر مسیر هستیم. یک درخت تصمیم جواب نهایی مسئلهی سرمایهگذاری را به مدیر نمیدهد بلکه به وی کمک میکند مسیر با بهترین سود و کمترین هزینه را مشاهده کند و با مسیرهای دیگر مقایسه نماید.
البته سود باید همراه با ریسک محاسبه شود. در شرکت شیمیایی Stygian، مدیران بخشهای مختلف نظرات متفاوتی نسبت به ریسک دارند. لذا تصمیمات متفاوتی با داشتن یک درخت تصمیم یکسان به دست میآید. افراد حاضر و درگیر در تهیه درخت تصمیم شامل سرمایهگذاران، نظریهپردازان، دادهکاوان یا تصمیمگیران دید متفاوتی نسبت به ریسک و عدم اطمینانها دارند. اگر با این تفاوتها به شکل منطقی برخورد نشود، هر یک از افراد مذکور به شکل متفاوتی به فرایند تصمیمگیری نگاه میکنند و تصمیم هر یک با دیگری متناقض به نظر میرسد.
برای مثال یک سرمایهدار ممکن است به این تصمیم به عنوان یک سرمایهگذاری با احتمال برد و باخت نگاه کند. یک مدیر ممکن است تمام اعتبار و شهرت خود را بر این تصمیم قمار کند اما موفقیت یا عدم موفقیت این انتخاب تاثیر بهسزایی در درآمد و موقعیت یک کارمند عادی ایجاد نکند. فرد دیگری ممکن است در صورت موفقیت پروژه سود سرشاری کسب کند اما در صورت شکست خیلی متضرر نگردد. طبیعت ریسک از نظر هر کدام از افراد درگیر ممکن است به تفاوت در فهم ریسک و انتخاب استراتژیهای ناهمگون در مقابله با ریسک منجر گردد.
حضور اهداف متعارض، ناپایدار و متعدد منجر به ایجاد سیاست اصلی شرکت شیمیایی Stygian میگردد و عناصر این سیاست تحت تاثیر خواست و زندگی افراد درگیر تغییر میکند. در ادامه بد نیست اجزاء مختلف تصمیمگیر را بررسی و ارزیابی نماییم.
چه چیزی با ریسک روبهرو است؟ سود، ادامه حیات کسبوکار، حفظ شغل یا شانس یک شغل بهتر؟
چه کسی ریسک را تحمل میکند؟ سرمایهگذار عموما به یک شکل ریسک را تحمل میکند. مدیریت، کارمندان و جامعه ریسکهای متفاوتی را تجربه مینمایند.
ویژگی ریسک چیست؟ منحصر به فرد، تصادفی یا با عدم قطعیت؟ آیا اقتصاد، صنعت، شرکت یا بخشی از آن را تحت تاثیر قرار میدهد؟
چنین سوالهایی حتما ذهن مدیران عالی را درگیر میکند و البته درخت تصمیم نشان داده شده در نگاره شماره 4 به این سوالها پاسخ نخواهد داد. اما این درخت به مدیران خواهد فهماند که کدامیک از تصمیمات، اهداف بلند مدت را دستخوش تغییر میکنند. ابزار مناسب در قدم بعدی تحلیل مفهوم عقبگرد (rollback) است.
مفهوم عقبگرد
مفهوم عقبگرد در این شرایط نیاز به توضیح دارد. در نقطه تصمیم گیری شماره یک در نگاره شماره چهار، مدیریت اجباری برای اخذ تصمیم شماره دو ندارد و حتی نمیداند مجبور به این کار خواهد شد یا نه. اما اگر قرار بر تصمیمگیری در نقطه دو باشد، با توجه به اطلاعات کنونی، شرکت تصمیم به توسعه ظرفیت تولید خواهد گرفت. این تحلیل در نگاره شماره ۵ نشان داده شده است. ( در این لحظه از سوال در مورد تنزیل سود آینده (discounting future profits) چشمپوشی میکنیم و در ادامه در مورد آن صحبت خواهیم کرد.) میبینیم که امید ریاضی کلی (total expected value) در تصمیم به توسعه ظرفیت 160 هزار دلار بیشتر از تصمیم برای عدم توسعه در هشت سال باقیمانده است. در نتیجه مدیریت با اطلاعات کنونی چنین تصمیمی خواهد گرفت (تصمیم تنها بر اساس سود بیشتر و به عنوان یک تصمیم منطقی اخذ میشود).
