خوشه بندی (Clustering) قسمت 1
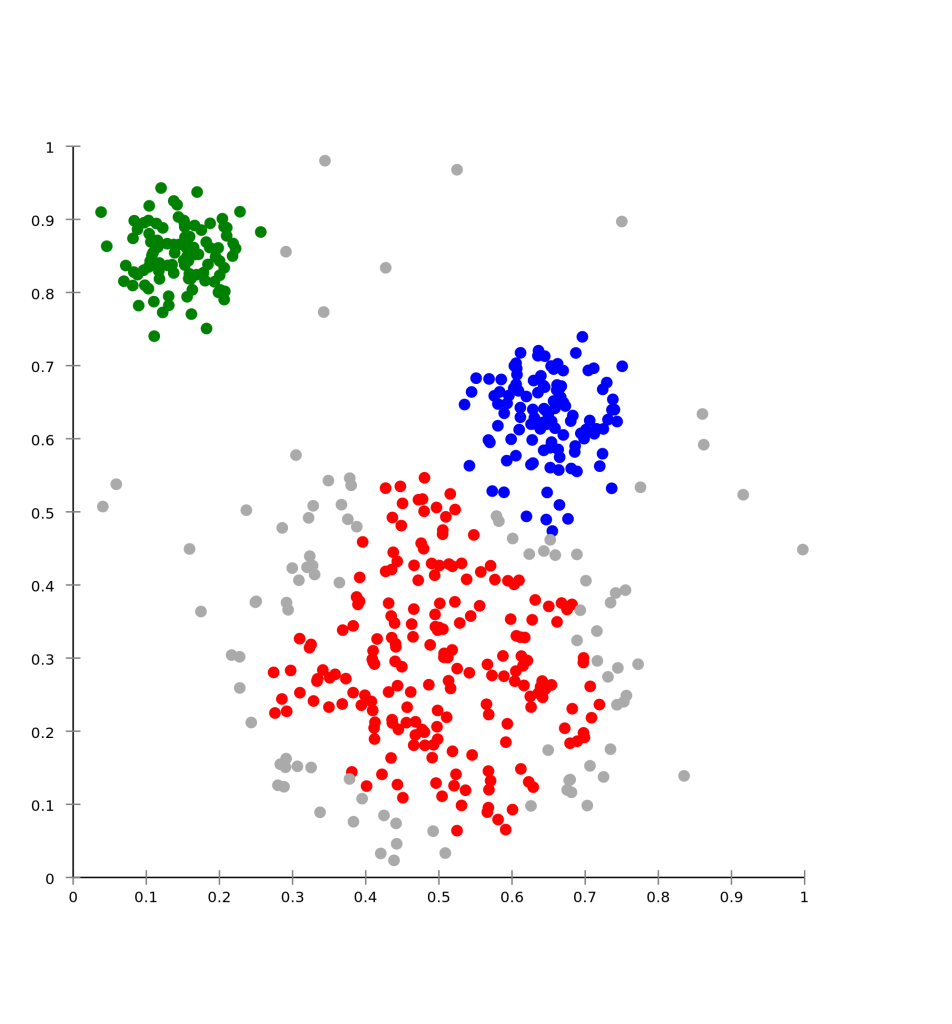
در تجزیه و تحلیل خوشه یا خوشه بندی، گروه بندی مجموعه ای از اشیاء انجام میشود اینکار به این صورت است که اشیاء در یک گروه (به نام خوشه) در مقایسه با دیگر دستهها (خوشه ها) مشابه تر هستند. این وظیفه اصلی داده کاوی اکتشافی است و یک روش معمول برای تجزیه و تحلیل دادههای آماری است که در بسیاری از زمینهها از جمله یادگیری ماشین، تشخیص الگو،تجزیه و تحلیل تصویر، بازیابی اطلاعات، بیوانفورماتیک، فشرده سازی دادهها و گرافیک کامپیوتری استفاده میشود.

