فیلتر کالمن (به انگلیسی: Kalman filter) که به عنوان تخمین خطی مرتبه دوم نیز از آن یاد میشود، الگوریتمی است که حالت یک سیستم پویا را با استفاده از مجموعهای از اندازهگیریهای شامل خطا در طول زمان برآورد میکند. این فیلتر معمولاً تخمین دقیقتری را نسبت به تخمین بر مبنای یک اندازهگیری واحد را بر مبنای استنباط بیزی و تخمین توزیع احتمال مشترکی از یک متغیر تصادفی در یک مقطع زمانی ارائه میکند. این فیلتر از نام رودولف ای کالمن، یکی از پایهگذاران این تئوری گرفته شدهاست.
فیلتر کالمن کاربردهای بسیاری در علم و فناوری مانند مسیریابی و پایش وسایل نقلیه، به خصوص هواپیما و فضاپیماها، دارد. فیلتر کالمن مفاهیم گستردهای را در زمینه سریهای زمانی، پردازش سیگنال و اقتصادسنجی مطرح میکند. این فیلتر از مفاهیم پایه در زمینه برنامهریزی و پایش رباتها و همچنین مدلسازی سیستم عصبی محسوب میشود. بر اساس تأخیر زمانی میان ارسال فرامین و دریافت پاسخ آنها، استفاده از فیلتر کالمن در تخمین حالات مختلف سیستم را ممکن میسازد.
این الگوریتم در دو گام اجرا میشود. در گام پیشبینی، فیلتر کالمن تخمینی از وضعیت فعلی متغیرها را در شرایط عدم قطعیت ارائه میکند. زمانی که نتیجه اندازهگیری بعدی بدست آید، تخمین قبلی با میانگین وزندار آپدیت میشود. به این ترتیب که وزن اطلاعاتی که دارای قطعیت بیشتری هستند، بیشتر خواهد بود. الگوریتم بازگشتی میباشد و با استفاده از ورودیهای جدید و حالات محاسبه شدهٔ قبلی بهصورت بیدرنگ اجرا میشود.
درمورد ورودیهای فیلتر کالمن نمیتوان بیان کرد که تمام خطاها گوسی هستند. اما در عمل فیلتر برآوردهای احتمالاتی را با فرض توزیع طبیعی داشتن انجام میدهد.