ممکن است بیاندیشید چرا با اینکه تنها با تصمیم شماره یک روبرو هستیم، باید به جایگاه تصمیمگیری نقطه دو فکر کنیم. دلیل این موضوع این است که ما بایستی بتوانیم سود حاصل از تصمیم نقطه دو را محاسبه کنیم تا قادر باشیم سود حاصل از تصمیم نقطه یک (ساخت یک واحد تولیدی کوچک یا یک واحد تولید بزرگ) را با یکدیگر مقایسه کنیم. ارزش مالی تصمیم شماره دو را ارزش مکانی (position value) آن مینامیم. ارزش مکانی یک تصمیم برابر است با ارزش مورد انتظار یا امید ریاضی شاخه متناظر (در این مثال، چند شاخه یا چنگال توسعه واحد). امید ریاضی به شکل ساده برابر است با میانگین مقادیر نتایج در صورت تکرار زیاد شرایط (بازده ۵۶۰۰ دلار در سال با احتمال ۸۶٪ و 4۰۰ دلار با احتمال 14٪).
به بیان دیگر، معدل 2۶۷2 دلار سود نصیب شرکت شیمیایی Stygian تا رسیدن به نقطه دو خواهد شد. حال این سوال پیش میآید که با توجه به این مقادیر بهترین تصمیم در نقطه شماره یک کدام است؟
به نگاره سرمایهگذاری شماره ۶ نگاه کنید. در قسمت بالای درخت و سمت راست، سود حاصل از پیشامدهای مختلف در صورت ساخت یک واحد بزرگ را مشاهده میکنید. در قسمت پایینی شاخههای مربوط به واحد تولیدی کوچک را میبینید. اگر تمام این سودها را در احتمال آنها ضرب کنیم، مقایسه زیر حاصل میشود:
گزینهی با امید ریاضی بزرگتر (سود مورد انتظار بیشتر) متناظر با ساخت واحد تولیدی بزرگ خواهد بود.
در نظر گرفتن زمان
اما چطور باید فواصل زمانی در سودهای آینده را به حساب آورد؟ رسم دورههای زمانی بین تصمیمهای متوالی در درخت تصمیم اهمیت زیادی دارد. در هر مرحله، بایستی ارزش زمانی سود یا هزینه را در نظر بگیریم. هر استانداردی انتخاب کنیم، ابتدا باید زمانی را به عنوان زمان مرجع در نظر بگیریم و ارزش تمامی مقادیر را برای امکان مقایسه در آن زمان به دست آوریم. این روش مشابه استفاده از نرخ تنزیل در بررسی امکانسنجی اقتصادی است. در این حالت تمامی مقادیر مالی باید متناسب با تورم یا نرخ تنزیل، تعدیل گردند.
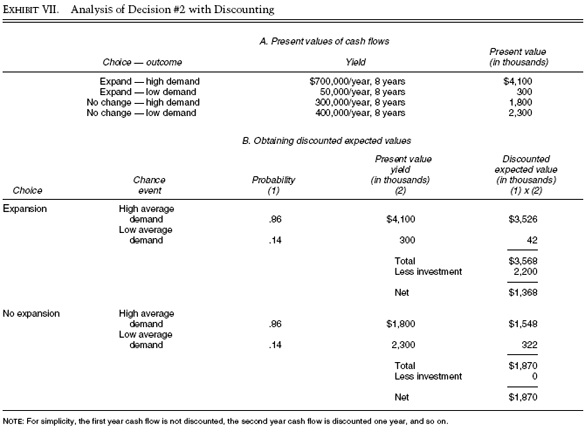
برای سادهسازی، نرخ تنزیل مورد نظر شرکت شیمیایی Stygian را برابر با 1۰٪ در سال در نظر میگیریم. با استفاده از قانون عقبگرد، دوباره با تصمیم شماره دو شروع میکنیم. با تنزیل مقادیر با نرخ 1۰٪، نتایج نگاره شماره هفت، قسمت A، به دست خواهد آمد. توجه کنید که این مقادیر، ارزش کنونی را در صورت اتخاذ تصمیم شماره دو نشان میدهند.
