یادگیری تحت نظارت
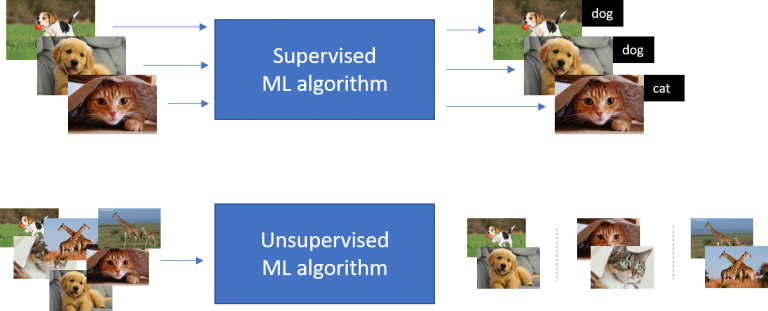
یادگیری با نظارت یا یادگیری تحت نظارت (Supervised learning) یکی از زیرمجموعههای یادگیری ماشینی است. با یک مثال عمومی وارد این بحث میشویم. یک میوه فروشی را در نظر بگیرید که تمام میوه ها را به صورت کاملاً جدا از هم مرتب کردهاست و شما نوع میوه را کاملاً میدانید، یعنی زمانی که یک میوه را در دست میگیرید به نام نوشته شده در قفسهٔ آن نگاه میکنید و در میابید که مثلاً سیب است و اصطلاحاً میگویند تمام داده ها تگ گذاری شده هستند. به طبع فردی از قبل دستهٔ دادهها را مشخص کردهاست. حال اگر با دید موجودی در حال یادگیری به ماجرا نگاه کنیم، انتظار میرود فرضاً مفهومی از سیبها را یاد بگیرد و احتمالاً در آینده نیز اگر تصویری از سیبها دید آن را تشخیص دهد.
این روش، یک روش عمومی در یادگیری ماشین است که در آن به یک سیستم، مجموعه ای از جفتهای ورودی – خروجی ارائه شده و سیستم تلاش میکند تا تابعی از ورودی به خروجی را فرا گیرد. یادگیری تحت نظارت نیازمند تعدادی داده ورودی به منظور آموزش سیستم است. با این حال ردهای از مسائل وجود دارند که خروجی مناسب که یک سیستم یادگیری تحت نظارت نیازمند آن است، برای آنها موجود نیست. این نوع از مسائل چندان قابل جوابگویی با استفاده از یادگیری تحت نظارت نیستند. یادگیری تقویتی مدلی برای مسائلی از این قبیل فراهم میآورد. در یادگیری تقویتی، سیستم تلاش میکند تا تقابلات خود با یک محیط پویا را از طریق آزمون و خطا بهینه نماید. یادگیری تقویتی مسئلهای است که یک عامل که میبایست رفتار خود را از طریق تعاملات آزمون و خطا با یک محیط پویا فرا گیرد، با آن مواجه است. در یادگیری تقویتی هیچ نوع زوج ورودی- خروجی ارائه نمیشود. به جای آن، پس از اتخاذ یک عمل، حالت بعدی و پاداش بلافصل به عامل ارائه میشود. هدف اولیه برنامهریزی عاملها با استفاده از تنبیه و تشویق است بدون آنکه ذکری از چگونگی انجام وظیفه آنها شود.
یک مجموعه از مثالهای یادگیری وجود دارد بازای هر ورودی، مقدار خروجی یا تابع مربوطه نیز مشخص است. هدف سیستم یادگیر بدست آوردن فرضیهای است که تابع یا رابطه بین ورودی یا خروجی را حدس بزند به این روش یادگیری با نظارت گفته میشود.
مثالهای زیادی در یادگیری ماشینی وجود دارند که در دسته یادگیری با نظارت میگنجند، از جمله میتوان به درخت تصمیمگیری، آدابوست، ماشین بردار پشتیبانی، دستهبندیکننده بیز ساده، رگرسیون خطی، رگرسیون لجستیک، گرادیان تقویتی، شبکههای عصبی و بسیاری مثالهای دیگر اشاره کرد.
منبع
در این قسمت می خواهیم در رابطه با یادگیری های نظارتی و بی نظارت توضیح دادیم.
- supervised learning = یادگیری با نظارت
- unsupervised learning = یادگیری بدون نظارت
پیش از این یادگیری با نظارت را اینگونه تعریف کردیم:
این مدل ماشین با استفاده از داده های برچسب گذاری شده و داشتن جواب های درست یاد می گیرند که در لاتین به آن Supervised learning می گویند.
مثال های مختلفی از یادگیری ماشین با نظارت:
یکی از مثال های مرسوم در یادگیری با نظارت تشخیص و فیلتر کردن اسپم ها میان پیام ها است. ابتدا تمامی داده ها به دو کلاس سالم و اسپم تقسیم می شوند، سپس ماشین آن ها را با مثال های موجود می آموزد در نهایت از او امتحان گرفته می شود و امتحان به این منظور تلقی می شود که شما ایمیل جدیدی که تا به حال ندیده است را به آن بدهید، سپس آن تشخیص دهد که سالم یا اسپم است.
نمونه دیگری از این دست یادگیری می توان زد پیشبینی مقدار عددی می باشد، به عنوان مثال قیمت یک ماشین با مجموعه ویژگی هایی مثل (مسافت طی شده، برند، سن ماشین و …). از این دست مثال ها با عنوان regression نامیده می شوند. (در پست های بعدی حتما یک مثال با regression توسط زبان پایتون حل می کنیم.)
برای آموزش سیستم، شما باید تعداد زیادی نمونه یا به عبارتی داده، در اختیار سیستم بگذارید که شامل label و predictor ها باشد.
نکته: دقت کنید بعضی از الگوریتم های regression را می توانند در classification استفاده شوند و برعکس.
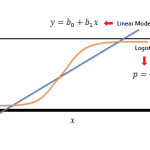
برای مثال، رگرسیون منطقی (Logistic Regression) معمولا برای طبقه بندی استفاده می شود، زیرا می تواند یک مقدار را که مربوط به احتمال متعلق به یک کلاس داده شده است، تولید کند.
