شبکه عصبی مصنوعی به زبان ساده
یک شبکه عصبی مصنوعی (Artificial Neural Network – ANN) ایده ای برای پردازش اطلاعات است که از سیستم عصبی زیستی الهام گرفته و مانند مغز به پردازش اطلاعات میپردازد. عنصر کلیدی این ایده، ساختار جدید سیستم پردازش اطلاعات است. این سیستم از شمار زیادی عناصر پردازشی فوق العاده بهم پیوسته به نام نورونها (neurons) تشکیل شده که برای حل یک مسئله با هم هماهنگ عمل میکنند.
شبکه های عصبی مصنوعی نیز مانند انسانها با مثال یاد می گیرند و یک شبکه عصبی برای انجام وظیفههای مشخص مانند شناسایی الگوها و دسته بندی اطلاعات، در طول یک پروسه یاد گیری تنظیم میشود. در سیستمهای زیستی، یاد گیری با تنظیماتی در اتصالات سیناپسی که بین اعصاب قرار دارد همراه است. از این روش در شبکه های عصبی نیز استفاده میشود.
شبکه های عصبی مصنوعی (ANN) که به اختصار به آن شبکه عصبی نیز گفته میشود، نوع خاصی از مدل یادگیری است که روش کارکرد سیناپسها در مغز انسان را تقلید میکند.
شبکه های عصبی مصنوعی با پردازش دادههای تجربی، دانش یا قانون نهفته در ورای دادهها را به ساختار شبکه منتقل میکند که به این عمل یادگیری میگویند. اصولاً توانایی یادگیری مهمترین ویژگی یک سیستم هوشمند است. سیستمی کهقابلیت یادگیری داشته باشد، منعطف تر است وساده تر برنامهریزی میشود، بنابراین بهتر میتواند در مورد مسایل و معادلات جدید پاسخگو باشد.
ساختار شبکه عصبی
انسانها از زمانهای بسیار دور سعی بر آن داشتند که بیوفیزیولوژی مغز را دریابند زیرا که همواره مسئله هوشمندی انسان و قابلیت یادگیری، تعمیم، خلاقیت، انعطاف پذیری و پردازش موازی در مغز برای بشر جالب بوده و بکارگیری این قابلیتها در ماشینها بسیار مطلوب مینمود. روشهای الگوریتمیک برای پیاده سازی این خصایص در ماشینها مناسب نمیباشند، در نتیجه میبایست روشهایی مبتنی بر همان مدلهای بیولوژیکی ابداع شوند.

به عبارت دیگر شبکهی عصبی یک سامانه پردازش دادهها است که از مغز انسان ایده گرفته و پردازش دادهها را به عهدهپردازندههای کوچک و بسیار زیادی میسپارد که به صورت شبکهای به هم پیوسته و موازی با یکدیگر برای حل یک مسئله رفتار میکنند. در این شبکهها به کمک دانش برنامه نویسی، ساختار دادهای طراحی میشود که میتواند همانندنورون عمل کند. به این ساختار داده گره گفته میشود.
در این ساختار با ایجاد شبکهای بین این گرهها و اعمال یک الگوریتم آموزشی به آن، شبکه را آموزش میدهند. در این حافظه یا شبکه عصبی گرهها دارای دو حالت فعال (روشن یا ۱) و غیرفعال (خاموش یا ۰) اند و هر یال (سیناپس یا ارتباط بین گرهها) دارای یک وزن میباشد. یالهای با وزن مثبت، موجب تحریک یا فعال کردن گره غیر فعال بعدی میشوند و یالهای با وزن منفی، گره متصل بعدی را غیر فعال یا مهار (در صورتی که فعال بوده باشد) میکنند.
مثالی برای شبکه عصبی
در روشهای محاسباتی سنتی، از یک سری عبارات منطقی برای اجرای یک عمل استفاده میشود؛ اما در مقابل، شبکه های عصبی از مجموعه نودها (به عنوان نرون) و یالها (در نقش سیناپس) برای پردازش داده بهره میگیرند. در این سیستم، ورودیها در شبکه به جریان افتاده و یک سری خروجی تولید میگردد.
سپس خروجیها با دادههای معتبر مقایسه میگردند. مثلا فرض کنید میخواهید کامپیوتر خود را به گونهای آموزش دهید که تصویر گربه را تشخیص دهد. برای این کار میلیونها تصویر از گربههای مختلف را وارد شبکه کرده و آنهایی که از سوی سیستم به عنوان خروجی انتخاب میشوند را دریافت میکنید.
در این مرحله کاربر انسانی میتواند به سیستم بگوید که کدام یک از خروجیها دقیقا تصویر گربه هستند. بدین ترتیب مسیرهایی که به تشخیص موارد درست منجر شده، از طرف شبکه تقویت خواهند شد. با تکرار این فرایند در دفعات زیاد، شبکه نهایتا قادر است به دقت بسیار خوبی در اجرای وظیفه موردنظر دست یابد.
