بایگانی برچسب برای: fishk hknda
آزمونتورینگ
آزمون تورینگ روشی برای سنجش میزان هوشمندی ماشین است. آزمون به این صورت انجام میگیرد که یک شخص به عنوان قاضی، با یک ماشین و یک انسان به گفتگو مینشیند، و سعی در تشخیص ماشین از انسان دارد. در صورتی که ماشین بتواند قاضی را به گونهای بفریبد که در قضاوت خود دچار اشتباه شود، توانسته است آزمون را با موفقیت پشت سر بگذارد.
برای اینکه تمرکز آزمون بر روی هوشمندی ماشین باشد، و نه توانایی آن در تقلید صدای انسان، مکالمه تنها از طریق متن و صفحه کلید و نمایشگر کامپیوتر صورت میگیرد.
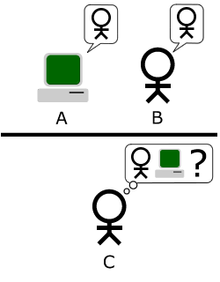
آزمون استاندارد تورینگ، که در آن بازیکن C به عنوان قاضی سعی دارد تشخصی دهد کدام یک از A یا B انسان است.
آزمون تورینگ
تست تورینگ یک تست از توانایی ماشین است برای نمایش دادن رفتاری هوشمندانه شبیه به انسان. آزمون تورینگ در سال ۱۹۵۰ توسط آلن تورینگ،ریاضیدان انگلیسی مطرح گردید. از نظر تورینگ، پرسش «آیا ماشینها میتوانند تفکر کنند» بیمعنیتر از آن بود که بتوان پاسخ روشنی به آن داد. چرا که نمیتوان تعریف مشخصی برای تفکر ارائه داد. بنابراین تورینگ پرسش را به این گونه مطرح نمود: آیا میتوان ماشینی ساخت که آزمون تورینگ را پشت سر بگذارد؟
هم اکنون دو نسخهٔ مختلف از این آزمون وجود دارد: آزمون استاندارد تورینگ، و آزمون تقلید.
آزمون تقلید
در این آزمون، دو شخص با جنسیتهای متفاوت، از طریق یادداشت با شخص سومی که قاضی است گفتگو میکنند. قاضی این دو بازیکن را نمیبیند، و با پرسش و پاسخ سعی دارد تشخیص دهد کدام یک مرد و کدام یک زن هستند. نقش بازیکن اول این است که قاضی را به نحوی بفریبد که در تشخیص جنست آن دو اشتباه کند.
تورینگ نقش بازیکن فریبکار را به ماشین سپرد، و در صورتی که این ماشین موفق شود که قاضی را بفریبد، از آزمون موفق بیرون آمده است و میتوان آن را ماشین هوشمند نامید.
مشکلات آزمون تورینگ
آزمون تورینگ فرض میکند که انسانها میتوانند با مقایسهٔ میان رفتار ماشین و انسان، پی به میزان هوشمند بودن آن ببرند. به دلیل این فرض، و تعدادی پیش فرضهای دیگر، دانشمندان حوزهٔهوش مصنوعی صحت آزمون تورینگ را مورد تردید قرار دادند.
اولین نکتهای که مطرح میگردد این است که تعدادی از رفتارهای انسان هوشمندانه نیستند. به عنوان مثال، توانایی توهین به دیگران، یا اشتباههای تایپی مکرر هنگام نوشتن با صفحه کلید.
نکتهٔ دومی که به آن اشاره میگردد این است که بعضی از رفتارهای هوشمندانه، انسانی نیستند. به عنوان مثال، کامپیوترها بسیار سریعتر از انسان محاسبه میکنند.
تورینگ پیشنهاد داده است که ماشین میتواند به صورت اتفاقی در خروجی خود اشتباهاتی را وارد کند، یا مدت زمان زیادی را صرف محاسبات کرده و در انتها پاسخی اشتباه دهد که قاضی را بفریبد، تا «بازیکن» بهتری باشد.
آزمون تورینگ؛ غایتی که در گنجه خاک میخورد
آزمون تورینگ چیست و چه کاربردی دارد؟

بیش از 60 سال پیش تورینگ در یکی از مشهورترین کارهایش آزمونی را به جامعه هوش مصنوعی پیشنهاد کرد تا به معیاری برای ساخت یک ماشین هوشمند تبدیل شود. تورینگ اعتقاد داشت که اگر ماشینی بتواند خود را از انسان غیرقابل تميز کند، بيشك میتوان برچسب هوشمندبودن را بر آن زد و البته وی بسيار خوشبین بود که تا پیش از پایان قرن بیستم، شاهد تولد چنین ماشینی خواهیم بود. اگرچه ميتوان گفت كه در طول سه دهه بعدی متخصصان از دستیابی به چنین هدفی تقریباً ناامید شدند، امروز دنیای هوش مصنوعی اعتقاد دارد که شاید دیگر گذراندن آزمون تورینگ هدف مناسبی برای دنبال کردن نباشد. امروزه بسیاری اعتقاد دارند که در اختیار داشتن یک راهبرد کاربردی و پذیرفتن تفاوتهای رفتاری کامپیوترها نسبت به انسانها، میتواند در موارد بسیاری، مفیدتر از تلاش برای ساخت ماشینی انساننما باشد.
آزمون تورینگ چیست؟
در سال 1950 آلنتورینگ در مقالهای با عنوان «ساز و کار رایانش و هوشمندی» برای نخستینبار آزمون تورینگ را به جهانیان معرفی کرد. به پیشنهاد تورینگ، این آزمون که میتوان به آسانی آن را اجرا کرد، مشخص میکند که آیا یک ماشین به حد کافی هوشمند است یا خیر. در نسخه ابتدایی تعریف شده توسط تورینگ یک انسان در نقش داور از طریق ترمینالی متنی با یک مجموعه از شرکتکنندگان که ترکیبی از انسانها و ماشینها هستند، ارتباط برقرار میکند. در صورتی که داور انسانی نتواند شرکتکننده ماشین را از شرکتکنندگان انسانی تشخیص دهد، آن ماشین از نظر تورینگ شایسته صفت هوشمند است.
توجه داشته باشید که لزومی ندارد ماشین به سؤالات مطرح شده توسط داور پاسخ صحیح دهد، بلکه تنها تقلید رفتار انسانی است که هوشمند بودن یا نبودن ماشین را مشخص میکند.
تورینگ مقاله مورد نظر را این گونه آغاز میکند: «من پیشنهاد میکنم که این پرسش را مد نظر قرار دهید: آیا ماشینها میتوانند فکر کنند؟» سپس از آنجا که تعریف دقیق تفکر بسیار مشکل است، تورینگ پیشنهاد میکند که این پرسش به گونه دیگری مطرح شود: «آیا قابل تصور است که کامپیوترهای دیجیتال بتوانند در بازی تقلید، عملکرد مناسبی از خود ارائه دهند؟» پرسشی که به گمان تورینگ دلیلی برای منفی بودن پاسخ آن وجود نداشت. در مورد شرایط دقیق آزمون تورینگ بحثهای زیادی مطرح است که باعث شده نسخههای مختلفی از این آزمون به وجود آید.
نکته اول شیوه انجام این آزمایش است که تقریباً همه اعتقاد دارند که نمیتوان تنها به یک آزمایش اتکا کرد و باید درصد موفقیت در تعداد زیادی آزمایش محاسبه شود. نکته بعدی در میزان اطلاعات پیش از آزمایش داور است. به عنوان مثال، برخی پیشنهاد کردهاند که لزومی ندارد داور بداند یکی از افراد درگیر در آزمایش کامپیوتر است و برخی دیگر اعتقاد دارند که مشکلی با دانستن این موضوع وجود ندارد چرا که در واقع آزمون تورینگ برای توانایی فریب دادن داور طراحی نشده بلکه صرفاً سنجش میزان توانایی ماشین در شبیهسازی رفتارهای انسانی مدنظر است.
در اینجا باید به نکته مهمی در رابطه با آزمون تورینگ اشاره کرد. تا قبل از ارائه آزمون تورینگ، دانشمندان فعال در زمینه علوم شناختی و هوش مصنوعی مشکلات فراوانی را برای تعریف دقیق هوشمندی و مشخصکردن اینکه چه زمانی میتوان یک فرآیند را تفکر نامید، تجربه میکردند. تورینگ که یک ریاضیدان خبره بود با ارائه آزمون تورینگ در واقع سعی داشت تا از دنیای تعاریف نادقیقی که هضم آن برای حوزههای دقیقی مانند علوم کامپیوتر مشکل بود، فاصله گرفته و معیاری مشخص برای میزان هوشمندی ماشینها ارائه کند. دانیل کلمنت دنت، دانشمند علوم شناختی و فیلسوف امریکایی در این رابطه میگوید: «هنگامي كه تورینگ، آزمون مورد نظر را برای هوشمندی ماشینها ارائه کرد، هدف وی بنا کردن پلتفرمی برای انجام تحقیقات علمی نبود بلکه وی آزمون تورینگ را به عنوان یک ختمالکلام برای بحثهای مورد نظر در آن زمان ارائه کرد.
در واقع، کلام اصلی تورینگ در مقابل کسانی که اصولاً تعریف هوشمندی برای ماشین را غیرقابل قبول میدانستند، این بود که: هر ماشینی که بتواند این آزمون را به صورت عادلانهای پشت سر بگذارد، قطعاً یک موجود هوشمند است و دیگر بحثی در این زمینه باقی نمیماند.» دنت سپس به بحث در مورد هوشمندی در قرن 17 توسط دکارت اشاره میکند و متذکر میشود که وی نیز روشی مشابه برای تعریف هوشمندی ارائه داده بود که براساس برقرارکردن یک مکالمه با موجود مورد نظر بنا شده بود. در نتیجه تورینگ ادعا نمیکند ماشینی که نتواند با ما به شکل درستی مکالمه برقرار کند هوشمند نیست، بلکه صرفاً ادعا دارد اگر ماشینی این توانایی را داشته باشد شکی در هوشمندی آن باقی نمیماند.
تلاشهای نیمه تمام
از اواسط دهه 1960 بسیاری از افراد فعال در زمینه هوش مصنوعی سعی کردند تا به ساخت ماشینهایی روی بیاورند که با در اختیار داشتن توانایی درک زبان انسان و استفاده از اطلاعات گنجانده شده در آنها، بتوانند به گذراندن آزمون تورینگ نزدیک شوند. جوزف وایزنباوم در 1966 برنامهای کامپیوتری با نام الیزا را معرفی کرد که یکی از نخستین نمونههای پردازش زبان طبیعی بود. این برنامه قادر بود تا یک مکالمه را با در اختیار داشتن کمترین اطلاعات ممکن نسبت به موضوع مورد بحث پیش ببرد. یکی از مشهورترین موارد پیادهسازی شده در الیزا، شبیهسازی با عنوان «دکتر» بود که سعی داشت تا نقش یک روانکاو را برای ماشین شبیهسازی کند.
پاسخهاي الیزا عموماً بسیار کلی بودند و برای تولید آنها از تکنیکهای موجود تطابق الگو در آن زمان استفاده میشد. وایزنباوم در 1976 در مقالهای با عنوان «قدرت کامپیوتر و استدلال انسان» اشاره کرد که بسیاری از افرادی که با اسکریپت «دکتر» کار کردهاند به زودی ارتباط عاطفی قوی با آن برقرار کردند، حتی اصرار داشتند که در هنگام کارکردن با برنامه در اتاق تنها گذاشته شوند. خود وایزنباوم اشاره کرده است که در طول سالهای استفاده از الیزا مواردی بوده که کاربران در تشخیص انسان نبودن الیزا با مشکل مواجه شدهاند یا حتی در آن ناکام ماندهاند. به طور کلی این دیدگاه که الیزا توانسته است آزمون تورینگ را پشت سر بگذارد در جامعه علمی هوش مصنوعی چندان طرفدار ندارد اما به طور حتم این قطعه کد نقش زیادی در پیشرفت شبیه ساختن برنامههای کامپیوتری به رفتارهای انسان ایفا کرد.
کنت کولبی در 1972 نمونهای جدیدتر از الیزا را با عنوان «پری» (PARRY) معرفی کرد که در واقع پیادهسازی رفتار یک بیمار شیزوفرنیک پارانویا بود. کمی بعد از معرفی پری، این ماشین در یک آزمایش واقعی قرار داده شد تا قدرت آن در گذراندن آزمون تورینگ مشخص شود. در این آزمایش گروهی از روانکاوان باتجربه ترکیبی از بیماران واقعی و نسخههای برنامه پری را از طریق یک تله پرینتر مورد بررسی قرار دادند. سپس از یک گروه روانکاو دیگر خواسته شد تا با مشاهده ریز مکالمات مشخص کنند که کدام مورد، مکالمه با ماشین و کدام یک مکالمه با انسان بوده است. در نهایت، روانکاوان گروه دوم تنها در 48 درصد موارد توانستند درست حدس بزنند؛ نتيجهاي که تقریباً مشابه سکه انداختن برای تعیین ماشین یا انسان بودن طرف مکالمه است! توسعه برنامههایی مانند الیزا و پری که در دسته کلی چت باتها قرار میگیرند هنوز هم در جای جای دنیا ادامه دارد. چنین برنامههایی که صرفاً قصد شبیهسازی یک مکالمه هوشمند را دارند عموماً از دانش خاصی برخوردار نیستند بلکه سعی میکنند تا با تکنیکهای زبانی و البته الگوریتمهای پیچیده، مکالمه را به شیوهای قابل قبول پیش ببرند؛ مکالمهای که لزوماً خروجی مفیدی برای کاربر ندارد.
چنین برنامههایی هر چند ممکن است در موارد خاصی حتی تا مرز گذراندن آزمون تورینگ نیز پیش روند، اما به دلیل نبود یک دانش ساختاری در درون سیستم، قلمرو بسیار محدودی دارند. تمرکز تحقیقات و نیروی انسانی متخصص حوزه هوش مصنوعی روی ساخت ماشینی که صرفاً بتواند به طریقی آزمون تورینگ را با موفقیت پشت سر گذارد، برای سالهای متمادی منجر به تحقیقاتی این چنینی شد که هر چند کسی در ارزش بسیار زیاد آن شکی ندارد، اما نمیتواند به عنوان بخشی از راهحل یک مسئله دنیای واقعی به کار رود.
آیا این هوشمندی است؟
در بیش از شصت سالی که آزمون تورینگ در حوزه هوش مصنوعی حضور داشته است، انتقادات مختلفی به آن وارد شده که بخش بزرگی از آنها بر این موضوع استوار بودهاند که آیا این آزمون معیار خوبی برای تشخیص هوشمندی یک سیستم است؟
به عنوان مثال، جان سیرل فیلسوف امریکایی در مقالهای با عنوان «ذهنها، مغزها و برنامهها» در سال1980 آزمایشی ذهنی با عنوان «اتاق چینی» را طراحی کرد که به تعریف هوشمندی مورد نظر حوزه هوش مصنوعی حمله میکند.
فرض کنید که شما یک برنامه در اختیار دارید که میتواند طوری رفتار کند که زبان چینی را میفهمد. این برنامه یک ورودی از کاراکترهای چینی را گرفته و براساس آنها خروجی متشکل از کاراکترهای چینی تولید میکند. همین طور فرض کنید که این برنامه آزمون تورینگ را با موفقیت پشت سر بگذارد. حال در اینجا یک پرسش بزرگ به وجود میآید : «آیا این ماشین بهراستي چینی میفهمد یا تنها میتواند فهم زبان چینی را شبیهسازی کند؟» سیرل بیان میکند که اگر وی در اتاقی، مقابل این ماشین قرار بگیرد، میتواند با واردکردن هر ورودی چینی در کامپیوتر و یادداشتکردن خروجی برنامه روی یک تکه کاغذ آزمون تورینگ را با موفقیت پشت سر بگذارد. وی سپس اشاره میکند که فرقی میان نقش ماشین در حالت اول و نقش وی در حالت دوم وجود ندارد و از آنجایی که وی یک کلمه چینی نمیفهمد، در نتیجه ماشین نیز درکی از زبان چینی ندارد. در نهایت وی نتیجه میگیرد که بدون درک شیوه عملکرد کامپیوتر و تنها از روی مشاهده رفتار آن نمیتوان نتیجه گرفت که کاری که ماشین انجام میدهد فکر کردن است.
