خوشهبندی سلسله مراتبی (Hierarchical Clustering)
برعکس خوشهبندی تفکیکی که اشیاء را در گروههای مجزا تقسیم میکند، «خوشهبندی سلسله مراتبی» (Hierarchical Clustering)، در هر سطح از فاصله، نتیجه خوشهبندی را نشان میدهد. این سطوح به صورت سلسله مراتبی (Hierarchy) هستند.
برای نمایش نتایج خوشهبندی به صورت سلسله مراتبی از «درختواره» (Dendrogram) استفاده میشود. این شیوه، روشی موثر برای نمایش نتایج خوشهبندی سلسله مراتبی است. در تصویر ۲ نتایج خوشهبندی سلسله مراتبی روی دادههای s=1,3,6,2,8,10 با استفاده از درختواره را میبینید.
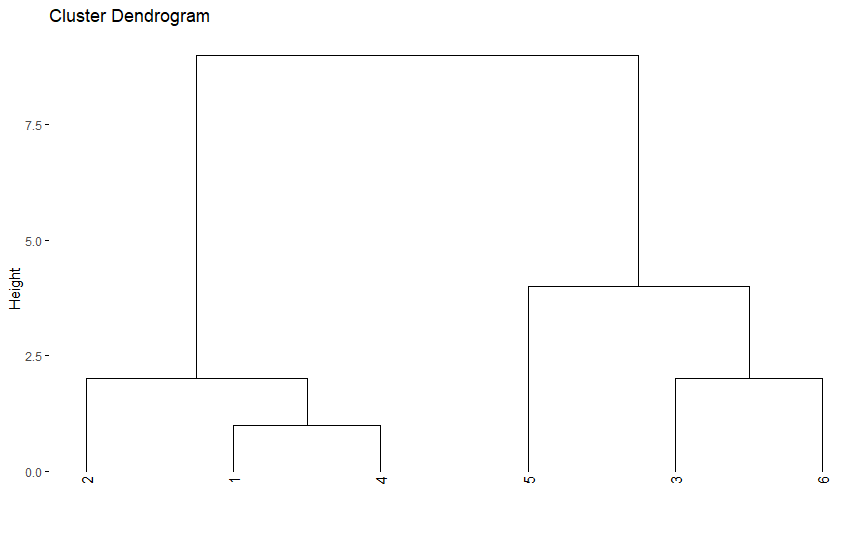
تصویر ۲- نمودار دختواره برای دادههای مربوط s=1,3,6,2,8,10
همانطور که در تصویر ۲ قابل رویت است، ابتدا هر مقدار یک خوشه محسوب میشود. در طی مراحل خوشهبندی، نزدیکترین مقدارها (براساس تابع فاصله تعریف شده) با یکدیگر ادغام شده و خوشه جدیدی میسازند.
در نتیجه براساس تصویر ۲ ابتدا در مرحله اول مقدار اول و چهارم تشکیل اولین خوشه را میدهند، زیرا کمترین فاصله را دارند. سپس در مرحله دو، مقدار دوم با خوشه تشکیل شده در مرحله اول ترکیب میشود. در مرحله سوم مقدارهای سوم و ششم با هم تشکیل یک خوشه میدهند که در مرحله چهارم با مقدار پنجم ترکیب شده و خوشه جدیدی میسازند.
در انتها نیز خوشه تشکیل شده در مرحله دوم با خوشه تشکیل شده در مرحله چهارم ادغام شده و خوشه نهایی را ایجاد میکنند. همانطور که دیده میشود با داشتن شش مقدار خوشهبندی سلسله مراتبی، پنچ مرحله خواهد داشت زیرا در هر مرحله فقط یک عمل ادغام انجام میشود.
نکته: توجه داشته باشید که مقدارهایی که روی محور افقی دیده میشوند، بیانگر موقعیت مقدارها در لیست دادهها است و نه خود مقادیر. همچنین محور عمودی نیز فاصله یا ارتفاع بین خوشهها را نشان میدهد.
در الگوریتم خوشهبندی سلسله مراتبی معمولا با کوچکترین خوشهها شروع میکنیم. به این معنی که در ابتدا هر مقدار بیانگر یک خوشه است. سپس دو مقداری که بیشترین شباهت (کمترین فاصله) را دارند با یکدیگر ادغام شده و یک خوشه جدید میسازند. بعد از این مرحله، ممکن است دو مقدار یا یک مقدار با یک خوشه یا حتی دو خوشه با یکدیگر ادغام شده و خوشه جدیدی ایجاد کنند.
این عملیات با رسیدن به بزرگترین خوشه که از همه مقدارها تشکیل یافته پایان مییابد. به این ترتیب اگر n مقدار داشته باشیم در مرحله اول تعداد خوشهها برابر با n است و در آخرین مرحله یک خوشه باقی خواهد ماند.