البته شبکه های عصبی را نمیتوان پاسخ تمام مسائل محاسباتی پیش روی انسان دانست، اما در مواجهه با دادههای پیچیده، بهترین گزینه به شمار میروند.
اخیرا گوگل و مایکروسافت هر دو اعلام کردند یادگیری مبتنی بر شبکه های عصبی را به نرمافزارهای مترجمشان افزودهاند.
گوگل و مایکروسافت از شبکه های عصبی برای تقویت اپلیکیشنهای ترجمه خود بهره گرفتهاند و به نتایج بسیار خوبی دست یافتهاند، زیرا عمل ترجمه از جمله فرایندهای بسیار پیچیده محسوب میگردد.

بدین ترتیب با استفاده از قابلیت یادگیری شبکه های عصبی، سیستم ترجمه میتواند ترجمههای صحیح را برای یادگیری به کار گرفته و به مرور زمان به دقت بیشتری دست یابد.
چنین وضعیتی در تشخیص گفتار نیز به وجود آمد. پس از افزودن یادگیری با شبکه های عصبی در Google Voice نرخ خطای این برنامه تا ۴۹% کاهش یافت. البته این قابلیت هیچوقت بدون نقص نخواهد بود، اما به مرور زمان شاهد پیشرفت آن هستیم.
شبکه های عصبی در مقابل کامپیوتر های معمولی
شبکه های عصبی نسبت به کامپیوترهای معمولی مسیر متفاوتی را برای حل مسئله طی میکنند. کامپیوترهای معمولی یکمسیر الگوریتمی را استفاده میکنند به این معنی که کامپیوتر یک مجموعه از دستورالعملها را به قصد حل مسئله پی میگیرد. اگر قدمهای خاصی که کامپیوتر باید بردارد، شناخته شده نباشند، کامپیوتر قادر به حل مسئله نخواهد بود. این حقیقت قابلیت حل مسئلهی کامپیوترهای معمولی را به مسائلی محدود میکند که ما قادر به درک آنها هستیم و می دانیم چگونه حل میشوند.
از طرف دیگر، کامپیوترهای معمولی از یک مسیر مشخص برای حل یک مسئله استفاده میکنند. راه حلی که مسئله از آن طریق حل میشود باید از قبل شناخته شده و به صورت دستورات کوتاه و غیر مبهمی شرح داده شده باشد. این دستورات به زبانهای برنامه نویسی سطح بالا برگردانده شده و سپس به کدهایی قابل درک و پردازش برای کامپیوترها تبدیل میشوند.
شبکه های عصبی اطلاعات را به روشی مشابه با کاری که مغز انسان انجام میدهد پردازش میکنند. آنها از تعداد زیادی ازعناصر پردازشی (سلول عصبی) که فوق العاده بهم پیوستهاند تشکیل شده است که این عناصر به صورت موازی باهم برای حل یک مسئله مشخص کار میکنند. شبکه های عصبی با مثال کار میکنند و نمیتوان آنها را برای انجام یک وظیفه خاص برنامه ریزی کرد. مثالها میبایست با دقت انتخاب شوند در غیر این صورت باعث اتلاف وقت و هزینه میشود و حتی بدتر از آن، ممکن است شبکه درست کار نکند.
امتیاز شبکه عصبی در آن است که چگونگی حل مسئله را خودش کشف میکند!
شبکه های عصبی و کامپیوترهای معمولی با هم در حال رقابت نیستند بلکه کامل کننده یکدیگرند. انجام بعضی وظایف مانند عملیاتهای محاسباتی بیشتر مناسب روشهای الگوریتمی است. همچنین انجام برخی دیگر از وظایف که به یادگیریو آزمون و خطا نیاز دارند را بهتر است به شبکه های عصبی بسپاریم. فراتر که میرویم، مسائلی وجود دارد که به سیستمیترکیبی از روش های الگوریتمی و شبکه های عصبی برای حل آنها مورد نیاز است (بطور معمول کامپیوتر های معمولی برای نظارت بر شبکه های عصبی به کار گرفته میشوند ) به این منظور که بیشترین کارایی بدست آید.

مزیتهای شبکه عصبی
شبکه عصبی با قابلیت قابل توجه آنها در جست و جو معانی از دادههای پیچیده یا مبهم، میتواند برای استخراج الگوها و شناسایی روشهایی که آگاهی از آنها برای انسان و دیگر تکنیکهای کامپیوتری بسیار پیچیده و دشوار است به کار گرفته شود. یک شبکه عصبی تربیت یافته میتواند به عنوان یک متخصص در مقوله اطلاعاتی که برای تجزیه تحلیل به آن داده شده به حساب آید.