مثال کاربردی
تهیه اطلاعات پیوسته و گسسته به روز و دقیق در مورد مکان و سرعت یک شی معین فقط به کمک توالی مشاهدات در مورد موقعیت آن شی، که هر کدام شامل مقداری خطاست امکانپذیر است. این فیلتر در طیف گستردهای از کاربریهای مهندسی از رادار گرفته تا بینایی رایانهای کاربرد دارد. روش فیلتر کالمن یکی از عناوین مهم در تئوری کنترل و مهندسی سیستمهای کنترلی میباشد.
به عنوان مثال، برای کاربری آن در رادار، آنجا که علاقهمند به ردیابی هدف هستید، اطلاعات در مورد موقعیت، سرعت و شتاب هدف با حجم عظیمی از انحراف به لطف پارازیت در هر لحظه اندازهگیریمیشود. فیلتر کالمن از پویایی هدف بهره میگیرد به این صورت که سیر تکاملی آن را کنترل میکند، تا تأثیرات پارازیت را از بین ببرد و یک برآورد خوب از موقعیت هدف در زمان حال (تصفیه کردن) و در آینده (پیش بینی) یا در گذشته (الحاق یا هموار سازی) ارائه میدهد. یک نسخه ساده شده فیلتر کالمن، فیلتر آلفا بتا (alpha beta filter)، که همچنان عموماً استفاده میشود از ثابتهای static weighting به جای ماتریسهای کواریانس استفاده میکند.
نامگذاری و تاریخچه توسعه
اگر چه Thorvald Nicolai Thiele و Peter Swerling قبلاً الگوریتم مشابهی ارائه داده بودند، این فیلتر به افتخار Rudolf E. Kalman، فیلتر کالمن نامگذاری شد و Stanley F. Schmidt عموماً به خاطر توسعه اولین پیادهسازی فیلتر کالمن شهرت یافت. این رخداد هنگام ملاقات با کالمن در مرکز تحقیقاتی ناسا (NASA Ames Research Center) روی داد و وی شاهد کارایی ایده کالمن در برآورد مسیر پرتاب پروژه آپولو بود، که منجر به الحاق آن به رایانه ناوبری آپولو شد. این فیلتر بر روی کاغذ در ۱۹۵۸ توسط Swerling، در ۱۹۶۰ توسط Kalman و در ۱۹۶۱ توسط Kalman and Bucy ایجاد و بسط داده شد.
این فیلتر بعضی مواقع فیلتر Stratonovich-Kalman-Bucy نامیده میشود، چرا که یک نمونه خاص از فیلتر بسیار معمولی و غیر خطی ای است که قبلاً توسط Ruslan L. Stratonovich ایجاد شده، در حقیقت معادله این نمونه خاص، فیلتر خطی در اسنادی که از Stratonovich قبل از تابستان ۱۹۶۰، یعنی زمانی که کالمن ،Stratonovich را در کنفرانسی در مسکو ملاقات کرد به چاپ رسید بود.
در تئوری کنترل، فیلتر کالمن بیشتر به برآورد مرتبه دوم (LQE) اشاره دارد. امروزه تنوع گستردهای از فیلتر کالمن بوجود آمده، از فرمول اصلی کالمن در حال حاضر فیلترهای: کالمن ساده، توسعه یافته اشمیت، اطلاعاتی و فیلترهای گوناگون جذر بیرمن، تورنتون و بسیاری دیگر بوجود آمدهاند. گویا مرسومترین نوع فیلتر کالمن فاز حلقهٔ بسته (phase-locked loop) میباشد که امروزه در رادیوها، رایانهها و تقریباً تمامی انواع ابزارهای تصویری و ارتباطی کاربرد دارد.
اساس مدل سیستم پویا
فیلترهای کالمن بر اساس سیستمهای خطی پویا (linear dynamical systems) گسسته در بازه زمانی هستند. آنها بر اساس زنجیره مارکوف (Markov chain) به کمک عملگرهای خطی ساخته شدهاند و توسط نوفه گاوسی (Gaussian noise) تحریک میشوند. حالت سیستم توسط برداری از اعداد حقیقی بیان میشود. در هر افزایش زمانی که در بازههای گسسته صورت میگیرد، یک عملگر خطی روی حالت فعلی اعمال میشود تا حالت بعدی را با کمی پارازیت ایجاد کند و اختیاراً در صورت شناخت روی کنترلکنندههای سیستم برخی اطلاعات مرتبط را استخراج میکند. سپس عملگر خطی دیگر به همراه مقدار دیگری پارازیت خروجی قابل مشاهدهای از این حالت نامشخص تولید میکند. فیلتر کالمن قادر است مشابه مدل نامشخص مارکوف برخورد کند. با این تفاوت کلیدی که متغییرهای حالت نامشخص در یک فضای پیوسته مقدار میگیرند (نقطهٔ مقابل فضای حالت گسسته در مدل مارکوف). بعلاوه، مدل نامشخص مارکوف میتواند یک توزیع دلخواه برای مقادیر بعدی متغییرهای حالت ارائه کند، که در تناقض با مدل پارازیت گاوسیای است که در فیلتر کالمن استفاده میشود. در اینجا یک دوگانگی بزرگ بین معادلات فیلتر کالمن و آن مدل مارکوف وجود دارد. مقالهای در رابطه با این مدل و دیگر مدلها در Roweis and Ghahramani و فصل ۱۳ Hamilton ارائه شدهاست.
برای تخمین حالت درونی یک فرایند که توسط مجموعهای مشاهدات دارای پارازیت ارائه شدهاست باید آن را منطبق بر چارچوب فیلتر کالمن کنیم. به این منظور ماتریسهای زیر را ارائه میکنیم:
Fk: مدل انتقال حالات،
Hk: مدل مشاهده شده،
Qk: کوواریانس پارازیت فرایند،
Rk: کوواریانس پارازیت مشاهده شده،
Bk: مدل ورودی-کنترل
فیلتر کالمن بیان میکند که میتوان حالت k را با استفاده از حالت (k – 1) با استفاده از رابطه زیر محاسبه کرد:

بهطوریکه:
Fk: حالت انتقالی اعمال شده به xk−۱،
Bk: مدل ورودی-کنترل اعمال شده به بردار کنترلی uk,
wk: فرایند نویزی با توزیع نرمال، میانگین صفر و واریانس Qk
در زمان k،مشاهده zk با توجه به حالت xk به صورت زیر بدست میآید:

بهطوریکه Hk مدل مشاهده شده که به فضای مشاهده شده نگاشت میشود و همچنین vk نویز مشاهده شده با توزیع گاوسی، میانگین صفر و کوواریانس Rk است.
لازم است ذکر شود که حالت اولیه و بردار نویزی در هر محله از هم مستقل هستند.
بسیاری از سیستمهای پویای واقعی از این مدل تبعیت نمیکنند. برخی سیستمهای پویا حتی در زمانی که منبع ورودی ناشناختهای را بررسی میکنیم، میتوانند موجب کاهش تأثیر این فیلتر شوند. زیرا اثر این سیستمها بر سیگنال ورودی تأثیرگذار است و به این ترتیب میتواند موجب ناپایداری تخمین فیلتر شود. به علاوه نویزهای سفید مستقل باعث منشعب شدن فیلتر نمیشوند. مسئله تفکیک نویز سفید و سیستمهای پویا در شاخهٔ نظریه کنترل و در چارچوب کنترل مقاوم بررسی میشود.

شرح بیشتر
فیلتر کالمن یک تخمینگر بازگشتی است، یعنی تنها تخمین حالت قبل و مشاهده فعلی برای محاسبه تخمین حالت فعلی لازم است. برعکس بسیاری از تخمینگرها نیازی به نگهداری اطلاعات تخمینها و مشاهدات تمام حالات قبل نیست. در اینجا بیانگر تخمینی از در زمان n به شرط از مشاهدات پیش از این زمان است.


حالت فعلی فیلتر توسط دو متغیر تشریح میشود:
- تخمین حالت پسینی در زمان k به شرط مشاهدات پیش از k.
- ماتریس کوواریانس خطای پسین.


فیلتر کالمن توسط یک معادله بیان میشود اما معمولاً آن را به دو بخش پیشبینی و آپدیت تفکیک میکنند. در گام پیشبینی با استفاده از تخمینهای حالات در بازههای زمانی پیشین، تخمینی برای حالت فعلی بدست میآید. این تخمین پیشبینی شده همان دانش پیشینی است زیرا تنها به تخمینهای قبلی وابسته است و هیچ مشاهدهای در حالت فعلی سیستم را در برنمیگیرد. در گام آپدیت تخمین پیشین با مشاهدات فعلی ترکیب میشود تا تخمینی از حالت فعلی سیستم ارائه کند.
معمولاً این دو گام متناوباً تکرار میشوند، به این معنی که پیشبینی تا مشاهده بعدی انجام میشود و سپس با استفاده از مشاهدات فعلی آپدیت انجام میشود. اگر در بازه زمانی مشاهدهای انجام نشود، پیشبینیها تا مشاهده بعدی انجام میشوند و آپدیت بر مبنای چند مرحله پیشبینی انجام میشود. بهطور مشابه اگر در بازه زمانی چندین مشاهده مستقل انجام شود، بر مبنای هریک از آنها چند آپدیت با ماتریسهای Hk متفاوت بدست میآید.
پیشبینی
| تخمین حالت پیشبینی شده (پیشین) | |
| تخمین کوواریانس پیشبینی شده (پیشین) |


آپدیت
| مشاهده جدید وابسته | |
| کوواریانس جدید وابسته | |
| نتیجه بهینه کالمن | |
| تخمین حالت آپدیت شده (پسین) | |
| تخمین کوواریانس آپدیت شده (پسین) |





فرمول کوواریانس آپدیت شده تنها در حالت بهینه بودن فیلتر کالمن کاربرد دارد و در باقی حالات فرمولهای پیچیدهتری موردنیاز است که در بخش مشتقات موجود است.
ثابتها
اگر مدلسازی دقیق باشد و و بیانگر توزیع حالات ابتدایی سیستم باشند، مقادیر ثابت زیر بدست میآیند:


