شبکه های عصبی مصنوعی چیست؟ قسمت 1

شبکههای عصبی مصنوعی
شبکه های عصبی مصنوعی یا شبکه های عصبی صناعی (Artificial Neural Network – ANN) یا به زبان سادهتر شبکه های عصبی سیستمها و روشهای محاسباتی نوین برای یادگیری ماشینی، نمایش دانش و در انتها اعمال دانش به دست آمده در جهت بیشبینی پاسخهای خروجی از سامانههای پیچیده هستند. ایدهٔ اصلی این گونه شبکهها تا حدودی الهامگرفته از شیوهٔ کارکردسیستم عصبی زیستی برای پردازش دادهها و اطلاعات به منظور یادگیری و ایجاد دانش قرار دارد. عنصر کلیدی این ایده، ایجاد ساختارهایی جدید برای سامانهٔ پردازش اطلاعات است.
این سیستم از شمار زیادی عناصر پردازشی فوقالعاده بهم پیوسته با نام نورون تشکیل شده که برای حل یک مسئله با هم هماهنگ عمل میکنند و توسط سیناپسها (ارتباطات الکترومغناطیسی) اطلاعات را منتقل میکنند. در این شبکهها اگر یک سلول آسیب ببیند بقیه سلولها میتوانند نبود آنرا جبران کرده، و نیز در بازسازی آن سهیم باشند. این شبکهها قادر به یادگیریاند. مثلاً با اعمال سوزش به سلولهای عصبی لامسه، سلولها یادمیگیرند که به طرف جسم داغ نروند و با این الگوریتم سیستم میآموزد که خطای خود را اصلاح کند. یادگیری در این سیستمها به صورت تطبیقی صورت میگیرد، یعنی با استفاده ازمثالها وزن سیناپسها به گونهای تغییر میکند که در صورت دادن ورودیهای جدید، سیستم پاسخ درستی تولید کند.
تعریفها
توافق دقیقی بر تعریف شبکه عصبی در میان محققان وجود ندارد؛ اما اغلب آنها موافقند که شبکه عصبی شامل شبکهای از عناصر پردازش ساده (نورونها) است، که میتواند رفتار پیچیده کلی تعیین شدهای از ارتباط بین عناصر پردازش و پارامترهای عنصر را نمایش دهد. منبع اصلی و الهام بخش برای این تکنیک، از آزمایش سیستم مرکزی عصبی و نورونها (آکسونها، شاخههای متعدد سلولهای عصبی و محلهای تماس دو عصب) نشأت گرفتهاست، که یکی از قابل توجهترین عناصر پردازش اطلاعات سیستم عصبی را تشکیل میدهد. در یک مدل شبکه عصبی، گرههای ساده (بطور گسترده «نورون»، «نئورونها»، «PE «ها (» عناصر پردازش «) یا» واحدها «) برای تشکیل شبکهای از گرهها، به هم متصل شدهاند—به همین دلیل به آن، اصطلاح» شبکه های عصبی» اطلاق میشود. در حالی که یک شبکه عصبی نباید به خودی خود سازگارپذیر باشد، استفاده عملی از آن بواسطه الگوریتمهایی امکانپذیر است، که جهت تغییر وزن ارتباطات در شبکه (به منظور تولید سیگنال موردنظر) طراحی شده باشد.
کارکرد
با استفاده از دانش برنامهنویسی رایانه میتوان ساختار دادهای طراحی کرد که همانند یک نرون عمل نماید. سپس با ایجاد شبکهای از این نورونهای مصنوعی به هم پیوسته، ایجاد یک الگوریتم آموزشی برای شبکه و اعمال این الگوریتم به شبکه آن را آموزش داد.
این شبکهها برای تخمین و تقریب، کارایی بسیار بالایی از خود نشان دادهاند. گستره کاربرد این مدلهای ریاضی بر گرفته از عملکرد مغز انسان، بسیار وسیع میباشد که به عنوان چند نمونه کوچک میتوان استفاده از این ابزار ریاضی در پردازش سیگنالهای بیولوییکی، مخابراتی و الکترونیکی تا کمک در نجوم و فضا نوردی را نام برد.