منبع
یادگیری با نظارت چیست؟
در یادگیری با نظارت کار با ایمپورت کردن مجموعه دادههای شامل ویژگیهای آموزش (خصیصههای آموزش | training attributes) و ویژگیهای هدف (خصیصههای هدف | target attributes) آغاز میشود. الگوریتم یادگیری نظارت شده رابطه بین مثالهای آموزش و متغیرهای هدف مختص آنها را به دست میآورد و آن رابطه یاد گرفته شده را برای دستهبندی ورودیهای کاملا جدید مورد استفاده قرار میدهد (بدون هدفها). برای نمایش اینکه یادگیری نظارت شده چگونه کار میکند، یک مثال از پیشبینی نمرات دانشآموزان برپایه ساعات مطالعه آنها ارائه میشود. از منظر ریاضی:
که در آن:
- F رابطه بین نمرات و تعداد ساعاتی است که دانشآموزان به منظور آماده شدن برای امتحانات به مطالعه میپردازند.
- X ورودی است (تعداد ساعاتی که دانشآموز خود را آماده میکند).
- Y خروجی است (نمراتی که دانشآموزان در آزمون کسب کردهاند).
- C یک خطای تصادفی است.
هدف نهایی یادگیری نظارت شده پیشبینی Y با حداکثر دقت برای ورودی جدید داده شده X است. چندین راه برای پیادهسازی یادگیری نظارت شده وجود دارد. برخی از متداولترین رویکردها در ادامه مورد بررسی قرار میگیرند. برپایه مجموعه داده موجود، مساله یادگیری ماشین در دو نوع «دستهبندی» (Classification) و «رگرسیون» (Regression) قرار میگیرد. اگر دادههای موجود دارای مقادیر ورودی (آموزش) و خروجی (هدف) باشند، مساله از نوع دستهبندی است. اگر مجموعه داده دارای «مقادیر عددی پیوسته» (continuous numerical values) بدون هرگونه برچسب هدفی باشد، مساله از نوع رگرسیون محسوب میشود.
Classification: Has the output label. Is it a Cat or Dog?
Regression: How much will the house sell for?
منبع
یادگیری نظارت شده: زمانی رخ می دهد که شما با استفاده از داده هایی که به خوبی برچسب گذاری شده اند به یک ماشین آموزش می دهید؛ به بیان دیگر در این نوع یادگیری، داده ها از قبل با پاسخ های درست (نتیجه) برچسب گذاری شده اند. برای نمونه به ماشین عکسی از حرف A را نشان می دهید. سپس پرچم ایران که سه رنگ دارد را به آن نشان می دهید. یاد می دهید که یکی از رنگ ها قرمز است و یکی سبز و دیگری سفید. هرچه این مجموعه اطلاعاتی بزرگ تر باشد ماشین هم بیشتر می تواند در مورد موضوع یاد بگیرد.
پس از آنکه آموزش دادن به ماشین به اتمام رسید، داده هایی در اختیارش قرار داده می شوند که کاملا تازگی دارند و قبلا آنها را دریافت نکرده است. سپس الگوریتم یادگیری با استفاده از تجربیات قبلی خود آن اطلاعات را تحلیل می کند. مثلا حرف A را تشخیص می دهد و یا رنگ قرمز را مشخص می کند.
منبع
یادگیری نظارتی (Supervised ML)
در روش یادگیری با نظارت، از دادههای با برچسبگذاری برای آموزش الگوریتم استفاده میکنیم. دادههای دارای برچسب به این معنی است که داده به همراه نتیجه و پاسخ موردنظر آن دردسترس است. برای نمونه اگر ما بخواهیم به رایانه آموزش دهیم که تصویر سگ را از گربه تشخیص دهد، دادهها را به صورت برچسبگذاری شده برای آموزش استفاده میکنیم. به الگوریتم آموزش داده میشود که چگونه تصویر سگ و گربه را طبقهبندی کند. پس از آموزش، الگوریتم میتواند دادههای جدید بدون برچسب را طبقهبندی کند تا مشخص کند تصویر جدید مربوط به سگ است یا گربه. یادگیری ماشین با نظارت برای مسائل پیچیده عملکرد بهتری خواهد داشت.
یکی از کاربردهای یادگیری با نظارت، تشخیص تصاویر و حروف است. نوشتن حرف A یا عدد ۱ برای هر فرد با دیگری متفاوت است. الگوریتم با آموزش یافتن توسط مجموعه دادههای دارای برچسب از انواع دستخط حرف A و یا عدد ۱، الگوهای حروف و اعداد را یاد میگیرد. امروزه رایانهها در تشخیص الگوهای دست خط از انسان دقیقتر و قدتمندتر هستند.
در ادامه تعدادی از الگوریتمها که در یادگیری نظارتی مورد استفاده قرار میگیرد شرح داده میشود.
درخت تصمیم (ِDecision Tree)
ساختار درخت تصمیم در یادگیری ماشین، یک مدل پیش بینی کننده میباشد که حقایق مشاهده شده در مورد یک پدیده را به استنتاج هایی در مورد هدف آن پدیده پیوند میدهد. درخت تصمیم گیری به عنوان یک روش به شما اجازه خواهد داد مسائل را بصورت سیستماتیک در نظر گرفته و بتوانید نتیجه گیری منطقی از آن بگیرید.