![{\displaystyle \operatorname {E} [\mathbf {x} _{k}-{\hat {\mathbf {x} }}_{k\mid k}]=\operatorname {E} [\mathbf {x} _{k}-{\hat {\mathbf {x} }}_{k\mid k-1}]=0}](https://wikimedia.org/api/rest_v1/media/math/render/svg/464fa9ffa8447f4442c8aaf2fa4c8e1d723cd6d9)
![{\displaystyle \operatorname {E} [{\tilde {\mathbf {y} }}_{k}]=0}](https://wikimedia.org/api/rest_v1/media/math/render/svg/892473985a1c98add4189f3f07b0a5ed5f0e640d)
بهطوریکه امید ریاضی متغیر تصادفی است. در بالا تمامی تخمینها دارای امید ریاضی صفر هستند.
![{\displaystyle \operatorname {E} [\xi ]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/261957bffe5d89e65e9d27dfa34c5f86f6017baa)

همچنین:



به این ترتیب ماتریسهای کوواریانس نشاندهنده مقادیر تخمینی کوواریانسها هستند.
تخمین کوواریانسهای نویز Qk و Rk
پیادهسازی عملی فیلتر کالمن با توجه به سختی بدست آوردن تخمین ماتریس کوواریانس Qk و Rk بهینه دشوار است. مطالعات بسیاری جهت بدست آوردن تخمینهای کوواریانس با توجه به دادههای موجود انجام شدهاست. یکی از بهترین روشها، تکنیک حداقل مربعات اتوکوواریانس(ALS) است که از اتوکوواریانس دادهها با ایجاد تأخیر زمانی برای تخمین استفاده میکند. از گنو آکتیو ومتلب جهت محاسبه ماتریسهای کوواریانس نویز با استفاده از تکنیک حداقل مربعات اتوکوواریانس استفاده میشود. این کار به صورت آنلاین توسط پروانه عمومی همگانی گنو امکانپذیر است.
بهینگی و کارایی
فیلتر کالمن یک فیلتر خطی بهینه است زیرا الف) مدلسازی آن با دقت بالایی بر سیستم اصلی منطبق است. ب) نویز ورودی، نویز سفید ناهمبسته است. ج) مقدار کوواریانس نویز قابل محاسبه است. روشهای بسیاری از جمله روش حداقل مربعات اتوکوواریانس که در بالا به آن اشاره شد برای تخمین کوواریانس نویز ارائه شدهاند. پس از تخمین کوواریانس لازم است کارایی سیستم ارتقا یابد. این بدین معنی است که تخمین حالات سیستم دقیقتر شوند. اگر فیلتر کالمن بهینه باشد، نویز ورودی نویز سفید است که محاسبه کارایی سیستم را ممکن میسازد. روشهای زیادی جهت محاسبه کارایی موجود است.
مثال کاربرد عملی
کامیونی دارای اصطکاک در مسیری مستقیم را در نظر بگیرید. کامیون در مکان صفر ثابت است و سپس در مسیری تحت تأثیر نیروهای تصادفی به حرکت در میآید. موقعیت کامیون را در هر Δt ثانیه اندازهگیری میکنیم. اما این اندازهگیری مبهم است چرا ما تنها مدلی از مکان و سرعت کامیون را در نظر میگیریم. در اینجا فیلتر کالمن را برای این مدل بیان میکنیم.
چون ثابت هستند، شاخصهای زمانی آنها حذف میشوند.

موقعیت و سرعت کامیون در فضای خطی موقعیت آن توصیف میشود:

سرعت، یعنی مشتق مکان نسبت به زمان است.

فرض کنیم در بازه زمانی میان (k − ۱) و k شتاب ak که دارای توزیع طبیعی با میانگین صفر و واریانسσa است به آن اعمال شود. طبق قوانین حرکت نیوتن داریم:

نتیجه شتابak را به سیستم اعمال میکند و همچنین داریم


و
![{\displaystyle \mathbf {G} ={\begin{bmatrix}{\frac {\Delta t^{2}}{2}}\\[6pt]\Delta t\end{bmatrix}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a18778fd8152da9596fd460ee1d07982638e6b21)
به این ترتیب

