رگرسیون لجستیک (LR)
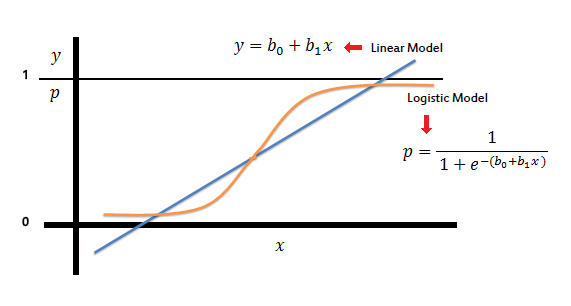
رگرسیون لجستیک (Logistic regression) یک مدل آماری رگرسیون برای متغیرهای وابسته دوسویی مانند بیماری یا سلامت، مرگ یا زندگی است. این مدل را میتوان به عنوان مدل خطی تعمیمیافتهای که از تابع لوجیت به عنوان تابع پیوند استفاده میکند و خطایش از توزیع چندجملهای پیروی میکند، بهحسابآورد. منظور از دو سویی بودن، رخ داد یک واقعه تصادفی در دو موقعیت ممکنه است. به عنوان مثال خرید یا عدم خرید، ثبت نام یا عدم ثبت نام، ورشکسته شدن یا ورشکسته نشدن و … متغیرهایی هستند که فقط دارای دو موقعیت هستند و مجموع احتمال هر یک آنها در نهایت یک خواهد شد.
کاربرد این روش عمدتاً در ابتدای ظهور در مورد کاربردهای پزشکی برای احتمال وقوع یک بیماری مورد استفاده قرار میگرفت. لیکن امروزه در تمام زمینههای علمی کاربرد وسیعی یافتهاست. به عنوان مثال مدیر سازمانی میخواهد بداند در مشارکت یا عدم مشارکت کارمندان کدام متغیرها نقش پیشبینی دارند؟ مدیر تبلیغاتی میخواهد بداند در خرید یا عدم خرید یک محصول یا برند چه متغیرهایی مهم هستند؟ یک مرکز تحقیقات پزشکی میخواهد بداند در مبتلا شدن به بیماری عروق کرنری قلب چه متغیرهایی نقش پیشبینیکننده دارند؟ تا با اطلاعرسانی از احتمال وقوع کاسته شود.
رگرسیون لجستیک میتواند یک مورد خاص از مدل خطی عمومی و رگرسیون خطی دیده شود. مدل رگرسیون لجستیک، بر اساس فرضهای کاملاً متفاوتی (دربارهٔ رابطه متغیرهای وابسته و مستقل) از رگرسیون خطی است. تفاوت مهم این دو مدل در دو ویژگی رگرسیون لجستیک میتواند دیده شود. اول توزیع شرطی یک توزیع برنولی به جای یک توزیع گوسی است چونکه متغیر وابسته دودویی است. دوم مقادیر پیشبینی احتمالاتی است و محدود بین بازه صفر و یک و به کمک تابع توزیع لجستیک بدست میآید رگرسیون لجستیک احتمال خروجی پیشبینی میکند.

این مدل به صورت

است که


برآورد پارامترهای بهینه
برای بدست آوردن پارامترهای بهینه یعنی میتوان از روش برآورد درست نمایی بیشینه (Maximum Likelihood Estimation) استفاده کرد. اگر فرض کنیم که تعداد مثالهایی که قرار است برای تخمین پارامترها استفاده کنیم است و این مثالها را به این شکل نمایش دهیم . پارامتر بهینه پارامتری است که برآورد درست نمایی را بیشینه کند، البته برای سادگی کار برآورد لگاریتم درست نمایی را بیشینه میکنیم. لگاریتم درست نمایی داده برای پارامتر را با نمایش میدهیم:
![{\displaystyle {\vec {\beta }}=[\beta _{0},\beta _{1},\cdots ,\beta _{k}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bdc88718ceff56832c5b289e0604368f643eea58)






اگر برای داده ام باشد، هدف افزایش است و اگر صفر باشد هدف افزایش مقدار است. از این رو از فرمول استفاده میکنیم که اگر باشد، فرمول به ما را بدهد و اگر بود به ما را بدهد.