تجزیه و تحلیل خوشه ای خود یک الگوریتم خاص نیست، بلکه روند کلی است و میتواند توسط الگوریتمهای مختلفی به دست آید که در درک آنچه که یک خوشه را تشکیل می دهند و نحوه کارآمدی آنها را پیدا میکند.
اصطلاحات خوشهها شامل گروههایی با فاصلههای کم بین اعضای خوشه، مناطق متراکم فضای داده، فواصل و یا توزیعهای آماری خاص است. بنابراین خوشه بندی میتواند به عنوان یک مسئله بهینه سازی چند هدفه صورت گیرد. الگوریتم خوشه بندی مناسب و تنظیمات پارامتر (از جمله پارامترهایی مانند تابع فاصله مورد استفاده، آستانه تراکم یا تعداد خوشه مورد انتظار) بستگی به تنظیم مجموعه دادهها توسط فرد و استفاده خاص فرد از نتایج دارد. تجزیه و تحلیل خوشه ای یک روش اتوماتیک نیست، بلکه یک فرآیند تکراری از کشف دانش یا بهینه سازی چند هدفه تعاملی است که شامل آزمایش و شکست است. اغلب لازم است که دادههای پیش پردازش شده و پارامترهای مدل اصلاح شوند تا نتیجه حاصل ، همان نتیجهٔ دلخواه باشد.
علاوه بر اصطلاحات خوشه بندی، تعدادی از اصطلاح با معانی مشابه وجود دارد، از جمله طبقه بندی خودکار، طبقه بندی عددی، روششناسی و تجزیه و تحلیل توپولوژیکی. تفاوتهای کم اغلب در نتایج استفاده میشود: در داده کاوی، نتیجه گروهها مورد توجه هست و در طبقه بندی خودکار، قدرت تشخیصی مورد توجه است.
تجزیه و تحلیل خوشه ای در انسانشناسی توسط Driver و Kroeber در سال 1932 آغاز شد و در روانشناسی توسط زوبین در سال 1938 و رابرت تیرون در سال 1939 معرفی شد و در سال 1943 برای طبقه بندی نظریه رفتاری در روانشناسی شخصیت توسط Cattell استفاده شدهاست.
تعریف
مفهوم “خوشه” را دقیقا نمیتوان تعریف کرد،یکی از دلایلش این است که الگوریتمهای خوشه بندی زیادی وجود دارد. همهٔ آنها یک قسمت مشترک دارند و آن یک گروه از اشیاء داده است. با این حال، محققان از مدلهای مختلف خوشه استفاده میکنند و برای هر یک از این مدلهای خوشه، الگوریتمهای مختلفی را میتوان ارائه داد. مفهوم یک خوشه، همانطور که توسط الگوریتمهای مختلف یافت میشود، بهطور خاصی در خواص تفاوت دارند. درک این مدلهای خوشه ، کلید فهمیدن تفاوت بین الگوریتمهای مختلف است. مدلهای خوشه ای معمول عبارتند از:
- مدلهای متصل: به عنوان مثال، خوشه بندی سلسله مراتبی، مدلهایی براساس فاصله متصل را ایجاد میکند.
- مدلهای مرکزی: به عنوان مثال، الگوریتم k-means ، هر خوشه را با یک بردار متوسط نشان میدهد.
- مدلهای توزیع: خوشهها با استفاده از توزیعهای آماری، مانند توزیع نرمال چند متغیره که در الگوریتم حداکثر انتظار ، استفاده شدهاست.
- مدلهای تراکم: به عنوان مثال، DBSCAN و OPTICS خوشه را به عنوان مناطق متراکم متصل در فضای داده تعریف میکنند.
- مدلهای زیر فضایی: در biclustering (که به عنوان خوشه مشترک یا خوشه ای دو حالت شناخته میشود)، خوشهها با هر دو اعضای خوشه و ویژگیهای مرتبط مدل سازی میشوند.
- مدلهای گروهی: برخی از الگوریتمها یک مدل تصحیح شده برای نتایج خود را ارائه نمی دهند و فقط اطلاعات گروه بندی را ارائه می دهند.
