شناسایی حروف توسط شبکه های عصبی
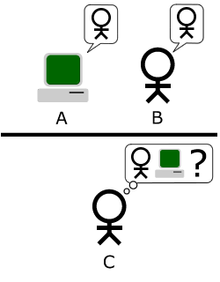
تو این مطلب می خواهیم بصورت عملی از شبکه های عصبی استفاده کنیم! واقعا خیلی جالبه می خوایم به کامپیوتر سه تا حرف الفبای انگلیسی رو یاد بدیم.
نکته ی جالب تر این هست که حتی به کامپیوتر نمی گیم هر کدوم از حرف ها چی هستن! فقط بهش می گیم که این ها سه حرف مختلف هستند! و کامپیوتر خودش تشخیص می ده هر کدوم متعلق به کدوم گروه هست! به این نوع طبقه بندی اصطلاحا Unsupervised میگویند.
سوال : به نظر میرسه باید توی مثال هامون به کامپیوتر بگیم مثلا این A هست و این B هست!
جواب : اون هم نوعی یادگیری هست که بهش اصطلاحا Supervised می گن. اما توی این مثال حالت جالب تر یعنی Unsupervised رو می خوایم بررسی کنیم. به این صورت که فقط به کامپیوتر می گیم ۳ دسته وجود داره و براش چندین مثال می زنیم و خودش مثال ها رو توی ۳ دسته قرار می ده! در نهایت ما مثلا می تونیم بگیم همه ی مثال هایی که در دسته ی دوم قرار گرفتن A هستند.
شاید جالب باشه بدونید گوگل هم برای دسته بندی اطلاعات از همچین روشی استفاده می کنه! البته کمی پیشرفته تر. مثلا ۱۰۰ متن اقتصادی و ۱۰۰ متن ورزشی به کامپیوتر میده و از کامپیوتر می خواد اونها رو به ۲ بخش تقسیم بندی بکنه! ورودی لغت های اون متن ها هستند. “
ابزار مورد نیاز
برای این که شروع کنیم به چند مورد نیاز داریم:
- در مورد هوش مصنوعی و شبکه های عصبی یکم اطلاعات داشته باشید.
- برنامه ای برای تولید الگو که ورودی شبکه ی عصبی ما خواهد بود. این برنامه رو میتونید از اینجا تهیه کنید.
- نرم افزار JOONE Editor. عبارت JOONE مخفف Java Object Oriented Neural Engine هست. که یک ابزار قدرت مند برای بوجود آوردن و آموزش انواع شبکه های عصبی در Java هست. توی این آموزش ما از ویرایشگر این ابزار استفاده می کنیم که محیطی گرافیکی برای تولید شبکه های عصبی داره و کار با اون بسیار ساده هست. این ابزار از اینجا قابل دریافت هست. بدیهیه که برای نصب این ابزار ابتدا باید جاوا روی کامپیوتر شما نصب باشه.
- کمی پشتکار و حوصله.
لینک جایگزین برای دانلود JOONE Editor:
https://sourceforge.net/projects/joone/files/
حالا می خوایم یک سری الگو تولید کنیم. الگو همون مثال هایی هست که گفتیم برای کامپیوتر می زنیم تا بتونه یاد بگیره.
برای این کار از برنامه ای که در شماره ی ۲ ابزارها معرفی کردم استفاده می کنیم. این برنامه خیلی ساده کار می کنه و فقط الگو ها رو از حالت تصویری به ۰ و ۱ تبدیل می کنه.
روش کار به این صورت هست که اول تصویر رو به یک ماتریس ۸ در ۸ تقسیم می کنه. یعنی ۶۴ قسمت. وقتی دکمه ی سمت چپ ماوس پایینه در صورتی که ماوس از هر کدوم از اون ۶۴ بخش رد بشه اون بخش رو داخل ماتریس علامت گذاری می کنه (مقدار اون قسمت رو True می کنه). وقتی دکمه ی Learn زده می شه برنامه مقدار تمام قسمت ها رو از بالا به پایین داخل یک فایل ذخیره می کنه. مقدار هر قسمت می تونه ۰ یا False و ۱ یا True باشه. ”
در صورتی که سورس این برنامرو خواستید کافیه توی بخش نظرات بگید تا براتون میل کنم.
کار با این برنامه خیلی آسون هست همونطور که توی شکل مشخصه.
کافیه الگویی که دوست دارید رو داخل فضای سفید بکشید و دکمه ی Learn رو بزنید. Textbox پایینی برای تغییر دادن آدرس فایلی هست که اطلاعات توی اون ذخیره میشه. و Textbox بالایی برای اینه که بگید این الگو چه حرفی هست که توی این مطلب نیازی به پر کردن اون نیست چون ما بحثمون یادگیری Unsupervised هست. توی مطالب بعدی برای یادگیری Supervised به این فیلد نیاز خواهیم داشت.
خوب من برای اینکه مثال پیچیده نشه ۳ حرف رو می خوام به کامپیوتر یاد بدم. A و C و Z!