دیدگاه جان سیرل از طرف دانشمندان علوم شناختی مورد انتقادات فراوانی قرار گرفته است. از جمله این انتقادات میتوان به این نکته اشاره کرد که ممکن است فرد به صورت خاص زبان چینی را نفهمد اما سیستم به صورت یک کل توانایی فهم زبان چینی را دارد و نمیتوان توانایی فهم انسان به عنوان بخشی از این سیستم را از کل جدا کرد. هر چند آزمایش «اتاق چینی» مورد انتقادات فراوانی قرار گرفته و نمیتواند به عنوان یک خطر جدی برای آزمون تورینگ تلقی شود، اما با مشاهده چنین دیدگاههایی کاملاً مشخص میشود که چرا پیادهسازی ایده آزمون تورینگ در دنیای واقعی تا این اندازه مشکل است.
دسته دیگری از انتقادات به این موضوع اشاره دارند که میزان تقلید از رفتارهای انسانی لزوماً معیار خوبی برای هوشمندی نیست. چراکه نه تمام رفتارهای انسانی هوشمندانه است و نه تمام رفتارهای هوشمندانه انسانی است. این که تا چه حد این جمله را قبول دارید، میتواند موضوع خوبی برای یک بحث فلسفی طولانی باشد و البته بعید است به نتیجه مشخصی برسد. به عنوان مثال، ابرکامپیوتر دیپبلو ساخت آیبیام را در نظر بگیرید که در دهه 1990 موفق شد گری کاسپاروف استاد مسلم شطرنج جهان را شکست دهد. دیپ بلو طبیعتاً نمیتواند در مکالمه با انسان همراهی کند اما به خوبی وی (حتی بهتر از او) شطرنج بازی میکند. آیا این ماشین کمتر از الیزا هوشمند است؟ جواب از نظر بسیاری خیر است. اما باز هم باید توجه داشت که تورینگ به هیچ عنوان ادعا نمیکند عدم تقلید از انسان به معنای عدم هوشمندی است.
این که آیا تقلید از رفتار انسان واقعاً نشاندهنده هوشمندی است یا خیر، هنوز مورد بحث و بررسی است. بهعبارتي، هنوز هم تعریف دقیقی برای هوشمندی در اختیار نداریم و همین موضوع باعث میشود تا نتوان در این مورد استدلال چندان قابل قبولی ارائه داد. به هر روی، ما امروز میدانیم که رفتار هوشمندانه و رفتار انسانی ممکن است لزوماً به یک معنی نباشند. همچنین آگاه هستیم که برای گذراندن آزمون تورینگ، آشنایی ماشین به جزئیات و قوانین زبان انسانی به همان اندازه اهمیت دارد که دانش و استدلال گنجانده شده در آن ارزشمند است. خبر نهچندان امیدوار کننده، این است که با وجود پیشرفتهای فراوان حوزه یادگیری زبان و زبانشناسی، فرآیند دقیقی که باعث میشود انسانها در یادگیری یک زبان به چنین درجهای از تبحر دستیابند، به طور دقیق برای دانشمندان مشخص نیست. حتی از تمام این موارد که بگذریم، مسئلهای بسیار مهمتر مطرح میشود و آن این است که آیا اصولاً گذراندن یا نگذراندن آزمون تورینگ تا این حد مسئله مهمی است؟ دنیای نوین هوش مصنوعی اعتقاد دارد که پاسخ این پرسش منفی است. در ادامه مقاله ميكوشيم تا تصویری از وضعیت آزمون تورینگ در دنیای امروز ترسیم کنيم.
وقتی انسان آنقدرها هم جذاب نیست
استیون لوی در سال 2010 در مقالهای با عنوان «انقلاب هوش مصنوعی آغاز شده است» نگاه متفاوتی را نسبت به دنیای هوش مصنوعی در روزگار نوین ارائه میدهد. نگاهی که البته لوی با بسیاری از صاحبنظران دیگر به اشتراک میگذارد. وی در ابتدا به سیستم اداره انبار Diapers.com که به صورت کامل توسط روباتها انجام میشود اشاره مختصری کرده و متذکر میشود که اداره این سیستم با سازماندهی فعلی برای انسانها تقریباً غیرممکن است. سپس ادامه میدهد «روباتهای به کار گرفته شده در این انبار خیلی باهوش نیستند. آنها توانایی حتی نزدیک به هوش انسانی را نیز در اختیار نداشته و بهطور قطعی نمیتوانند آزمون تورینگ را با موفقیت پشت سر بگذارند. اما آنها نمایانگر نگاه جدیدی در حوزه هوش مصنوعی هستند. هوش مصنوعی امروز تلاش نمیکند تا مغز را بازسازی کند. بلکه در مقابل این حوزه، از یادگیری ماشین، دیتاستهای عظیم، حسگرهاي پیشرفته و الگوریتمهای پیچیده استفاده کرده تا کارهای گسسته را به نحو احسن انجام دهد. مثالهای این امر در همه حوزهها مشهود است. ماشینهای گوگل پرسوجوهای پیچیده انسانی را تفسیر میکنند. شرکتهای کارت اعتباری از هوش مصنوعی برای تشخیص کلاهبرداری سود میبرند. نت فلیکس با استفاده از آن، سعی میکند ذائقه مشترکانش را حدس زده و فیلمهای مورد علاقهشان را به آنان پیشنهاد کند و سرانجام، سیستم مالی از هوش مصنوعی برای مدیریت میلیاردها داد و ستد استفاده میکند (که تنها گهگاهی از هم میپاشد!).»
لوی سپس با اشاره به زمستان هوش مصنوعی که باعث متوقف شدن مقطعی پیشرفتها در حوزه هوش مصنوعی و «مرگ هدف اولیه» شد، میگوید: «اما این باعث شد تا یک هدف جدید متولد شود؛ ماشینها ساخته شدهاند تا کارهایی را انجام دهند که انسانها نمیتوانند هیچ گاه از عهده آنها برآیند.» همانطور که لوی بهدرستی اشاره میکند ساخت سیستمهای منطقی که بتوانند شیوه تفکر انسان را بهطور کامل شبیهسازی کرده و با استفاده از اصول منطقی ساده یک ماشین هوشمند را تشکیلدهند، کاری است که محققان در خلال دهههای 1960 و 1970 انجام آن را خیلی سختتر از آن چیزی که تصور میشد، یافتند. در مقابل، تحقیقات جدیدتر حوزه هوش مصنوعی بخش دیگری از حقیقت را نمایان ساخت. منطق کارکرد کامپیوترها ممکن است با آنچه انسانها از تفکر منطقی انتظار دارند کاملاً متفاوت باشد. یکی از حوزههایی که مانور اصلی خود را بر این حقیقت استوار کرده، الگوریتمهای احتمالاتی هستند.
با پیشرفت قدرت محاسباتی کامپیوترها، دانشمندان بیش از هر زمان دیگری، نسبت به الگوریتمهایی که المانهای تصادفی را شامل میشوند، علاقه نشان میدهند. ترکیب این الگوریتمها با قدرت محاسباتی امروز عموماً پاسخهایی «به حد کافی مناسب» را برای مسئلههای پیچیدهای که حل آنها دور از دسترس بود، ارائه میدهد. به عنوان مثال، الگوریتمهای ژنتیک را در نظر بگیرید. در چارچوب این الگوریتمها ماشین با یک ساختار منطقی گامبهگام و استدلالهای پیچیده مواجه نمیشود بلکه صرفاً یک سیستم بازخورد از تعدادی جوابها را در اختیار گرفته و سعی میکند تا رفتار درست را براساس ورودی انسانی پیدا کند. چنین روشهای استدلالی از عهده انسانها خارج است. ما برای خروج از یک وضعیت نامطلوب نمیتوانیم میلیونها راه را آزمون کنیم بلکه عموماً سعی میکنیم تا با استفاده رشتهای از تفکرات پیچیده، راه خروج را به صورت مکاشفهای (Heuristic) پیدا کنیم. در مقابل ماشینها میتوانند منطق دیگری را دنبال کنند و آن انجام آزمون و خطا در مقیاس میلیونی است. شاید تصور بسیاری بر این باشد که راهبرد اول نسبت به راهبرد دوم از ارزش بیشتری برخوردار است. از جهاتي نميتوان به این دیدگاه اعتراضی داشت، اما بهنظر ميرسد تا زمانی که یک راهبرد میتواند پاسخ مناسبی را در مدت زمانی کوتاه در اختیار ما قرار دهد، انتقاد از آن چندان محلی از اعراب ندارد.
راسل و نوریگ نویسندگان مشهورترین کتاب درسی در زمینه هوش مصنوعی نیز دیدگاهی به نسبت نزدیک به دیدگاه لوی را در این زمینه ارائه میکنند. آنها اعتقاد دارند که شبیهسازی واقعي هوش انسان مسئلهای بسیار مشکل است که نیازی نیست به عنوان هدف اولیه تحقیقات هوش مصنوعی در نظر گرفته شود. هرچند در بسیاری از فناوریهای امروز تطبیق فناوری با رفتارها و عادتهای انسانی به عنوان یکی از برگهای برنده فناوری مورد نظر به شمار میرود (نگاهی به آیفون و آیپد بیاندازید) اما لزوماً راه ساخت یک ماشین هوشمند، از شبیهسازی رفتار انسانی نمیگذرد (همانطور که بارها در طول مقاله ذکر شد، تورینگ خود نیز چنین عقیدهای نداشت). راسل و نوریگ برای این موضوع آنالوژی جالبی ارائه میدهند: «هواپیماها با توجه به میزان کیفیت پروازشان آزمایش میشوند و نه شبیه بودنشان به پرندگان. متون هوافضا هدف حوزهشان را “ساخت ماشینهایی که آن قدر شبیه کبوترها پرواز کنند که بتوانند کبوترهای دیگر را فریب دهند” بیان نمیکنند.»
مراحل ایجاد یک سیستم خبره
ایجاد یک سیستم خبره تا حد زیادی بستگی به تأمین منابع دارد. ولی مانند هر پروژه دیگری، ایجاد سیستم بستگی به این دارد که فرآیند ایجاد سیستم چگونه سازماندهی و مدیریت شود.
مدیریت پروژه
انتظار می رود مدیریت پروژه، موارد ذیل را تأمین نماید. در حقیقت مدیریت پروژه، خود یکی از موضوعات مورد نظر طراحات سیستمها خبره بوده است.
| مدیریت فعالیتها | |
| برنامه ریزی | – تعریف فعالیتها– تعیین اولویت فعالیتها
– احتیاجات منابع – اهداف شاخص میانی – مدت فعالیتها – مسئولیتها – تعیین زمانهای شروع و پایان – رفع مشکل زمان بندی فعالیتهایی که اولویت یکسان دارند. – نظارت بر عملکرد پروژه – برنامه های تحلیل، زمان بندیها و فعالیتهای ثبت شده |
| مدیریت پیکره بندی محصول | |
| مدیریت محصول | – مدیریت نسخه های مختلف محصول– مدیریت تغییرات پیشنهادی و انجام ارزشیابی
– تخصیص پرسنل برای انجام تغییرات – نصب نسخه های جدید محصول |
مدیریت منابع
تخمین منابع مورد نیاز
منابع در دسترس
تعیین مسئولیتها برای استفاده بهینه از منابع
تهیه و تدارک منابع بحرانی برای به حداقل رساندن گلوگاه ها
فعالیتهای لازم برای ایجاد یک سیستم خبره، آن دسته از وظایفند که برای ساخت سیستم لازمند. شکل ۲-۶ یک نگرش سطح بالا از فعالیتهای لازم برای ساخت سیستم را نشان می دهد که شامل مراحلی است که سیستم باید از آنها عبور کند.
مسئله تحویل
سیستم چگونه تحویل داده خواهد شد؟
با این که استفاده از کامپیوترهای (اندازه متوسط) مدرن بسیار آسان بوده و زمان تحویل را نیز کاهش می دهد، ولی اغلب تحویل سیستم بر روی چنین کامپیوترهیی بسیار هزینه بر است. از این گذشته، هزینه نگهداری سالانه نیز این هزینه را به طور قابل توجهی افزایش می دهد.
بسته به تعداد سیستمهای خبره ای که در صف تحویل قرار دارند، مسئله تحویل سیستمهای ساخته شده ممکن است به یک مشکل جدی بدل شود. به همین دلیل مسئله تحویل باید در اولین مرحله ایجاد سیستم مورد نظر قرار گیرد.
حالت ایده آل آن است که سیستم خبره تحویل شده را بتوان روی سخت افزار استاندارد اجرا نمود. ولی بعضی ابزارهای سیستم خبره به یک ریزپردازنده LISP خاص نیاز دارند که هزینه را تا حد زیادی افزایش می دهد.
در بسیاری از موارد، سیستم خبره باید با سایر برنامه های موجود، یکپارچه شود. در این موارد باید به ارتباطات و هماهنگ سازی ورودی و خروجیهای سیستم خبره با سایر برنامه ها توجه شود. همچنین ممکن است مایل باشیم که در زبان برنامه نویسی رایج، سیستم خبره به عنوان یک رویه، فراخوانی شود و سیستم باید از این برنامه پشتیبانی کند.
نگهداری و تکامل
چگونه سیستم تکامل یافته و از آن نگهداری می شود؟
فعالیتهای نگهداری و تکامل یک سیستم خبره بیش از برنامه های رایج کامپیوتری، ادامه خواهد یافت. زیرا سیستمهای خبره مبتنی بر الگوریتم نیستند، عملکرد آنها به دانش وابسته است. هر دانش جدیدی که کسب شود، دانش قدیمی اصلاح می شود و عملکرد سیستم بهبود می یابد.
در یک محصول با کیفیت تجاری باید یک روش سیستماتیک و موثر برای جمع آوری شکایات از کاربران وجود داشته باشد. هر چند در سیستمهای خبره مربوط به تحقیقات، جمع آوری و رسیدگی به گزارشهای مربوط به ایرادات و نقائص از اولویت بالایی برخوردار نیست، ولی این موضوع در سیستمهایی با کیفیت تجاری دارای اولویت زیادی است. فقط در صورتی می توان بخوبی از سیستم نگهداری کرد که گزارشهای مربوط به ایرادات جمع آوری شده باشد.
ارتقاء و غنی سازی یک سیستم خبره پس از تحویل در سیستمهای خبره تجاری از اهمیت بیشتری برخوردار است. سازندگان یک سیستم تجاری علاقه مند به کسب موفقیتهای مالی هستند. این به معنای شنیدن خواسته های کاربران و بکارگیری آنها جهت بهبود سیستم است. در موقعیتهای واقعی یک سیستم خبره تجاری ممکن است هرگز به نقطه پایان نرسد، بلکه همواره بهتر شود.
خطاها در مراحل ایجاد
همان طور که شکل ۳-۶ نشان می دهد، خطاهای عمده ای که احتمالا در ایجاد سیستم خبره رخ می دهد. با تشخیص مرحله ای که احتمال بروز آن خطا بیشتر است دسته بندی می شود. این خطاها شامل موارد زیر هستند.
خطاهای موجود در دانش فرد خبره، منبع دانش سیستم خبره است. اگر در دانش فرد خبره خطایی وجود داشته باشد، نتایج آن ممکن است در کل فرآیند ایجاد سیستم منتشر شود. یکی از مزایای جنبی ساخت یک سیستم خبره این است که وقتی دانش فرد خبره، به صراحت بیان شده و شفاف می شود خطاهای احتمالی آن آشکار خواهد شد.
