هدف از خوشه بندی چیست؟
همانطور که میدانید از داده کاوی برای کاوش در اطلاعات و کشف دانش استفاده میشود. برای اینکار الگوریتمهای متعددی وجود دارد که هر یک برای هدف خاصی کاربرد دارند
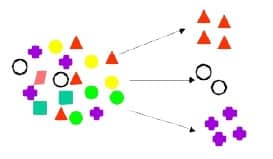
خوشه بندی
کلاسترینگ(Clustering) یا خوشه بندی از جمله الگوریتمهای قطعه بندی به حساب میآید. الگوریتم خوشهبندی اطلاعاتی را که ویژگیهای نزدیک به هم و مشابه دارند را در دستههای جداگانه که به آن خوشه گفته میشود قرار میدهد. به بیان دیگر خوشهبندی همان دستهبندیهای سادهای است که در کارهای روزانه انجام میدهیم. وقتی با یک مجموعه کوچک از صفات روبرو باشیم دسته بندی به سادگی قابل اجرا است، برای مثال در یک مجموعه از خودکارهای آبی، مشکی، قرمز و سبز به راحتی میتوانیم آنها را در ۴ دسته قرار دهیم اما اگر در همین مجموعه ویژگیهای دیگری مثل سایز، شرکت سازنده، وزن، قیمت و… مطرح باشد کار کمی پیچیده میشود. حال فرض کنید در یک مجموعه متشکل از هزاران رکورد و صدها ویژگی قصد دسته بندی دارید، چگونه باید این کار را انجام دهید؟!
بخش بندی دادهها به گروهها یا خوشههای معنادار به طوری که محتویات هر خوشه ویژگیهای مشابه و در عین حال نسبت به اشیاء دیگر در سایر خوشهها غیر مشابه باشند را خوشهبندی میگویند. از این الگوریتم در مجموعه دادههای بزرگ و در مواردی که تعداد ویژگیهای داده زیاد باشد استفاده میشود.
هدف خوشه بندی (Clustering) یافتن خوشه های مشابه از اشیاء در بین نمونه های ورودی می باشد اما چگونه می توان گفت که یک خوشه بندی مناسب است و دیگری مناسب نیست؟ در حقیقت سوال اصلی این است که کدام روش خوشه بندی برای هر مجموعه داده ای مناسب خواهد بود؟ می توان نشان داد که هیچ معیار مطلقی برای بهترین خوشه بندی وجود ندارد بلکه این بستگی به مساله و نظر کاربر دارد که باید تصمیم بگیرد که آیا نمونه ها بدرستی خوشه بندی شده اند یا خیر؟ با این حال معیار های مختلفی برای خوب بودن یک خوشه بندی ارائه شده است که می تواند کاربر را برای رسیدن به یک خوشه بندی مناسب راهنمایی کند که در بخشهای بعدی چند نمونه از این معیارها آورده شده است. یکی از مسایل مهم در خوشه بندی انتخاب تعداد خوشه ها می باشد. در بعضی از الگوریتم ها تعداد خوشه ها از قبل مشخص شده است و در بعضی دیگر خود الگوریتم تصمیم می گیرد که داده ها به چند خوشه تقسیم شوند.
