منطق فازی (fuzzy logic) چیست؟
ایده اصلی مربوط به منطق فازی اولین بار توسط پروفسور لطفی زاده در دانشگاه برکلی و در دهه 60 میلادی ارائه شد. دکتر لطفی زاده در آن زمان بر روی مسئله در ک زبان انسان توسط کامپیوتر کار می کرد. زبان طبیعی انسان( مانند بیشتر فعالیت ها در زندگی و جهان هستی) به آسانی به مقادیر مطلق 0 و 1 تبدیل نمی شود( این که ایا همه چیز را می توان در نهایت به صورت جمله های دوتایی(باینری) توصیف کرد سوالی فلسفی است که ارزش پیگیری دارد اما در عمل بیشتر داده هایی که می خواهیم به صورت ورودی در اختیار کامپیوتر قرار دهیم و همچنین در اغلب موارد نتایج آن نیز حالتی بینابینی دارد). شاید تصور منطق فازی به عنوان راه اصلی استدلال و در نظر گرفتن منطق بولی به عنوان یک حالت خاص از آن بتواند به درک بهتر موضوع کمک کند.
منطق فازی 0 و 1 را به عنوان حالت های مفرط حقیقت (واقعیت) در نظر می گیرند اما چندین حالت درستی نیز در بین این دو حالت قرار می گیرد مثلا نتیجه مقایسه بین دو چیز ممکن است نه کوتاه یا بلند بودن آن ها بلکه 0.38 بلندتر بودن یکی از آن ها باشد.
منطق فازی به روش کار کردن مغز ما نزدیک تر است. ما داده ها را در کنار هم جمع می کنیم و حقایقی جزئی را ایجاد می کنیم. این حقایق جزئی در ادامه در کنار هم جمع می شوند تا به حقیقت های مرتبه بالاتری تبدیل شوند به طوری که وقتی از حد معینی می گذرند نتایجی مانند واکنش های حرکتی را در بر خواهند داشت. فرآیند مشابهی در شبکه های عصبی، سیستم های خبره و سایر کاربرد های ان در هوش مصنوعی مورد استفاده قرار می گیرد. منطق فازی برای توسعه توانایی انسان گونه در هوش مصنوعی ضروری است. این قابلیت که گاهی مواقع به عنوان هوش مصنوعی عمومی از آن یاد می شود نمایش کلی توانایی های شناختی انسان در نرم افزار به گونه ای است که وقتی سیستم هوش مصنوعی با شرایط ناآشنا روبرو شد بتواند راه حلی پیدا کند.
هوش مصنوعی – سیستم های منطق فازی
سیستم های منطق فازی (FLS) در پاسخ به ورودی ناقص، مبهم، تحریف شده و یا غیر دقیق، خروجی قابل قبول ولی مشخصی تولید می کنند.
در تعریفی دیگر میتوان گفت که منطق فازی نوعی روش استدلال است که به نحوه استدلال کردن انسان شباهت دارد. رویکرد منطق فازی از روش تصمیم گیری انسان ها تقلید می کند و در آن همه حالت های میانی ممکن بین مقادیر دیجیتالی “بله” و “خیر” در نظر گرفته می شوند.
بلوک منطقی متعارفی که کامپیوتر می تواند آن را درک کند یک ورودی مشخص دریافت می کند و یک خروجی معین و قطعی به صورت صحیح یا غلط تولید می کند که در واقع معادل بله و خیر در انسان ها است.
لطفی زاده، ابداع کننده منطق فازی مشاهده کرد که بر خلاف کامپیوتر ها فرآیند تصمیم گیری در انسان شامل بازه ای از حالات ممکن بین بله و خیر است، مثل:
- قطعا بله
- احتمالا بله
- نمی توان گفت
- احتمالا خیر
- قطعا خیر
منطق فازی بر روی سطوح احتمال موجود برای ورودی کار می کند تا بتواند به یک خروجی معین و قطعی برسد.
اجرا
از این روش می توان در سیستم های با ابعاد و توانایی مختلف، از ریزکنترل کننده ها گرفته تا سیستم های کنترلی بزرگ و شبکه شده ، استفاده کرد.
از این روش می توان در سخت افزار ها، نرم افزار ها و یا ترکیبی از آن ها استفاده کرد.
چرا منطق فازی؟
- منطق فازی برای اهداف تجاری و کاربردی بسیار مفید است.
- ی تواند ماشین آلات و محصولات تولیدی را کنترل کند.
- ممکن است از استدلال دقیق استفاده نکند اما از استدلالی قابل قبول ارائه خواهد کرد.
- منطق فازی در حل مشکل عدم قطعیت در علوم مهندسی به ما کمک خواهد کرد.
معماری سیستم های منطق فازی
این سیستم دارای 4 بخش اصلی است که در ادامه تشریح خواهند شد:
1. مدول فازی ساز:
این مدول ورودی های سیستم را که به صورت عددی هستند به مجموعه های فازی تبدیل می کند. این مدول سیگنال ورودی را به 5 حالت تقسیم می کند:
| X عددی مثبت و بزرگ است | LP |
| X عددی مثبت و متوسط است | MP |
| X کوچک است | S |
| X عددی منفی و متوسط است | MN |
| X عددی منفی و بزرگ است | LN |
2. پایگاه دانش:
محلی است که دستورات “اگر- آنگاه” که توسط کارشناسان ایجاد شده اند در آن ذخیره می شود.
3. موتور استنتاج:
در این بخش فرآیند استدلالی انسان به وسیله نتیجه گیری های فازی از ورودی ها و دستورات شرطی شبیه سازی می شود.
4. مدول غیرفازی ساز:
این بخش مجموعه فازی که توسط موتور استنتاجی به دست آمده را به یک مقدار عددی تبدیل می کند.