در پروژه هایی که ماموریت حساسی به عهده دارند و زندگی یا اموال افراد در خطر است، ممکن است لازم باشد از یک رویه رسمی برای تصدیق دانش فرد خبره استفاده شود. یکی از روشهای موفقیت آمیزی که ناسا برای پروازهای فضایی بکار برد استفاده از کمیته فنی پرواز بود که به طور منظم، راه حل مسائل و روشهای تحلیلی بکار رفته در ایجاد راه حلها را مورد بازنگری قرار می داد (Culbert 87). کمیته های فنی از کاربران سیستم، افراد خبره در زمینه های مستقل از هم، سازندگان سیستم و مدیران تشکیل می شود تا همه زمینه های ایجاد سیستم به طور موثر پوشش داده شود.
مزیت استفاده از کمیته فنی این است که دانش فرد خبره در بدو ایجاد سیستم مورد بررسی دقیق قرار می گیرد و این زمانی است که تصحیح خطاهای موجود دار دانش بسیار آسان تر است. هر چه خطاهای موجود در دانش دیرتر ظاهر شود هزینه بیشتری برای تصحیح آن لازم است. اگر در ابتدا دانش فرد خبره بررسی نشود، آزمون نهایی جهت تصدیق سیستم خبره صورت خواهد گرفت. اعتبارسنجی نهایی سیستم خبره مشخص می کند که آیا این سیستم جوابگوی نیازها هست یا خیر و به خصوص اینکه آیا راه حلها کامل و صحیح هستند یا نه.
عیب استفاده از کمیته فنی، هزینه ای است که در ابتدا تحمیل می شود. ولی این هزینه با افزایش کارایی فرآیند ایجاد سیستم جبران می شود.
خطای معنایی. خطای معنایی زمانی رخ می دهد که مفهوم دانش به درستی منتقل نمی شود. به عنوان یک مثال بسیار ساده فرض کنید یک فرد خبره می گوید «شما می توانید آتش را با آب خاموش کنید.» و مهندس دانش این گونه تعبیر می کند که «آتش سوزیها را می توان با آب مهار کرد.» خطای معنایی زمانی روی می دهد که یا مهندس دانش تعبیر نادرستی از پاسخ فرد خبره داشته باشد و یا فرد خبره، سوال مهندس دانش را به درستی تعبیر نکند و یا هر دوی این موارد.
خطای شکلی. خطاهای شکلی و یا دستور زبانی ساد هستند و زمانی روی می دهد که قاعده یا واقعیت به شکل نادرستی وارد شود. ابزارهای سیستم خبره باید این خطاها را شناسایی کرده و پیغامی مناسب به کاربر ارائه دهند. سایر خطاهایی که در مرحله ساخت پایگاه دانش روی می دهند نتیجه خطاهای موجود در منبع دانش هستند که در مراحل قبلی آشکار نشده اند.
خطاهای موتور استنتاج. مانند هر قسمتی از یک نرم افزار، موتور استنتاج نیز ممکن است دچار خطا شود. اولین باری که یک ابزار سیستم خبره جهت استفاده عمومی آماده می شود باید کلیه خطاهای عمومی آن برطرف شده باشد. ولی گاه خطاهایی وجود دارند که فقط در شرایطی بسیار نادر بروز می کنند که به عنوان مثال قرار گرفتن ۱۵۹ قاعده در دستور کار از آن جمله است. ممکن است بعضی خطاها بسیار ظریف باشند و فقط در تطبیق خاصی از قواعد با واقعیات بروز کنند. به طور کلی خطاهای موتور استنتاج ممکن است در تطبیق قواعد با واقعیات، رفع تناقض و اجرای فعالیتها روی دهند. اگر این خطاها به طور پیوسته رخ ندهند تشخیص آنها بسیار دشوار است. وقتی از ابزار سیستم خبره برای مأموریتهای حساس استفاده می کنید باید مشخص کنید که ابزار چگونه معتبر می شود.
ساده ترین روش برای خطاهای ابزار، روش قدیمی سوال از کاربران و فروشندگان ابزار است. باید فروشندگان ابزار فهرستی از مشتریان، خطاهای برنامه و چگونگی رفع آنها و نیز طول زمان استفاده از ابزار را تهیه نمایند. گروهی از کاربران می تواند منبع اطلاعاتی بسیار خوبی باشد.
خطاهای زنجیره استنتاج. این خطاها ممکن است در اثر عواملی همچون دانش آمیخته با خطا، خطاهای معنایی، خطاهای موتور استنتاج، تخصیص اولویت نادرست به قواعد و ارتباطات برنامه ریزی نشده بین قواعد بروز کنند. خطاهای پیچیده تر در زنجیره های استنتاج مربوط به عم قطعیت قواعد و شواهد، انتشار عدم قطعیت در زنجیره استنتاج و عدم یکنواختی هستند.
تنها انتخاب روشی برای مواجهه با عدم قطعیت نمی تواند همه مسائل مربوط به عدم قطعیت را خود به خود حل کند. به عنوان مثال، قبل از اینکه شما روش استنتاج بیزی ساده را انتخاب کنید باید بررسی نمایید که آیا تضمینی برای فرض استقلال شرطی وجود دارد یا خیر.
خطاهای مربوط به محدوده های جهل. یکی از مشکلات مربوط به همه مراحل ایجاد سیستم، تعیین محدوده های جهل سیستم است. افراد خبره، محدوده دانش خود را می دانند و خوشبختانه همان طور که به مرزهای جهل خود نزدیک می شوند به تدریج اطمینان آنها نسبت به استنتاج کاهش می یابد. افراد خبره باید به حدی صادق باشند که وقتی به مرزهای جهل خود نزدیک می شوند اجازه دهند که نتایج با عدم قطعیت بیشتری همراه باشد. ولی در یک سیستم خبره حتی اگر مدارک و زنجیره استنتاج بسیار ضعیف شوند باز هم با همان اطمینان به پاسخگویی ادامه می دهد مگر اینکه یک سیستم خبره طوری برنامه ریزی شده باشد که بتواند در چنین شرایطی با عدم قطعیت نتایج را بیان کند.
مهندسی نرم افزار و سیستمهای خبره
در قسمت قبل درباره ملاحظات کلی در بکارگیری سیستم خبره بحث کردیم. حال اجازه بدهید با یک دیدگاه فنی تر یعنی با دیدگاه مهندس دانش که سیستم را ساخته است مراحل ساخت سیستم خبر را مرور نماییم.
وقتی سیستم خبره از مرحله تحقیق بیرون آمد، لازم است سطح کیفیت نرم افزار به سطح استاندارد نرم افزارهای معمولی ارتقاء یابد. متدولوژی پذیرفته شده برای ایجاد نرم افزارهای کیفی در حد استانداردهای تجاری، صنعتی و دولتی، مهندسی نرم افزار است.
پیروی از استانداردهای مناسب برای ایجاد یک محصول از اهمیت زیادی برخوردار است در غیر این صورت احتمالا محصول کیفیت خوبی نخواهد داشت. در حال حاضر سیستمهای خبره را باید محصولی مانند سایر محصولات نرم افزاری نظیر پردازشگر لغات، برنامه پرداخت حقوق، بازیهای کامپیوتری و غیره در نظر گرفت.
با این وجود تفاوت مشهودی بین مأوریت سیستمهای خبره و سایر محصولات مصرفی نظیر پردازشگر لغات و بازیهای ویدئویی وجود دارد. معمولا تکنولوژی سیستمهای خبره وظیفه دارد دانش و خبرگی را برای موقعیتهای سطح بالا و احتمالا خطرناک که زندگی و اموال افراد در خطر است تهیه کند. این مأموریت حساسی است که در قسمت قبلی نیز به آن اشاره شد.
این مأمویت های حساس و بحرانی با مأموریت ساده پردازشگر لغات و برنامه های ویدئویی یعنی افزایش کارایی و تفریح کردن تفاوت بسیار زیادی دارد. زندگی هیچ انسانی نمی تواند به سیستمهای خبره، سیستمهایی با توان عملکرد بالا هستند که باید کیفیت بسیار خوبی داشته باشند در غیر این صورت با اشکالات زیادی رو به رو خواهند شد. همان طور که در شکل ۴-۶ نشان می دهد مهندسی نرم افزار روشهایی برای ساخت نرم افزار کیفی ارائه می دهد.
تشریح کلمه کیفیت به صورت کلی دشوار است زیرا این کلمه برای افراد معانی گوناگونی دارد. یکی از تعاریف کیفیت این است که آن را به صورت مشخصه های لازم یا مطلوبیک شی تعریف کنیم که در مقیاسهای خاصی تعیین شده است. کلمه شی در اینجا به معنای هر نوع سخت افزار یا نرم افزار یا محصولات نرم افزاری است. مشخصه ها و مقادیر آنها شاخص نامیده می شوند زیرا از آنها برای اندازه گیری اشیاء استفاده می شود. به عنوان مثال، قابلیت اطمینان اندازه گیری شده یک دیسک درایو، شاخصی برای کیفیت آن است. یکی از معیارهای این مشخصه، متوسط زمان بین خرابی (MTBF) درایوهاست. MTBF یک درایو قابل اطمینان، حدود ۱۰۰۰ ساعت است، در حالی که برای یک درایو غیر قابل اطمینان ممکن است حدود ۱۰۰ ساعت باشد.
جدول ۱-۶ فهرستی از چند شاخص ارائه داده است که ممکن است در ارزیابی کیفیت یک سیستم خبره کاربرد داشته باشند. این شاخصها فقط جنبه راهنما دارند زیرا یک سیستم خبره مخصوص ممکن است برخی از این شاخصها یا شاخصهای دیگری داشته باشد. در هر حال بهتر است که فهرستی از شاخصهای لازم تهیه شود تا از آن بتوان در تشریح کیفیت استفاده کرد.
فهرست شاخصها به شما کمک می کند تا به راحتی شاخصها را اولویت بندی کنید زیرا ممکن است بعضی از آنها با هم تناقض داشته باشند. به عنوان مثال افزایش تعداد آزمونهای یک سیستم خبره جهت اطمینان از درستی عملکرد آن، هزینه را افزایش خواهد داد. معمولا تصمیم گیری در مورد زمان ختم آزمونها کاری دشوار است که نیازمند بررسی عواملی همچون زمان بندی، هزینه و احتیاجات می باشد. در حالت ایده آل همه نیازهای فوق باید ارضاء شوند. در عمل ممکن است به بعضی از این نیازها اهمیت بیشتری داده و لذا موضوع ارضا همه عوامل به طور جدی دنبال نشود.
چرخه حیات سیستم خبره
یکی از روشهای کلیدی در مهندسی نرم افزار، چرخه حیات است. چرخه حیات نرم افزار مدت زمانی است که از لحظه ای که نرم افزار مفهوم خود را پیدا می کند شروع شده و پس از اینکه سیستم از رده خارج شد پایان می یابد. چرخه حیات علاوه بر اینکه به ایجاد و نگهداری سیستم به طور جداگانه می پردازد، نوعی پیوستگی و ارتباط بین کلیه مراحل ایجاد می کند. هر چه در چرخه حیات، برنامه ریزی برای نگهداری و ارتقاء سیستم زودتر انجام شود هزینه مراحل بعدی کاهش خواهد یافت.
هزینه های نگهداری
برای نرم افزارهای معمولی، معمولا ۶۰ تا ۸۰ درصد کل هزینه نرم افزار مربوط به هزینه نگهداری است که حدود ۲ تا ۴ برابر هزینه ایجاد سیستم است. اگر چه هنوز به دلیل جدید بودن سیستمهای خبره، اطلاعات کمی درباره نگهداری آنها در دست است ولی احتمالا برای سیستمهای خبره ارقام فوق صادق نیستند. اگر برنامه های معمولی با الگوریتم های شناخته شده نیاز به چنین هزینه زیادی جهت نگهداری دارند احتمالا سیستمهای خبره نیاز به هزینه بیشتری خواهند داشت زیرا این سیستمها مبتنی بر دانش تجربی و هیوریستیکها هستند. سیستمهای خبره ای که حجم بالایی از استنتاجها را در شرایط عدم اطمینان انجام می دهند هزینه نگهداری و ارتقاء بالاتری را می طلبند.
مدل آبشاری
برای نرم افزارهای معمولی، مدلهای چرخه حیات متعددی ایجاد شده است. مدل آبشاری کلاسیک، مدل اصلی چرخه حیات است که در شکل ۵-۶ نمایش داده شده است. این مدل برای برنامه نویسان نرم افزارهای معمولی بسیار آشنا است. در مدل آبشاری هر مرحله با یک فعالیت تصدیق و اعتبارسنجی (V&V) پایان می یابد تا مشکلات آن مرحله به حداقل برسد. همچنین دقت کنید که پیکانها فقط یک مرحله به جلو یا عقب می روند. این موضوع سبب می شود تا ایجاد دوباره سیستم بین دو مرحله مجاور، حداقل هزینه را در برداشته باشد در حالیکه ایجاد دوباره سیستم طی چند مرحله هزینه بالاتری در پی خواهد داشت.
اصطلاح دیگری که به چرخه حیات اطلاق می گردد مدل پردازش است زیرا این موضوع به دو مسئله اصلی در ایجاد نرم افزار مربوط می شود.
۱) بعد از این کار چه کاری باید انجام شود؟
۲) مرحله بعد طی چه مدت زمانی انجام می شود؟
مدل پردازش عملا یک فوق اسلوب یا فرا روش شناسی است زیرا ترتیب و مدت زمان لازم جهت اجرای روشهای نرم افزاری را مشخص می کند. روشهای ایجاد نرم ازار (متدولوژیها) موارد زیر را نشان می دهند.
روشهای خاص برای انجام یک مرحله نظیر
برنامه ریزی
احتیاجات
کسب دانش
آزمونها
نمایش محصول هر مرحله
مستندسازی
کد نویسی
نمودارها
مدل کدنویسی و اصلاح
تاکنون مدلهای پردازش بسیاری برای ایجاد نرم افزار مورد استفاده قرار گرفته اند. اولین مدل، مدل غیر معروف کدنویسی و اصلاح است که در آن ابتدا کدنویسی صورت می گیرد و سپس در صورتی که درست عمل نکند اصلاح می شود (Boehm 88). این روشی است که برنامه نویسان کم تجربه هم برای برنامه های متداول و هم برای سیستمهای خبره در پیش می گیرند.
از سال ۱۹۷۰ نقایص روش کدنویسی و اصلاح بخوبی مشهود شده بود و لذا مدل آبشاری برای ارائه یک روش سیستماتیک پدید آمد. این روش به ویژه برای پروژه های بزرگ مفید بود. ولی روش آبشاری نیز با مشکلاتی همراه بود زیرا در این مدل فرض می شود که همه اطلاعات لازم برای یک مرحله وجود دارد. اغلب مواقع در عمل این مکان وجود ندارد که بتوان یک بخش خاص را به طور کامل نوشت مگر اینکه قبلا یک نمونه آزمایشی از سیستم ساخته شده باشد. این موضوع موجب پدیدار شدن مفهوم جدیدی شد: «آن را دوبار انجام دهید.» یعنی در ابتدا با ساخت یک نمونه، احتیاجات را مشخص کرده و سپس سیستم اصلی را بسازید.
مدل افزایشی
مدل آبشاری افزایشی از بهبود روش آبشاری و روش استاندارد بالا به پائین بدست آمده است. ایده اصلی روش افزایشی این است که با افزای قابلیتهای عملکردی، نرم افزار بهبود یابد. مدل افزایشی در پروژه های بزرگ نرم افزاری متداول بسیار موفق عمل کرده است. همچنین در بعضی سیستمهای خبره که اضافه شدن قواعد، توانایی سیستم را از سطح دستیار به همکار و از همکار به سطح خبره افزایش می دهد، مدل افزایشی کاملا موفق عمل کرده است. بنابراین در یک سیستم خبره، توسعه یا افزایش کلی از سطح دستیار به سطح همکار و از سطح همکار به سطح خبره است. توسعه یا افزایش جزئی، میزان خبرگی را در هر سطحی افزایش می دهد که گاه بهبودهای مهمی را نیز صورت می دهد یک توسعه یا افزایش ریز عبارت از تغییر در خبرگی است که با اضافه شدن یا اصلاح یک قاعده منفرد صورت می گیرد.