حال همان فرایند نگاره پنجم را اینبار با احتساب مقادیر تنزیل شده به دست میآوریم. این نتایج در قسمت B، نگاره شماره هفت نشان داده شدهاند. از آنجا که امید ریاضی تنزیلشده گزینه عدم توسعه بیشتر است، این شکل به شیوه بهتری ارزش مکانی نقطه تصمیم شماره دو را نشان میدهد.
بعد از انجام موارد ذکرشده، دوباره به سراغ تصمیم شماره یک خواهیم رفت. این محاسبات در نگاره شماره هشت نشان داده شده است. توجه کنید که ارزش مکانی نقطه شماره دو با فرض قرار گرفتن در نقطه شماره یک از نظر زمانی به دست آمده است.
واحد تولیدی بزرگ دوباره به عنوان انتخاب برتر شناسایی میگردد. اما حاشیه سود (margin) اینبار نسبت به مرتبه بدون تنزیل مقدار کمتری (2۹۰ هزار دلار) است.
گزینههای عدم قطعیت (Uncertainty Alternatives)
در نمایش مفهوم درخت تصمیم، با گزینههای موجود به عنوان موارد گسسته برخورد شد و احتمال وقوع هریک به صورت جداگانه به دست آمد. برای مثالهای قبل، از شرایط عدم قطعیت بر پایه یک متغیر مانند تقاضا، شکست یا موفقیت پروژه استفاده شد. سعی بر این بود تا از پیچیدگیهای غیر ضرور با تایید بر روابط بین تصمیمات حال و آینده و در نظر گرفتن عدم قطعیتها پرهیز شود.
در بسیاری از موارد، عناصر عدم قطعیت در قالب گزینههای تک متغیره گسسته بررسی میشوند. اما در بسیاری از موارد دیگر، احتمال سودآوری در مراحل مختلف به عوامل عدم قطعی بسیاری مانند هزینه، قیمت، بازده، شرایط اقتصادی و.. بستگی دارد. در این موارد، میتوان بازده مقادیر یا احتمالات جریان نقدینگی را در هر مرحله با دانش کافی نسبت به متغیرهای اصلی و عدم قطعیتهای متناظر به دست آورد. سپس میتوان احتمالات جریان نقدینگی را به دو، سه یا چند زیربخش تقسیم کرد تا به عنوان گزینههای گسسته مورد بررسی قرار گیرند.
نتیجهگیری
پیتر اف دراکر (Peter F. Drucker) به زیبایی رابطه بین برنامهریزی زمان حال و پیشامدهای آینده را توضیح داده است: «برنامهریزی بلند مدت با تصمیمات آینده سروکار ندارد. بلکه با آینده تصمیمات حاضر مرتبط است». تصمیمات امروز باید متاثر از نتیجه محتمل در آینده اتخاذ شوند. از آنجا که تصمیمات امروز پایه انتخابهای آینده را خواهند ساخت، باید تعادلی بین سودآوری و انعطافپذیری ایجان نمایند؛ این تصمیمات باید بین نیاز به سرمایهگذاری بر فرصتهای پرسود با ظرفیت عکسالعمل به شرایط و نیازهای آینده تعادل برقرار نمایند.
این ویژگی یکتای درخت تصمیم است که به مدیریت امکان تلفیق ابزارهای تحلیل را ارائه مینماید. با استفاده از درخت تصمیم مدیریت میتواند مسیری از انتخابها را با راحتی و شفافیت بیشتر دنبال کند. با این روش نتایج تصمیمات کاملا روشن خواهند بود.
البته بسیاری از جوانب کاربردی دیگر درخت تصمیم در تنها یک نوشته جای نمیگیرد. با مطالعه بیشتر و استفاده از روشهای متعدد، تحلیل شما جزیی و دقیقتر خواهد شد.
مطمئنا مفهوم درخت تصمیم پاسخ قطعی و نهایی سوال سرمایهگذاری را با توجه به عدم قطعیتها در اختیار مدیر قرار نخواهد داد. هنوز این ابزار قادر به پاسخگویی در این سطح نیست و احتمالا هرگز نخواهد بود. با اینحال درخت تصمیم از آن جهت ارزشمند است که ساختار تصمیم به سرمایهگذاری را شفاف میکند و به ارزیابی فرصتها کمک مینماید.
