آزمون مربوط به مدل و پارامترهای آن
بعد از انجام مراحل رگرسیون، با استفاده از جدول «تحلیل واریانس» (Analysis of Variance) میتوان صحت مدل ایجاد شده و کارایی آن را سنجید. اساس کار در تحلیل واریانس، تجزیه واریانس متغیر وابسته به دو بخش است، بخشی از تغییرات یا پراکندگی که توسط مدل رگرسیونی قابل نمایش است و بخشی که توسط جمله خطا تعیین میشود. پس میتوان رابطه زیر را بر این اساس نوشت.
SST= SSR+SSE
که هر کدام به صورت زیر تعریف شدهاند:
SST=∑(yi−y¯)2
مقدار SST را میتوان مجموع مربعات تفاضل مشاهدات متغیر وابسته با میانگینشان در نظر گرفت که در حقیقت صورت کسر واریانس متغیر وابسته است. این کمیت میتواند به دو بخش زیر تفکیک شود.
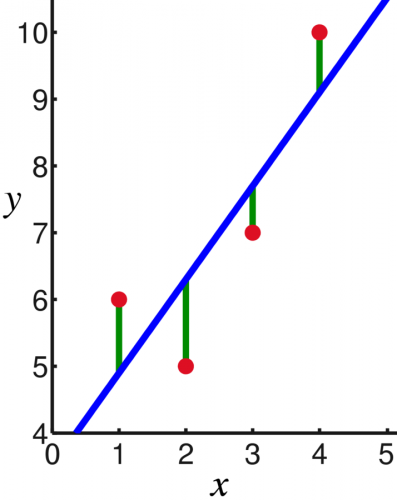
SSE=∑(yi−y^i)2
شایان ذکر است به مقدار SSE مجموع مربعات خطا نیز گفته میشود که در مدل رگرسیون با توجه به کمینه کردن آن پارامترهای مدل بدست آمد. همچنین بخش بعدی با SSR نشان داده میشود:
SSR=∑(y^i−y¯)2
که میتواند به عنوان مجموع مربعات تفاضل مقدارهای پیشبینیشده از میانگینشان نامگذاری شود.
در صورتی که مدل رگرسیون مناسب باشد، انتظار داریم سهم SSR از SST زیاد باشد، بطوری که بیشتر تغییرات متغیر وابسته توسط مدل رگرسیون توصیف شود. برای محاسبه واریانس از روی هر یک از مجموع مربعات کافی است حاصل را بر تعداد اعضایشان تقسیم کنیم. به این ترتیب مقدارهای جدیدی به نام «میانگین مربعات خطا» (MSE)، «میانگین مربعات رگرسیون» (MSR) بوجود میآیند. به جدول زیر که به جدول تحلیل واریانس معروف است، توجه کنید.
| منشاء تغییرات | درجه آزادی | مجموع مربعات | میانگین مربعات | آماره F |
| رگرسیون | k-1 | SSR | MSR=SSRk−1 | F=MSRMSE |
| خطا | n-k | SSE | MSE=SSEn−k | |
| کل | n-1 | SST |
درجه آزادی برای رگرسیون که با k-1 نشان داده شده است، یکی کمتر از تعداد پارامترهای مدل (k) است که در رگرسیون خطی ساده برابر با 1-2=1 خواهد بود زیرا پارامترهای مدل در این حالت β0 و β1 هستند. تعداد مشاهدات نیز با n نشان داده شده است.
اگر محاسبات مربوط به جدول تحلیل واریانس را برای مثال ذکر شده، انجام دهیم نتیجه مطابق جدول زیر خواهد بود.
| منشاء تغییرات | درجه آزادی | مجموع مربعات | میانگین مربعات | آماره F |
| رگرسیون | 1 | 520338.1755 | 520338.1755 | F=MSRMSE=520338.1755239.91=2168.89 |
| خطا | 48 | 11515.7187 | 239.91 | |
| کل | 49 | 531853.8942 |
از آنجایی که نسبت میانگین مربعات دارای توزیع آماری F است با مراجعه به جدول این توزیع متوجه میشویم که مقدار محاسبه شده برای F بزرگتر از مقدار جدول توزیع F با k−1 و n−k درجه آزادی است، پس مدل رگرسیون توانسته است بیشتر تغییرات متغیر وابسته را در خود جای دهد در نتیجه مدل مناسبی توسط روش رگرسیونی ارائه شده.
گاهی از «ضریب تعیین» (Coefficient of Determination) برای نمایش درصدی از تغییرات که توسط مدل رگرسیونی بیان شده، استفاده میشود. ضریب تعیین را با علامت R2 نشان میدهند. هر چه ضریب تعیین بزرگتر باشد، نشاندهنده موفقیت مدل در پیشبینی متغیر وابسته است. در رگرسیون خطی ساده مربع ضریب همبستگی خطی همان ضریب تعیین خواهد بود.