شبکه های عصبی معجزه نمیکنند اما اگر خردمندانه به کار گرفته شوند نتایج شگفت آوری خلق میکنند.
مزیتهای دیگر شبکه های عصبی
-
یادگیری انطباق پذیر (Adaptive Learning)
یادگیری انطباق پذیر، قابلیت یادگیری و نحوه انجام وظایف بر پایه اطلاعات داده شده برای تمرین و تجربههای مقدماتی.
-
-
-
سازماندهی توسط خود (Self Organization)
-
-
سازماندهی توسط خود یعنی یک شبکه هوش مصنوعی سازماندهی یا ارائهاش را برای اطلاعاتی که در طول دوره یادگیری دریافت میکند، خودش ایجاد کند.
-
-
-
عملکرد بهنگام (Real Time Operation)
-
-
در عملکرد بهنگام محاسبات شبکه هوش مصنوعی میتواند بصورت موازی انجام شود و سخت افزارهای مخصوصی طراحی و ساخته شده که میتواند از این قابلیت استفاده کنند.
-
-
-
تحمل اشتباه بدون ایجاد وقفه در هنگام کد گذاری اطلاعات
-
-
خرابی جزئی یک شبکه منجر به تنزل کارایی متناظر با آن میشود، اگر چه تعدادی از قابلیتهای شبکه حتی با خسارت بزرگی هم به کار خود ادامه میدهند.
انواع شبکه عصبی مصنوعی
-
-
-
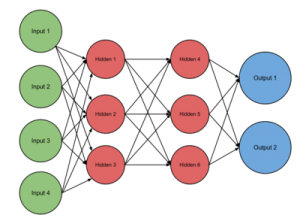
شبکههای پیش خور (FeedForward Neural Network)
-
-
شبکههای پیش خور، شبکههایی هستند که مسیر پاسخ در آنها همواره رو به جلو پردازش شده و به نرونهای لایههای قبل خود باز نمیگردد. در این نوع شبکه به سیگنالها تنها اجازه عبور از مسیر یکطرفه (از ورودی تا خروجی) داده میشود. بنابراین بازخورد یا فیدبک وجود ندارد به این معنی که خروجی هر لایه تنها بر لایه بعد اثر میگذارد و در لایهی خودش تغییری ایجاد نمیکند.
-
-
-
شبکههای پسخور (FeedBack Neural Network)
-
-
تفاوت شبکه هاِی پس خور با شبکههای پیش خور در آن است که در شبکههای برگشتی حداقل یک سیگنال برگشتی از یک نرون به همان نرون یا نرونهای همان لایه یا نرونهای لایههای قبل وجود دارد و اگر نرونی دارای فیدبک باشد بدین مفهوم است که خروجی نرون در لحظه حال نه تنها به ورودی در آن لحظه بلکه به مقدار خروجی خود نرون در لحظه ی گذشته نیز وابسته است.
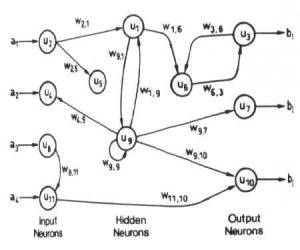
یادگیری در شبکه های عصبی
-
-
-
یادگیری با ناظر (Supervised learning)
-
-
در یادگیری با ناظر به الگوریتم یادگیری، مجموعه ای از زوج دادهها داده میشود. هر داده یادگیری شامل ورودی به شبکه و خروجی هدف است. پس از اعمال ورودی به شبکه، خروجی شبکه با خروجی هدف مقایسه میگردد و سپس خطای یادگیری محاسبه شده و از آن جهت تنظیم پارامترهای شبکه (وزن ها)، استفاده میگردد. به گونه ای که اگر دفعه بعد به شبکه همان ورودی را دادیم، خروجی شبکه به خروجی هدف نزدیک گردد.
-
-
-
یادگیری تشدیدی
-
-
یادگیری تشدیدی حالت خاصی از یادگیری با ناظر و یک یادگیری برخط (On-Line) از یک نگاشت ورودی-خروجی است. این کار از طریق یک پروسه سعی و خطا به صورتی انجام میپذیرد که شاخصی موسوم به سیگنال تشدید، ماکزیمم شود که در آن بجای فراهم نمودن خروجی هدف، به شبکه عددی که نشاندهنده میزان عملکرد شبکه است ارائه میگردد.
-
-
-
یادگیری بدون ناظر (UnSupervised learning)
-
-
در یادگیری بدون ناظر یا یادگیری خود سامانده، پارامترهای شبکه عصبی تنها توسط پاسخ سیستم اصلاح و تنظیم میشوند. به عبارتی تنها اطلاعات دریافتی از محیط به شبکه را بردارهای ورودی تشکیل میدهند.