- مدلهای مبتنی بر گراف: یک کلاس، یعنی یک زیر مجموعه از گرهها در یک گراف به طوری که هر دو گره در زیر مجموعه با یک لبه متصل میشود که میتواند به عنوان یک شکل اولیه از خوشه مورد توجه قرار گیرد.
- مدلهای عصبی: شبکه عصبی غیرقابل نظارت ، شناخته شدهترین نقشه خود سازمانی است و معمولا این مدلها می توانند به عنوان مشابه با یک یا چند مدل فوق شامل مدلهای زیر فضایی، زمانی که شبکههای عصبی یک فرم تجزیه و تحلیل مؤلفه اصلی یا مستقل تجزیه و تحلیل المان میباشد .
“خوشه بندی” اساسا مجموعه ای از خوشهها است که معمولا شامل تمام اشیاء در مجموعه دادهها میشود. علاوه بر این، میتوان رابطه خوشهها را به یکدیگر تعریف کند، به عنوان مثال، سلسله مراتب خوشههای تعبیه شده در یکدیگر.
خوشه بندی را میتوان براساس سختی تمایز به صورت زیر مشخص کرد:
- خوشه بندی سخت: هر شیء متعلق به خوشه است یا نه.
- خوشه بندی نرم (همچنین: خوشه فازی): هر شیء به درجه خاصی از هر خوشه متعلق است (به عنوان مثال، احتمال وابستگی به خوشه)
همچنین امکان تمایز دقیق تر وجود دارد، مثلا:
- خوشه بندی جداسازی دقیق ( پارتیشن بندی): هر شیء دقیقا به یک خوشه متعلق است.
- خوشه بندی جداسازی دقیق با ناپیوستگی: اشیاء می توانند به هیچ خوشه ای تعلق نداشته باشند.
- خوشه بندی همپوشانی (همچنین: خوشه بندی جایگزین، خوشه بندی چندگانه): اشیاء ممکن است متعلق به بیش از یک خوشه باشد؛ معمولا خوشههای سخت را شامل میشود
- خوشه بندی سلسله مراتبی: اشیایی که متعلق به خوشه فرزند هستند، متعلق به خوشه پدر و مادر هم هستند.
- خوشه بندی زیر فضا: در حالی که خوشه بندی همپوشانی، که در یک زیر فضای منحصر به فرد تعریف شده ، انتظار نمی رود که خوشهها با همپوشانی داشته باشند.
الگوریتم
همانطور که در بالا ذکر شد، الگوریتمهای خوشه بندی را میتوان بر اساس مدل خوشه ای طبقه بندی کرد. در ادامه نمونههای برجسته ای از الگوریتمهای خوشه بندی بیان شدهاست، زیرا احتمالا بیش از 100 الگوریتم خوشه بندی منتشر شده وجود دارد. همه مدلها برای خوشه هایشان بیان نشده اند، بنابراین نمی توان به راحتی دسته بندی کرد.
الگوریتم خوشه بندی عینی “صحیح” وجود ندارد، اما همانطور که اشاره شد، “خوشه بندی در چشم بیننده است.” بهترین الگوریتم خوشه بندی برای یک مسئله خاص، اغلب باید به صورت تجربی انتخاب شود، مگر اینکه یک دلیل ریاضی برای ترجیح دادن یک مدل خوشه بر دیگری وجود داشته باشد. لازم به ذکر است که یک الگوریتم که برای یک نوع مدل طراحی شدهاست و در یک مجموعه داده ای که شامل تفاوت اساسی مدل است، شکست می خورد. به عنوان مثال، k-means نمیتواند خوشههای غیرمحدب را پیدا کند.