مزیت اصلی این روش آن است که «افزایش قابلیتهای عملکردی» در مدل افزایشی را بسیار راحت تر از«محصول هر مرحله» در مدل آبشاری می توان مورد آزمون، تصدیق و اعتبارسنجی قرار داد. فرد خبره می تواند به جای یک اعتبارسنجی کامل و کلی در انتهای کار، هر افزایش عملکرد را بلافاصله مورد آزمون، تصدیق و اعتبارسنجی قرار دهد. این امر هزینه تصحیحهای کلی را در سیستم کاهش می دهد. در اصل مدل افزایشی شبیه به نمونه سازی سریع و پیوسته است که کل مراحل ایجاد سیستم را در بر می گیرد. بر خلاف روش «آن را دوبار انجام دهید» که برای تعیین احتیاجات سریعا یک نمونه از مراحل اولیه می سازد، در این روش نمونه متکامل شونده بنوعی همان سیستم مورد نظر ماست.
مدل مارپیچی
همان طور که شکل ۶-۶ نشان می دهد مدل افزایشی را می توان به صورت تعدیلی از یک مدل مارپیچی متداول تجسم کرد. در هر حلقه مارپیچ، توانایی های عملکردی جدیدی به سیستم اضافه می شود. آخرین نقطه که «سیستم تحویل شده» نام دارد عملا پایان مارپیچ نیست. بلکه با شروع نگهداری و ارتقاء سیستم یک مارپیچ جدید شروع می شود. این مارپیچ را می توان اصلاح کرد تا مراحل کلی کسب دانش، کدنویسی، ارزشیابی و برنامه ریزی به طور دقیق تر مشخص شوند.
سیستم خبره قسمت 1
سیستم خبره قسمت 2
سیستم خبره قسمت 3
سیستم خبره قسمت 4
سیستم خبره قسمت 5
سیستم خبره قسمت 6
گذری بر سیستمهای خبره (Expert Systems)
")
اشاره :
<استدلال> در میان اهل فن و صاحبان اندیشه تعاریف و تفاسیر متنوعی دارد. در نگاهی كلی، استفاده از دلیل و برهان برای رسیدن به یك نتیجه از فرضیاتی منطقی با استفاده از روشهای معین، تعریفی از استدلال تلقی میشود؛ تعریفی كه البته با دیدگاههای فلسفی و گاه ایدهآلگرایانه از استدلال تفاوت دارد. با این حال موضوع مهم و اساسی در اینجا بحث در چیستی و چرایی این دیدگاهها نیست، بلكه در مورد نحوه طراحی سیستمهای با قدرت استدلال، با هر تعریفی، برای رسیدن به مجموعهای از تصمیمات منطقی با استفاده از مفروضات یا به طور دقیقتر دانشی است كه در اختیار آنها قرار میگیرد. سیستمهایی خبره (expert systems) اساسا برای چنین هدفی طراحی میشوند. در حقیقت به واسطه الگوبرداری این سیستمها از نظام منطق و استدلال انسان و نیز یكسان بودن منابع دانش مورد استفاده آنها، حاصل كار یك سیستم خبره میتواند تصمیماتی باشد كه درحوزهها و عرصههای مختلف قابل استفاده، مورد اطمینان و تاثیرگذار هستند. بسیاری بر این باورند كه سیستمهای خبره بیشترین پیشرفت را در هوش مصنوعی به وجود آوردهاند. آنچه درادامه میخوانید نگاهی كوتاه به تعاریف و سازوكار سیستمهای خبره و گذری بر مزایا و محدودیتهای به كارگیری این سیستمها در علوم و فنون مختلف است. طبیعتاً مباحث كاربردیتر و عملیتر درباره سیستمهای خبره و بحث درباره نحوه توسعه و پیادهسازی آنها، نیازمند مقالات جداگانهای است كه در آینده به آنها خواهیم پرداخت.
سیستم خبره چیست؟
در یك تعریف كلی میتوان گفت سیستمهای خبره، برنامههای كامپیوتریای هستند كه نحوه تفكر یك متخصص در یك زمینه خاص را شبیهسازی میكنند. در واقع این نرمافزارها، الگوهای منطقیای را كه یك متخصص بر اساس آنها تصمیمگیری میكند، شناسایی مینمایند و سپس بر اساس آن الگوها، مانند انسانها تصمیمگیری میكنند.
یكی از اهداف هوش مصنوعی، فهم هوش انسانی با شبیهسازی آن توسط برنامههای كامپیوتری است. البته بدیهی است كه “هوش” را میتوان به بسیاری از مهارتهای مبتنی بر فهم، از جمله توانایی تصمیمگیری، یادگیری و فهم زبان تعمیم داد و از اینرو واژهای كلی محسوب میشود.
بیشتر دستاوردهای هوش مصنوعی در زمینه تصمیمگیری و حل مسئله بوده است كه اصلیترین موضوع سیستمهای خبره را شامل میشوند. به آن نوع از برنامههای هوش مصنوعی كه به سطحی از خبرگی میرسند كه میتوانند به جای یك متخصص در یك زمینه خاص تصمیمگیری كنند، expert systems یا سیستمهای خبره گفته میشود. این سیستمها برنامههایی هستند كه پایگاه دانش آنها انباشته از اطلاعاتی است كه انسانها هنگام تصمیمگیری درباره یك موضوع خاص، براساس آنها تصمیم میگیرند. روی این موضوع باید تأكید كرد كه هیچیك از سیستمهای خبرهای كه تاكنون طراحی و برنامهنویسی شدهاند، همهمنظوره نبودهاند و تنها در یك زمینه محدود قادر به شبیهسازی فرآیند تصمیمگیری انسان هستند.
به محدوده اطلاعاتی از الگوهای خبرگی انسان كه به یك سیستم خبره منتقل میشود، task domain گفته میشود. این محدوده، سطح خبرگی یك سیستم خبره را مشخص میكند و نشان میدهد كه آن سیستم خبره برای چه كارهایی طراحی شده است. سیستم خبره با این task ها یا وظایف میتواند كارهایی چون برنامهریزی، زمانبندی، و طراحی را در یك حیطه تعریف شده انجام دهد.
به روند ساخت یك سیستم خبره، knowledge engineering یا مهندسی دانش گفته میشود. یك مهندس دانش باید اطمینان حاصل كند كه سیستم خبره طراحی شده، تمام دانش مورد نیاز برای حل یك مسئله را دارد. طبیعتاً در غیراینصورت، تصمیمهای سیستم خبره قابل اطمینان نخواهند بود.
ساختار یك سیستم خبره
هر سیستم خبره از دو بخش مجزا ساخته شده است: پایگاه دانش و موتور تصمیمگیری.
پایگاه دانش یك سیستم خبره از هر دو نوع دانش مبتنی بر حقایق (factual) و نیز دانش غیرقطعی (heuristic) استفاده میكند. Factual knowledge، دانش حقیقی یا قطعی نوعی از دانش است كه میتوان آن را در حیطههای مختلف به اشتراك گذاشت و تعمیم داد؛ چراكه درستی آن قطعی است.
پایگاه دانش یك سیستم خبره از هر دو نوع دانش مبتنی بر حقایق (factual) و نیز دانش غیرقطعی (heuristic) استفاده میكند. Factual knowledge، دانش حقیقی یا قطعی نوعی از دانش است كه میتوان آن را در حیطههای مختلف به اشتراك گذاشت و تعمیم داد؛ چراكه درستی آن قطعی است.
در سوی دیگر، Heuristic knowledge قرار دارد كه غیرقطعیتر و بیشتر مبتنی بر برداشتهای شخصی است. هرچه حدسها یا دانش هیورستیك یك سیستم خبره بهتر باشد، سطح خبرگی آن بیشتر خواهد بود و در شرایط ویژه، تصمیمات بهتری اتخاذ خواهد كرد.
دانش مبتنی بر ساختار Heuristic در سیستمهای خبره اهمیت زیادی دارد این نوع دانش میتواند به تسریع فرآیند حل یك مسئله كمك كند. البته یك مشكل عمده در ارتباط با به كارگیری دانشHeuristic آن است كه نمیتوان در حل همه مسائل از این نوع دانش استفاده كرد. به عنوان نمونه جلوگیری از حمل سموم خطرناك از طریق خطوط هوایی با استفاده از روش Heuristic امكانپذیر نیست.
اطلاعات این بخش از سیستم خبره از طریق مصاحبه با افراد متخصص در این زمینه تامین میشود. مهندس دانش یا مصاحبهكننده، پس از سازماندهی اطلاعات جمعآوریشده از متخصصان یا مصاحبه شوندگان، آنها را به قوانین قابل فهم برای كامپیوتر به صورت (if-then) موسوم به قوانین ساخت (production rules) تبدیل میكند.
موتور تصمیمگیری سیستم خبره را قادر میكند با استفاده از قوانین پایگاه دانش، پروسه تصمیمگیری را انجام دهد. برای نمونه، اگر پایگاه دانش قوانینی به صورت زیر داشته باشد:
●دفتر ماهنامه شبكه در تهران قرار دارد.
●تهران در ایران قرار دارد.
سیستم خبره میتواند به قانون زیر برسد:
● دفتر ماهنامه شبكه در ایران قرار دارد.
در یك تعریف كلی میتوان گفت سیستمهای خبره، برنامههای كامپیوتریای هستند كه نحوه تفكر یك متخصص در یك زمینه خاص را شبیهسازی میكنند.
استفاده از منطق فازی
موضوع مهم دیگر در ارتباط با سیستمهای خبره، پیوند و ارتباط آن با دیگر شاخههای هوش مصنوعی است. به بیان روشنتر، برخی از سیستمهای خبره از Fuzzy Logic یا منطق فازی استفاده میكنند. در منطق غیرفازی تنها دو ارزش درست (true) یا نادرست (false) وجود دارد. چنین منطقی نمیتواند چندان كامل باشد؛ چراكه فهم و پروسه تصمیمگیری انسانها در بسیاری از موارد، كاملا قطعی نیست و بسته به زمان و مكان آن، تا حدودی درست یا تا حدودی نادرست است. در خلال سالهای 1920 و 1930، Jan Lukasiewicz فیلسوف لهستانی منطقی را مطرح كرد كه در آن ارزش یك قانون میتواند بیشتر از دو مقدار 0 و 1 یا درست و نادرست باشد. سپس پروفسور لطفیزاده نشان داد كه منطق Lukasiewicz را میتوان به صورت “درجه درستی” مطرح كرد. یعنی به جای اینكه بگوییم: “این منطق درست است یا نادرست؟” بگوییم: “این منطق چقدر درست یا چقدر نادرست است؟”
از منطق فازی در مواردی استفاده میشود كه با مفاهیم مبهمی چون “سنگینی”، “سرما”، “ارتفاع” و از این قبیل مواجه شویم. این پرسش را در نظر بگیرید : “وزن یك شیء 500 كیلوگرم است، آیا این شیء سنگین است؟” چنین سوالی یك سوال مبهم محسوب میشود؛ چراكه این سوال مطرح میشود كه “از چه نظر سنگین؟” اگر برای حمل توسط یك انسان بگوییم، بله سنگین است. اگر برای حمل توسط یك اتومبیل مطرح شود، كمی سنگین است، ولی اگر برای حمل توسط یك هواپیما مطرح شود سنگین نیست.
در اینجاست كه با استفاده از منطق فازی میتوان یك درجه درستی برای چنین پرسشی در نظر گرفت و بسته به شرایط گفت كه این شیء كمی سنگین است. یعنی در چنین مواردی گفتن اینكه این شیء سنگین نیست
(false) یا سنگین است (true) پاسخ دقیقی نیست.
مزایا و محدودیتهای سیستمهای خبره
دستاورد سیستمهای خبره را میتوان صرفهجویی در هزینهها و نیز تصمیمگیریهای بهتر و دقیقتر و بسیاری موارد تخصصیتر دیگر عنوان كرد. استفاده از سیستمهای خبره برای شركتها میتواند صرفهجویی به همراه داشته باشد.
دستاورد سیستمهای خبره را میتوان صرفهجویی در هزینهها و نیز تصمیمگیریهای بهتر و دقیقتر و بسیاری موارد تخصصیتر دیگر عنوان كرد. استفاده از سیستمهای خبره برای شركتها میتواند صرفهجویی به همراه داشته باشد.
در زمینه تصمیمگیری نیز گاهی میتوان در شرایط پیچیده، با بهرهگیری از چنین سیستمهایی تصمیمهای بهتری اتخاذ كرد و جنبههای پیچیدهای را در مدت زمان بسیار كمی مورد بررسی قرار داد كه تحلیل آنها به روزها زمان نیاز دارد.
از سوی دیگر، بهكارگیری سیستمهای خبره محدودیتهای خاصی دارد. به عنوان نمونه، این سیستمها نسبت به آنچه انجام میدهند، هیچ <حسی> ندارند. چنین سیستمهایی نمیتوانند خبرگی خود را به گسترههای وسیعتری تعمیم دهند؛ چراكه تنها برای یك منظور خاص طراحی شدهاند و پایگاه دانش آنها از دانش متخصصان آن حوزه نشات گرفته و از اینرو محدود است.
چنین سیستمهایی از آنجا كه توسط دانش متخصصان تغذیه اطلاعاتی شدهاند، در صورت بروز برخی موارد پیشبینی نشده، نمیتوانند شرایط جدید را به درستی تجزیه و تحلیل نمایند.
كاربرد سیستمهای خبره
از سیستمهای خبره در بسیاری از حیطهها از جمله برنامهریزیهای تجاری، سیستمهای امنیتی، اكتشافات نفت و معادن، مهندسی ژنتیك، طراحی و ساخت اتومبیل، طراحی لنز دوربین و زمانبندی برنامه پروازهای خطوط هوایی استفاده میشود. دو نمونه از كاربردهای این سیستمها در ادامه توضیح دادهشدهاند.
از سیستمهای خبره در بسیاری از حیطهها از جمله برنامهریزیهای تجاری، سیستمهای امنیتی، اكتشافات نفت و معادن، مهندسی ژنتیك، طراحی و ساخت اتومبیل، طراحی لنز دوربین و زمانبندی برنامه پروازهای خطوط هوایی استفاده میشود. دو نمونه از كاربردهای این سیستمها در ادامه توضیح دادهشدهاند.
● طراحی و زمانبندی
سیستمهایی كه در این زمینه مورد استفاده قرار میگیرند، چندین هدف پیچیده و تعاملی را مورد بررسی قرار میدهند تا جوانب كار را روشن كنند و به اهداف مورد نظر دست یابند یا بهترین گزینه را پیشنهاد دهند. بهترین مثال از این مورد، زمانبندی پروازهای خطوط هوایی، كارمندان و گیتهای یك شركت حمل و نقل هوایی است.
سیستمهایی كه در این زمینه مورد استفاده قرار میگیرند، چندین هدف پیچیده و تعاملی را مورد بررسی قرار میدهند تا جوانب كار را روشن كنند و به اهداف مورد نظر دست یابند یا بهترین گزینه را پیشنهاد دهند. بهترین مثال از این مورد، زمانبندی پروازهای خطوط هوایی، كارمندان و گیتهای یك شركت حمل و نقل هوایی است.