Decision Tree مفهومی است که اگر در نظر دارید تا تصمیم پیچیدهای بگیرید و یا میخواهید مسائل را برای خودتان به بخشهای کوچکتری تقسیم کرده تا به شکل بهتری قادر به حل آنها گردیده و ذهنتان را سازماندهی کنید، میتوانید از آن استفاده نمایید. در این پست قصد داریم تا همه چیز را در مورد درختهای تصمیمگیری مورد بررسی قرار دهیم؛ از جمله اینکه این مفهوم چه هست، چهطور مورد استفاده قرار میگیرد و همچنین چگونه میتوانیم دست به ایجاد یک درخت تصمیمگیری بزنیم.
آشنایی با مفهوم Decision Tree (درخت تصمیم)
به طور خلاصه، درخت تصمیم نقشهای از نتایج احتمالی یکسری از انتخابها یا گزینههای مرتبط بهم است به طوری که به یک فرد یا سازمان اجازه میدهد تا اقدامات محتمل را از لحاظ هزینهها، احتمالات و مزایا بسنجد. از درخت تصمیم میتوان یا برای پیشبرد اهداف و برنامههای شخصی و غیررسمی یا ترسیم الگوریتمی که بر اساس ریاضیات بهترین گزینه را پیشبینی میکند، استفاده کرد.
یک درخت تصمیمگیری به طور معمول با یک نُود اولیه شروع میشود که پس از آن پیامدهای احتمالی به صورت شاخههایی از آن منشعب شده و هر کدام از آن پیامدها به نُودهای دیگری منجر شده که آنها هم به نوبهٔ خود شاخههایی از احتمالات دیگر را ایجاد میکنند که این ساختار شاخهشاخه سرانجام به نموداری شبیه به یک درخت مبدل میشود. در درخت تصمیمگیری سه نوع Node (گِره) مختلف وجود دارد که عبارتند از:
نُود تصادفی، که توسط یک دایره نشان داده میشود، نمایانگر احتمال وقوع یکسری نتایج خاص است، نُود تصمیمگیری، که توسط یک مربع نشان داده میشود، تصمیمی که میتوان اتخاذ کرد را نشان میدهد و همچنین نُود پایانی نمایانگر پیامد نهایی یک مسیر تصمیمگیری خواهد بود.
درختهای تصمیمگیری را میتوان با سَمبولها یا علائم فلوچارت نیز رسم کرد که در این صورت برای برخی افراد، به خصوص دولوپرها، درک و فهم آن آسانتر خواهد بود.
چهطور می توان اقدام به کشیدن یک Decision Tree کرد؟
به منظور ترسیم یک درخت تصمیم، ابتدا وسیله و ابزار مورد نظرتان را انتخاب کنید (میتوانید آن را با قلم و کاغذ یا وایتبرد کشیده یا اینکه میتوانید از نرمافزارهای مرتبط با این کار استفاده کنید.) فارغ از اینکه چه ابزاری انتخاب میکنید، میبایست به منظور ترسیم یک درخت تصمیم اصولی، مراحل زیر را دنبال نمایید:
۱- کار با تصمیم اصلی آغاز کنید که برای این منظور از یک باکس یا مستطیل کوچک استفاده کرده، سپس از آن مستطیل به ازای هر راهحل یا اقدام احتمالی خطی به سمت راست/چپ کشیده و مشخص کنید که هر خط چه معنایی دارد.
۲- نُودهای تصادفی و تصمیمگیری را به منظور شاخ و برگ دادن به این درخت، به طریق پایین رسم کنید:
ـ اگر تصمیم اصلی دیگری وجود دارد، مستطیل دیگری رسم کنید. ـ اگر پیامدی قطعی نیست، یک دایره رسم کنید (دایرهها نمایانگر نُودهای تصادفی هستند.) ـ اگر مشکل حل شده، آن را فعلاً خالی بگذارید.
از هر نُود تصمیمگیری، راههای احتمالی را منشعب کنید به طوری که برای هر کدام از نُودهای تصادفی، خطوطی کشیده و به وسیلهٔ آن خطوط پیامدهای احتمالی را نشان دهید و اگر قصد دارید گزینههای پیش روی خود را به صورت عددی و درصدی آنالیز کنید، احتمال وقوع هر کدام از پیشامدها را نیز یادداشت کنید.