اگر یک شبکه را همارز با یک گراف بدانیم، فرایند آموزش شبکه تعیین نمودن وزن هر یال و base اولیهٔ خواهد بود.
تاریخچه شبکه های عصبی مصنوعی
از قرن نوزدهم به طور همزمان اما جداگانه سویی نروفیزیولوزیستها سعی کردند سیستم یادگیری و تجزیه و تحلیل مغز را کشف کنند، و از سوی دیگر ریاضیدانان تلاش کردند تا مدل ریاضی بسازند، که قابلیت فراگیری و تجزیه و تحلیل عمومی مسائل را دارا باشد. اولین کوششها در شبیهسازی با استفاده از یک مدل منطقی توسط مک کلوک و والتر پیتز انجام شد که امروزه بلوک اصلی سازنده اکثر شبکه های عصبی مصنوعی است. این مدل فرضیههایی در مورد عملکرد نورونها ارائه میکند. عملکرد این مدل مبتنی بر جمع ورودیها و ایجاد خروجی است. چنانچه حاصل جمع ورودیها از مقدار آستانه بیشتر باشد اصطلاحاً نورون برانگیخته میشود. نتیجه این مدل اجرای توابع ساده مثل AND و OR بود.
نه تنها نروفیزیولوژیستها بلکه روانشناسان و مهندسان نیز در پیشرفت شبیهسازی شبکه های عصبی تأثیر داشتند. در سال ۱۹۵۸ شبکه پرسپترون توسط روزنبلات معرفی گردید. این شبکه نظیر واحدهای مدل شده قبلی بود. پرسپترون دارای سه لایه میباشد، به همراه یک لایه وسط که به عنوان لایه پیوند شناخته شدهاست. این سیستم میتواند یاد بگیرد که به ورودی داده شده خروجی تصادفی متناظر را اعمال کند. سیستم دیگر مدل خطی تطبیقی نورون میباشد که در سال ۱۹۶۰ توسط ویدرو و هاف (دانشگاه استنفورد) به وجود آمد که اولین شبکه های عصبی به کار گرفته شده در مسائل واقعی بودند. Adalaline یک دستگاه الکترونیکی بود که از اجزای سادهای تشکیل شده بود، روشی که برای آموزش استفاده میشد با پرسپترون فرق داشت.
در سال ۱۹۶۹ میسکی و پاپرت کتابی نوشتند که محدودیتهای سیستمهای تک لایه و چند لایه پرسپترون را تشریح کردند. نتیجه این کتاب پیش داوری و قطع سرمایهگذاری برای تحقیقات در زمینه شبیهسازی شبکه های عصبی بود. آنها با طرح اینکه طرح پرسپترون قادر به حل هیچ مسئله جالبی نمیباشد، تحقیقات در این زمینه را برای مدت چندین سال متوقف کردند.
با وجود اینکه اشتیاق عمومی و سرمایهگذاریهای موجود به حداقل خود رسیده بود، برخی محققان تحقیقات خود را برای ساخت ماشینهایی که توانایی حل مسائلی از قبیل تشخیص الگو را داشته باشند، ادامه دادند. از جمله گراسبگ که شبکهای تحت عنوان Avalanch را برای تشخیص صحبت پیوسته و کنترل دست ربات مطرح کرد. همچنین او با همکاری کارپنتر شبکههای ART را بنانهادند که با مدلهای طبیعی تفاوت داشت. اندرسون و کوهونن نیز از اشخاصی بودند که تکنیکهایی برای یادگیری ایجاد کردند. ورباس در سال ۱۹۷۴ شیوه آموزش پس انتشار خطا را ایجاد کرد که یک شبکه پرسپترون چندلایه البته با قوانین نیرومندتر آموزشی بود.