● تصمیمگیریهای مالی
صنعت خدمات مالی یكی از بزرگترین كاربران سیستمهای خبره است. نرمافزارهای پیشنهاددهنده نوعی از سیستمهای خبره هستند كه به عنوان مشاور بانكداران عمل میكنند. برای نمونه، با بررسی شرایط یك شركت متقاضی وام از یك بانك تعیین میكند كه آیا پرداخت این وام به شركت برای بانك مورد نظر صرفه اقتصادی دارد یا نه. همچنین شركتهای بیمه برای بررسی میزان خطرپذیری و هزینههای موارد مختلف، از این سیستمها استفاده میكنند.
صنعت خدمات مالی یكی از بزرگترین كاربران سیستمهای خبره است. نرمافزارهای پیشنهاددهنده نوعی از سیستمهای خبره هستند كه به عنوان مشاور بانكداران عمل میكنند. برای نمونه، با بررسی شرایط یك شركت متقاضی وام از یك بانك تعیین میكند كه آیا پرداخت این وام به شركت برای بانك مورد نظر صرفه اقتصادی دارد یا نه. همچنین شركتهای بیمه برای بررسی میزان خطرپذیری و هزینههای موارد مختلف، از این سیستمها استفاده میكنند.
چند سیستم خبره مشهور
از نخستین سیستمهای خبره میتوان به Dendral اشاره كرد كه در سال 1965 توسط Edward Feigenbaum وJoshun Lederberg پژوهشگران هوش مصنوعی در دانشگاه استنفورد ساخته شد.
از نخستین سیستمهای خبره میتوان به Dendral اشاره كرد كه در سال 1965 توسط Edward Feigenbaum وJoshun Lederberg پژوهشگران هوش مصنوعی در دانشگاه استنفورد ساخته شد.
وظیفه این برنامه كامپیوتری، تحلیلهای شیمیایی بود. ماده مورد آزمایش میتوانست تركیبی پیچیده از كربن، هیدروژن و نیتروژن باشد. Dendarl میتوانست با بررسی آرایش و اطلاعات مربوط به یك ماده، ساختار مولكولی آن را شبیهسازی كند. كاركرد این نرمافزار چنان خوب بود كه میتوانست با یك متخصص رقابت كند.
از دیگر سیستمهای خبره مشهور میتوان به MYCIN اشاره كرد كه در سال 1972 در استنفورد طراحی شد. MYCIN برنامهای بود كه كار آن تشخیص عفونتهای خونی با بررسی اطلاعات به دست آمده از شرایط جسمی بیمار و نیز نتیجه آزمایشهای او بود.
برنامه به گونهای طراحی شده بود كه در صورت نیاز به اطلاعات بیشتر، با پرسشهایی آنها را درخواست میكرد تا تصمیمگیری بهتری انجام دهد؛ پرسشهایی چون “آیا بیمار اخیرا دچار سوختگی شده است؟” (برای تشخیص اینكه آیا عفونت خونی از سوختگی نشات گرفته یا نه. MYCIN ( گاه میتوانست نتایج آزمایش را نیز از پیش حدس بزند.
سیستم خبره دیگر در این زمینه Centaur بود كه كار آن بررسی آزمایشهای تنفسی و تشخیص بیماریهای ریوی بود. یكی از پیشروان توسعه و كاربرد سیستمهای خبره، سازمانهای فضایی هستند كه برای مشاوره و نیز بررسی شرایط پیچیده و صرفهجویی در زمان و هزینه چنین تحلیلهایی به این سیستمها روی آوردهاند.
Marshall Space Flight Center) MSFC) یكی از مراكز وابسته به سازمان فضایی ناسا از سال 1994 در زمینه توسعه نرمافزارهای هوشمند كار میكند كه هدف آن تخمین كمّ و كیف تجهیزات و لوازم مورد نیاز برای حمل به فضا است.
این برنامههای كامپیوتری با پیشنهاد راهكارهایی در این زمینه از بار كاری كارمندان بخشهایی چون ISS (ایستگاه فضایی بین المللی) میكاهند و به گونهای طراحی شدهاند كه مدیریتپذیرند و بسته به شرایط مختلف، قابل تعریف هستند.
مركز فضایی MSFC، توسط فناوری ویژه خود موسوم به 2G به ایجاد برنامههای ویژه كنترل هوشمندانه و سیستمهای مانیتورینگ خطایاب میپردازد. این فناوری را میتوان هم در سیستمهای لینوكسی و هم در سیستمهای سرور مبتنی بر ویندوز مورد استفاده قرار داد.
آنچه در نهایت میتوان گفت آن است كه یكی از مزیتهای سیستمهای خبره این است كه میتوانند در كنار متخصصان انسانی مورد استفاده قرار بگیرند كه ماحصل آن تصمیمی مبتنی بر تخصص انسانی و دقت ماشینی است. این فناوری از دید تجاری نیز برای توسعهدهندگان آن سودآور است.
هماكنون شركتهای بسیاری به فروش سیستمهای خبره و پشتیبانی از مشتریان محصولات خود میپردازند. درآمد یك شركت كوچك فعال در زمینه فروش چنین محصولاتی میتواند سالانه بالغ بر پنج تا بیست میلیون دلار باشد. بازار فروش و پشتیبانی سیستمهای خبره در سراسر جهان نیز سالانه به صدها میلیون دلار میرسد.
خبرگی
خبرگی(Expertise) دانشی است تخصصی که برای رسیدن به آن نیاز به مطالعه مفاهیم تخصصی یا دورههای ویژه وجود دارد.
سیستمهای خبره
سیستمهای خبره یکی از زیرشاخههای هوش مصنوعی میباشد و یک سیستم خبره به برنامه کامپیوتری گفته میشود که دارای خبرگی در حوزه خاصی میباشد و میتواند در آن حوزه تصمیمگیری با کمک به خبره جهت تصمیمگیری بکار رود.
نکته
سیستمهای خبره برا حل مسائلی بکار میروند که:1. الگوریتم خاصی برا حل آن مسائل وجود ندارند.
2. دانش صریح برای حل آن مسائل وجود دارد.
بنابراین اگر سیستمی با استفاده از روشهای علم آماراقدام به پیشبینی دمایهوای فردا کند، در حوزه سیستمهای خبره قرار نمیگیرد.اما اگر سیستمی بااستفاده از این قاعده که«در این فصل سال دمایهوا معمولا ثابت میباشد» و این واقعیت که «دمای امروز 25 درجه سانتی گراد میباشد» به این نتیجه دست یابد که «دمای فردا 25 درجه خواهد بود» در حوزه سیستمهای خبره قرا خواهد گرفت.
از سیستم خبره نباید انتظار داشت که نتیجه بهتر از نتیجه یک خبره را بیابد. سیستم خبره تنها میتواند همسطح یک خبره اقدام به نتیجهگیری نماید. سیستمهای خبره همیشه به جواب نمیرسند.
باتوجه به این که علوم مختلفی وجود دارد در نتیجه خبرگی در شاخههای علمی متفاوت مطرح است. یک فرد خبره(Expert) فردی است که در زمینهای خاص مهارت دارد به طور مثال یک پزشک یک مکانیک و یک مهندس افرادی خبره هستند. این مسئله بیانگر این است که دامنه کاربرد سیستمهای خبره گسترده است و میتوان برای هر زمینه کاری یک سیستم خبره طراحی نمود.
بیان خبرگی در قالب دانش یا بازنمایی دانش
برای این که این خبرگی یک سیستم خبره تشکیل دهد لازم است این خبرگی در قالب دانش بیان شود. بازنمایی دانش تکنیکی است برای بیان خبرگی در قالب دانش.بازنمایی دانش برای ایجاد و سازماندهی دانش یک فرد خبره در یک سیستم خبره استفاده میشود.
اجزای اصلی سیستم خبره
یک سیستم خبره دارای اجزای زیر میباشد:
پایگاه دانش
یکی از مولفههای مهم سیستمهای خبره پایگاه دانش یا مخزن دانش است. محلی است که دانش خبره به صورت کدگذاری شده و قابل فهم برای سیستم ذخیره میشود. پایگاه قواعد دانش، محلی است که بازنمایی دانش صورت میگیرد. بازنمایی دانش بعد از اتمام مراحل به پایگاه قواعد دانش تبدیل میشود.
به کسی که دانش خبره را کد کرده و وارد پایگاه دانش میکند مهندس دانش (Knowledge engineer) گفته میشود.
بطور کلی دانش به صورت عبارات شرطی و قواعد در پایگاه دانش ذخیره میگردد.«اگر چراغ قرمز است آنگاه متوقف شو»
هرگاه این واقعیت وجود داشته باشد که «چراغ قرمز است» آنگاه این واقعیت با الگوی« چراغ قرمز است» منطبق میشود. دراین صورت این قاعده برآورده میشود و دستور متوقف شو اجرا میشود.
موتور استنتاج
یعنی از دانش موجود استفاده و دانش را برای حل مسئله به هم ربط دهیم.
موتور استنتاج با استفاده از قواعد منطق و دانش موجود در پایگاه دانش و حقایق حافظه کاری اقدام به انجام کار خاصی مینماید. این عمل یا بصورت افزودن حقایق جدیدی به پایگاه دانش میباشد یا بصورت نتیجهای برای اعلام به کاربر یا انجام کار خاصی میباشد.
حافظه کاری
حافظهای برای ذخیره پاسخ سوالهای مربوط به سیستم میباشد.
امکانات کسب دانش
امکانات کسب دانش در واقع راهکارهایی برای ایجاد و اضافه نمودن دانش به سیستم میباشد. امکاناتی است که اگر بخواهیم دانشی به سیستم اضافه کنیم باید یک بار از این مرحله عبور کنیم اگر این دانش قبلا در سیستم وجود نداشته باشد به موتور استنتاج میرود روی آن پالایشی صورت میگیرد و سپس در پایگاه دانش قرار میگیرد.
امکانات توضیح
برای نشان دادن مراحل نتیجهگیری سیستم خبره برای یک مسئله خاص با واقعیت خاص به کاربر به زبان قابل فهم برای کاربر بکارمیرود. این امکانات این فایده را دارد که کاربر با دیدن مراحل استنتاج اطمینان بیشتری به تصمیم گرفتهشده توسط سیستم خواهد داشت و خبرهای که دانش او وارد پایگاه دانش شدهاست اطمینان حاصل خواهد کرد که دانش و به صورت صحیح وارد شدهاست.
اگر د ارتباط با سیستم سوال و جوابهایی مطرح شود و سیستم به ما یک سری راهکار پیشنهاد کند و توضیحی در زمینه اینکه چرا چنین سوالی پرسیده میشود؟(Why) و چگونه به این نتیجه رسیدهایم؟(How) را در ناحیهای ذخیره نماییم، امکانات توضیح را تشکیل میدهد.
بخش ارتباط با کاربر
مربوط به بخشی است که بطور مستقیم با کاربر در ارتباط است.
کاربردهای سیستم های خبره
1- جایگزینی برای فرد خبره(سیستم اینترنتی در زمینه مشاور محصولات یک شرکت)
-
- تداوم کار در صورت عدم دسترسی به فرد خبره
-
- کاهش هزینه
-
- احساساتی نبودن سیستم و خستگی ناپذیری آن
2- کمک و دستیار( برنامههای MS Project یا Autocad یا Pspicee برنامههایی هستند که دانشی برای انجام عملیاتی برای کمک به افرادی خاص را دارند)
سیستم خبره قسمت 1
سیستم خبره قسمت 2
سیستم خبره قسمت 3
سیستم خبره قسمت 4
سیستم خبره قسمت 5
سیستم خبره قسمت 6
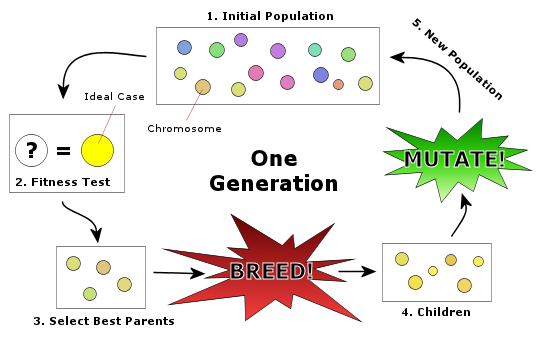
تکنیک جستجو در علم رایانه برای یافتن راهحل تقریبی برای بهینهسازی مدل ،ریاضی و مسائل جستجو است. الگوریتم ژنتیک نوع خاصی از الگوریتمهای تکامل است که از تکنیکهای زیستشناسی فرگشتی مانند وراثت، جهش زیستشناسی و اصول انتخابی داروین برای یافتن فرمول بهینه جهت پیشبینی یا تطبیق الگواستفاده میشود. الگوریتمهای ژنتیک اغلب گزینه خوبی برای تکنیکهای پیشبینی بر مبنای رگرسیون هستند.
در مدل سازی الگوریتم ژنتیک یک تکنیک برنامهنویسی است که از تکامل ژنتیکی به عنوان یک الگوی حل مسئله استفاده میکند. مسئلهای که باید حل شود دارای ورودیهایی میباشد که طی یک فرایند الگوبرداری شده از تکامل ژنتیکی به راهحلها تبدیل میشود سپس راه حلها بعنوان کاندیداها توسط تابع ارزیاب (Fitness Function) مورد ارزیابی قرار میگیرند و چنانچه شرط خروج مسئله فراهم شده باشد الگوریتم خاتمه مییابد. الگوریتم ژنتیک چیست؟ بطور کلی یک الگوریتم مبتنی بر تکرار است که اغلب بخشهای آن به صورت فرایندهای تصادفی انتخاب میشوند که این الگوریتمها از بخشهای تابع برازش، نمایش، انتخاب وتغییر تشکیل میشوند.
مقدمه
هنگامی که لغت تنازع بقا به کار میرود اغلب بار ارزشی منفی آن به ذهن میآید. شاید همزمان قانون جنگل به ذهن برسد و حکم بقای قویترها!
البته همیشه هم قویترینها برنده نبودهاند. مثلاً دایناسورها با وجود جثه عظیم و قویتر بودن در طی روندی کاملاً طبیعی بازیِ بقا و ادامه نسل را واگذار کردند در حالی که موجوداتی بسیار ضعیفتر از آنها حیات خویش را ادامه دادند. ظاهراً طبیعت، بهترینها را تنها بر اساس هیکل انتخاب نمیکند! در واقع درستتر آنست که بگوییم طبیعت مناسب ترینها (Fittest) را انتخاب میکند نه بهترینها.
قانون انتخاب طبیعی بدین صورت است که تنها گونههایی از یک جمعیت ادامه نسل میدهند که بهترین خصوصیات را داشته باشند و آنهایی که این خصوصیات را نداشته باشند به تدریج و در طی زمان از بین میروند.
الگوریتمهای ژنتیک یکی از الگوریتمهای جستجوی تصادفی است که ایده آن برگرفته از طبیعت میباشد. الگوریتمهای ژنتیک برای روشهای کلاسیک بهینهسازی در حل مسائل خطی، محدب و برخی مشکلات مشابه بسیار موفق بودهاند ولی الگوریتمهای ژنتیک برای حل مسائل گسسته و غیر خطی بسیار کاراتر میباشند. به عنوان مثال میتوان به مسئله فروشنده دورهگرد اشاره کرد. در طبیعت از ترکیب کروموزومهای بهتر، نسلهای بهتری پدید میآیند. در این بین گاهی اوقات جهشهایی نیز در کروموزومها روی میدهد که ممکن است باعث بهتر شدن نسل بعدی شوند. الگوریتم ژنتیک نیز با استفاده از این ایده اقدام به حل مسائل میکند. روند استفاده از الگوریتمهای ژنتیک به صورت زیر میباشد:
الف) معرفی جوابهای مسئله به عنوان کروموزوم
ب) معرفی تابع برازندگی (فیت نس)
ج) جمعآوری اولین جمعیت
د) معرفی عملگرهای انتخاب
ه) معرفی عملگرهای تولید مثل
در الگوریتمهای ژنتیک ابتدا به طور تصادفی یا الگوریتمیک، چندین جواب برای مسئله تولید میکنیم. این مجموعه جواب را جمعیت اولیه مینامیم. هر جواب را یک کروموزوم مینامیم. سپس با استفاده از عملگرهای الگوریتم ژنتیک پس از انتخاب کروموزومهای بهتر، کروموزومها را باهم ترکیب کرده و جهشی در آنها ایجاد میکنیم. در نهایت نیز جمعیت فعلی را با جمعیت جدیدی که از ترکیب و جهش در کروموزومها حاصل میشود، ترکیب میکنیم.