برای اندازهگیری فاصله بین دو خوشه یا یک مقدار با یک خوشه از روشهای «پیوند» (Linkage) استفاده میشود. از انواع روشهای پیوند میتوان به «نزدیکترین همسایه» (Nearest Neighbor) یا «پیوند تکی» (Single Linkage)، «دورترین همسایه» (Furthest Neighbor) یا «پیوند کامل» (Complete Linkage) و همچنین «پیوند میانگین» (Average Linkage) اشاره کرد.
معمولا به این شیوه خوشهبندی سلسله مراتبی، روش «تجمیعی» (Agglomerative) میگویند.
برعکس اگر عمل خوشهبندی سلسله مراتبی به شکلی باشد که با بزرگترین خوشه، عملیات خوشهبندی شروع شده و با تقسیم هر خوشه به خوشههای کوچکتر ادامه پیدا کند، به آن «خوشهبندی سلسله مراتبی تقسیمی» (Divisive Hierarchical Clustering) میگویند. در آخرین مرحله این روش، هر مقدار تشکیل یک خوشه را میدهد پس n خوشه خواهیم داشت.
هر چند شیوه نمایش خوشهبندی سلسله مراتبی تقسیمی نیز توسط درختواره انجام میشود ولی از آنجایی که محدودیتهایی برای تقسیم یک خوشه به زیر خوشههای دیگر وجود دارد، روش تقسیمی کمتر به کار میرود.
نکته: در شیوه خوشهبندی سلسله مراتبی، عمل برچسب گذاری در طی مراحل خوشهبندی اصلاح پذیر نیست. به این معنی که وقتی عضوی درون یک خوشه قرار گرفت هرگز از آن خوشه خارج نمیشود.
از الگوریتمهای معروف برای خوشهبندی سلسله مراتبی تجمیعی میتوان به AGNES و برای تقسیمی به DIANA اشاره کرد.
خوشهبندی برمبنای چگالی (Density-Bases Clustering)
روشهای خوشهبندی تفکیکی قادر به تشخیص خوشههایی کروی شکل هستند. به این معنی که برای تشخیص خوشهها از مجموعه دادههایی به شکلهای «کوژ» (Convex) یا محدب خوب عمل میکنند. در عوض برای تشخیص خوشهها برای مجموعه دادههای «کاو» (Concave) یا مقعر دچار خطا میشوند. به تصویر ۳ توجه کنید که بیانگر شکلهای کاو است.
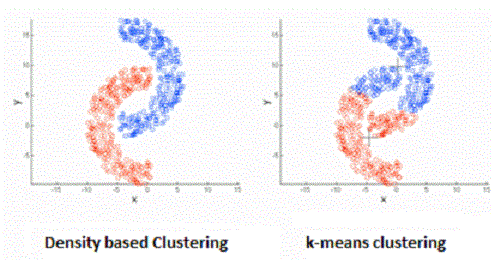
تصویر ۳- مقایسه نتایج خوشهبندی تفکیکی با روش چگالی
همانطور که دیده میشود میانگین هر دو خوشه در روش k-means در محلی قرار گرفته است که مربوط به خوشه دیگر است. در حالی که خوشهبندی برمبنای چگالی به خوبی نقاط را در خوشههای درست قرار داده است.
در الگوریتمها خوشهبندی برمبنای چگالی، نقاط با تراکم زیاد شناسایی شده و در یک خوشه قرار میگیرند. از الگوریتمهای معروف در این زمینه میتوان به DBSCAN اشاره کرد که در سال ۱۹۹۶ توسط «استر» (Ester) معرفی شد.
این الگوریتم توانایی شناسایی نقاط دورافتاده را داشته و میتواند تاثیر آنها را در نتایج خوشهبندی از بین ببرد. شیوه کارکرد این الگوریتم بنا به تعریفهای زیر قابل درک است:
- همسایگی به شعاع ϵ: اگر فضای با شعاع ϵ را حول نقطهای x در نظر بگیریم، یک همسایگی ایجاد کردهایم که به شکل Nϵ(x) نشان داده میشود. شکل ریاضی این همسایگی به صورت زیر است.
Nϵ(x)={y∈D;d(x,y)≤ϵ}
بطوری که D مجموعه داده و d تابع فاصله است. تصویر 4 مفهوم همسایگی را نشان میدهد.