خوشه بندی براساس اتصال (خوشه بندی سلسله مراتبی)
خوشه بندی براساس اتصال، که همچنین به عنوان خوشه بندی سلسله مراتبی شناخته میشود، بر مبنای ایده اصلی اشیائی است که بیشتر مربوط به اشیای نزدیک، نسبت به اشیاء دورتر است. این الگوریتمها “اشیا” را برای ایجاد “خوشه ها” بر اساس فاصله آنها متصل میکنند. خوشه را میتوان به طورکلی با حداکثر فاصله مورد نیاز برای اتصال قطعات خوشه توصیف کرد. در فاصلههای مختلف، خوشههای متفاوتی شکل میگیرند که میتواند با استفاده از یک دندروگرام نشان داده شود، که توضیح میدهد که نام معمول “خوشه بندی سلسله مراتبی” از آن می آید: این الگوریتمها یک پارتیشن بندی مچموعه داده را ارائه نمی دهند، بلکه یک سلسله مراتب گسترده ای از خوشههایی که در فاصلههای معینی با یکدیگر ادغام میشوند، ارائه میدهد. در یک دندروگرام، محور y نشان دهنده فاصله ای است که خوشهها ادغام میکنند، در حالی که اشیا در امتداد محور x قرار میگیرند به طوری که خوشهها با هم مخلوط نمیشوند.
خوشه بندی سلسله مراتبی شامل دو نوع خوشه بندی میباشد:
single linkage -1 این روش که به روش Bottom-Up و Agglomerative نیز معروف است روشی است که در آن ابتدا هر داده به عنوان یک خوشه در نظر گرفته میشود. در ادامه با به کارگیری یک الگوریتم هر بار خوشههای دارای ویژگیهای نزدیک به هم با یکدیگر ادغام شده و این کار ادامه مییابد تا به چند خوشهٔ مجزا برسیم. مشکل این روش حساس بودن به نویز و مصرف زیاد حافظه میباشد.
complete linkage -2 در این روش که به روش Top-Down و Divisive نیز معروف است ابتدا تمام دادهها به عنوان یک خوشه در نظر گرفته شده و با به کارگیری یک الگوریتم تکرار شونده هربار دادهای که کمترین شباهت را با دادههای دیگر دارد به خوشههای مجزا تقسیم میشود. این کار ادامه مییابد تا یک یا چند خوشه یک عضوی ایجاد شود. مشکل نویز در این روش برطرف شدهاست.
مثال هایی از خوشه linkage

خوشه بندی براساس centroid
در خوشه بندی براساس centroid، خوشهها با یک بردار مرکزی نشان داده میشوند، که ممکن است لزوما جزء مجموعه داده نباشد. هنگامی که تعدادی از خوشهها به k متصل میشوند، خوشه بندی k-means یک تعریف رسمی را به عنوان یک مسئله بهینه سازی ارائه میدهد.
روش میانگین k در عین سادگی یک روش بسیار کاربردی و پایه چند روش دیگر مثل خوشه بندی فازی و Segment-wise distributional clustering Algorithm میباشد.روش کار به این صورت است که ابتدا به تعداد دلخواه نقاطی به عنوان مرکز خوشه در نظر گرفته میشود. سپس با بررسی هر داده، آن را به نزدیکترین مرکز خوشه نسبت میدهیم. پس از اتمام این کار با گرفتن میانگین در هر خوشه میتوانیم مراکز خوشه و به دنبال آن خوشههای جدید ایجاد کنیم. (با تکرار مراحل قبل)از جمله مشکلات این روش این است که بهینگی آن وابسته به انتخاب اولیه مراکز بوده و بنابراین بهینه نیست. مشکلات دیگر آن تعیین تعداد خوشهها و صفر شدن خوشهها میباشد.
K-means دارای تعدادی خواص نظری است. اول، فضای داده را به یک ساختار معروف به یک نمودار Voronoi تقسیم میکند. دوم، به لحاظ مفهومی نزدیک به طبقه بندی نزدیکترین همسایه است و به همین علت در یادگیری ماشین محبوب است. سوم، میتوان آن را به عنوان تنوع خوشه بندی براساس مدل مشاهده کرد.
مثال هایی از خوشه بندی k-means

خوشه بندی براساس توزیع
این مدل خوشه بندی که دقیقا مربوط به آمار میباشد، بر اساس مدلهای توزیع است.خوشهها به راحتی می توانند به عنوان اشیایی تعریف میشوند که به احتمال زیاد ب توزیع یکسانی دارند. یک ویژگی خوب این رویکرد این است که با نمونه برداری از اشیاء تصادفی از یک توزیع، دقیقا شبیه نحوه تولید مجموعه دادههای مصنوعی است. مبنای نظری این روشها عالی است، ولی مشکل اصلی overfitting دارند، مگر اینکه محدودیتها بر پیچیدگی مدل قرار بگیرد.
