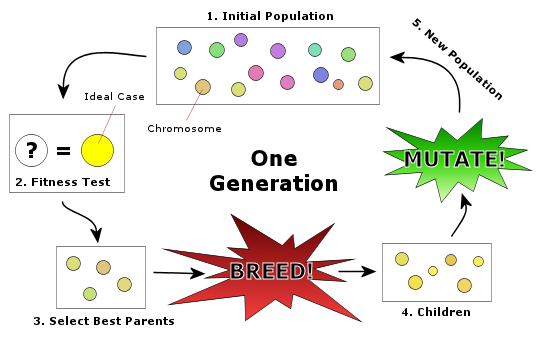
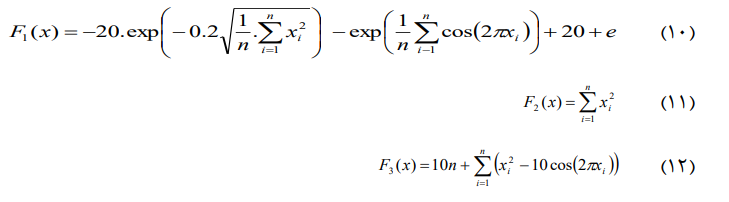استفاده از الگوریتم کندوی زنبور عسل در مسیر یابی بر اساس خوشه در شبکه های حسگر بیسیم
چکیده : با توجه به پیشرفت های اخیر فناوری ارتباطات بی سیم در چند دهه اخیر ، مطالعات کارشناسان در زمینه شبکه های گیرنده بی سیم هم سیر صعودی را طی کرده است.بسیاری از این بررسی ها در قالب کتب علمی ، الحاقیه ، الگوریتم و موارد کاربردی اجرا و اعمال شده اند. کارایی این شبکه ها به طور مستقیم به پروتکل های مسیریابی که روی زمان زندگی شبکه تآثیر می گذارند بستگی خواهد داشت. خوشه بندی یکی از رایج ترین روش های اجرایی در این مبحث تلقی می شود. ما در این مقاله به بررسی کارایی انرژی در پروتکل های بر پایه الگوریتم های کندوی زنبور عسل می پردازیم که نشان دهنده امتداد طول عمر شبکه می باشد. الگوریتم های کندوی زنبور عسل طوری طراحی شده اند که رفتارهای جستجوگرانه زنبورهای عسل را شبیه سازی کرد و به طور موفقیت آمیزی در تکنیک های خوشه بندی مورد استفاده قرار می گیرند. عملکرد این روش پیشنهادی با پروتکل های متکی بر LEACH و بهینه سازی گروهی اجزا که پیش از این مورد بررسی قرار گرفته اند ،مقایسه می شود. نتایج این بررسی ها نشان می دهد که الگوریتم های کندوی زنبور عسل میتواند در پروتکل های مسیریابی WSN روند موفقیت آمیزی داشته باشد.
کلمات کلیدی : شبکه های گیرنده بی سیم ، برپایه خوشه بندی ( خوشه ای ) ، الگوریتم زنبور عسل فایل PDF – در 22 صفحه
– نویسنده : ناشناس
دانلود
پسورد فایل : behsanandish.com
الگوریتم کلونی زنبور عسل مصنوعی
شامل سرفصل های :
1- الگوریتم کلونی زنبورعسل مصنوعی
2- معرفی چند الگوریتم بهینه شده کلونی زنبورعسل در محیط پیوسته
3- الگوریتم کلونی زنبورعسل مصنوعی موازی
4- الگوریتم کلونی زنبورعسل مصنوعی برای مسائل بهینه سازی دودویی
فایل Power Point – در 40 اسلاید – نویسنده : ناشناس
الگوریتم کلونی زنبور عسل مصنوعی
پسورد فایل : behsanandish.com
رویکرد الگوریتم فرا ابتکاری کلونی زنبور عسل مصنوعی برای تعیین مکان بهینه سوئیچها در شبکه ارتباطی تلفن همراه
چكيده : در این تحقیق برای حل مسئله ی تخصیص سلول به سوئیچ (CTSAP) ، از الگوریتم فراابتکاری کلونی زنبور عسل مصنوعی (ABC) استفاده شده است. هدف مسئله، تخصیص بهینه سلولها به سوئیچها با حداقل هزینه است. در این تحقیق هزینه از دو جزء تشکیل یافته است. یکی هزینه ی تعویضها که مربوط به دو سوئیچ است و دیگری هزینه ی اتصال میباشد. ظرفیت پاسخگویی تماس هر سوئیچ نیز محدود است و فرض میشود همه ی سوئیچها ظرفیت برابری داشته باشند. در مدل این پژوهش هر سلول باید فقط و فقط تنها به یک سوئیچ متصل گردد(single homed).مدل ریاضی این تحقیق، غیرخطی صفر و یک است. کد رایانه ای الگوریتم با نرم افزار MATLAB 7.8.0 نوشته شده است. پس از تعیین مقادیر پارامترهای مدل و تأیید صحت عملکرد کد و تنظیم پارامترهای کنترل، کارایی الگوریتم با ایجاد مسائل آزمایشی، با یکی از بهترین الگوریتمهای CTSAP یعنی الگوریتم بهینه سازی کلونی مورچگان (ACO) مقایسه شده است و نتایج نشان می دهد که الگوریتم ABC در قیاس با ACO عملکرد رضایت بخشی دارد.