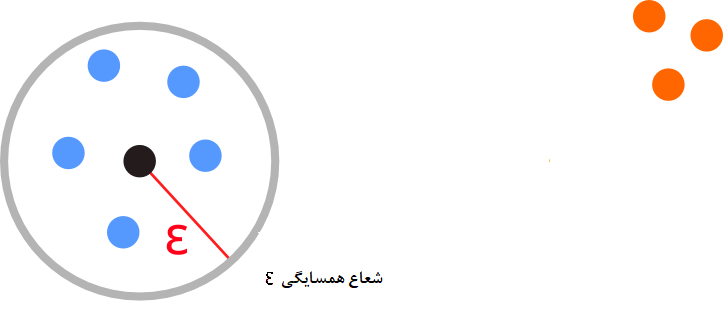
تصویر ۴- همسایگی و شعاع همسایگی
- قابل دسترسی مستقیم (Directly density-reachable): نقطه x را قابل دسترسی مستقیم از y مینامند اگر براساس دو پارامتر Nmin و ϵϵداشته باشیم:
x∈Nϵ(y)
|Nϵ(y)|≥Nmin
در اینجا |Nϵ(y)| نشانگر تعداد اعضای همسایگی به شعاع ϵ از نقطه y است.
پس شرط اول به معنی این است که x در همسایگی از y قرار دارد و شرط دوم نیز بیان میکند که باید تعداد اعضای همسایگی y از حداقل تعداد اعضای همسایگی بیشتر باشد.
- نقطه قابل دسترسی (Density-Reachable): نقطه x را از طرق y نامیده میشود، اگر دنبالهای از نقاط مثل x1,x2,…,xi موجود باشند که نقطه x را به y برسانند. یعنی:
x=x1,x2,…,xi=y
در این حالت برای مثال x1 «قابل دسترسی مستقیم» (Direct Reachable) به x2 نامیده میشود.
- نقاط متصل (Density-Connected): دو نقطه x و y را متصل گویند اگر براساس پارامترهای ϵ و Nmin نقطهای مانند z وجود داشته باشد که هر دو نقطه x و y از طریق آن قابل دسترسی باشند.
- خوشه (Cluster): فرض کنید مجموعه داده D موجود باشد. همچنین C یک زیر مجموعه غیر تهی از D باشد. C را یک خوشه مینامند اگر براساس پارمترهای ϵ و Nmin در شرایط زیر صدق کند:
۱- اگر x درون C باشد و y نیز قابل دسترسی به x با پارامترهای ϵ و Nmin باشد، آنگاه y نیز در C است.
۲- اگر دو نقطه x و y در C باشند آنگاه این نقاط براساس پارامترهای ϵ و Nmin نقاط متصل محسوب شوند.
به این ترتیب خوشهها شکل گرفته و براساس میزان تراکمشان تشکیل میشوند. نویز یا نوفه (Noise) نیز نقاطی خواهند بود که در هیچ خوشهای جای نگیرند. برای روشن شدن این تعریفها به تصویر 5 توجه کنید.
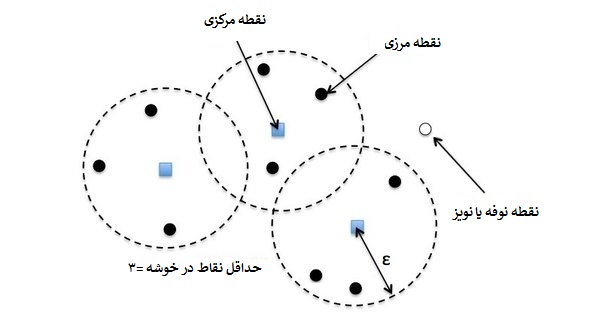
تصویر ۵- نقاط مرکزی، مرزی، نوفه (نویز)
نکته: با توجه به تعریف خوشه، مشخص است که اندازه هر خوشه از Nmin بیشتر است.
مراحل خوشهبندی برمبنای چگالی به این ترتیب است که ابتدا یک نقطه را به صورت اختیاری انتخاب کرده و نقاط قابل دسترس برای آن پیدا میشود. اگر x یک نقطه مرکزی باشد (نقطهای که درون خوشه قرار داشته باشد)، خوشه را تشکیل میدهد ولی اگر x نقطهای مرزی باشد (نقطهای که در لبههای خوشه قرار داشته باشد) آنگاه هیچ نقطه قابل دسترسی برای x وجود نخواهد داشت و الگوریتم از نقطهای دیگری ادامه پیدا میکند.
در مراحل خوشهبندی ممکن است دو خوشه که به یکدیگر نزدیک باشند، ادغام شوند. فاصله بین دو خوشه برحسب حداقل فاصله بین اعضای دو خوشه (پیوند تکی) سنجیده میشود.
نکته: انتخاب مقدار برای پارامترهای ϵ و Nmin مسئله مهمی است که براساس نظر محقق باید به الگوریتم داده شوند. ترسیم نمودار دادهها در انتخاب این پارامترها میتواند موثر باشد. هرچه دادهها در دستههای متراکمتر دیده شوند بهتر است مقدار ϵϵ را کوچک در نظر گرفت و اگر لازم است که تعداد خوشهها کم باشند بهتر است مقدار Nmin را بزرگ انتخاب کرد.