پیشرفتهایی که در سال ۱۹۷۰ تا ۱۹۸۰ بدست آمد برای جلب توجه به شبکه های عصبی بسیار مهم بود. برخی فاکتورها نیز در تشدید این مسئله دخالت داشتند، از جمله کتابها و کنفرانسهای وسیعی که برای مردم در رشتههای متنوع ارائه شد. امروز نیز تحولات زیادی در تکنولوژی ANN ایجاد شدهاست.
در ایران
از جمله کارهای انجام شده در ایران که بعد از سال ۲۰۰۰ به طور جدی انجام گرفته میتوان به تحلیلهای دقیق انجام شده روی مواد پلیمری، سیکلهای ترمودینامیکی، مجراهای عبور سیال و… اشاره کرد.
دیگر نقاط دنیا
فیسبوک از یک شبکه عصبی مصنوعی ۹ لایه با بیش از ۱۲۰میلیون ارتباط وزنی، برای شناسایی و تشخیص چهره در طرح عمقصورت (به انگلیسی:DeepFace) استفاده میکند. ادعا میشود دقت شناسایی چهره در این سامانه ۹۷٪ است که در مقایسه با سامانه نسلبعدیشناسایی (به انگلیسی: Next Generation Identification) مورد استفاده اداره تحقیقات فدرال آمریکا که مدعی است تا ۸۵٪ دقت دارد جهش بلندی در جمعاوری و تحلیل اطلاعات شخصی محسوب میشود. قابل ذکر است فیسبوک بدلیل قوانین محافظت از اطلاعات شخصی در اتحادیه اروپا از این سامانه در این کشورها استفاده نمیکند.
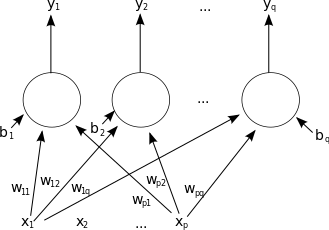



معرفی شبکه عصبی مصنوعی
شبکه عصبی مصنوعی یک سامانه پردازشی دادهها است که از مغز انسان ایده گرفته و پردازش دادهها را به عهدهٔ پردازندههای کوچک و بسیار زیادی سپرده که به صورت شبکهای به هم پیوسته و موازی با یکدیگر رفتار میکنند تا یک مسئله را حل نمایند. در این شبکهها به کمک دانش برنامهنویسی، ساختار دادهای طراحی میشود که میتواند همانند نورون عمل کند؛ که به این ساختارداده نورون گفته میشود. بعد باایجاد شبکهای بین این نورونها و اعمال یک الگوریتم آموزشی به آن، شبکه را آموزش میدهند.

در این حافظه یا شبکهٔ عصبی نورونها دارای دو حالت فعال (روشن یا ۱) و غیرفعال (خاموش یا ۰) اند و هر یال (سیناپس یا ارتباط بین گرهها) دارای یک وزن میباشد. یالهای با وزن مثبت، موجب تحریک یا فعال کردن گره غیرفعال بعدی میشوند و یالهای با وزن منفی، گره متصل بعدی را غیرفعال یا مهار (در صورتی که فعال بوده باشد) میکنند.
تحقیقات اخیر
در تاریخ Dec 17, 2009 ابرکامپیوتر شرکت IBM در آمریکا توانست در حدود billion 1 (میلیارد) نورون را با حدود 10 trillion سیناپس مصنوعی شبیهسازی کند که نشان دهنده این واقعیت هست که نورونهای مصنوعی به سیستمهای قدرتمندی برای اجرا نیاز دارند و برای شبیهسازی مغز انسان احتمالاً به کامپیوتر کوانتومی نیاز خواهد بود. همچنین با دانستن این موضوع که مورچه ۲۵۰٬۰۰۰ نورون و زنبور در حدود ۹۶۰٬۰۰۰ و گربه ۷۶۰٬۰۰۰٬۰۰۰ نورون و در حدود 1013 سیناپس دارد میشود نتیجه گرفت که با ابرکاپیوترهای کنونی تا حدودی بتوان این موجودات را شبیهسازی کرد. (لیست موجودات مختلف بر اساس تعداد نورونها و سیناپسها)
در تاریخ Dec 9, 2014 شرکت IBM از تراشه SyNAPSE خود رونمایی کرد. این چیپ که با سرمایهگذاری DARPA (سازمان پروژههای تحقیقاتی پیشرفتهٔ دفاعی ایالت متحده) به بهرهبرداری رسیده، به گونهای طراحی شده که فعالیتهای مغز انسان را شبیهسازی کند و به طور کلی از چارچوب منطق بولین و باینری خارج شود. این تراشه متشکل از ۱ میلیون نورون مجازی است که با استفاده از ۲۵۶ میلیون سیناپس مجازی به یکدیگر متصل شدهاند. سیناپس بزرگترین تراشهای است که شرکت IBM تاکنون تولید کرده است، چراکه در آن ۵٫۴ میلیارد ترانزیستور استفاده شده است.