واژگان کليدی: مسئله تخصیص سلول به سوئیچ، الگوریتم فراابتکاری، شبکههای تلفن همراه، الگوریتم کلونی زنبور عسل مصنوعی
فایل PDF – در 24 صفحه- نویسندگان : سيد محمد علی خاتمی فيروزآبادی , امين وفادار نيكجو
دانلود
پسورد فایل : behsanandish.com
ﮐﻠﻮﻧﯽ زﻧﺒﻮرﻫﺎي ﻣﺼﻨﻮﻋﯽ ﺳﻠﻮﻟﯽ
ﭼﮑﯿﺪه: در اﯾﻦ ﻣﻘﺎﻟﻪ دو ﻣﺪل ﺗﺮﮐﯿﺒﯽ ﮐﻪ از ﺗﺮﮐﯿﺐ ﮐﻠﻮﻧﯽ زﻧﺒﻮرﻫـﺎ و اﺗﻮﻣﺎﺗﺎي ﺳﻠﻮﻟﯽ ﺣﺎﺻﻞ ﺷﺪه اﺳﺖ ﺑﻪ ﻣﻨﻈﻮر ﺑﻬﯿﻨﻪ ﺳﺎزي ﭘﯿﺸﻨﻬﺎد ﻣﯽﮔﺮدد . اﺗﻮﻣﺎﺗـﺎي ﺳـﻠﻮﻟﯽ وﻇﯿﻔـﻪ ﮐـﺎﻫﺶ آﻧﺘﺮوﭘـﯽ و اﻓـﺰاﯾﺶ ﺳـﺮﻋﺖ ﻫﻤﮕﺮاﯾﯽ را ﺑﻪ ﻋﻬﺪه دارد . در ﻣـﺪل ﭘﯿﺸـﻨﻬﺎدي در اول ﻫـﺮ ﺳـﻠﻮل از اﺗﻮﻣﺎﺗﺎي ﯾﺎدﮔﯿﺮ ﺳﻠﻮﻟﯽ ﯾﮏ ﮐﻠﻮﻧﯽ از زﻧﺒﻮرﻫـﺎ ﻗـﺮار داده ﻣـﯽ ﺷـﻮد . ﺑـﻪ ﺑﺪﺗﺮﯾﻦ ﻫﺮﺳﻠﻮل ، ﻣﻨﻈﻮر ﺑﻬﺒﻮد ﺟﺴﺘﺠﻮي ﺳﺮاﺳﺮي و ﻫﻤﮕﺮاﯾﯽ ﺳﺮﯾﻌﺘﺮ ﺑﺎ ﺑﻬﺘﺮﯾﻦ ﻫﻤﺴﺎﯾﮕﺎن ﺑﻪ روش ﺣﺮﯾﺼﺎﻧﻪ ﺟﺎﯾﮕﺰﯾﻦ ﻣﯽ گردد. در ﻣﺮﺣﻠـﻪ دوم در ﻫﺮ ﺳﻠﻮل ﯾﮏ زﻧﺒﻮر ﻗﺮار ﻣـﯽ ﮔﯿـﺮد .ﻧﺘـﺎﯾﺞ آزﻣﺎﯾﺸـﻬﺎ ﺑـﺮ روي ﻣﺴﺎیل ﻧﻤﻮنه ﻧﺸﺎن ﻣﯿﺪﻫﺪ ﮐﻪ روش ﻫﺎی اراﺋﻪ ﺷﺪه از ﻋﻤﻠﮑﺮد ﺑﻬﺘـﺮي در ﻣﻘﺎﯾﺴﻪ ﺑﺎ ﻣﺪل ﮐﻠﻮﻧﯽ زﻧﺒﻮرﻫﺎي ﻣﺼﻨﻮعی اﺳﺘﺎﻧﺪارد ﺑﺮﺧﻮردار می باشد.