برای این کار برای هر کدوم از حروف چهار مثال وارد می کنم و دکمه ی Learn رو می زنم. توی شکل زیر می تونید هر ۱۲ الگو رو ببینید.
فایل خروجی مربوط به این الگوهای مثال از اینجا قابل دریافت هست.همونطور که می بینید هر ردیف به نظر من و شما عین هم هستند. اما اگر کمی بیشتر دقت کنیم می بینیم جای مربع های مشکی با هم فرق دارن. به نظر شما کامپیوتر هم خواهد فهمید هر ردیف نشاندهنده ی یک حرف مجزا هست؟
تشکیل شبکه ی عصبیخوب! حالا می خواهیم ساختار شبکه ی عصبی رو طراحی کنیم. برای این کار از JOONE Editor کمک می گیریم.
صفحه ی اول این نرم افزار به این شکل هست:
توی این مثال ما از یک لایه ی ورودی خطی ۶۴ نورونی استفاده می کنیم که هر نورون یک قسمت از ماتریسی که در بخش قبل گفتیم رو به عنوان ورودی می گیره. به عنوان خروجی هم از یک لایه ی ۳ نورونی WinnerTakeAll استفاده می کنیم. در این نوع خروجی یکی از نورون ها ۱ و بقیه ۰ خواهند بود که برای تقسیم بندی بسیار مناسب هست.
برای شروع ابتدا یک لایه ی FileInput ایجاد می کنیم. توسط این ابزار می تونیم یک فایل رو به عنوان ورودی به شبکه بدیم.
روی FileInput کلیک راست کرده و در Properties اون فایل درست شده در مرحله ی قبلی رو به عنوان fileName انتخاب می کنیم و به عنوان Advanced Column Selector مقدار 1-64 رو وارد می کنیم تا برنامه متوجه بشه باید از ستون های ۱ تا ۶۴ به عنوان ورودی استفاده کنه.
ایجاد یک لایه ی خطی:
مرحله ی بعدی ایجاد یک Linear Layer یا لایه ی خطی هست. بعد از ایجاد این لایه Properties اون باید به شکل زیر باشه:
همونطور که می بینید تعداد ردیف ها ۶۴ مقداردهی شده که دلیلش این هست که ۶۴ ورودی داریم.
حالا با انتخاب FileInput و کشیدن نقطه ی آبی رنگ سمت راست اون روی Linear Layer خروجی FileInput یعنی اطلاعات فایل رو به عنوان ورودی Linear Layer انتخاب می کنیم.
تا این لحظه ما یک لایه ی ۶۴ نورونه داریم که ورودی اون مقادیر مثال های تولید شده در مرحله ی قبل هست.
ایجاد لایه ی WinnerTakeAll :
خوب توی این مرحله لایه ی خروجی که یک لایه ی WinnerTakeAll هست رو تولید می کنیم. Properties این لایه باید به شکل زیر تغییر پیدا کنه تا اطمینان پیدا کنیم الگوها به سه دسته تقسیم میشن:
حالا باید بین لایه ی خطی و لایه ی WinnerTakeAll ارتباط برقرار کنیم. برای این کار باید از Kohonen Synapse استفاده کنیم و Full Synapse جواب نخواهد داد. پس روی دکمه ی Kohonen Synapse کلیک کرده و بین لایه ی خطی و لایه ی WinnerTakeAll ارتباط ایجاد می کنیم.
در آموزش های بعدی فرق انواع سیناپس ها رو بررسی خواهیم کرد.آموزش شبکه
تا این لحظه شبکه باید به این شکل باشه. حالا می تونیم آموزش شبکرو شروع کنیم. برای این کار در منوی Tools بخش Control Panel رو انتخاب می کنیم. و در صفحه ی جدید learningRating و epochs و training pattern و learning رو به شکل زیر تغییر می دیم.
epochs تعداد دفعاتی که مرحله ی آموزش تکرار میشرو تعیین می کنه.
learningRate ضریبی هست که در یادگیری از اون استفاده می شه. بزرگ بودن اون باعث میشه میزان تغییر وزن نورون ها در هر مرحله بیشتر بشه و سرعت رسیدن به حالت مطلوب رو زیاد می کنه اما اگر مقدار اون خیلی زیاد شه شبکه واگرا خواهد شد.
training patterns هم تعداد الگو هایی که برای آموزش استفاده می شن رو نشون می ده که در این مثال ۱۲ عدد بود.
بعد از اینکه تمام تغییرات رو ایجاد کردیم دکمه ی Run رو می زنیم و منتظر می شیم تا ۱۰۰۰۰ بار عملیات یادگیری انجام بشه.
تبریک می گم! شما الان به کامپیوتر سه حرف A و C و Z رو یاد دادید!
اما خوب حالا باید ببینید کامپیوتر واقعا یاد گرفته یا نه.
برای این کار از یک لایه ی FileOutput استفاده می کنیم تا خروجی شبکرو داخل یک فایل ذخیره کنیم.