مثلاً فرض کنید گونه خاصی از افراد، هوش بیشتری از بقیه افرادِ یک جامعه یا کولونی دارند. در شرایط کاملاً طبیعی، این افراد پیشرفت بهتری خواهند کرد و رفاه نسبتاً بالاتری خواهند داشت و این رفاه، خود باعث طول عمر بیشتر و باروری بهتر خواهد بود (توجه کنید شرایط، طبیعیست نه در یک جامعه سطح بالا با ملاحظات امروزی؛ یعنی طول عمر بیشتر در این جامعه نمونه با زاد و ولد بیشتر همراه است). حال اگر این خصوصیت (هوش) ارثی باشد بالطبع در نسل بعدی همان جامعه تعداد افراد باهوش به دلیل زاد و ولد بیشترِ اینگونه افراد، بیشتر خواهد بود. اگر همین روند را ادامه دهید خواهید دید که در طی نسلهای متوالی دائماً جامعه نمونه ما باهوش و باهوشتر میشود. بدین ترتیب یک مکانیزم ساده طبیعی توانستهاست در طی چند نسل عملاً افراد کم هوش را از جامعه حذف کند علاوه بر اینکه میزان هوش متوسط جامعه نیز دائماً در حال افزایش است.
بدین ترتیب میتوان دید که طبیعت با بهرهگیری از یک روش بسیار ساده (حذف تدریجی گونههای نامناسب و در عین حال تکثیر بالاتر گونههای بهینه)، توانستهاست دائماً هر نسل را از لحاظ خصوصیات مختلف ارتقاء بخشد.
البته آنچه در بالا ذکر شد به تنهایی توصیف کننده آنچه واقعاً در قالب تکامل در طبیعت اتفاق میافتد نیست. بهینهسازی و تکامل تدریجی به خودی خود نمیتواند طبیعت را در دسترسی به بهترین نمونهها یاری دهد. اجازه دهید تا این مسئله را با یک مثال شرح دهیم:
پس از اختراع اتومبیل به تدریج و در طی سالها اتومبیلهای بهتری با سرعتهای بالاتر و قابلیتهای بیشتر نسبت به نمونههای اولیه تولید شدند. طبیعیست که این نمونههای متأخر حاصل تلاش مهندسان طراح جهت بهینهسازی طراحیهای قبلی بودهاند. اما دقت کنید که بهینهسازی یک اتومبیل، تنها یک «اتومبیل بهتر» را نتیجه میدهد.
اما آیا میتوان گفت اختراع هواپیما نتیجه همین تلاش بودهاست؟ یا فرضاً میتوان گفت فضاپیماها حاصل بهینهسازی طرح اولیه هواپیماها بودهاند؟
پاسخ اینست که گرچه اختراع هواپیما قطعاً تحت تأثیر دستاوردهایهای صنعت اتومبیل بودهاست؛ اما به هیچ وجه نمیتوان گفت که هواپیما صرفاً حاصل بهینهسازی اتومبیل یا فضاپیما حاصل بهینهسازی هواپیماست. در طبیعت هم عیناً همین روند حکمفرماست. گونههای متکاملتری وجود دارند که نمیتوان گفت صرفاً حاصل تکامل تدریجی گونه قبلی هستند.
در این میان آنچه شاید بتواند تا حدودی ما را در فهم این مسئله یاری کند مفهومیست به نام تصادف یا جهش.
به عبارتی طرح هواپیما نسبت به طرح اتومبیل یک جهش بود و نه یک حرکت تدریجی. در طبیعت نیز به همین گونهاست. در هر نسل جدید بعضی از خصوصیات به صورتی کاملاً تصادفی تغییر مییابند سپس بر اثر تکامل تدریجی که پیشتر توضیح دادیم در صورتی که این خصوصیت تصادفی شرایط طبیعت را ارضا کند حفظ میشود در غیر اینصورت به شکل اتوماتیک از چرخه طبیعت حذف میگردد.
در واقع میتوان تکامل طبیعی را به اینصورت خلاصه کرد: جستجوی کورکورانه (تصادف یا Blind Search) + بقای قویتر.
حال ببینیم که رابطه تکامل طبیعی با روشهای هوش مصنوعی چیست. هدف اصلی روشهای هوشمندِ به کار گرفته شده در هوش مصنوعی، یافتن پاسخ بهینه مسائل مهندسی است. بعنوان مثال اینکه چگونه یک موتور را طراحی کنیم تا بهترین بازدهی را داشته باشد یا چگونه بازوهای یک ربات را متحرک کنیم تا کوتاهترین مسیر را تا مقصد طی کند (دقت کنید که در صورت وجود مانع یافتن کوتاهترین مسیر دیگر به سادگی کشیدن یک خط راست بین مبدأ و مقصد نیست) همگی مسائل بهینهسازی هستند.
روشهای کلاسیک ریاضیات دارای دو اشکال اساسی هستند. اغلب این روشها نقطه بهینه محلی (Local Optima) را بعنوان نقطه بهینه کلی در نظر میگیرند و نیز هر یک از این روشها تنها برای مسئله خاصی کاربرد دارند. این دو نکته را با مثالهای سادهای روشن میکنیم.
به شکل زیر توجه کنید. این منحنی دارای دو نقطه ماکزیمم میباشد؛ که یکی از آنها تنها ماکزیمم محلی است. حال اگر از روشهای بهینهسازی ریاضی استفاده کنیم مجبوریم تا در یک بازه بسیار کوچک مقدار ماکزیمم تابع را بیابیم. مثلاً از نقطه ۱ شروع کنیم و تابع را ماکزیمم کنیم. بدیهی است اگر از نقطه ۱ شروع کنیم تنها به مقدار ماکزیمم محلی دست خواهیم یافت و الگوریتم ما پس از آن متوقف خواهد شد. اما در روشهای هوشمند، به ویژه الگوریتم ژنتیک به دلیل خصلت تصادفی آنها حتی اگر هم از نقطه ۱ شروع کنیم باز ممکن است در میان راه نقطه A به صورت تصادفی انتخاب شود که در این صورت ما شانس دستیابی به نقطه بهینه کلی (Global Optima) را خواهیم داشت.

بهینه محلی و بهینه کلی
در مورد نکته دوم باید بگوییم که روشهای ریاضی بهینهسازی اغلب منجر به یک فرمول یا دستورالعمل خاص برای حل هر مسئله میشوند. در حالی که روشهای هوشمند دستورالعملهایی هستند که به صورت کلی میتوانند در حل هر مسئلهای به کار گرفته شوند. این نکته را پس از آشنایی با خود الگوریتم بیشتر و بهتر خواهید دید.
نحوه عملکرد الگوریتم ژنتیک روش کار الگوریتم ژنتیک به طور فریبندهای ساده، قابل درک و به طور قابل ملاحظهای روشی است که ما معتقدیم حیوانات آنگونه تکامل یافتهاند. هر فرمولی که از طرح داده شده بالا تبعیت کند فردی از جمعیت فرمولهای ممکن تلقی میشود. الگوریتم ژنتیک در انسان متغیرهایی که هر فرمول دادهشده را مشخص میکنند به عنوان یکسری از اعداد نشان دادهشدهاند که معادل DNA آن فرد را تشکیل میدهند. موتور الگوریتم ژنتیک یک جمعیت اولیه اینگونه است که هر فرد در برابر مجموعهای از دادهها مورد آزمایش قرار میگیرد و مناسبترین آنها باقی میمانند؛ بقیه کنار گذاشته میشوند.
مناسبترین افراد با هم جفتگیری (جابجایی عناصر DNA) و (تغییر تصادفی عناصر DNA) کرده و مشاهده میشود که با گذشت از میان تعداد زیادی از نسلها، الگوریتم ژنتیک به سمت ایجاد فرمولهایی که دقیقتر هستند، میل میکنند. در فرمول نهایی برای کاربر انسانی قابل مشاهده خواهد بوده و برای ارائه سطح اطمینان نتایج میتوان تکنیکهای آماری متعارف را بر روی این فرمولها اعمال کرد که در نتیجه جمعیت را کلاً قویتر میسازند.الگوریتم ژنتیک درمدل سازی مختصراً گفته میشود که الگوریتم ژنتیک یک تکنیک برنامهنویسی است که از تکامل ژنتیکی به عنوان یک الگوی حل مسئله استفاده میکند. مسئلهای که باید حل شوددارای ورودی هایی میباشدکه طی یک فرایند الگو برداری شده از تکامل ژنتیکی به راه حلها تبدیل سپس راه حلها به عنوان کاندید توسط تابع ارزیاب ( fitness function) مورد ارزیابی قرار گرفته و چنانچه شرط خروج مسئله فراهم باشد الگوریتم خاتمه می یابد.
در هر نسل، مناسبترینها انتخاب میشوند نه بهترینها. یک راهحل برای مسئله مورد نظر، با یک لیست از پارامترها نشان داده میشود که به آنها کروموزوم یا ژنوم میگویند. کروموزومها عموماً به صورت یک رشته ساده از دادهها نمایش داده میشوند، البته انواع ساختمان دادههای دیگر هم میتوانند مورد استفاده قرار گیرند. در ابتدا چندین مشخصه به صورت تصادفی برای ایجاد نسل اول تولید میشوند. در طول هر نسل، هر مشخصه ارزیابی میشود و ارزش تناسب (fitness) توسط تابع تناسب اندازهگیری میشود.
گام بعدی ایجاد دومین نسل از جامعه است که بر پایه فرایندهای انتخاب، تولید از روی مشخصههای انتخاب شده با عملگرهای ژنتیکی است: اتصال کروموزومها به سر یکدیگر و تغییر.
برای هر فرد، یک جفت والد انتخاب میشود. انتخابها به گونهایاند که مناسبترین عناصر انتخاب شوند تا حتی ضعیفترین عناصر هم شانس انتخاب داشته باشند تا از نزدیک شدن به جواب محلی جلوگیری شود. چندین الگوی انتخاب وجود دارد: چرخ منگنهدار (رولت)، انتخاب مسابقهای (Tournament) ،… .
معمولاً الگوریتمهای ژنتیک یک عدد احتمال اتصال دارد که بین ۰٫۶ و ۱ است که احتمال به وجود آمدن فرزند را نشان میدهد. ارگانیسمها با این احتمال دوباره با هم ترکیب میشوند. اتصال ۲ کروموزوم فرزند ایجاد میکند، که به نسل بعدی اضافه میشوند. این کارها انجام میشوند تا این که کاندیدهای مناسبی برای جواب، در نسل بعدی پیدا شوند. مرحله بعدی تغییر دادن فرزندان جدید است. الگوریتمهای ژنتیک یک احتمال تغییر کوچک و ثابت دارند که معمولاً درجهای در حدود ۰٫۰۱ یا کمتر دارد. بر اساس این احتمال، کروموزومهای فرزند به طور تصادفی تغییر میکنند یا جهش مییابند، مخصوصاً با جهش بیتها در کروموزوم ساختمان دادهمان.
این فرایند باعث به وجود آمدن نسل جدیدی از کروموزومهایی میشود، که با نسل قبلی متفاوت است. کل فرایند برای نسل بعدی هم تکرار میشود، جفتها برای ترکیب انتخاب میشوند، جمعیت نسل سوم به وجود میآیند و … این فرایند تکرار میشود تا این که به آخرین مرحله برسیم.
شرایط خاتمه الگوریتمهای ژنتیک عبارتند از:
- به تعداد ثابتی از نسلها برسیم.
- بودجه اختصاص دادهشده تمام شود (زمان محاسبه/پول).
- یک فرد (فرزند تولید شده) پیدا شود که مینیمم (کمترین) ملاک را برآورده کند.
- بیشترین درجه برازش فرزندان حاصل شود یا دیگر نتایج بهتری حاصل نشود.
- بازرسی دستی.
- ترکیبهای بالا.
روشهای نمایش
قبل از این که یک الگوریتم ژنتیک برای یک مسئله اجرا شود، یک روش برای کد کردن ژنومها به زبان کامپیوتر باید به کار رود. یکی از روشهای معمول کد کردن به صورت رشتههای باینری است: رشتههای ۰ و ۱. یک راه حل مشابه دیگر کدکردن راه حلها در آرایهای از اعداد صحیح یا اعداد اعشاری است .سومین روش برای نمایش صفات در یک GA یک رشته از حروف است، که هر حرف دوباره نمایش دهنده یک خصوصیت از راه حل است.
خاصیت هر سه روش این است که آنها تعریف سازندهای را که تغییرات تصادفی در آنها ایجاد میکنند را آسان میکنند: ۰ را به ۱ و برعکس، اضافه یا کم کردن ارزش یک عدد یا تبدیل یک به صفر یا برعکس. یک روش دیگر که توسط John Koza توسعه یافت، برنامهنویسی ژنتیک است؛ که برنامهها را به عنوان شاخههای داده در ساختار درخت نشان میدهد. در این روش تغییرات تصادفی میتوانند با عوض کردن عملگرها یا تغییر دادن ارزش یک گره داده شده در درخت، یا عوض کردن یک زیر درخت با دیگری به وجود آیند.
عملگرهای یک الگوریتم ژنتیک
در هر مسئله قبل از آنکه بتوان الگوریتم ژنتیک را برای یافتن یک پاسخ به کار برد به دو عنصر نیاز است:در ابتدا روشی برای ارائه یک جواب به شکلی که الگوریتم ژنتیک بتواند روی آن عمل کند لازم است. در دومین جزء اساسی الگوریتم ژنتیک روشی است که بتواند کیفیت هر جواب پیشنهاد شده را با استفاده از توابع تناسب محاسبه نماید.
شبه کد
1 Genetic Algorithm
2 begin
3 Choose initial population
4 repeat
5 Evaluate the individual fitness of a certain proportion of the population
6 Select pairs of best-ranking individuals to reproduce
7 Apply crossover operator
8 Apply mutation operator
9 until terminating condition
10 endشمای کلی شبه کد 
ایده اصلی
در دهه هفتاد میلادی دانشمندی از دانشگاه میشیگان به نام جان هلند ایده استفاده از الگوریتم ژنتیک را در بهینهسازیهای مهندسی مطرح کرد. ایده اساسی این الگوریتم انتقال خصوصیات موروثی توسط ژنهاست. فرض کنید مجموعه خصوصیات انسان توسط کروموزومهای او به نسل بعدی منتقل میشوند. هر ژن در این کروموزومها نماینده یک خصوصیت است. بعنوان مثال ژن ۱ میتواند رنگ چشم باشد، ژن ۲ طول قد، ژن ۳ رنگ مو و الی آخر. حال اگر این کروموزوم به تمامی، به نسل بعد انتقال یابد، تمامی خصوصیات نسل بعدی شبیه به خصوصیات نسل قبل خواهد بود. بدیهیست که در عمل چنین اتفاقی رخ نمیدهد. در واقع بصورت همزمان دو اتفاق برای کروموزومها میافتد. اتفاق اول جهش (Mutation) است.
«جهش» به این صورت است که بعضی ژنها بصورت کاملاً تصادفی تغییر میکنند. البته تعداد اینگونه ژنها بسیار کم میباشد اما در هر حال این تغییر تصادفی همانگونه که پیشتر دیدیم بسیار مهم است. مثلاً ژن رنگ چشم میتواند بصورت تصادفی باعث شود تا در نسل بعدی یک نفر دارای چشمان سبز باشد. در حالی که تمامی نسل قبل دارای چشم قهوهای بودهاند. علاوه بر «جهش» اتفاق دیگری که میافتد و البته این اتفاق به تعداد بسیار بیشتری نسبت به «جهش» رخ میدهد چسبیدن دو کروموزوم از طول به یکدیگر و تبادل برخی قطعات بین دو کروموزوم است. این مسئله با نام Crossover شناخته میشود. این همان چیزیست که باعث میشود تا فرزندان ترکیب ژنهای متفاوتی را (نسبت به والدین خود) به فرزندان خود انتقال دهند.