۳- به بسط این درخت ادامه دهید تا زمانی که هر خط به نقطهٔ پایانی برسد (یعنی تا جایی که انتخابهای دیگری وجود نداشته و پیامدهای احتمالی دیگری برای در نظر گرفتن وجود نداشته باشد.) در ادامه، برای هر پیشامد احتمالی یک مقدار تعیین کنید که این مقدار میتواند یک نمرهٔ فرضی یا یک مقدار واقعی باشد. همچنین به خاطر داشته باشید که برای نشان دادن نقاط پایانی، از مثلث استفاده کنید.
حال با داشتن یک درخت تصمیم کامل، میتوانید تصمیمی که با آن مواجه هستید را تجزیه و تحلیل کنید.
مثالی از پروسهٔ تجزیه و تحلیل Decision Tree با محاسبهٔ سود یا مقدار مورد انتظار از هر انتخاب در درخت مد نظر خود، میتوانید ریسک را به حداقل رسانده و احتمال دستیابی به یک پیامد یا نتیجهٔ مطلوب و مورد انتظار را بالا ببرید. به منظور محاسبهٔ سود مورد انتظار یک گزینه، تنها کافی است هزینهٔ تصمیم را از مزایای مورد انتظار آن کسر کنید (مزایای مورد انتظار برابر با مقدار کلی تمام پیامدهایی است که میتوانند از یک انتخاب ناشی شوند که در چنین شرایطی هر مقدار در احتمال پیشامد ضرب شده است.) برای مثالی که در تصاویر بالا زدهایم، بدین صورت این مقادیر را محاسبه خواهیم کرد:
زمانی که قصد داریم دست به تعیین مطلوبترین پیامد بزنیم، مهم است که ترجیحات تصمیمگیرنده را نیز مد نظر داشته باشیم چرا که برخی افراد ممکن است گزینههای کمریسک را ترجیح داده و برخی دیگر حاضر باشند برای یک سود بزرگ، دست به ریسکهای بزرگی هم بزنند.
هنگامی که از درخت تصمیمتان به همراه یک مدل احتمالی استفاده میکنید، میتوانید از ترکیب این دو برای محاسبهٔ احتمال شرطی یک رویداد، یا احتمال پیشامد آن اتفاق با در نظر گرفتن رخ دادن دیگر اتفاقات استفاده کنید که برای این منظور، همانطور که در تصویر فوق مشاهده میشود، کافی است تا از رویداد اولیه شروع کرده، سپس مسیر را از آن رویداد تا رویداد هدف دنبال کنید و در طی مسیر احتمال هر کدام از آن رویدادها را در یکدیگر ضرب نمایید که بدین ترتیب میتوان از یک درخت تصمیم به شکل یک نمودار درختی سنتی بهره برد که نشانگر احتمال رخداد رویدادهای خاص (مثل دو بار بالا انداختن یک سکه) میباشد.
آشنایی با برخی مزایا و معایب Decision Tree
در میان متخصصین در صنایع مختلف، مدیران و حتی دولوپرها، درختهای تصمیم محبوباند چرا که درک آنها آسان بوده و به دیتای خیلی پیچیده و دقیقی احتیاج ندارند، میتوان در صورت لزوم گزینههای جدیدی را به آنها اضافه کرد، در انتخاب و پیدا کردن بهترین گزینه از میان گزینههای مختلف کارآمد هستند و همچنین با ابزارهای تصمیمگیری دیگر به خوبی سازگاری دارند.
با تمام اینها، درختهای تصمیم ممکن است گاهی به شدت پیچیده شوند! در چنین مواردی یک به اصطلاح Influence Diagram جمع و جورتر میتواند جایگزین بهتری برای درخت تصمیم باشد به طوری که این دست نمودارها توجه را به تصمیمات حساس، اطلاعات ورودی و اهداف محدود میکنند.