بهطوریکه و

![{\displaystyle \mathbf {Q} =\mathbf {G} \mathbf {G} ^{\text{T}}\sigma _{a}^{2}={\begin{bmatrix}{\frac {\Delta t^{4}}{4}}&{\frac {\Delta t^{3}}{2}}\\[6pt]{\frac {\Delta t^{3}}{2}}&\Delta t^{2}\end{bmatrix}}\sigma _{a}^{2}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/86bee2fe99e37e404cf77aeecc8db011375b749d)
توزیع کاملاً پیوسته نیست و بنابراین هیچ تابع توزیع احتمالی ندارد. روش دیگر بیان این توزیع به صورت زیر است:


در هر بازه زمانی، موقعیت کامیون که با نویزی آمیختهاست در دست است. فرض کنیم این نویز vk دارای توزیع طبیعی با میانگین صفر و واریانس σz باشد،

بهطوریکه

و
![{\displaystyle \mathbf {R} ={\textrm {E}}[\mathbf {v} _{k}\mathbf {v} _{k}^{\text{T}}]={\begin{bmatrix}\sigma _{z}^{2}\end{bmatrix}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/17eb90e02a9843ffb800341a7a295e5c3c642388)
میدانیم موقعیت اولیه کامیون مشخص است و به صورت زیر در نظر گرفته میشود

برای اینکه در فیلتر آگاهیمان نسبت به این موضوع را مشخص کنیم، یک ماتریس کوواریانس صفر تعریف میکنیم:

اگر حالت ابتدایی و سرعت به درستی و دقت در دست نباشند، ماتریس کوواریانس باید با توجه به واریانسهای داده شده و به صورت قطری تعریف شود:

به این ترتیب فیلتر قادر به محاسبه اطلاعات مدل بر اساس مقادیر اولیه میشود.
مشتقات
مشتقگیری از ماتریس تخمینی کوواریانس پسین
با توجه به مقدار ثابت کوواریانس خطا Pk | k در بالا

با جایگذاری از روابط اثبات شده خواهیم داشت

حال مقدار را جایگزین میکنیم


همچنین را نیز در رابطه جایگذاری میکنیم


با توجه به بردار خطا

چون خطای اندازهگیری شدهvk نسبت به سایر متغیرها ناهمبسته است، میتوان گفت

با توجه به ویژگیهای ماتریس کوواریانس

با توجه به ثابت بودن Pk | k−1 و تعریف Rk نتیجه میشود

این فرمول برای هر مقدار Kk معتبر است. فرمول بالا بیان میکند اگر Kk نتیجه بهینه کالمن باشد، رابطه به شکل زیر ساده خواهد شد.
مشتق نتیجه کالمن
فیلتر کالمن یک تخمینگر کمینه مربع میانگین خطا (MMSE) است. خطا در تخمین حالت پسین برابر است با

هدف ما کمینه کردن میانگین مربع این بردار خطا یعنی است. این معادل کمینه کردن اثر تخمین پسین ماتریس کوواریانس است. با بسط رابطه بالا نتیجه میشود:
![{\displaystyle {\textrm {E}}[\|\mathbf {x} _{k}-{\hat {\mathbf {x} }}_{k|k}\|^{2}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4d49d16c9f09f21a03252c1bd68b134884c2c5a7)

![{\displaystyle {\begin{aligned}\mathbf {P} _{k\mid k}&=\mathbf {P} _{k\mid k-1}-\mathbf {K} _{k}\mathbf {H} _{k}\mathbf {P} _{k\mid k-1}-\mathbf {P} _{k\mid k-1}\mathbf {H} _{k}^{\text{T}}\mathbf {K} _{k}^{\text{T}}+\mathbf {K} _{k}(\mathbf {H} _{k}\mathbf {P} _{k\mid k-1}\mathbf {H} _{k}^{\text{T}}+\mathbf {R} _{k})\mathbf {K} _{k}^{\text{T}}\\[6pt]&=\mathbf {P} _{k\mid k-1}-\mathbf {K} _{k}\mathbf {H} _{k}\mathbf {P} _{k\mid k-1}-\mathbf {P} _{k\mid k-1}\mathbf {H} _{k}^{\text{T}}\mathbf {K} _{k}^{\text{T}}+\mathbf {K} _{k}\mathbf {S} _{k}\mathbf {K} _{k}^{\text{T}}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0910592840b7840cef04141e6bca0caf1e958e3d)
اثر ماتریس زمانی کمینه میشود که حساب ماتریس صفر شود. با استفاده از خواص ماتریس گرادیان و تقارن ماتریسها داریم:

اگر این معادله را برای Kk حل کنیم، نتیجه کالمن بدست میآید


این عبارت همان نتیجه بهینه کالمن است.
ساده کردن فرمول کوواریانس خطای پسین
با استفاده از نتیجه بهینه کالمن که در بالا بدست آمد میتوان فرمول کوواریانس خطای پسین را سادهتر کرد. اگر طرفیت رابطه نتیجه بهینه کالمن را در SkKkT ضرب کنیم، داریم:

با استفاده از فرمول بسط داده شده کوواریانس خطای پسین

با سادهسازی دو جملهٔ آخر نتیجه میشود

این فرمول در محاسبه بسیار راحتتر است اما تنها برای نتیجه بهینه کاربرد دارد و زمانی که نتیجه کالمن بهینه نباشد باید از همان فرمول قبلی استفاده کرد.
تحلیل درستی
معادلات فیلتر کردن کالمن تخمینی بازگشتی برای حالت و کوواریانس خطای ارائه میکند. دقت تخمین به پارامترهای سیستم و نویز ورودی تخمینگر بستگی دارد. در غیاب مقادیر ماتریسهای کوواریانس و عبارت



مقدار درست کوواریانس خطا را ارائه نمیکند. به عبارت دیگر، . در بسیاری از کاربردهای بیدرنگ، ماتریسهای کوواریانس مورد استفاده در طراحی فیلتر کالمن با مقادیر واقعی ماتریسهای کوواریانس تفاوت دارند. این تحلیل بیان میدارد که تخمین کوواریانس خطا زمانی که ماتریسهای ورودی سیستم و باشند، نادرست است.
![{\displaystyle \mathbf {P} _{k\mid k}\neq E[(\mathbf {x} _{k}-{\hat {\mathbf {x} }}_{k\mid k})(\mathbf {x} _{k}-{\hat {\mathbf {x} }}_{k\mid k})^{\mathrm {T} }]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/dc57aee9cf21ad76b273fd206af9ef1c5f5b6796)


این بحث به حالتی که عدم قطعیت درمورد خطا داریم محدود میشود. حال مقادیر واقعی کوواریانس نویز را و تعریف میکنیم بهطوریکه مقادیر آنها به ترتیب در روابط جایگزین و شوند. مقدار واقعی کوواریانس خطا را و با فیلتر کالمن محاسبه میشوند. اگر و خواهد بود. با محاسبه مقدار واقعی کوواریانس خطا و جایگذاری و در نظر داشتن اینکه and معادلات بازگشتی برای بدست میآید:






![{\displaystyle \mathbf {P} _{k\mid k}^{a}=E[(\mathbf {x} _{k}-{\hat {\mathbf {x} }}_{k\mid k})(\mathbf {x} _{k}-{\hat {\mathbf {x} }}_{k\mid k})^{\mathrm {T} }]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0410d9491c417074132830990749bd4072b590ee)

![{\displaystyle E[\mathbf {w} _{k}\mathbf {w} _{k}^{\mathrm {T} }]=\mathbf {Q} _{k}^{a}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c43d89d7d8bf0273b139ce7a28c541364be79ab1)
![{\displaystyle E[\mathbf {v} _{k}\mathbf {v} _{k}^{\mathrm {T} }]=\mathbf {R} _{k}^{a}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0c08a1ba0b1a8c5b5665becfcb0127d014ac582a)