خوشه بندی داده ها
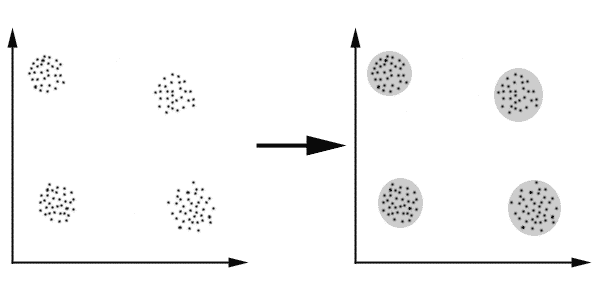
خوشه بندی یا Clustering یکی از شاخه های یادگیری بدون نظارت (Unsupervised) می باشد و فرآیند خود کاری است که در طی آن، نمونه ها به دسته هایی که اعضای آن مشابه یکدیگر می باشند تقسیم می شوند که به این دسته ها خوشه (Cluster) گفته می شود. بنابراین خوشه مجموعه ای از اشیاء می باشد که در آن اشیاء با یکدیگر مشابه بوده و با اشیاء موجود در خوشه های دیگر غیر مشابه می باشند. برای مشابه بودن می توان معیارهای مختلفی را در نظر گرفت مثلا می توان معیار فاصله را برای خوشه بندی مورد استفاده قرار داد و اشیائی را که به یکدیگر نزدیکتر هستند را بعنوان یک خوشه در نظر گرفت که به این نوع خوشه بندی، خوشه بندی مبتنی بر فاصله نیز گفته می شود. بعنوان مثال در شکل ۱ نمونه های ورودی در سمت چپ به چهار خوشه مشابه شکل سمت راست تقسیم می شوند. در این مثال هر یک از نمونه های ورودی به یکی از خوشه ها تعلق دارد و نمونه ای وجود ندارد که متعلق به بیش از یک خوشه باشد.
بعنوان یک مثال دیگر شکل ۲ را در نظر بگیرید در این شکل هر یک از دایره های کوچک یک وسیله نقلیه (شیء) را نشان می دهد که با ویژگی های وزن و حداکثر سرعت مشخص شده اند. هر یک از بیضی ها یک خوشه می باشد و عبارت کنار هر بیضی برچسب آن خوشه را نشان می دهد. کل دستگاه مختصات که نمونه ها در آن نشان داده شده اند را فضای ویژگی می گویند.
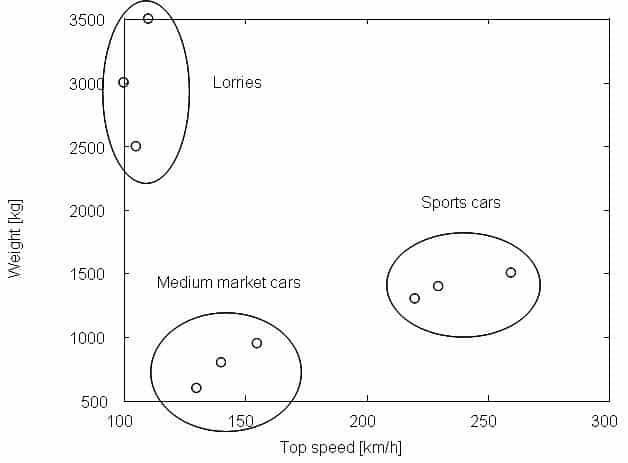
همانطور که در شکل می بینید وسایل نقلیه به سه خوشه تقسیم شده اند. برای هر یک از این خوشه ها می توان یک نماینده در نظر گرفت مثلا می توان میانگین وسایل نقلیه باری را محاسبه کرد و بعنوان نماینده خوشه وسایل نقلیه باری معرفی نمود. در واقع الگوریتمهای خوشه بندی اغلب بدین گونه اند که یک سری نماینده اولیه برای نمونه های ورودی در نظر گرفته می شود و سپس از روی میزان تشابه نمونه ها با این نماینده های مشخص می شود که نمونه به کدام خوشه تعلق دارد و بعد از این مرحله نماینده های جدید برای هر خوشه محاسبه می شود و دوباره نمونه ها با این نماینده ها مقایسه می شوند تا مشخص شود که به کدام خوشه تعلق دارند و این کار آنقدر تکرار می شود تا زمانیکه نماینده های خوشه ها تغییری نکنند.