واژه ﻫﺎي ﮐﻠﯿﺪی : کلونی زنبور، اﺗﻮﻣﺎﺗﺎي ﺳﻠﻮﻟﯽ، بهینه سازی
فایل PDF – در 4 صفحه- نویسندگان : زهرا گل میرزایی ، محمدرضا میبدی
دانلود
پسورد فایل : behsanandish.com
یک بررسی جامع: الگوریتم و برنامه های کاربردی کلونی زنبور عسل (ABC)
A comprehensive survey: artificial bee colony (ABC) algorithm and applications
Abstract : Swarm intelligence (SI) is briefly defined as the collective behaviour of decentralized
and self-organized swarms. The well known examples for these swarms are bird
flocks, fish schools and the colony of social insects such as termites, ants and bees. In 1990s,
especially two approaches based on ant colony and on fish schooling/bird flocking introduced
have highly attracted the interest of researchers. Although the self-organization features are
required by SI are strongly and clearly seen in honey bee colonies, unfortunately the researchers
have recently started to be interested in the behaviour of these swarm systems to describe
new intelligent approaches, especially from the beginning of 2000s. During a decade, several
algorithms have been developed depending on different intelligent behaviours of honey bee
swarms. Among those, artificial bee colony (ABC) is the one which has been most widely
studied on and applied to solve the real world problems, so far. Day by day the number of
researchers being interested in ABC algorithm increases rapidly. This work presents a comprehensive
survey of the advances with ABC and its applications. It is hoped that this survey
would be very beneficial for the researchers studying on SI, particularly ABC algorithm.
,Keywords : Swarm intelligence
,Bee swarm intelligence
Artificial bee colony algorithm
فایل Power Point - در 37 صفحه - نویسندگان: Dervis Karaboga , Beyza Gorkemli , Celal Ozturk , Nurhan Karaboga
A comprehensive survey- artificial bee colony (ABC)
پسورد فایل : behsanandish.com
الگوریتم جستجوی کلونی زنبور عسل مصنوعی جهانی برای بهینه سازی تابع عددی
Global Artificial Bee Colony Search Algorithm for Numerical Function Optimization
Abstract—The standard artificial bee colony (ABC) algorithm as a relatively new swarm optimization method is often trapped in local optima in global optimization. In this paper, a novel search strategy of main three procedures of the ABC algorithm is presented. The solutions of the whole swarm are exploited based on the neighbor information by employed bees and onlookers in the ABC algorithm. According to incorporating all employed bees’ historical best position information of food source into the solution search equation, the improved algorithm that is called global artificial bee colony search algorithm has great advantages of convergence property and solution quality. Some experiments are made on a set of benchmark problems, and the results demonstrate that the proposed algorithm is more effective than other population based optimization algorithms. Keywords—Artificial bee colony, Search strategy, Particle swarm optimization, Function optimization فایل PDF – در 4 صفحه – نویسندگان : Guo Peng, Cheng Wenming, Liang Jian Global Artificial Bee Colony Search Algorithm for Numerical Function Optimization پسورد فایل : behsanandish.com
یک الگوریتم کلونی زنبور عسل مصنوعی اصلاح شده برای بهینه سازی مسائل محدود شده
A modified Artificial Bee Colony (ABC) algorithm for constrained optimization problems
Abstract : Artificial Bee Colony (ABC) algorithm was firstly proposed for unconstrained optimization problems on where that ABC algorithm showed superior performance. This paper describes a modified ABC algorithm for constrained optimization problems and compares the performance of the modified ABC algorithm against those of state-of-the-art algorithms for a set of constrained test problems. For constraint handling, ABC algorithm uses Deb’s rules consisting of three simple heuristic rules and a probabilistic selection scheme for feasible solutions based on their fitness values and infeasible solutions based on their viola- tion values. ABC algorithm is tested on thirteen well-known test problems and the results obtained are compared to those of the state-of-the-art algorithms and discussed. Moreover, a statistical parameter analysis of the modified ABC algorithm is conducted and appropriate values for each control parameter are obtained using analysis of the variance (ANOVA) and analysis of mean (ANOM) statistics. Keywords: Swarm intelligence Modified Artificial Bee Colony algorithm Constrained optimization فایل PDF – در 37 صفحه – نویسندگان : Dervis Karaboga , Bahriye Akay A modified Artificial Bee Colony (ABC) algorithm for constrained optimization1 پسورد فایل : behsanandish.com
یک الگوریتم کلونی زنبور عسل مصنوعی جدید-بر اساس فاصله داده های سریال با استفاده گرام های سیگما
ABC-SG: A New Artificial Bee Colony Algorithm-Based Distance of Sequential Data Using Sigma Grams
Abstract
The problem of similarity search is one of the main
problems in computer science. This problem has many
applications in text-retrieval, web search, computational
biology, bioinformatics and others. Similarity between
two data objects can be depicted using a similarity
measure or a distance metric. There are numerous
distance metrics in the literature, some are used for a
particular data type, and others are more general. In this
paper we present a new distance metric for sequential data
which is based on the sum of n-grams. The novelty of our
distance is that these n-grams are weighted using artificial
bee colony; a recent optimization algorithm based on the
collective intelligence of a swarm of bees on their search
for nectar. This algorithm has been used in optimizing a
large number of numerical problems. We validate the new
distance experimentally.