توابع عضویت بر روی مجموعه متغیر های فازی عمل می کنند.
تابع عضویت
تابع عضویت به شما اجازه می دهد تا یک واژه زبانی را کمی سازی کرده و یک مجموعه فازی را به صورت نموداری نمایش دهید. یک تابع عضویت برای مجموعه فازی A در دامنه سخن Universe of Discourse) X) به شکل روبرو تعریف می شود: [µA:X →0,1]
در این حالت هر المان از X به مقداری بین صفر و یک نگاشته می شود که به آن مقدار عضویت یا درجه عضویت گفته می شود. این مقدار نمایش کمی درجه عضویت المان موجود در X را نسبت به مجموعه فازی A نشان می دهد.
- محور x دامنه سخن را نشان می دهد
- محور y درجه عضویت را در بازه صفر تا یک نمایش می دهد.
برای فازی سازی یک مقدار عددی می توان از چند تابع عضویت استفاده کرد. معمولا از توابع عضویت ساده استفاده می شود زیرا توابع پیچیده دقت بیشتری را برای خروجی به همراه ندارند.
همه توابع عضویت برای LP, MP, S, MN, و LN در شکل زیر نمایش داده شده اند.

توابع عضویت با شکل مثلثی در میان توابع با شکل های دیگر نظیر ذوزنقه ای ، گاوسی و… متداول ترین هستند.
در اینجا، مقدار ورودی برای فازی ساز پنج مرحله ای از 10- ولت تا 10+ ولت تغییر می کند. به همین دلیل خروجی مربوط به هر ورودی نیز تغییر می کند.
مثالی از سیستم منطق فازی
بیایید یک سیستم تهویه هوا را با سیستم منطق فازی 5 مرحله ای بررسی کنیم. این سیستم دمای سیستم تهویه را به کمک مقایسه دمای اتاق و دمای موردنظر، تنظیم می کند.

الگوریتم
تعریف متغیر های زبانی و عبارت های مربوطه
تعریف توابع عضویت برای آن ها
تشکیل پایگاه دستورات
تبدیل داده های عددی به مجموعه داده های فازی با استفاده از توابع عضویت (فازی سازی)
ارزیابی دستورات موجود در پایگاه دستورات ( موتور استنتاجی)
ترکیب کردن نتایج به دست آمده از هر دستور با سایر نتایج (موتور استنتاجی)
تبدیل داده خروجی به مقادیر غیر فازی (غیر فازی سازی)
توسعه منطق
مرحله 1 : تعریف متغیر ها و عبارت های زبانی
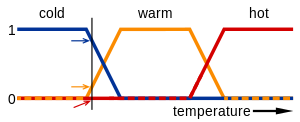
متغیر های زبانی، متغیر های ورودی و خروجی به شکل کلمات و یا جمله های ساده هستند. برای دمای اتاق، سرد، گرم، خیلی گرم و… عبارت های زبانی محسوب می شوند.
دما (t) = {خیلی سرد، سرد، گرم، خیلی گرم، فوق العاده گرم}
هر عضو از این مجموعه یک عبارت زبانی به شمار می رود و می تواند بخشی از مقادیر کلی دمای اتاق را پوشش دهد.
مرحله 2: تعریف توابع عضویت
توابع عضویت متغیر دما در شکل زیر نشان داده شده اند:

مرحله 3: تشکیل پایگاه دستورات
دراین مرحله یک ماتریس از مقادیر دمای اتاق در برابر دمای مطلوب اتاق که یه سیستم تهویه هوا باید آن را تامین کند تشکیل داده می شود .
| فوق العاده گرم | خیلی گرم | گرم | سرد | خیلی سرد | دمای اتاق/ دمای مطلوب |
| افزایش دما | افزایش دما | افزایش دما | افزایش دما | بدون تغییر | خیلی سرد |
| افزایش دما | افزایش دما | افزایش دما | بدون تغییر | کم کردن دما | سرد |
| افزایش دما | افزایش دما | بدون تغییر | کم کردن دما | کم کردن دما | گرم |
| افزایش دما | بدون تغییر | کم کردن دما | کم کردن دما | کم کردن دما | خیلی گرم |
| بدون تغییر | کم کردن دما | کم کردن دما | کم کردن دما | کم کردن دما | فوق العاده گرم |
سپس مجموعه ای از دستورات شرطی به فرم “اگر- آنگاه- در غیر این صورت” در پایگاه دستورات تشکیل می شود.
| نوع عملکرد | شرط | شماره دستور |
| افزایش دما | اگر دما= (سرد یا خیلی سرد) و دمای مطلوب = گرم… آنگاه | 1 |
| کاهش دما | اگر دما= (خیلی گرم یا فوق العاده گرم) و دمای مطلب = گرم…آنگاه | 2 |
| بدون تغییر | اگر دما=( گرم) و دمای مطلوب = گرم… آنگاه | 3 |
مرحله 4: به دست آوردن مقادیر فازی
عملیات مجموعه های فازی ارزیابی دستورات موجود را به عهده می گیرند. عملیات مورد استفاده برای “یا” و “و” به ترتیب Maxو Min هستند. نتایج همه شرایط با یکدیگر ترکیب می شوند تا نتیجه نهایی بدست بیاید. این نتیجه یک مقدار فازی است.
مرحله 5: اجرای عملیات غیرفازی سازی
در نهایت عملیات غیر فازی سازی با توجه به تابع عصویت برای متغیر خروجی انجام می شود.

حوزه کاربرد منطق فازی
سیستم های خودرو:
گیربکس های اتوماتیک
فرمان پذیری چهار چرخ
کنترل محیط زیست وسیله نقلیه
کالا های الکترونیکی:
سیستم های Hi-fi
دستگاه های فتوکپی
دوربین های عکاسی و فیلم برداری
تلویزیون
لوازم خانگی
مایکروویو ها
یخچال ها
توستر ها
جاروبرقی ها
ماشین های ظرف شویی
کنترل کننده های محیطی
سیستم های تهویه هوا
مرطوب کننده ها
نقاط قوت سیستم های منطق فازی
مفاهیم ریاضی با استفاده از استدلال های فازی بسیار ساده هستند.
می توانید یک سیستم منطق فازی را به دلیل انعطاف پذیر بودن منطق فازی با اضافه کردن و یا حذف برخی از قوانین تغییر دهید.
سیستم های منطق فازی می توانند اطلاعات ورودی غیر دقیق، مغشوش و یا نویزدار را دریافت کنند.
ساخت ودرک این سیستم ها بسیار راحت است.
منطق فازی راه حلی برای مسائل پیچیده در همه زمینه ها حتی پزشکی نیز می باشد زیرا شبیه به فرایند استدلال و تصمیم گیری انسان است.
نقاط ضعف سیستم های منطق فازی
هیچ رویکرد سیستماتیکی برای طراحی سیستم های فازی وجود ندارد.
درک آن ها تنها در صورتی امکان پذیر است که ساده باشند.
برای مسائلی مناسب هستند که به دقت بالا نیاز ندارند.
منطق فازی (Fuzzy Logic) قسمت 1
منطق فازی (Fuzzy Logic) قسمت 2
![[عکس: 6.gif]](http://www.syavash.com/portal/files/siavash/blogs/farsi-what-is-artificial-intelligence/6.gif)
![[عکس: 7.gif]](http://www.syavash.com/portal/files/siavash/blogs/farsi-what-is-artificial-intelligence/7.gif)
![[عکس: 8.gif]](http://www.syavash.com/portal/files/siavash/blogs/farsi-what-is-artificial-intelligence/8.gif)
![[عکس: 9.gif]](http://www.syavash.com/portal/files/siavash/blogs/farsi-what-is-artificial-intelligence/9.gif)
![[عکس: 10.gif]](http://www.syavash.com/portal/files/siavash/blogs/farsi-what-is-artificial-intelligence/10.gif)
![[عکس: 11.gif]](http://www.syavash.com/portal/files/siavash/blogs/farsi-what-is-artificial-intelligence/11.gif)





![{\displaystyle [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/738f7d23bb2d9642bab520020873cccbef49768d)