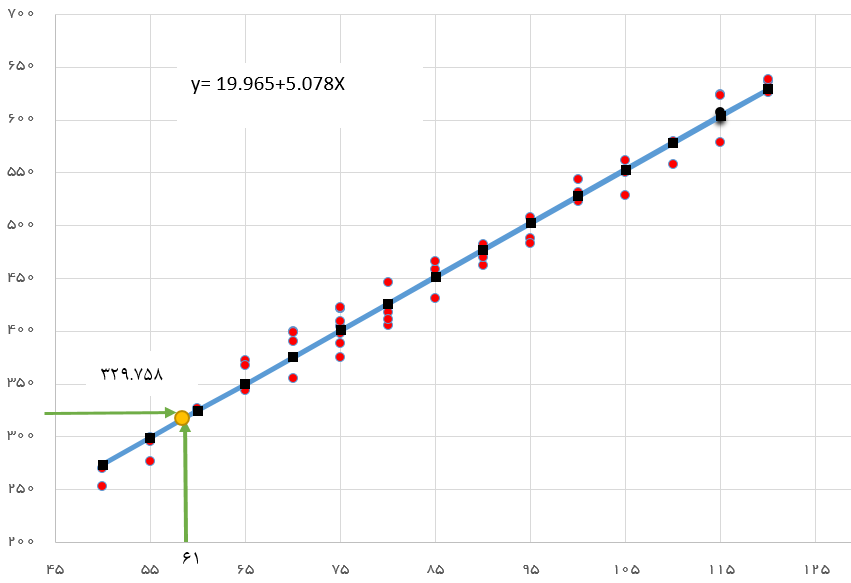
در مثال قبل ضریب تعیین برای مدل رگرسیونی برابر با 0.9783 است. بنابراین به نظر میرسد که مدل رگرسیونی در پیشبینی ارزش خانه برحسب متراژ موفق عمل کرده.
نکاتی در مورد رگرسیون خطی ساده
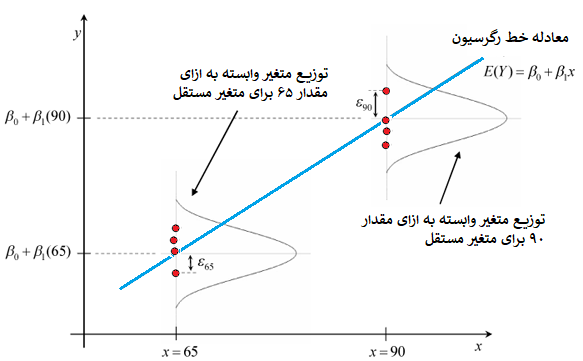
قبل از اتمام کار با مدل رگرسیون نکاتی باید در نظر گرفته شوند. با توجه به تعریف فیشر برای رگرسیون، جمله خطا باید یک متغیر تصادفی با توزیع نرمال باشد. از آنجایی که در انجام محاسبات این فرضیه چک نشده است، باید بعد از محاسبات مربوط به مدل رگرسیون خطی، مقدارهای خطا محاسبه شده و تصادفی بودن و وجود توزیع نرمال برای آنها چک شود.
تصادفی بودن باقیماندهها
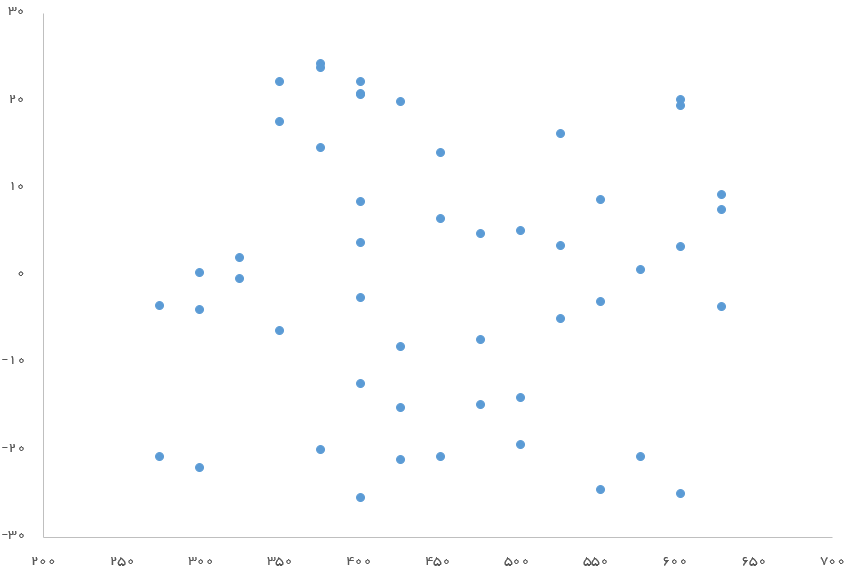
یک راه ساده، برای چک کردن تصادفی بودن مقدارهای خطا میتواند رسم آنها و مقدار پیشبینی شده y^ روی یک نمودار باشد، بطوری که مقدارهای پیشبینی در محور افقی و مقدارهای خطا در محور عمودی ظاهر شوند. اگر در این نمودار، الگوی خاصی مشاهده نشود میتوان رای به تصادفی بودن باقیمانده داد. منظور از الگوی غیرتصادفی، افزایش یا کاهش مقدار خطا با افزایش یا کاهش مقدارهای پیشبینی شده است.
در تصویر زیر این نمودار برای مثال قبلی ترسیم شده است. محور افقی در این نمودار مقدار قیمت خانه و محور عمودی نیز باقیماندهها است. همانطور که دیده میشود، الگوی خاصی وجود ندارد.
تعریف رگرسیون خطی (Linear Regression) قسمت 1
تعریف رگرسیون خطی (Linear Regression) قسمت 2
تعریف رگرسیون خطی (Linear Regression) قسمت 3
تعریف رگرسیون خطی (Linear Regression) قسمت 4
تعریف رگرسیون خطی (Linear Regression) قسمت 5
تعریف رگرسیون خطی (Linear Regression) قسمت 6
تعریف رگرسیون خطی (Linear Regression) قسمت 7