Keywords: Artificial Bee Colony, Extended Edit
Distance, Sequential Data, Distance Metric, n-grams.
فایل PDF – در 7 صفحه – نویسنده :Muhammad Marwan Muhammad Fuad
پسورد فایل : behsanandish.com
کاربرد الگوریتم کلونی زنبور عسل مصنوعی در جستجوی آزادسازی بهینه سد بزرگ آسوان
Application of artificial bee colony (ABC) algorithm in search of optimal release of Aswan High Dam
Abstract. The paper presents a study on developing an optimum reservoir release policy by using ABC algorithm. The decision maker of a reservoir system always needs a guideline to operate the reservoir in an optimal way. Release curves have developed for high, medium and low inflow category that can answer how much water need to be release for a month by observing the reservoir level (storage condition). The Aswan high dam of Egypt has considered as the case study. 18 years of historical inflow data has used for simulation purpose and the general system performance measuring indices has measured. The application procedure and problem formulation of ABC is very simple and can be used in optimizing reservoir system. After using the actual historical inflow, the release policy succeeded in meeting demand for about 98% of total time period. فایل PDF – در 8 صفحه – نویسندگان : Md S Hossain and A El-shafie Application of artificial bee colony (ABC) algorithm پسورد فایل : behsanandish.com
الگوریتم بهینه سازی کلونی زنبور عسل مصنوعی برای حل مشکلات بهینه سازی محدود
Artificial Bee Colony (ABC) Optimization Algorithm for Solving Constrained Optimization Problems
Abstract. This paper presents the comparison results on the performance of the Artificial Bee Colony (ABC) algorithm for constrained optimization problems. The ABC algorithm has been firstly proposed for unconstrained optimization problems and showed that it has superior performance on these kind of problems. In this paper, the ABC algorithm has been extended for solving constrained optimization problems and applied to a set of constrained problems . فایل PDF – در 10 صفحه – نویسندگان : Dervis Karaboga and Bahriye Basturk Artificial Bee Colony (ABC) Optimization پسورد فایل : behsanandish.com
الگوریتم کلونی زنبور عسل مصنوعی و کاربردش در مشکل تخصیص انتزاعی
Artificial Bee Colony Algorithm and Its Application to Generalized Assignment Problem
فایل PDF – در 32 صفحه – نویسندگان : Adil Baykasoùlu, Lale Özbakır and Pınar Tapkan Artificial Bee Colony Algorithm and Its پسورد فایل : behsanandish.com
الگوریتم کلونی زنبور عسل مصنوعی
Artificial Bee Colony Algorithm
Contents
• Swarm Intelligence – an Introduction
• Behavior of Honey Bee Swarm
• ABC algorithm
• Simulation Results
• Conclusion
فایل PDF از یک فایل Power Point – در 22 اسلاید- نویسنده : ناشناس
پسورد فایل : behsanandish.com
بهینه سازی کلونی زنبور عسل پارت 1: مرور الگوریتم
BEE COLONY OPTIMIZATION PART I: THE ALGORITHM OVERVIEW
,Abstract: This paper is an extensive survey of the Bee Colony Optimization (BCO) algorithm proposed for the first time in 2001. BCO and its numerous variants belong to a class of nature-inspired meta–heuristic methods, based on the foraging habits of honeybees. Our main goal is to promote it among the wide operations research community. BCO is a simple, but ecient meta–heuristic technique that has been successfully applied to many optimization problems, mostly in transport, location and scheduling fields. Firstly, we shall give a brief overview of the meta–heuristics inspired by bees’ foraging principles, pointing out the dierences between them. Then, we shall provide the detailed description of the BCO algorithm and its modifications, including the strategies for BCO parallelization, and give the preliminary results regarding its convergence. The application survey is elaborated in Part II of our paper. Keywords: Meta–heuristics, Swarm Intelligence, Foraging of Honey Bees فایل PDF- در24 صفحه – نویسندگان : Tatjana DAVIDOVI´ C , Duˇsan TEODOROVI´ C , Milica ˇSELMI´ C BEE COLONY OPTIMIZATION PART I پسورد فایل : behsanandish.com
")




![[عکس: 34b5ae95f23a0378679d434d7cea3360.png]](http://upload.wikimedia.org/wikipedia/fa/math/3/4/b/34b5ae95f23a0378679d434d7cea3360.png)
![[عکس: a9be4f8956d1bb85c9e932c584196743.png]](http://upload.wikimedia.org/wikipedia/fa/math/a/9/b/a9be4f8956d1bb85c9e932c584196743.png)