و

محاسبه با فرض و انجام میشود. روابط بازگشتی برای و جز زمانی که و را به ترتیب به جای و در نظر بگیریم، یکتا هستند.
![{\displaystyle E[\mathbf {w} _{k}\mathbf {w} _{k}^{\mathrm {T} }]=\mathbf {Q} _{k}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4fb336628d0061bed34fe69cd0920679e8964057)
![{\displaystyle E[\mathbf {v} _{k}\mathbf {v} _{k}^{\mathrm {T} }]=\mathbf {R} _{k}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e7d86c822e04e9499953f5309bd703b1f11befde)
ریشه مربع
یکی از مشکلات فیلتر کالمن ثبات عددی است. اگر کوواریانس نویز Qk کوچک باشد، مقدار ویژه آن منفی میشود. به این ترتیب ماتریس کوواریانس حالات P نامعین میشود در حالیکه باید مثبت معین باشد.
یک ویژگی ماتریسهای مثبت معین این است که ریشه مربعی ماتریس مثلثی P = S·ST دارند. این ریشه میتواند به کمک روش تفکیک چولسکی (Cholesky decomposition) محاسبه شود. اگر کوواریانس به این فرم نوشته شود، هیچگاه قطری یا متقارن نخواهد بود. یک فرم معادل این ماتریس که با استفاده از تفکیک U-D بدست میآید، P = U·D·UT
است کهU یک ماتریس مثلثی واحد و D یک ماتریس قطری است. در میان این دو فرم، فرم U-D رایجتر است و نیاز به محاسبات کمتری دارد.
الگوریتمهای کارای پیشبینی و آپدیت کالمن در فرم ریشه مربعی، توسط بیرمن و تورتون ارائه شدند.
‘تفکیک’L·D·LT ماتریس کوواریانسSk مبنای دیگر فیلترهای عددی و ریشه مربعی است. الگوریتم با تفکیک LU آغاز میشود و نتایج آن در ساختارL·D·LT وارد میشود تا به روش Golub و Van Loan (الگوریتم ۴٫۱٫۲) در ماتریس قطری غیر واحد انجام شود.
ارتباط با تخمین بازگشتی بیز
فیلتر کالمن یکی از سادهترین شبکههای پویای بیزی است. فیلتر کالمن حالات فعلی سیستم را در طول زمان به صورت بازگشتی، با استفاده از اندازهگیریهای ورودی در مدل فرایندی ریاضی تخمین میزند. بهطور مشابه تخمین بازگشتی بیز، توابع توزیع احتمال ناشناخته را به صورت بازگشتی، با استفاده از اندازهگیریهای ورودی در مدل فرایندی ریاضی در طول زمان تخمین میزند.[۲۰]
در تخمین بازگشتی بیز، حالت فعلی یک فرایند مارکوف مشاهده نشده در نظر گرفته میشود و اندازهگیریهای مشاهده شده مدل پنهان مارکف (HMM) هستند.
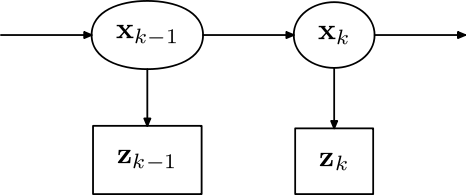
با فرض مارکوف، حالت فعلی سیستم مستقل از تمام حالات پیش از حالت قبلی آن است.

بهطور مشابه اندازهگیری در بازه زمانی kام تنها به حالت قبلی وابسته است و مستقل از تمام حالات پیش از حالت قبلی آن است.

با این مفروضات، توزیع احتمال تمام حالات مدل پنهان مارکوف به صورت زیر بیان میشود:

هدف فیلتر کالمن تخمین حالت فعلی سیستم است. این تخمین با استفاده از حاشیهسازی تابع توزیع مشترک بر اساس حالت قبلی سیستم قابل محاسبه است. کافی است حاشیهسازی نسبت به تمام حالات قبل انجام شده و بر احتمال مجموعه اندازهگیریها تقسیم شود.
به این ترتیب گامهای پیشبینی و آپدیت فیلتر کالمن به صورت احتمالاتی بدست میآیند. توزیع احتمال حالت پیشبینی شده حاصل انتگرال حاصلضرب توابع توزیع احتمال انتقال از حالت (k-1)ام به حالت kام است و حالت قبلی روی تمام های ممکن است.


اندازهگیریها تا بازه زمانی kام عبارتند از:

توزیع احتمال آپدیت از حاصلضرب پیشبینی و احتمال بخت (likelihood) بدست میآید.

بهطوریکه

ضریب نرمالسازی است.
توابع توزیع احتمال باقیمانده عبارتند از:



توجه کنید که تابع چگالی احتمال حالت قبل، یک تخمین است. فیلتر کالمن فیلتری بهینه است و به این ترتیب توزیع احتمال به شرط اندازهگیری یک تخمین بهینه توسط فیلتر کالمن است.


تعریف فیلتر کالمن (Kalman filter) قسمت 1
تعریف فیلتر کالمن (Kalman filter) قسمت 2

