حال برای بدست آوردن پارامتر بهینه باید یی پیدا کنیم که مقدار را بیشینه کند. از آنجا که این تابع نسبت به مقعر است حتماً یک بیشینه مطلق دارد. برای پیدا کردن جواب میتوان از روش گرادیان افزایشی از نوع تصادفی اش استفاده کرد (Stochastic Gradient Ascent). در این روش هر بار یک مثال را بهصورت اتفاقی از نمونههای داده انتخاب کرده، گرادیان درست نمایی را حساب میکنیم و کمی در جهت گرادیان پارامتر را حرکت میدهیم تا به یک پارامتر جدید برسیم. گرادیان جهت موضعی بیشترین افزایش را در تابع به ما نشان میدهد، برای همین در آن جهت کمی حرکت میکنیم تا به بیشترین افزایش موضعی تابع برسیم. اینکار را آنقدر ادامه میدهیم که گرادیان به اندازه کافی به صفر نزدیک شود. بجای اینکه دادهها را بهصورت تصادفی انتخاب کنیم میتوانیم به ترتیب داده شماره تا داده شماره را انتخاب کنیم و بعد دوباره به داده اولی برگردیم و این کار را بهصورت متناوب چندین بار انجام دهیم تا به اندازه کافی گرادیان به صفر نزدیک شود. از لحاظ ریاضی این کار را میتوان به شکل پایین انجام داد، پارامتر را در ابتدا بهصورت تصادفی مقدار دهی میکنیم و بعد برای داده ام و تمامی ها، یعنی از تا تغییر پایین را اعمال میکنیم، دراینجا همان مقداریست که در جهت گرادیان هربار حرکت میکنیم و مشتق جزئی داده ام در بُعد ام است:







تنظیم مدل (Regularization)
پیچیدگی مدلهای پارامتری با تعداد پارامترهای مدل و مقادیر آنها سنجیده میشود. هرچه این پیچیدگی بیشتر باشد خطر بیشبرازش (Overfitting) برای مدل بیشتر است. پدیده بیشبرازش زمانی رخ میدهد که مدل بجای یادگیری الگوهای داده، داده را را حفظ کند و در عمل، فرایند یادگیری به خوبی انجام نمیشود. برای جلوگیری از بیشبرازش در مدلهای خطی مانند رگرسیون خطی یا رگرسیون لجستیک جریمهای به تابع هزینه اضافه میشود تا از افزایش زیاد پارامترها جلوگیری شود. تابع هزینه را در رگرسیون لجستیک با منفی لگاریتم درستنمایی تعریف میکنیم تا کمینه کردن آن به بیشینه کردن تابع درست نمایی بیانجامد. به این کار تنظیم مدل یا Regularization گفته میشود. دو راه متداول تنظیم مدلهای خطی روشهای و هستند. در روش ضریبی از نُرمِ به تابع هزینه اضافه میشود و در روش ضریبی از نُرمِ که همان نُرمِ اقلیدسی است به تابع هزینه اضافه میشود.


در تنظیم مدل به روش تابع هزینه را به این شکل تغییر میدهیم:

این روش تنظیم مدل که به روش لاسو (Lasso) نیز شهرت دارد باعث میشود که بسیاری از پارامترهای مدل نهائی صفر شوند و مدل به اصطلاح خلوت (Sparse) شود.
در تنظیم مدل به روش تابع هزینه را به این شکل تغییر میدهیم:

در روش تنظیم از طریق سعی میشود طول اقلیدسی بردار کوتاه نگه داشته شود. در روش و یک عدد مثبت است که میزان تنظیم مدل را معین میکند. هرچقدر کوچکتر باشد جریمه کمتری برا بزرگی نرم بردار پارامترها یعنی پرداخت میکنیم. مقدار ایدئال از طریق آزمایش بر روی داده اعتبار (Validation Data) پیدا میشود.