خوشه بندی با طبقه بندی (Classification) متفاوت است. در طبقه بندی نمونه های ورودی برچسب گذاری شده اند ولی در خوشه بندی نمونه های ورودی دارای بر چسب اولیه نمی باشند و در واقع با استفاده از روشهای خوشه بندی است که داده های مشابه مشخص و بطور ضمنی برچسب گذاری می شوند. در واقع می توان قبل از عملیات طبقه بندی داده ها یک خوشه بندی روی نمونه ها انجام داد و سپس مراکز خوشه های حاصل را محاسبه کرد و یک بر چسب به مراکز خوشه ها نسبت داد و سپس عملیات طبقه بندی را برای نمونه های ورودی جدید انجام داد.
آشنایی با خوشهبندی (Clustering) و شیوههای مختلف آن
الگوریتمهای متنوع و زیادی برای انجام عملیات خوشهبندی در دادهکاوی به کار میرود. آگاهی از الگوریتمهای خوشهبندی و آشنایی با نحوه اجرای آنها کمک میکند تا مناسبترین روش را برای خوشهبندی دادههای خود به کار ببرید.
«تحلیل خوشهبندی» (Cluster Analysis) نیز مانند «تحلیل طبقهبندی» (Classification Analysis) در «یادگیری ماشین» (Machine Learning) به کار میرود. هر چند که تحلیل طبقهبندی یک روش «با ناظر» (Supervised) محسوب شده ولی خوشهبندی روشی «بدون ناظر» (Unsupervised) است.
در این متن، ابتدا خوشهبندی را تعریف میکنیم و سپس به معرفی گونههای مختلف الگوریتمهای خوشهبندی میپردازیم.
خوشهبندی (Clustering)
«تحلیل خوشهبندی» (Cluster Analysis) یا بطور خلاصه خوشهبندی، فرآیندی است که به کمک آن میتوان مجموعهای از اشیاء را به گروههای مجزا افراز کرد. هر افراز یک خوشه نامیده میشود. اعضاء هر خوشه با توجه به ویژگیهایی که دارند به یکدیگر بسیار شبیه هستند و در عوض میزان شباهت بین خوشهها کمترین مقدار است. در چنین حالتی هدف از خوشهبندی، نسبت دادن برچسبهایی به اشیاء است که نشان دهنده عضویت هر شیء به خوشه است.
به این ترتیب تفاوت اصلی که بین تحلیل خوشهبندی و «تحلیل طبقهبندی» (Classification Analysis) وجود دارد، نداشتن برچسبهای اولیه برای مشاهدات است. در نتیجه براساس ویژگیهای مشترک و روشهای اندازهگیری فاصله یا شباهت بین اشیاء، باید برچسبهایی بطور خودکار نسبت داده شوند. در حالیکه در طبقهبندی برچسبهای اولیه موجود است و باید با استفاده از الگویهای پیشبینی قادر به برچسب گذاری برای مشاهدات جدید باشیم.
با توجه به روشهای مختلف اندازهگیری شباهت یا الگوریتمهای تشکیل خوشه، ممکن است نتایج خوشهبندی برای مجموعه داده ثابت متفاوت باشند. شایان ذکر است که تکنیکهای خوشهبندی در علوم مختلف مانند، گیاهشناسی، هوش مصنوعی، تشخیص الگوهای مالی و … کاربرد دارند.
روشهای خوشهبندی
اگر چه بیشتر الگوریتمها یا روشهای خوشهبندی مبنای یکسانی دارند ولی تفاوتهایی در شیوه اندازهگیری شباهت یا فاصله و همچنین انتخاب برچسب برای اشیاء هر خوشه در این روشها وجود دارد.

هر چند ممکن است امکان دستهبندی روشها و الگوریتمها خوشهبندی به راحتی میسر نباشد، ولی طبقهبندی کردن آنها درک صحیحی از روش خوشهبندی بکار گرفته شده در الگوریتمها به ما میدهد. معمولا ۴ گروه اصلی برای الگوریتمهای خوشهبندی وجود دارد. الگوریتمهای خوشهبندی تفکیکی، الگوریتمهای خوشهبندی سلسله مراتبی، الگوریتمهای خوشهبندی برمبنای چگالی و الگوریتمهای خوشهبندی برمبنای مدل. در ادامه به معرفی هر یک از این گروهها میپردازیم.