خوشهبندی برمبنای مدل (Model-Based Clustering)
در روشهای پیشین، فرضیاتی مبنی بر وجود یک توزیع آماری برای دادهها وجود نداشت. در روش «خوشهبندی برمبنای مدل» (Model-Based Clustering) یک توزیع آماری برای دادهها فرض میشود. هدف در اجرای خوشهبندی برمبنای مدل، برآورد پارامترهای توزیع آماری به همراه متغیر پنهانی است که به عنوان برچسب خوشهها در مدل معرفی شده.
با توجه به تعداد خوشههایی که در نظر گرفته شده است، مثلا k، تابع درستنمایی را برای پیدا کردن خوشهها به صورت زیر مینویسند:
LM(Θ1,Θ2,Θ3,…,Θk;t1,t2,…,tk)=n∏i=1k∑j=1tjfj(xi,Θj)
در رابطه بالا tj بیانگر احتمال تعلق نقطه به خوشه jام و fj نیز توزیع آمیخته با پارامترهای Θj است.
در اکثر مواقع برای دادهها توزیع نرمال آمیخته در نظر گرفته میشود. در چنین حالتی توزیع آمیخته را به فرمی مینویسند که درصد آمیختگی (درصدی از دادهها که متعلق به هر توزیع هستند) نیز به عنوان پارامتر در مدل حضور دارد.
f(x)=k∑j=1pjΦ(X;μj,Σi)
در رابطه بالا Φ توزیع نرمال با پارامترهای μj و Σj برای توزیع jام هستند و pj نیز درصد آمیختگی برای توزیع jام محسوب میشود. در تصویر 6 یک نمونه از توزیع آمیخته نرمال دو متغیره نمایش داده شده است.
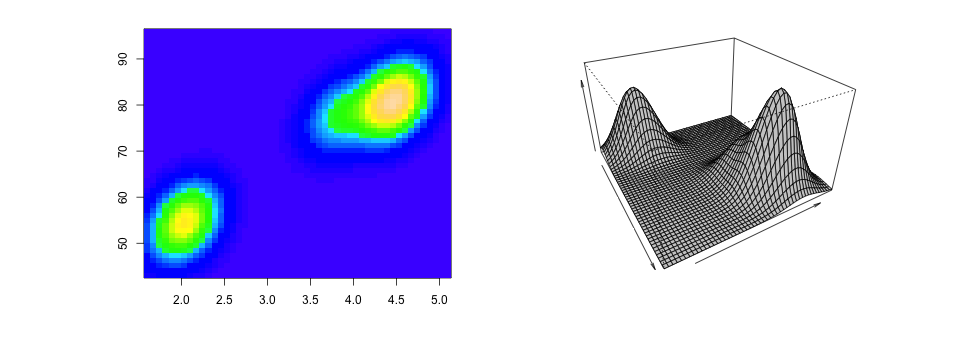
تصویر ۶- توزیع آمیخته نرمال دو متغیره
انتخابهای مختلفی برای ماتریس واریانس-کوواریانس یا Σ وجود دارد. یکی از این حالتها در نظر گرفتن استقلال و یکسان بودن واریانس برای همه توزیعها است. همچنین میتوان واریانس هر توزیع را متفاوت از توزیعهای دیگر در نظر گرفت و بدون شرط استقلال عمل کرد. در حالت اول پیچیدگی مدل و تعداد پارامترهای برآورد شده کم و در حالت دوم پیچیدگی مدل و تعداد پارامترهای برآورده شده زیاد خواهد بود.
برای برآورد پارامترهای چنین مدلی باید از تابع درستنمایی استفاده کرد و به کمک مشتق مقدار حداکثر را برای این تابع بدست آورد. با این کار پارامترهای مدل نیز برآورد میشوند. ولی با توجه به پیچیدگی تابع درستنمایی میتوان از روشهایی ساده و سریعتری نیز کمک گرفت. یکی از این روشها استفاده از الگوریتم EM (مخفف Expectation Maximization) است. در الگوریتم EM که براساس متغیر پنهان عمل میکند، میتوان به حداکثر مقدار تابع درستنمایی همراه با برآورد پارامترها دست یافت.
در چنین حالتی میتوان برچسب تعلق هر مقدار به خوشه را به عنوان متغیر پنهان در نظر گرفت. اگر متغیر پنهان را zij در نظر بگیریم مقداری برابر با ۱ دارد اگر مشاهده iام در خوشه jام باشد و در غیر اینصورت مقدار آن 0 خواهد بود.
منابع
خوشه بندی (Clustering) قسمت 1
خوشه بندی (Clustering) قسمت 2
خوشه بندی (Clustering) قسمت 3
خوشه بندی (Clustering) قسمت 4