تفسیر احتمالی تنظیم مدل
اگر بجای روش درست نمایی بیشینه از روش بیشینه سازی احتمال پسین استفاده کنیم به ساختار «تنظیم مدل» یا همان regularization خواهیم رسید. اگر مجموعه داده را با نمایش بدهیم و پارامتری که به دنبال تخمین آن هستیم را با ، احتمال پسین ، طبق قانون بیز متناسب خواهد بود با حاصلضرب درست نمایی یعنی و احتمال پیشین یعنی:




ازین رو

معادله خط پیشین نشان میدهد که برای یافتن پارامتر بهینه فقط کافیست که احتمال پیشین را نیز در معادله دخیل کنیم. اگر احتمال پیشین را یک توزیع احتمال با میانگین صفر و کوواریانس در نظر بگیریم به معادله پایین میرسیم:


با ساده کردن این معادله به نتیجه پایین میرسیم:

با تغییر علامت معادله، بیشینهسازی را به کمینهسازی تغییر میدهیم، در این معادله همان است:


همانطور که دیدیم جواب همان تنظیم مدل با نرم است.
حال اگر توزیع پیشین را از نوع توزیع لاپلاس با میانگین صفر در نظر بگیریم به تنظیم مدل با نرم خواهیم رسید.
از آنجا که میانگین هر دو توزیع پیشین صفر است، پیشفرض تخمین پارامتر بر این بنا شدهاست که اندازه پارامتر مورد نظر کوچک و به صفر نزدیک باشد و این پیشفرض با روند تنظیم مدل همخوانی دارد.
منبع
رگرسیون لوژستیک (لجستیک)
زمانی که متغیر وابسته ی ما دو وجهی (دو سطحی مانند جنسیت، بیماری یا عدم بیماری و …) است و می خواهیم از طریق ترکیبی از متغیرهای پیش بین دست به پیش بینی بزنیم باید از رگرسیون لجستیک استفاده کنیم. چند مثال از کاربردهای رگرسیون لجستیک در زیر ارائه می گردد.
1. در فرایند همه گیر شناسی ما می خواهیم ببینیم آیا یک فرد بیمار است یا خیر. اگر به عنوان مثال بیماری مورد نظر بیماری قلبی باشد پیش بینی کننده ها عبارتند از سن، وزن، فشار خون سیستولیک، تعداد سیگارهای کشیده شده و سطح کلسترول.
2. در بازاریابی ممکن است بخواهیم بدانیم آیا افراد یک ماشین جدیدی را می خرند یا خیر. در اینجا متغیرهایی مانند درآمد سالانه، مقدار پول رهن، تعداد وابسته ها، متغیرهای پیش بین می باشند.
3. در تعلیم و تربیت فرض کنید می خواهیم بدانیم یک فرد در امتحان نمره می آورد یا خیر.
4. در روانشناسی می خواهیم بدانیم آیا فرد یک رفتار بهنجار اجتماعی دارد یا خیر.
در تمام موارد گفته شده متغیر وابسته یک متغیر دو حالتی است که دو ارزش دارد. زمانی که متغیر وابسته دو حالتی است مسایل خاصی مطرح می شود.
1. خطا دارای توزیع نرمال نیست. 2. واریانس خطا ثابت نیست. 3. محدودیت های زیادی در تابع پاسخ وجود دارد. مشکل سوم مطرح شده مشکل جدی تری است.
می توان از روش حداقل مجذورات وزنی برای حل مشکل مربوط به واریانس های نابرابر خطا استفاده نمود. بعلاوه زمانی که حجم نمونه بالا باشد می توان روش حداقل مجذورات برآوردگرهایی را ارائه می دهد که به طور مجانبی و تحت موقعیت های نسبتا عمومی نرمال می باشند. ما در رگرسیون لجستیک به طور مستقیم احتمال وقوع یک رخداد را محاسبه می کنیم. چرا که فقط دو حالت ممکن برای متغیر وابسته ی ما وجود دارد.
دو مساله ی مهم که باید در ارتباط با رگرسیون لجستیک در نظر داشته باشیم عبارتند از:
1. رابطه ی بین پیش بینی کننده ها و متغیر وابسته غیر خطی است.
2. ضرایب رگرسیونی از طریق روش ماکزیمم درستنمایی برآورد می شود.