یک روش شناخته شده ،مدل مخلوط گاوس (با استفاده از الگوریتم حداکثر سازی انتظار) است. مجموعه دادهها معمولا با یک ثابت (برای جلوگیری از overfitting) تعداد توزیعهای گاوسی که به صورت تصادفی استفاده شده و به منظور مناسب تر کردن مجموعه داده مدل ، پارامترهای آن بهطور تکراری بهینه شدهاست که به یک بهینه محلی همگرا میشود، بنابراین در طول چند اجرا ممکن است نتایج متفاوتی تولید کند. به منظور به دست آوردن خوشه بندی سخت، اشیاء اغلب به توزیع گاوسی که به احتمال زیاد متعلق به آنهاست، اختصاص داده است که برای خوشه بندی نرم، اینکار لازم نیست.خوشه بندی مبتنی بر توزیع، مدلهای پیچیده ای را برای خوشهها ایجاد میکند که میتواند همبستگی و وابستگی ویژگی را نشان دهد.
مثال های Expectation-maximization (EM)

خوشه بندی براساس Density
در این تکنیک این اصل مطرح میشود که خوشهها مناطقی با چگالی بیشتر هستند که توسط مناطق با چگالی کمتر از هم جدا شدهاند. یکی از مهمترین الگوریتمها در این زمینه الگوریتم DBSCAN است.
روش این الگوریتم به این صورت است که هر داده متعلق به یک خوشه در دسترس چگالی سایر دادههای همان خوشه است، ولی در دسترسی چگالی سایر دادههای خوشههای دیگر نیست.(چگالی داده همسایگی به مرکز داده و شعاع همسایگی دلخواه ε است)مزیت این روش این است که تعداد خوشهها به صورت خودکار مشخص میشود. در تشخیص نویز نیز بسیار کاراست.
مثال هایی برای خوشه بندی براساس Density

پیشرفت های اخیر
در سالهای اخیر تلاشهای قابل توجهی در بهبود عملکرد الگوریتمهای موجود انجام شدهاست.با توجه به نیازهای جدید به پردازش دادههای خیلی بزرگ، تمایل به کاربرد خوشههای تولید شده برای عملکرد تجاری افزایش یافتهاست. این امر منجر به توسعه روشهای پیش خوشه سازی مانند خوشه بندیcanopy میشود که میتواند دادههای حجیم را بهطور مؤثر پردازش کند.
برای دادههای با ابعاد بزرگ، بسیاری از روشهای موجود به علت ابعاد شکست خورده است، که باعث میشود که توابع خاص فاصله در فضاهای بزرگ بعدی مشکل ساز باشند. این باعث شد که الگوریتمهای خوشه بندی جدید برای دادههای با ابعاد بزرگ ، بر خوشه بندی زیر فضایی تمرکز کنند و استفاده شود.
چندین سیستم خوشه بندی مختلف مبتنی بر اطلاعات متقابل پیشنهاد شدهاست. یکی از آن ها، تغییرات اطلاعات مارینا مالگا است که یکی دیگر از خوشه بندی سلسله مراتبی را فراهم میکند. با استفاده از الگوریتمهای ژنتیکی، طیف گسترده ای از تناسب توابع مختلف، از جمله اطلاعات متقابل، میتواند بهینه سازی شود،پیشرفت اخیر در علوم کامپیوتری و فیزیک آماری، منجر به ایجاد انواع جدیدی از الگوریتمهای خوشه بندی شدهاست.
خوشه بندی (Clustering) قسمت 1
خوشه بندی (Clustering) قسمت 2
خوشه بندی (Clustering) قسمت 3

دیدگاه خود را ثبت کنید
تمایل دارید در گفتگوها شرکت کنید؟در گفتگو ها شرکت کنید.