روشهای انتخاب
روشهای مختلفی برای الگوریتمهای ژنتیک وجود دارند که میتوان برای انتخاب ژنومها از آنها استفاده کرد. اما روشهای لیست شده در پایین از معمولترین روشها هستند.
انتخاب Elitist
مناسبترین عضو هر اجتماع انتخاب میشود.
انتخاب Roulette
یک روش انتخاب است که در آن عنصری که عدد برازش (تناسب) بیشتری داشته باشد، انتخاب میشود. در واقع به نسبت عدد برازش برای هر عنصر یک احتمال تجمعی نسبت میدهیم و با این احتمال است که شانس انتخاب هر عنصر تعیین میشود.
انتخاب Scaling
به موازات افزایش متوسط عدد برازش جامعه، سنگینی انتخاب هم بیشتر میشود و جزئیتر. این روش وقتی کاربرد دارد که مجموعه دارای عناصری باشد که عدد برازش بزرگی دارند و فقط تفاوتهای کوچکی آنها را از هم تفکیک میکند.
انتخاب Tournament
یک زیر مجموعه از صفات یک جامعه انتخاب میشوند و اعضای آن مجموعه با هم رقابت میکنند و سرانجام فقط یک صفت از هر زیرگروه برای تولید انتخاب میشوند.
بعضی از روشهای دیگر عبارتند از:
- Hierarchical Selection
- Steady-State Selection
- Rank Selection
مثال عملی
در این مثال میخواهیم مسئلهٔ ۸ وزیر را بوسیلهٔ این الگوریتم حل کنیم. هدف مشخص کردن چیدمانی از ۸ وزیر در صفحهٔ شطرنج است به نحوی که هیچیک همدیگر را تهدید نکند. ابتدا باید نسل اولیه را تولید کنیم. صفحه شطرنج ۸ در ۸ را در نظر بگیرید. ستونها را با اعداد ۰ تا ۷ و سطرها را هم از ۰ تا ۷ مشخص میکنیم. برای تولید حالات (کروموزومها) اولیه بصورت تصادفی وزیرها را در ستونهای مختلف قرار میدهیم. باید در نظر داشت که وجود نسل اولیه با شرایط بهتر سرعت رسیدن به جواب را افزایش میدهد (اصالت نژاد) به همین خاطر وزیر i ام را در خانهٔ تصادفی در ستون i ام قرار میدهیم (به جای اینکه هر مهرهای بتواند در هر خانه خالی قرار بگیرد). با اینکار حداقل از برخورد ستونی وزیرها جلوگیری میشود.
توضیح بیشتر اینکه مثلاً وزیر اول را بطور تصادفی درخانههای ستون اول که با ۰ مشخص شده قرار میدهیم تا به آخر. i=۰٬۱، … ۷ حال باید این حالت را به نحوی کمی مدل کرد. چون در هر ستون یک وزیر قرار دادیم هر حالت را بوسیلهٔ رشته اعدادی که عدد k ام در این رشته شمارهٔ سطر وزیر موجود در ستون i ام را نشان میدهد. یعنی یک حالت که انتخاب کردیم میتواند بصورت زیر باشد: ۶۷۲۰۳۴۲۲ که ۶ شمارهٔ سطر ۶ است که وزیر اول که شمارهٔ ستونش ۰ است میباشد تا آخر. فرض کنید ۴ حالت زیر به تصادف تولید شدهاند. این چهار حالت را بعنوان کروموزومهای اولیه بکار میگیریم.
- ) ۶۷۲۰۳۴۲۰
- ) ۷۰۰۶۳۳۵۴
- ) ۱۷۵۲۲۰۶۳
- )۴۳۶۰۲۴۷۱
حال نوبت به تابع برازش fitness function میرسد. تابعی را که در نظر میگیریم تابعی است که برای هر حالت تعداد برخوردها (تهدیدها) را در نظر میگیرد. هدف صفر کردن یا حداقل کردن این تابع است. پس احتمال انتخاب کروموزومی برای تولید نسل بیشتر است که مقدار محاسبه شده توسط تابع برازش برای آن کمتر باشد. (روشهای دیگری نیز برای انتخاب وجود دارد) مقدار برازش برای حالات اولیه بصورت زیر میباشد: (مقدار عدد برازش در جلوی هر کروموزوم (با رنگ قرمز)همان تعداد برخوردهای وزیران میباشد)
- )۶۷۲۰۳۴۲۰ ← ۶
- )۷۰۰۶۳۳۵۴ ← ۸
- )۱۷۵۲۲۰۶۳ ← ۲
- )۴۳۶۰۲۴۷۱ ← ۴
پس احتمالها بصورت زیر است:

در اینجا کروموزومهایی را انتخاب میکنیم که برازندگی کمتری دارند. پس کروموزوم ۳ برای crossover با کروموزومهای ۴ و ۱ انتخاب میشود. نقطهٔ ترکیب را بین ارقام ۶ و ۷ در نظر میگیریم.
۴ و ۳:
- )۱۷۵۲۲۰۷۱
- )۴۳۶۰۲۴۶۳
۱ و ۳:
- )۱۷۵۲۲۰۲۰
- )۶۷۲۰۳۴۶۳
حال نوبت به جهش میرسد. در جهش باید یکی از ژنها تغییر کند.
فرض کنید از بین کروموزومهای ۵ تا ۸ کروموزوم شمارهٔ ۷ و از بین ژن چهارم از ۲ به ۳ جهش یابد. پس نسل ما شامل کروموزومهای زیر با امتیازات نشان داده شده میباشد: (امتیازات تعداد برخوردها میباشد)
- )۶۷۲۰۳۴۲۰ ← ۶
- )۷۰۰۶۳۳۵۴ ← ۸
- )۱۷۵۲۲۰۶۳ ← ۲
- )۴۳۶۰۲۴۷۱ ← ۴
- )۱۷۵۲۲۰۷۱ ← ۶
- )۴۳۶۰۲۴۶۳ ← ۴
- )۱۷۵۳۲۰۲۰ ← ۴
- )۶۷۲۰۳۴۶۳ ← ۵
کروموزوم ۳ کاندیدای خوبی برای ترکیب با ۶ و ۷ میباشد. (فرض در این مرحله جهشی صورت نگیرد و نقطهٔ اتصال بین ژنهای ۱ و ۲ باشد)
- )۶۷۲۰۳۴۲۰ ← ۶
- )۷۰۰۶۳۳۵۴ ← ۸
- )۱۷۵۲۲۰۶۳ ← ۲
- )۴۳۶۰۲۴۷۱ ← ۴
- )۱۷۵۲۲۰۷۱ ← ۶
- )۴۳۶۰۲۴۶۳ ← ۴
- )۱۷۵۳۲۰۳۰ ← ۴
- )۶۷۲۰۳۴۶۳ ← ۵
- )۱۳۶۰۲۴۶۳ ← ۲
- )۴۷۵۲۲۰۶۳ ← ۲
- )۱۷۵۲۲۰۲۰ ← ۴
- )۱۷۵۲۲۰۶۳ ← ۲
کروموزومهای از ۹ تا ۱۲ را نسل جدید میگوییم. بطور مشخص کروموزومهای تولید شده در نسل جدید به جواب مسئله نزدیکتر شدهاند. با ادامهٔ همین روند پس از چند مرحله به جواب مورد نظر خواهیم رسید.
چکیده
انطباق تصویر، یکی از زمینه های بسیار پرکاربرد در پردازش تصویر است که تحقیقات زیادی در این حوزه انجام شده اسـت. انطبـاق تصویر به معنای هم تراز و هم محورکردن دو یـا چنـد تصـویر از شـرایط مختلـف تصـویربرداری اسـت. از کاربردهـای آن مـی تـوان بـه شناسایی تغییرات بین تصاویر، ترکیب تصاویر، تشخیص اشیاء و موزاییک تصاویر اشاره کـرد. در ایـن مقاله، ضـمن معرفـی مفـاهیم انطباق تصویر، تحقیقات مختلف جمع آوری و دسته بندی شده و سوگیری تحقیقات در این زمینه مشخص شده است. عـلاوه بـر ایـن، از طریق چهار دسته آزمایش مختلف جنبه های مختلف انطباق تصویر مورد ارزیابی قرارگرفته است. ایـن مقالـه مـیتوانـد راه گشـای محققین پردازش تصویر در این زمینه بوده و سعی شده است تمام جنبه های این زمینه تحقیقاتی مورد کاوش قرار بگیرد.
ﮐﻠﯿﺪواژه ﻫﺎ
اﻧﻄﺒﺎق ﺗﺼﻮﯾﺮ، ﺷﻨﺎﺳﺎﯾﯽ وﯾﮋﮔﯽ ﻫﺎ، ﺗﻄﺒﯿﻖ، ﺑﺮآورد ﻣﺪل ﺗﺒﺪﯾﻞ، اﻟﮕﻮرﯾﺘﻢ SIFT
مقدمه
اﻧﻄﺒﺎق ﺗﺼﻮﯾﺮ، ﻓﺮآﯾﻨﺪ روی ﻫﻢ ﮔﺬاﺷﺘﻦ دو ﯾﺎ ﭼﻨﺪ ﺗﺼﻮﯾﺮ از ﯾﮏ صحنه است ﮐﻪ در ﺷﺮاﯾﻂ ﻣﺨﺘﻠﻒ ﺗﺼﻮﯾﺮﺑﺮداری (زﻣﺎن ﻫﺎی ﻣﺘﻔﺎوت، زواﯾﺎی ﻣﺘﻔﺎوت، ﺣﺴﮕﺮ ﻫﺎی ﻣﺘﻔﺎوت و ﻧﻮع و ﻣﺎﻫﯿِﺖ ﻣﻨﻄﻘﻪ ی ﺗﺼﻮﯾﺮﺑﺮداری ﺷﺪه) ﮔﺮﻓﺘﻪ ﺷﺪه اﻧﺪ و اﯾﻦ ﻓﺮآﯾﻨﺪ از ﻧﻈﺮ ﻫﻨﺪﺳﯽ، دو ﺗﺼﻮﯾﺮ ﻣﺮﺟﻊ و ﺣﺲ ﺷﺪه را ﻫﻢ ﺗﺮاز می ﮐﻨﺪ. اﯾﻦ ﻓﺮآﯾﻨﺪ، ﯾﮏ ﻣﺮﺣﻠﻪ ی ﭘﯿﺶ ﭘﺮدازش در ﺗﺤﻠﯿﻞ ﺗﺼﺎوﯾﺮاﺳﺖ.
در واﻗﻊ ﺷﺮاﯾﻂ ﻣﺨﺘﻠﻒ ﺗﺼﻮﯾﺮﺑﺮداری ﺳﺒﺐ اﯾﺠﺎد اﺧﺘﻼﻓﺎت ﻗﺎﺑﻞ ﺗﻮﺟﻪ ﺑﯿﻦ ﺗﺼﺎوﯾﺮمی ﺷﻮد و ﺑﻪ ﺻﻮرت ﮐﻠﯽ اﯾﻦ اﺧﺘﻼف را می ﺗﻮان ﺑﻪ ﭼﻬﺎردﺳﺘﻪ ی ﻫﻨﺪﺳﯽ، ﻣﺸﮑﻼت رادﯾﻮﻣﺘﺮی، ﻣﺸﮑﻼت ﺑﺎﻓﺖ و ﺗﻐﯿﯿﺮ ﻣﻨﺎﻇﺮ ﺗﻘﺴﯿﻢ ﮐﺮد. مشکلاتی ﻣﺎﻧﻨﺪ اﺧﺘﻼﻓﺎت ﻣﻘﯿﺎس ﺗﺼﺎوﯾﺮ، اﺧﺘﻼﻓﺎت ﭼﺮﺧﺸﯽ ﺗﺼﺎوﯾﺮ و ﺗﻐﯿﯿﺮ ﺷﮑﻞ ﻫﺎی ﻧﺎﺷﯽ از ﺗﻐﯿﯿﺮ ﻣﻮﻗﻌﯿﺖ اﺧﺬ ﺗﺼﻮﯾﺮ را مشکلات ﻫﻨﺪﺳﯽ ﻣﯽﮔﻮﯾﻨﺪ.
اﯾﻦ اﺧﺘﻼﻓﺎت در ﺗﺼﺎوﯾﺮ پزشکی، ﺑﺮ اﺳﺎس ﺣﺮﮐﺎت ﻏﯿﺮارادی (ﻣﺎﻧﻨﺪ ﺗﻨﻔﺲ، ﺿﺮﺑﺎن ﻗﻠﺐ و…) ﺣﺮﮐﺎت ارادی (ﻣﺎﻧﻨﺪ ﺟﺎﺑﺠﺎﯾﯽ ﺑﯿﻤﺎر) و در ﺗﺼﺎوﯾﺮ دﯾﮕﺮ ﺑﺮ اﺳﺎس ﺣﺮﮐﺖ دورﺑﯿﻦ ﺑﻪ وﺟﻮد ﻣﯽ آﯾﻨﺪ. ﻧﻮﯾﺰ، ﺗﻔﺎوت ﺷﺪت روﺷﻨﺎﯾﯽ، ﻣﻮﻗﻌﯿﺖ ﻣﻨﺎﺑﻊ روﺷﻨﺎﯾﯽ در ﺻﺤﻨﻪ و اﺧﺬ ﺗﺼﻮﯾﺮ درﺣﺴﮕﺮ ﻫﺎ و ﺑﺎﻧﺪﻫﺎی ﻃﯿﻔﯽ ﻣﺘﻔﺎوت، ﺳﺒﺐ اﯾﺠﺎد ﺗﻐﯿﯿﺮاﺗﯽ در ﺷﺪت روﺷﻨﺎﯾﯽ ﺗﺼﻮﯾﺮ می ﺷﻮد ﮐﻪ ﺑﻪ ﻣﺸﮑﻼت رادﯾﻮﻣﺘﺮی ﻣﻌﺮوف می ﺑﺎﺷﻨﺪ. ﺗﺼﺎوﯾﺮ، ﻣﻤﮑﻦ اﺳﺖ دارای ﺳﻄﻮﺣﯽ ﺑﺎ ﺑﺎﻓﺖ ﺿﻌﯿﻒ (ﻣﺎﻧﻨﺪ
درﯾﺎ ) ﺑﺪون ﺑﺎﻓﺖ و ﺑﺎﻓﺖ ﻫﺎی ﺗﮑﺮاری (ﻣﺎﻧﻨﺪ ﺳﺎﺧﺘﻤﺎن ﻫﺎی ﻣﺸﺎﺑﻪ) ﺑﺎﺷﺪ که مشکلات بافت نامیده می شوند. ویژگی های متحرک ( مانند حرکت وسایل نقلیه) و تغییراتی که در اثر گذر زمان در تصاویر (مانند تغییرات فصلی) وجود دارد، سبب تغییرات مناظر می شود. بر اساس مشکلات ذکر شده، جهت افزایش دقت در پردازش تصاویر، ضروری است فرآیند انطباق انجام شود. باید توجه کرد که هریک از الگوریتم های انطباق، تنها برای انطباق نوع مشخصی از تصاویر طراحی شده اند چرا که هر الگوریتم انطباق تصویر تنها برای حل نوع مشخصی از مشکلات هندسی، رادیو متری و مشکلات بافت و غیره کاربرد دارد.