رگرسیون لجستیک از لحاظ محاسبات آماری شبیه رگرسیون چند گانه است اما از لحاظ کارکرد مانند تحلیل تشخیصی می باشد. در این روش عضویت گروهی بر اساس مجموعه ای از متغییرهای پیش بین انجام می شود دقیقا مانند تحلیل تشخیصی. مزیت عمده ای که تحلیل لجستیک نسبت به تحلیل تشخیصی دارد این است که در این روش با انواع متغیرها به کار می رود و بنابراین بسیاری از مفروضات در مورد داده ها را به کار ندارد. در حقیقت آنچه در رگرسیون لجستیک پیش بینی می شود یک احتمال است که ارزش آن بین 0 تا 1 در تغییر است. ضرایب رگرسیونی مربوط به معادله ی رگرسیون لجستیک اطلاعاتی را راجع به شانس هر مورد خاص برای تعلق به گروه صفر یا یک ارائه می دهد. شانس به صورت احتمال موفقیت در برابر شکست تعریف می شود. ولی بدلیل ناقرینگی و امکان وجود مقادیر بی نهایت برای آن تبدیل به لگاریتم شانس می شود. هر یک از وزن ها را می توان از طریق مقدار خی دو که به آماره ی والد مشهور است به لحاظ معناداری آزمود. لگاریتم شانس، شانسی را که یک متغییر به طور موفقیت آمیزی عضویت گروهی را برای هر مورد معین پیش بینی می کند را نشان می دهد.
به طور کلی در روش رگرسیون لجستیک رابطه ی بین احتمال تعلق به گروه 1 و ترکیب خطی متغیرهای پیش بین بر اساس توزیع سیگمودال تعریف می شود. برای دستیابی به معادله ی رگرسیونی و قدرت پیش بینی باید به نحوی بتوان رابطه ای بین متغیرهای پیش بین و وابسته تعریف نمود. برای حل این مشکل از نسبت احتمال تعلق به گروه یک به احتمال تعلق به گروه صفر استفاده می شود. به این نسبت شانس OR گویند. به خاطر مشکلات شانس از لگاریتم شانس استفاده می شود. لگاریتم شانس با متغیرهای پیش بینی کننده ارتباط خطی دارد. بنابراین ضرایب بدست آمده برای آن باید بر اساس رابطه ی خطی که با لگاریتم شانس دارند تفسیر گردند. بنابراین اگر بخواهیم تفسیر را بر اساس احتمال تعلق به گروهها انجام دهیم باید لگاریتم شانس را به شانس و شانس را به اجزای زیر بنایی آن که احتمال تعلق است تبدیل نماییم. آماره ی والد که از توزیع خی دو پیروی می کند نیز برای بررسی معناداری ضرایب استفاده می شود. از آزمون هاسمر و لمشو نیز برای بررسی تطابق داده ها با مدل استفاده می شود معنادار نبودن این آزمون که در واقع نوعی خی دو است به معنای عدم تفاوت داده ها با مدل یعنی برازش داده با مدل است.
رگرسیون چند متغیری: در این رگرسیون هدف این است که از طریق مجموعه ای از متغیرهای پیش بین به پیش بینی چند متغیر وابسته پرداخته شود در واقع اتفاقی که در رگرسیون کانونی می افتد.
رگرسیون لجستیک (LOGESTIC REGRESSION)
همان طور که میدانیم در رگرسیون خطی، متغیر وابسته یک متغیر کمی در سطح فاصلهای یا نسبی است و پیش بینی کننده ها از نوع متغیرهای پیوسته، گسسته یا ترکیبی از این دو هستند. اما هنگامی که متغیر وابسته در کمی نباشد، یعنی به صورت دو یا چندمقولهای باشد، از رگرسیون لجستیک استفاده میکنیم که امکان پیشبینی عضویت گروهی را فراهم میکند. این روش موازی روشهای تحلیل تشخیصی و تحلیل لگاریتمی است. برای مثال، پیش بینی مرگ و میر نوزادان بر اساس جنسیت نوزاد، دوقلو بودن و سن و تحصیلات مادر.