همچنین مجموعهٔ ترانزیستورهای مورد استفاده متشکل از ۴٫۰۹۶ هستهٔ neuroSynaptic است که روی تراشه قرار گرفتهاند. مصرف این تراشه تنها ۷۰ میلیوات mW است که در مقایسه با تراشههای کنونی بسیار کمتر است. List of CPU power dissipation figures از نظر مقیاس، تراشهٔ سیناپس برابر با مغز یک زنبور عسل است و تعداد نئورونها و سیناپسهای مورد استفاده با آن برابری میکند، با این وجود این تراشه بسیار ضعیفتر از مغز انسانها است. مغز هر انسان از حدود ۸۶ میلیارد نورون و ۱۰۰ تریلیوین سیناپس تشکیل شده است. البته تیم توسعهٔ SyNAPSE نشان داده که میتوان با اتصال تراشههای سیناپس به یکدیگر، تراشهٔ بزرگتر و قویتری ساخت.
در حال حاضر IBM موفق شده یک بورد قابل برنامهریزی و کارآمد با استفاده از ۱۶ عدد چیپ SyNAPSE ایجاد نماید که همگی در هماهنگی کامل با یکدیگر فعالیت میکنند. این بورد نمایانگر قدرت ۱۶ میلیون نورون است که بنا بر گفتهٔ محققان این پروژه، در پردازش سنتی با استفاده از تعداد زیادی رک (مکان قرارگیری چندین کامپیوتر پر قدرت بزرگ) و مجموعههای عظیم کامپیوتری قابل دستیابی بود؛ و با وجود مجتمع نمودن ۱۶ چیپ در یک سیستم، باز هم با مصرف نیروی به شدت پایینی روبرو هستیم که در نتیجهٔ آن حرارت بسیار پایینتری نیز تولید میشود. در حقیقت چیپ SyNAPSE جدید آنچنان انقلابی بوده و دنیای پردازش را از نگرش دیگری نمایان میسازد که IBM مجبور شده برای همراهی با توسعهٔ آن به ایجاد یک زبان برنامهنویسی جدید بپردازد و یک برنامهٔ آموزشی گستردهٔ اطلاعرسانی تحت نام دانشگاه SyNAPSE راهاندازی کند.
در تاریخ March 16, 2016 شرکت Google بخش DeepMind توانست توسط هوش مصنوعی خود قهرمان جهان را در بازی GO (شطرنج چینی با قدمتی بیش از ۲۵۰۰ سال) با نتیجه ۴ به ۱ شکست دهند که این دستاورد بزرگی برای هوش مصنوعی بود. گوگل در این هوش مصنوعی از تکنولوژی Deep Learning و short-term memory بهره برده است و این سیستم به نوعی مشابهTuring Machine هست اما به صورت end-to-end دارای تفاوتهای قابل تشخیص میباشد و این تکنولوژیها به اون اجازه داده است که با gradient descent به صورت مؤثری قابل تعلیم باشد.