ساختار شبکه های عصبی مصنوعی به زبان ساده (Artificial Neural Network)
شبکه عصبی مصنوعی روشی عملی برای یادگیری توابع گوناگون نظیر توابع با مقادیر حقیقی، توابع با مقادیر گسسته و توابع با مقادیر برداری میباشد.
مطالعه شبکه های عصبی مصنوعی تا حد زیادی ملهم از سیستم های یادگیر طبیعی است که در آنها یک مجموعه پیچیده از نرونهای به هم متصل درکار یادگیری دخیل هستند.
گمان میرود که مغز انسان از تعداد 1011 نرون تشکیل شده باشد که هر نرون با تقریبا 104 نرون دیگر در ارتباط است. سرعت سوئیچنگ نرونها در حدود 3–10 ثانیه است که در مقایسه با کامپیوترها 10–10 ثانیه بسیار ناچیز مینماید. با این وجود آدمی قادر است در 0.1 ثانیه تصویر یک انسان را بازشناسائی نماید. ولی برای کامپیتر دقایقی طول می کشد که این بازشناسی انجام شود.
شاید بد نباشد ابتدا به این سوال فکر کنید، چرا با اینکه سرعت سوئیچنگ نرونهای کامپیوتر از مغز انسان بیشتر است ولی انسانها سریعتر چهره یک شخص را به یاد میآورند؟
ساختار شبکه عصبی
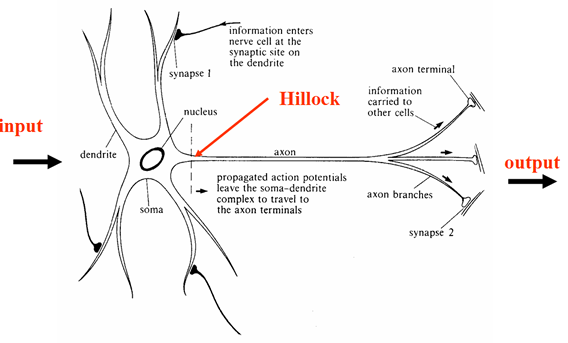
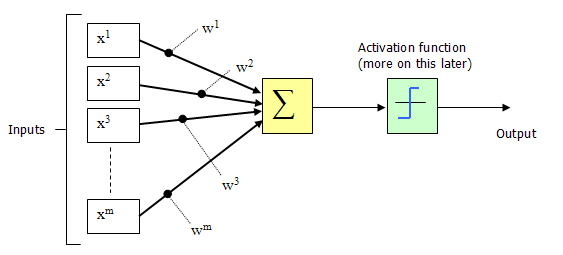
هر دو تصویر بالا را مشاهده کنید. چه شباهتهایی میبینید؟
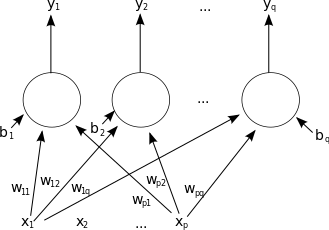
همانطور که ملاحظه می کنید، تصویر اول یک نرون طبیعی بیولوژیکی است. اطلاعات از طریق ورودی یا همان دندریت وارد نرون می شوند، همان ورودیها در تصویر دوم با مقادیر (x1,…….,xm) قابل مشاهده هستند. در مدل شبکه عصبی مصنوعی به هر ورودی یک وزن (w1,…….,wm) اختصاص می دهیم. این وزنها در واقع اهمیت ورودیها برای ما هستند، یعنی هر چه وزن بیشتر باشد، ورودی برای آموزش شبکه مهمتر است. سپس تمامی ورودیها با هم جمع (Σ) شده و به صورت یکلایه به آکسون وارد می شوند. در مرحله بعد Activation Function را بر روی دادهها اعمال میکنیم.
Activation Function در واقع نسبت به نیاز مسئله و نوع شبکه عصبی ما (در آموزش های بعدی به آن می پردازیم) تعریف می شود. این function شامل یک فرمول ریاضی برای بروزرسانی وزنها در شبکه است.
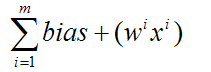
پس از انجام محاسبات در این مرحله اطلاعات ما از طریق سیناپس های خروجی وارد نرون دیگر میشوند، و این مرحله تا جایی ادامه پیدا میکند که شبکه اصطلاحا train شده باشد.
شبکه های عصبی مصنوعی چیست؟ قسمت 1
شبکه های عصبی مصنوعی چیست؟ قسمت 2
شبکه های عصبی مصنوعی چیست؟ قسمت 3
شبکه های عصبی مصنوعی چیست؟ قسمت 4