کاربرد Decision Tree در حوزهٔ ماشین لرنینگ و دیتا ماینینگ
از درخت تصمیم میتوان به منظور ایجاد مُدلهای پیشبینی خودکار استفاده کرد که در حوزهٔ یادگیری ماشینی، استخراج داده و آمار کاربردی هستند. این روش که تحت عنوان Decision Tree Learning شناخته میشود، به بررسی مشاهدات در مورد یک آیتم به جهت پیشبینی مقدارش میپردازد و به طور کلی، در چنین درخت تصمیمی، نُودها نشاندهندهٔ دیتا هستند نَه تصمیمات. این نوع درختها همچنین تحت عنوان Classification Tree نیز شناخته میشوند به طوری که هر شاخه در برگیرندهٔ مجموعهای از ویژگیها یا قوانین طبقهبندی دیتا است و مرتبط با یک دستهٔ خاص میباشد که در انتهای هر شاخه یافت میشود.
این دست قوانین که تحت عنوان Decision Rules شناخته میشوند قابل بیان به صورت جملات شرطی میباشند (مثلاً اگر شرایط ۱ و ۲ و ۳ محقق شوند، با قطعیت میتوان گفت که X نتیجهای همچون Y برخواهد گرداند.) هر مقدار دادهٔ اضافی به مدل کمک میکند تا دقیقتر پیشبینی کند که مسئلهٔ مورد نظر به کدام مجموعه از مقادیر متعلق میباشد و این در حالی است که از این اطلاعات بعداً میتوان به عنوان ورودی در یک مدل تصمیمگیری بزرگتر استفاده کرد.
درختهای تصمیمگیری که پیامدهای محتمل پیدرپی و بینهایت دارند، Regression Tree نامیده میشوند. به طور کلی، متدهای کاربردی در این حوزه به صورت زیر دستهبندی میشوند:
– Bagging: در این متد با نمونهسازی مجدد دیتای سورس، چندین درخت ایجاد شده سپس با برداشتی که از آن درختان میشود، تصمیم نهایی گرفته شده یا نتیجهٔ نهایی به دست میآید.
– Random Forest: در این متد طبقهبندی از چندین درخت تشکیل شده که به منظور افزایش نرخ کلاسیفیکیشن طراحی شدهاند.
– Boosted: درختهایی از این جنس میتوانند برای رگرسیون مورد استفاده قرار گیرند.
– Rotation Forest: در این متد، همگی درختها توسط یک به اصطلاح Principal Component Analysis با استفاده از بخشی از دادههای تصادفی آموزش داده میشوند.
درخت تصمیمگیری زمانی مطلوب تلقی میشود که نشاندهندهٔ بیشترین دیتا با حداقل شاخه باشد و این در حالی است که الگوریتمهایی که برای ایجاد درختهای تصمیمگیری مطلوب طراحی شدهاند شامل CART ،ASSISTANT ،CLS و ID31415 میشوند. در واقع، هر کدام از این متدها باید تعیین کنند که بهترین راه برای تقسیم داده در هر شاخه کدام است که از متدهای رایجی که بدین منظور استفاده میشوند میتوان به موارد زیر اشاره کرد:
– Gini Impurity – Information Gain – Variance Reduction
استفاده از درختهای تصمیمگیری در یادگیری ماشینی چندین مزیت عمده دارد منجمله هزینه یا بهای استفاده از درخت به منظور پیشبینی داده با اضافه کردن هر به اصطلاح Data Point کاهش مییابد و این در حالی است که از جمله دیگر مزایایش میتوان به موارد زیر اشاره کرد:
– برای دادههای طبقهبندی شده و عددی به خوبی پاسخگو است. – میتواند مسائل با خروجیهای متعدد را مدلسازی کند. – میتوان قابلیت اطمینان به درخت را مورد آزمایش و اندازهگیری قرار داد. – صرفنظر از اینکه آیا فرضیات دادهٔ منبع را نقض میکنند یا خیر، این روش به نظر دقیق میرسد.
اما Decision Tree در ML معایبی نیز دارا است که از جملهٔ مهمترین آنها میتوان به موارد زیر اشاره کرد:
– حین مواجه با دادههای طبقهبندی شده با سطوح مختلف، دادههای حاصله تحتتأثیر ویژگیها یا صفاتی که بیشترین شاخه را دارند قرار میگیرد. – در صورت رویارویی با پیامدهای نامطمئن و تعداد زیادی پیامد بهم مرتبط، محاسبات ممکن است خیلی پیچیده شود. – ارتباطات بین نُودها محدود به AND بوده حال آنکه یک Decision Graph این اجازه را به ما میدهند تا نُودهایی داشته باشیم که با OR به یکدیگر متصل شدهاند.