Properties لایه ی FileOutput باید بصورت زیر باشه:
همونطور که می بینید به عنوان fileName مقدار c:\output.txt رو دادیم. یعنی خروجی شبکه در این فایل ذخیره میشه.
حالا کافیه لایه ی WinnerTakeAll رو به لایه ی FileOutput متصل کنیم.
بعد از متصل کردن این دو لایه شکل کلی باید بصورت زیر باشه:
برای اینکه فایل خروجی ساخته بشه باید یک بار این شبکرو اجرا کنیم. برای این کار مجددا در منوی Tools بخش Control Panel رو انتخاب می کنیم و در اون learning رو False و epochs رو ۱ می کنیم تا شبکه فقط یک بار اجرا شه. پس از تغییرات این صفحه باید به شکل زیر باشه:
حالا با توجه به اینکه من اول چهار مثال A رو وارد کردم و بعد به ترتیب چهار مثال C و چهار مثال Z رو ببینیم خروجی این شبکه به چه شکل شده.
باور کردنی نیست! خروجی به این شکل در اومده:
1.0;0.0;0.0
1.0;0.0;0.0
1.0;0.0;0.0
0.0;1.0;0.0
0.0;1.0;0.0
0.0;1.0;0.0
0.0;1.0;0.0
0.0;0.0;1.0
0.0;0.0;1.0
0.0;0.0;1.0
0.0;0.0;1.0
همونطور که می بینید ۴ خط اول که مربوط به A هستن ستون اولشون ۱ هست و در چهار خط دوم ستون دوم و در چهار خط سوم ستون سوم!
این یعنی کامپیوتر بدون اینکه کسی به اون بگه کدوم مثال ها کدوم حرف هست خودش فهمیده و اون ها رو دسته بندی کرده.
سوال : ممکنه چون پشت هم دادید مثال هر حرف رو اینطوری نشده؟
جواب : نه! کامپیوتر که نمی دونسته من می خوام مثال های هر حرف رو پشت سر هم بدم! من برای راحتی خودم این کار رو کردم. شما می تونی ورودی هاتو غیر مرتب بدی!
سوال : دلیل خاصی داره که در A ستون اول ۱ هست و …
جواب : نه! ممکن بود برای A ستون دوم ۱ بشه و یا هر حالت دیگه. شما اگر امتحان کنید ممکنه تفاوت پیدا کنه. اما مهم اینه در تمام A ها یک ستون خاص مقدارش ۱ و بقیه ی ستون ها مقدارشون صفر می شه. پس یعنی کامپیوتر تونسته به خوبی تقسیم بندی کنه.
حالا می خوایم شبکرو با سه مثال جدید تست کنیم که در مثال های آموزشی نبوده! برای این کار من با استفاده از برنامه ی تولید الگو ۳ مثال جدید درست می کنم و به عنوان فایل ورودی در شبکه فایل جدید رو انتخاب می کنم.
توی شکل زیر سه مثال جدید رو می تونید ببینید:
برای جذابیت علاوه بر این سه مثال ۲ مثال دیگه هم که حروف خاصی نیستند گذاشتم!
فایل خروجی این مثال ها از اینجا قابل دریافت هست.
خوب حالا بگذارید ببینیم کامپیوتر چه جوابی می ده. با توجه به اینکه اول مثال C بعد مثال Z و بعد مثال A رو وارد کردم. دو مثال بعدی هم به ترتیب مثال بد خط سمت چپ و مثال بد خط سمت راست هستند. و اما جواب:
0.0;1.0;0.0
0.0;0.0;1.0
1.0;0.0;0.0
0.0;0.0;1.0
0.0;1.0;0.0
کامپیوتر سه مورد اول رو به خوبی C و Z و A تشخیص داده. و دو مورد بد خط هم به ترتیب از چپ به راست Z و C تشخیص داده!
حتی برای انسان هم سخته فهمیدن اینکه مورد های چهارم و پنجم چی هستند اما اگر خوب دقت کنید می بینید به مواردی که کامپیوتر خروجی داده نزدیک تر هستند.
کامپیوتر شعور نداره! اما ما سعی کردیم طریقه ی عملکرد مغز رو به صورت خیلی ابتدایی و به ساده ترین نحو توش شبیه سازی کنیم! ”
تو این مطلب دیدیم که کامپیوتر تونست بدون اینکه ما براش مثال هایی بزنیم و بگیم هر کدوم چه حرفی هستند و فقط با دادن تعداد دسته ها، مثال ها رو به سه دسته همونطوری که انسان ها تقسیم می کنند تقسیم کنه. همونطور که گفتیم به این نوع دسته بندی، دسته بندی Unsupervised میگن.
منبع






![[عکس: 34b5ae95f23a0378679d434d7cea3360.png]](http://upload.wikimedia.org/wikipedia/fa/math/3/4/b/34b5ae95f23a0378679d434d7cea3360.png)
![[عکس: a9be4f8956d1bb85c9e932c584196743.png]](http://upload.wikimedia.org/wikipedia/fa/math/a/9/b/a9be4f8956d1bb85c9e932c584196743.png)