در DeepMind محققان گوگل مجموعهای از حرکتهای بهترین بازکنان گو را که شامل بیش از ۳۰ میلیون حرکت است، جمعآوری کرده و سیستم هوش مصنوعی مبتنی بر یادگیری عمیق خود را با استفاده از این حرکات آموزش دادهاند تا از این طریق آلفاگو قادر باشد به تنهایی و براساس تصمیمات خود به بازی بپردازد. همچنین دانشمندان برای بهبود هر چه بیشتر این سیستم راهحل تقابل هوش مصنوعی توسعه یافته با خودش را در پیش گرفتند؛ با استفاده از این روش، دانشمندان موفق شدند تا حرکات جدیدی را نیز ثبت کنند و با استفاده از این حرکات آموزش هوش مصنوعی را وارد مرحلهٔ جدیدتری نمایند. چنین سیستمی قادر شده تا بهترین بازیکن اروپا و جهان را شکست دهد.
بزرگترین نتیجهٔ توسعهٔ آلفاگو، عدم توسعهٔ این سیستم با قوانین از پیش تعیین شده است. در عوض این سیستم از روشهای مبتنی بر یادگیری ماشین و شبکه عصبی توسعه یافته و تکنیکهای برد در بازی گو را به خوبی یادگرفته و حتی میتواند تکنیکهای جدیدی را ایجاد و در بازی اعمال کند. کریس نیکولسون، مؤسس استارت آپ Skymind که در زمینهٔ تکنولوژیهای یادگیری عمیق فعالیت میکند، در این خصوص این چنین اظهار نظر کرده است: ” از سیستمهای مبتنی بر شبکهٔ عصبی نظیر آلفاگو میتوان در هر مشکل و مسئلهای که تعیین استراتژی برای رسیدن به موفقیت اهمیت دارد، استفاده کرد. کاربردهای این فناوری میتواند از اقتصاد، علم یا جنگ گسترده باشد. “
اهمیت برد آلفاگو :در ابتدای سال ۲۰۱۴ میلادی، برنامهٔ هوش مصنوعی Coulom که Crazystone نام داشت موفق شد در برابر نوریموتو یودا، بازیکن قهار این رشتهٔ ورزشی پیروز شود؛ اما موضوعی که باید در این پیروزی اشاره کرد، انجام ۴ حرکت پی در پی ابتدایی در این رقابت توسط برنامهٔ هوش مصنوعی توسعه یافته بود که برتری بزرگی در بازی گو به شمار میرود. در آن زمان Coulom پیشبینی کرده بود که برای غلبه بر انسان، نیاز به یک بازهٔ زمانی یک دههای است تا ماشینها بتوانند پیروز رقابت با انسانها در بازی GO باشند.
چالش اصلی در رقابت با بهترین بازیکنهای گو، در طبیعت این بازی نهفته است. حتی بهترین ابررایانههای توسعه یافته نیز برای آنالیز و پیشبینی نتیجهٔ حرکتهای قابل انجام از نظر قدرت پردازشی دچار تزلرل شده و نمیتوانند قدرت پردازشی مورد نیاز را تأمین کنند. در واقع نیروی پردازشی این رایانهها مناسب نبوده و در نتیجه زمان درازی را برای ارائهٔ نتیجهٔ قابل قبول مورد نیاز است. زمانی که ابررایانهٔ موسوم به Deep Blue که توسط IBM توسعه یافته بود، موفق شد تا در سال ۱۹۹۷، گری کاسپاروف، قهرمان شطرنج جهان را شکست دهد، بسیاری به قدرت این ابررایانه پی بردند؛ چراکه این ابررایانه با قدرت زیادی کاسپاروف را شکست داد. علت پیروزی قاطع این Deep Blue، قدرت بالای این ابررایانه در کنار قدرت تحلیل و نتیجهگیری از هر حرکت احتمالی ممکن در بازی بود که تقریباً هیچ انسانی توانایی انجام آن را ندارد.