خوشهبندی تفکیکی (Partitioning Clustering)
در این روش، براساس n مشاهده و k گروه، عملیات خوشهبندی انجام میشود. به این ترتیب تعداد خوشهها یا گروهها از قبل در این الگوریتم مشخص است. با طی مراحل خوشهبندی تفکیکی، هر شیء فقط و فقط به یک خوشه تعلق خواهد داشت و هیچ خوشهای بدون عضو باقی نمیماند. اگر lij نشانگر وضعیت تعلق xi به خوشه cj باشد تنها مقدارهای ۰ یا ۱ را میپذیرد. در این حالت مینویسند:
lij=1 , xi∈cj or lij=0 , xi∉cj
هر چند این قانونها زمانی که از روش «خوشهبندی فازی» (Fuzzy Clustering) استفاده میشود، تغییر کرده و برای نشان دادن تعلق هر شئی به هر خوشه از درجه عضویت استفاده میشود. به این ترتیب میزان عضویت xi به خوشه cj مقداری بین ۰ و ۱ است. در این حالت مینویسند:
lij∈[0,1]
معمولا الگوریتمهای تفکیکی بر مبنای بهینهسازی یک تابع هدف عمل میکنند. این کار براساس تکرار مراحلی از الگوریتمهای بهینهسازی انجام میشود. در نتیجه الگوریتمهای مختلفی بر این مبنا ایجاد شدهاند. برای مثال الگوریتم «k-میانگین» (K-means) با تعیین تابع هدف براساس میانگین فاصله اعضای هر خوشه نسبت به میانگینشان، عمل میکند و به شکلی اشیاء را در خوشهها قرار میدهد تا میانگین مجموع مربعات فاصلهها در خوشهها، کمترین مقدار را داشته باشد. اگر مشاهدات را با x نشان دهیم، تابع هدف الگوریتم «k-میانگین» را میتوان به صورت زیر نوشت:
E=k∑j=1∑x∈cjdist(x,μcj)
که در آن μcj میانگین خوشه cj و dist نیز مربع فاصله اقلیدسی است.
به این ترتیب با استفاده از روشهای مختلف بهینهسازی میتوان به جواب مناسب برای خوشهبندی تفکیکی رسید. ولی از آنجایی که تعداد خوشهها یا مراکز اولیه باید به الگوریتم داده شود، ممکن است با تغییر نقاط اولیه نتایج متفاوتی در خوشهبندی بدست آید. در میان الگوریتمهای خوشهبندی تفکیکی، الگوریتم k-میانگین که توسط «مککوئین» (McQueen) جامعه شناس و ریاضیدان در سال ۱۹۶۵ ابداع شد از محبوبیت خاصی برخوردار است.

نکته: در شیوه خوشهبندی تفکیکی با طی مراحل خوشهبندی، برچسب عضویت اشیاء به هر خوشه براساس خوشههای جدیدی که ایجاد میشوند قابل تغییر است. به این ترتیب میتوان گفت که الگوریتمهای خوشهبندی تفکیکی جزء الگوریتمهای «یادگیری ماشین بدون ناظر» (Unsupervised Machine Learning) محسوب میشوند.
در تصویر ۱ نتایج ایجاد ۴ خوشه روی دادههای دو بعدی به کمک الگوریتم k-میانگین نمایش داده شده است. داشتن حالت کروی برای دادهها به ایجاد خوشههای مناسب در الگوریتم k-میانگین کمک میکند.
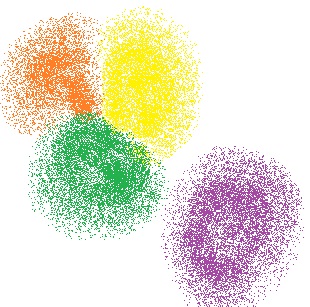
تصویر ۱- خوشهبندی k-میانگین برای دادههای دو بعدی