دستهبندی کننده بیز (Naive Bayes classifier)
دستهبندیکننده بیز در یادگیری ماشین به گروهی از دستهبندیکنندههای ساده بر پایه احتمالات گفته میشود که با متغیرهای تصادفی مستقل مفروض میان حالتهای مختلف و براساس قضیه بیز کاربردی است. بهطور ساده روش بیز روشی برای دستهبندی پدیدهها، بر پایه احتمال وقوع یا عدم وقوع یک پدیدهاست.

کمینه مربعات
در علم آمار، حداقل مربعات معمولی یا کمینه مربعات معمولی روشی است برای برآورد پارامترهای مجهول در مدل رگرسیون خطی از طریق کمینه کردن اختلاف بین متغیرهای جواب مشاهده شده در مجموعه داده است. این روش در اقتصاد، علوم سیاسی و مهندسی برق و هوش مصنوعی کاربرد فراوان دارد.

رگرسیون لجستیک (logistic regression)
زمانی که متغیر وابسته ی ما دو وجهی (دو سطحی مانند جنسیت، بیماری یا عدم بیماری) است و میخواهیم از طریق ترکیبی از توابع منطقی دست به پیش بینی بزنیم باید از رگرسیون لجستیک استفاده کنیم. اندازه گیری میزان موفقیت یک کمپین انتخاباتی، پیش بینی فروش یک محصول یا پیش بینی وقوع زلزله در یک شهر، چند مثال از کاربردهای رگرسیون لجستیک است.

ماشین بردار پشتیبانی (Support vector machines )
یکی از روشهای یادگیری نظارتی است که از آن برای طبقهبندی و رگرسیون استفاده میکنند. مبنای کاری دستهبندی کننده SVM دستهبندی خطی دادهها است و در تقسیم خطی دادهها سعی میکنیم خطی را انتخاب کنیم که حاشیه اطمینان بیشتری داشته باشد. از طریق SVM میتوان مسائل بزرگ و پیچیدهای از قبیل شناسایی تمایز انسان و باتها در سایتها، نمایش تبلیغات مورد علاقه کاربر، شناسایی جنسیت افراد در عکسها و… را حل کرد.

منبع
و در پایان یک شمای کلی از انواع یادگیری ماشین وتقسیم بندی های آنها جهت تفهیم بیشتر یادآور می شویم:


دیدگاه خود را ثبت کنید
تمایل دارید در گفتگوها شرکت کنید؟در گفتگو ها شرکت کنید.