اما چنین پیشبینیهایی در بازی GO ممکن نیست. براساس اطلاعات ارائه شده در بازی شطرنج که در صفحهای ۸ در ۸ انجام میشود، در هر دور، بصورت میانگین میتوان ۳۵ حرکت را انجام داد، اما در بازی گو که بین دو نفر در تختهای به بزرگی ۱۹ در ۱۹ خانه انجام میشود، در هر دور بصورت میانگین میتوان بیش از ۲۵۰ حرکت انجام داد. هر یک از این ۲۵۰ حرکت احتمالی نیز در ادامه ۲۵۰ احتمال دیگر را در پی دارند؛ که می شه نتیجه گرفت که در بازی گو، به اندازهای احتمال حرکات گسترده است که تعداد آن از اتمهای موجود در جهان هستی نیز بیشتر است.
تلاشهای پیشین: در سال ۲۰۱۴ محققان در DeepMind، دانشگاه ادینبورگ و facebook امیدوار بودند تا با استفاده از شبکه های عصبی، سیستمهایی مبتنی بر شبکه های عصبی توسعه دهند که قادر باشد تا با نگاه کردن به تختهٔ بازی، همچون انسانها به بازی بپردازند. محققان در فیسبوک موفق شدهاند تا با کنار هم قراردادن تکنیک درخت مونت کارلو و یادگیری عمیق، شماری از بازیکنان را در بازی گو شکست دهد. البته سیستم فیسبوک قادر به برد در برابر CrazyStone و سایر بازیکنان شناخته شدهٔ این رشتهٔ ورزشی نشد.
سختافزار مورد نیاز سیستم یادگیری عمیق دیپ مایند: براساس اطلاعات ارائه شده، سیستم DeepMind قادر است روی رایانهای با چند پردازندهٔ گرافیکی نیز به خوبی کار کند؛ اما در مسابقهای که آلفاگو در برابر فان هوی برگزار کرد، این سیستم مبتنی بر شبکهٔ عصبی از وجود شبکههای از رایانهها بهره میبرد که شامل بیش از ۱۷۰ پردازندهٔ گرافیکی Nvidia و ۱٬۲۰۰ پردازنده بود.
در تاریخ October 4, 2016 شرکت Google از نوعی رباتیک ابری رونمایی کرد که در ان شبکه های عصبی روباتها قادر به به اشتراک گذاشتن یادگیری هایشان با یکدیگر بودند؛ که این عمل باعث کاهش زمان مورد نیاز برای یادگیری مهارتها توسط رباتها میشود و به جای اینکه هر ربات به شکل جداگانه عمل کند، رباتها تجربههای خود را به صورت جمعی در اختیار یکدیگر قرار میدهند. برای مثال یک ربات به ربات دیگر آموزش میدهد که چطور کار سادهای مانند در باز کردن را انجام دهد یا جسمی را جابهجا کند و در فواصل زمانی معین، رباتها آنچه را که یادگرفتهاند به سرور آپلود میکنند. ضمن این که آخرین نسخه از یادگیری آن موضوع را هم دانلود میکنند تا به این وسیله هر ربات به تصویر جامعتری از تجربههای فردی خود دست پیدا کند.
در شروع یادگیری رفتار هر ربات از منظر ناظر خارجی کاملاً تصادفی است. اما پس امتحان کردن راه حلهای مختلف توسط ربات، هر ربات یاد خواهند گرفت که چطور راه حل نزدیکتر به هدف را انتخاب کند و به این ترتیب، تواناییهای ربات به طور مستمر بهبود پیدا خواهد کرد. حال آنکه در روش رباتیک ابری، رباتها بهتر میتوانند به شکل همزمان یاد بگیرند و یادگیری خود را با یکدیگر به اشتراک بگذارند. از این رو رباتهای جمعی میتوانند عملکرد سریع تر و بهتری نسبت به یک ربات تنها نشان دهند و افزایش سرعت این روند، میتواند عملکرد رباتها را در انجام کارهای پیچیده بهود بخشد.
شبکه های عصبی مصنوعی چیست؟ قسمت 1
شبکه های عصبی مصنوعی چیست؟ قسمت 2
شبکه های عصبی مصنوعی چیست؟ قسمت 3
شبکه های عصبی مصنوعی چیست؟ قسمت 4

دیدگاه خود را ثبت کنید
تمایل دارید در گفتگوها شرکت کنید؟در گفتگو ها شرکت کنید.