بسیاری از مطالعات پژوهشی در علوم اجتماعی و علوم رفتاری، متغیرهای وابسته از نوع دو مقوله ای را بررسی میکنند. مانند: رأی دادن یا ندادن در انتخابات، مالکیت (مثلاٌ داشتن یا نداشتن کامپیوتر شخصی) و سطح تحصیلات (مانند: داشتن یا نداشتن تحصیلات دانشگاهی) ارزیابی میشود. از جمله حالت های پاسخ دوتایی عبارتند از: موافق- مخالف، موفقیت – شکست، حاضر – غایب و جانبداری – عدم جانبداری.
متغیرهای تحلیل رگرسیون لجستیک
در تحلیل رگرسیون لجستیک، همیشه یک متغیر وابسته و معمولا مجموعه ای از متغیرهای مستقل وجود دارند که ممکن است دو مقوله ای، کمی یا ترکیبی از آن ها باشند. به علاوه لازم نیست متغیرهای دو مقوله ای به طور واقعی دوتایی باشند. به عنوان مثال ممکن است پژوهشگران متغیر وابسته کمی دارای کجی شدید را به یک متغیر دومقوله ای که در هر طبقه آن تعداد موردها تقریباً مساوی است تبدیل کنند. مانند آن چه که در مورد رگرسیون چندگانه دیدیم، برخی از متغیرهای مستقل در رگرسیون لجستیک می توانند به عنوان متغیرهای همپراش (covariates) مورد استفاده قرار گیرند تا پژوهشگران بتوانند با ثابت نگه داشتن یا کنترل آماری این متغیرها اثرات دیگر متغیرهای مستقل را بهتر ارزیابی کنند.
پیش فرض های رگرسیون لجستیک
با این که رگرسیون لجستیک در مقایسه با رگرسیون خطی پیش فرض های کمتری دارد (به عنوان مثال پیش فرض های همگنی واریانس و نرمال بودن خطاها وجود ندارد)، رگرسیون لجستیک نیازمند موارد زیر است:
- هم خطی چندگانه کامل وجود نداشته باشد.
- خطاهای خاص نباید وجود داشته باشد (یعنی، همه متغیرهای پیش بین مرتبط وارد شوند و پیش بین های نامربوط کنار گذاشته شوند).
- متغیرهای مستقل باید در مقیاس پاسخ تراکمی یا جمع پذیر (cumulative response scale)، فاصله ای یا سطح نسبی اندازه گیری شده باشند (هر چند که متغیرهای دو مقوله ای نیز می توانند مورد استفاده قرار گیرند).
برای تفسیر درست نتایج، رگرسیون لجستیک در مقایسه با رگرسیون خطی نیازمند نمونه های بزرگتری است. با این که آماردان ها در خصوص شرایط دقیق نمونه توافق ندارند. بسیاری پیشنهاد می کنند تعداد افراد نمونه حداقل باید ۳۰ برابر تعداد پارامترهایی باشند که برآورد می شوند.
منبع
رگرسیون لجستیک چیست؟
رگرسیون لجستیک نسبت به تحلیل تشخیصی نیز ارجحیت دارد و مهم ترین دلیل آن است که در تحلیل تشخیصی گاهی اوقات احتمال وقوع یک پدیده خارج از طیف(۰) تا (۱) قرار می گیرد و متغیرهای پیش بین نیز باید دارای توزیع در داخل محدوده (۰) تا (۱) قرار دارد و رعایت پیش فرض نرمال بودن متغیرهای پیش بینی لازم نیست (سرمد، ۱۳۸۴: ۳۳۱).
انواع رگرسیون لجستیک
همان طور که در ابتدای مبحث تحلیل رگرسیون لجستیک گفته شد، در رگرسیون لجستیک، متغیر وابسته می تواند به دو شکل دووجهی و چندوجهی باشد. به همین خاطر، در نرم افزارSPSS شاهد وجود دو نوع تحلیل رگرسیون لجستیک هستیم که بسته به تعداد مقولات و طبقات متغیر وابسته، می توانیم از یکی از این دو شکل استفاده کنیم:
۱-رگرسیون لجستیک اسمی دووجهی: موقعی است که متغیر وابسته در سطح اسمی دووجهی (دوشقی) است. یعنی در زمانی که با متغیر وابسته اسمی دووجهی سروکار داریم.
۲-رگرسیون لجستیک اسمی چندوجهی : موقعی مورد استفاده قرار می گیرد که متغیر وابسته، اسمی چندوجهی (چندشقی) است.
منبع

دیدگاه خود را ثبت کنید
تمایل دارید در گفتگوها شرکت کنید؟در گفتگو ها شرکت کنید.