انطباق تصویر، یک مرحله ی پیش پردازش است که در شناسایی تغییرات، ترکیب تصاویر، موازییک تصاویر و غیره کاربرد دارد. با توجه به کاربردهای این فرآیند، هر روز توجه دانشمندان بیشتری را به خود جلب می کند. شکل 1 نمودار تعداد مقالات ژورنالی که در پایگاه های ساینس دایرکت و IEEE بر حسب سال چاپ شده اند را نشان می دهد.

همانطور که در شکل 1 مشاهده می شود، هر سال مقالات بیشتری در زمینه ی انطباق تصویر نسبت به سال های قبل به چاپ رسیده است که این نشان دهنده اهمیت این موضوع می باشد. با این وجود، مقاله مروری فارسی در این زمینه وجود ندارد. هم چنین تعداد اندک مقالات مروری انگلیسی که در این زمینه وجود دارد، متاسفانه به شرح کلی روش ها پرداخته اند و بسیار قدیمی هستند. از طرف دیگر، مقالات مروری که اخیراً نوشته شده اند هم اکثراً مربوط به نوع خاصی از تصاویر پزشکی و در زمینه ی یکی از مراحل انطباق است. در این مقالات، به بررسی مزایا و معایب هریک از الگوریتم های مهم در تصاویر متفاوت (سنجش از دور، تصاویر پزشکی، تصاویر سنجش از دور SAR) پرداخته نشده است. اهمیت و کاربرد روزافزون این زمینه علمی، نشان می دهد که هر پنج سال یک بار باید یک مقاله مروری نوشته شود تا به شرح مزایا و معایب الگوریتم ها و معیارهای ارزیابی جدید در زمینه ی انطباق تصویر پرداخته شود تا بتواند دانشمندان را در جهت ارتقاء عملکرد فرآیند انطباق تصویر راهنمایی کند و راهگشای محققین جدید باشد. این موارد ذکر شده انگیزه ی نگارش مقاله مروری در این زمینه را فراهم می کند.
هدف ما در این مقاله، بررسی رویکردها، شرح روش ها و مراحل انطباق تصویر، توصیف بعضی الگوریتم های مهم و بهبودهایی که در زمینه ی ارتقاء دقت انطباق در آن ها انجام شده است. علاوه بر مرور روش های انطباق، یک سری آزمایش ها بر روی تصاویر طبیعی، تصاویر سنجش از دور اپتیکی و تصاویر چند مودی سنجش از دور جهت بررسی دقت تطبیق انجام می شود.
سازمان دهی مقاله به این صورت است که در بخش دوم به بررسی کاربردهای انطباق تصویر بر اساس شیوه امتساب، در بخش سوم به شرح جزئیات مراحل و روش های انطباق تصویر و در بخش های چهارم و پنجم به ترتیب، به دسته بندی انطباق و بررسی معیارهای ارزیابی انطباق پرداخته می شود.نتایج آزمایشات به منظور ارزیابی الگوریتم ها در بخش ششم و در نهایت به جمع بندی و جهت یابی آینده در بخش هفتم پرداخته می شود.
2- کاربردهای انطباق تصویر
انطباق تصویر، کاربردهای گسترده ای در تصاویر سنجش از دور اپتیکی، پزشکی، بینایی کامپیوتر، تصاویر سنجش از دور SAR و تصاویر طبیعی دارد. در کل، کاربردهای آن را می توان بر طبق شیوه اکتساب تصویر به چهار گروه اصلی، زوایای متفاوت، زمان های متفاوت، حسگرهای متفاوت و انطباق تصویر به مدل تقسیم کرد که در ادامه به شرح مختصر هر یک از آن ها پرداخته می شود.
1-2- زوایای متفاوت
در این دسته، هدف انطباق دو تصویر است که از یک صحنه در زاویای متفاوت گرفته شده اند. در این روش، هدف رسیدن به بعد سوم تصویر، شناسایی یک شیء در تصویر و به دست آوردن اطلاعات کامل تری در مورد آن شیء مدنظر است. از آنجایی که با محدود بودن عدسی های دوربین نمی توان تصاویر پانوراما ایجاد کرد، می توان با استفاده از این روش، چنین تصاویری را ایجاد نمود. در شکل 2 نمونه ای از این نوع انطباق مشاهده می شود.
2-2- زمان های متفاوت
در این دسته، هدف انطباق تصاویری است که از یک صحنه در زمان های متفاوت و تحت شرایط مختلفی گرفته شده است. در اینجا، هدف اصلی یافتن و ارزیابی تغییرات است. در این نوع تصاویر، انطباق تصویر به عنوان یک مرحله پیش پردازش در همه ی الگوریتم های شناسایی تغییرات استفاده می شود. برای مثال، در شبکیه چشم جهت تصویر برداری آنژیوگرافی فلورسین، یک یا دو تصویر قبل از تزریق رنگ سدیم فلورسین و چند عکس بعد از تزریق رنگ سدیم فلورسین در طول فواصل معین گرفته می شود که در شکل 3 نشان داده شده است. جهت شناسایی و ارزیابی آسیب هایی که در شبکیه ایجاد شده، لازم است فرآیند انطباق به عنوان یک مرحله ی پیش پردازش انجام شود.

حسگرهای متفاوت
در این دسته، هدف انطباق تصاویری است که از یک صحنه به وسیله حسگرهای متفاوت و در یک زمان یکسان گرفته شده است که به این نوع تصاویر، تاویر چند مودی می گویند. در این دسته از روش ها، هدف اصلی به دست آوردن اطلاعات کامل تر و دقیق تری از یک صحنه است که در تصاویر پزشکی و سنجش از دور اپتیکی و سنجش از دور SAR کاربرد دارد. برای مثال، تعیین موقعیت آناتومی یک تومور در پزشکی بسیار مهم است. تمایز بین تومور و بافت پیرامون آن، در تصاویر سی تی اسکن(CT) کم است. از طرفی تصاویر MRI توانایی خوبی در به تصویر کشیدن بافت های نرم دارند، در حالی که CT بافت سخت و SPECT ،PET کارکردها و فیزیولوژی را به خوبی در بدن نشان می دهند. استفاده هم زمان از تصاویر چند مودی در کنار هم کمک شایانی در فرآیند تشخیص و درمان برای پزشکان دارد. در این زمینه، طی سالیان متمادی، روش های گوناگون و متنوعی ارائه شده است. در شکل 4 نمونه ای از این نوع انطباق مشاهده می شود.

4-2- انطباق تصویر به مدل
در این دسته، هدف انطباق تصویری است که از یک صحنه با مدل آن گرفته شده است. مدل می تواند یک تصویر کامپیوتری از صحنه باشد. هدف اصلی در این نوع انطباق، مقایسه تصویر با مدل و تهیه اطلس است و برای رسیدن به این منظور، از انطباق بین موضوعی و درون شیوه ای استفاده می شود. یک نمونه ی کاربردی از این دسته، در تصویربرداری پزشکی جهت مقایسه تصویر بیمار با اطلس های دیجیتالی است. پس از بررسی کاربردهای فرآیند انطباق تصویر در این بخش، در بخش بعدی به شرح مراحل انطباق تصاویر پرداخته خواهد شد.

3- انطباق تصاویر و مراحل آن
به صورت کلی، دو روش تعاملی(پایه) و خودکار برای انجام عمل انطباق وجود دارد. در روش تعاملی، یک مجموعه از نقاط کنترلی در تصاویر به صورت دستی انتخاب می شوند و سپس، از این نقاط برای برآورد تابع تبدیل میان دو تصویر و نمونه برداری مجدد استفاده می کنند. این روش نیاز به یک اپراتور ماهر دارد. همچنین، انجام آن خسته کننده، تکراری و بسیار زمان بر است و همچنین با مشکل محدودیت دقت مواجه می شود. یکی دیگر از مشکلات تعاملی، مسئله اختلاف دیدگاه بین متخصصین است که بدین معناست که ممکن است متخصصین در انتخاب نقاط کنترلی اختلاف نظر داشته باشند و نقاط به دست آمده توسط آن ها منحصر به فرد نباشد؛ بنابراین، وجود روش های خودکار در انطباق، یک مسئله ی مهم است و روش های متعددی در این زمینه ارائه شده اند. علیرغم اینکه روش های گوناگونی برای انجام انطباق خودکار تصویر وجود دارد، اما اکثریت آن ها از مراحلی که در شکل 5 مشاهده می شود، تشکیل شده اند که از مهم ترین مراحل انطباق تصویر، شناسایی ویژگی ها و تطبیق میان آن ها است. در ادامه به شرح هر یک از این مراحل پرداخته می شود.

1-3- شناسایی ویژگی ها
به طور کلی روش های انطباق تصویر بر اساس نوع شناسایی ویژگی ها به دو دسته ی روش های مبتنی بر ناحیه و روش های مبتنی بر ویژگی در انطباق خودکار برای شناسایی ویژگی ها تقسیم می شوند که شکل 6 یک جفت تصویر که در آن ویژگی ها شناسایی شده اند را نشان می دهد. در ادامه به شرح هر یک از این روش ها پرداخته می شود.

1-1-3- روش های مبتنی بر ناحیه
روش های مبتنی بر ناحیه، زمانی به کار می روند که تصاویر جزئیات مهم زیادی نداشته باشد. اطلاعات متمایز، به وسیله تفاوت شدت روشنایی مشخص می شوند. در این دسته از روش ها، هیچ ویژگی از تصویر شناسایی نمی شود و این روش ها روی مرحله تطبیق تصویر تأکید بیشتری دارند؛ بنابراین، اولین مرحله انطباق تصویر حذف می شوند. روش های مبتنی بر ناحیه نیاز به فضای جستجو و مقدار اولیه ی مناسب داشته و در مناطق با بافت یکنواخت ضعف دارند که جهت رفع این مشکل روش های مبتنی بر ویژگی پیشنهاد شد.
2-1-3- روش های مبتنی بر ویژگی
در این رویکرد، ویژگی های تصاویر شناسایی می شوند و سپس تطبیق میان آن ها انجام می شود. از این دسته از روش ها، معمولاً زمانی استفاده می شود که اطلاعات ساختار محلی مهم تر از اطلاعات شدت روشنایی باشد. این روش نسبت به انحراف های بین تصاویر پایدار است. یک وِیژگی مناسب برای فرآیند تطبیق این است که باید نسبت به همسایگی های خود متمایز بوده و در میان دیگر وِیژگی ها، منحصر به فرد باشد و مستقل از اعوجاج هندسی و رادیومتری و پایدار در برابر نویز باشد. نوع وِیژگی هایی که در تصاویر انتخاب می شود، بستگی به نوع تصاویر دارد. به طور کلی، در تصاویر سه نوع ویژگی وجود دارد: ویژگی های نقطه ای، ویژگی های خطی و ویژگی های ناحیه ای. در ادامه به شرح هریک از این ویژگی ها پرداخته می شود.
– ویژگی های نقطه ای
گوشه ها و نقاط را می توان به عنوان ویژگی های نقطه ای در نظر گرفت. گوشه ها، نقاطی از تصویر هستند مه تغییرات شدت روشنایی آن ها نسبت به سایر همسایه های آن ها بسیار زیاد است. به طور کلی، برای استخراج ویژگی های نقطه ای نیاز به شناساگرهای گوشه و شناساگرهای کلیدی می باشد که شناساگرهای مُراوِک و هریس و SIFT نمونه ای از این شناساگرها می باشند که در ادامه به بررسی آن ها پرداخته می شود.
شناساگر گوشه مُراوِک
ایده مُراوِک برای تشخیص گوشه، استفاده از یک پنجره ی باینری کوچک (برای مثال 3*3) با مرکزیت پیکسل مورد بررسی است. با حرکت دادن این پنجره در چهار جهت اصلی (u,v) = (1,0) , (1,1) , (-1,-1) , (0, 1) میزان تغییرات شدت روشنایی بررسی می شود. اگر این میزان، در چهار جهت بررسی شده نسبت به سایر همسایه ها بیشتر باشد، آن پیکسل به عنوان گوشه در نظر گرفته می شود. این شناساگر دارای نقاط ضعفی است عبارت اند از:
چون شناساگر مُراوِک از پنجره باینری استفاده می کند، اگر پیکسلی نویزی باشد در مقدار نهایی شدت روشنایی، اثر زیادی می گذارد و ممکن است نقاط گوشه به درستی شناسایی نشوند. شناساگر مُراوِک در چهار جهت، مقدار شدت روشنایی را بررسی می کند در صورتی که نقاط گوشه، نقاطی است که در همه جهات تغییرات شدت روشنایی آن زیاد باشد. برای برطرف کردن نقاط ضعف شناساگر مُراوِک، شناساگر دیگری به نام شناساگر هریس پیشنهاد شده است که در ادامه به بررسی آن پرداخته می شود.
شناساگر هریس
شناساگر هریس توسط کریس هریس در سال 1988 پیشنهاد شد. این شناساگر، برای شناسایی گوشه از یک پنجره دایره ای هموار برای مثال پنجره گوسی استفاده می کند و سپس با استفاده از بسط تیلور، پنجره را در تمام جهت ها حرکت می دهد و مقدار شدت روشنایی را در تمام جهان بررسی می کند. این شناساگر، نسبت به مقیاس تغییر پذیر است یعنی ممکن است یک پیکسل در یک مقیاس تصویر به عنوان گوشه در نظر گرفته شود، اما همان پیکسل در مقیاس دیگر همان تصویر به عنوان گوشه در نظر گرفته نشود. یانگ و همکاران در سال 2013 برای انطباق تصاویر از الگوریتم هریس برای شناسایی ویژگی ها استفاده کردند. ژانگ و همکاران در سال 2013 از الگوریتم هریس برای شناسایی ویژگی ها در انطباق غیر سخت تصاویر ریه که با CT گرفته شده اند، استفاده کردند.
برای حل مشکل نقطه ضعف ذکر شده شناساگر هریس، یک الگوریتم به نام تبدیل ویژگی مقیاس ثابت پیشنهاد شد. در ادامه به بررسی بیشتر این الگوریتم پرداخته می شود.
الگوریتم تبدیل ویژگی مقیاس ثابت
این الگوریتم در سال 2004 توسط لاو جهت انجام فرآیند تشخیص الگو در تصاویر اپتیکی ارائه شده است. الگوریتم SIFT هم شناساگر و هم توصیفگر است که مرحله استخراج ویژگی در آن خود شامل سه مرحله است؛ که مرحله استخراج اکسترمم های فضای مقیاس، بهبود دقت موقعیت و حذف اکسترمم های ناپایدار و در آخر تخصیص جهت به هر ویژگی که ایجاد شده است. الگوریتم SIFT دارای محدودیت هایی است که برای بهبود دادن این الگوریتم جهت ارتقاء دقت انطباق باید به نوع تصویر هم توجه کرد، زیرا انحراف هایی که بین تصاویر وجود دارد، با توجه به ماهیت تصاویر ممکن است، متفاوت باشد. در تصاویر سنجش از دور SAR به دلیل وجود نویز اسپکل و همچنین استفاده از فضای مقیاس گوسی در SIFT باعث می شود اغلب لبه ها و جزئیات ظریف در تصویر از بین برود که تأثیر قابل توجهی در تشخیص ویژگی ها دارد. برای غلبه بر مشکلات ذکر شده در تصاویر سنجش از دور SAR، بهبود هایی در الگوریتم SIFT انجام شده است که در ادامه به بعضی از آن ها اشاره می شود.
فلورا دلینگر و همکاران در سال 2015 جهت بهبود الگوریتم SIFT در تصاویر سنجش از دور SAR روش SAR-SIFT را معرفی کردند. این روش از دو مرحله کلی تشکیل شده است که ابتدا از روش نسبت به جای روش تفاضل برای محاسبه گرادیان استفاده می کند که این سبب می شود مقدار گرادیان در مناطق همگن تحت شرایط بازتاب مختلف فرقی نداشته باشد. سپس برای تطبیق تصاویر سنجش از دور SAR از یک الگوریتم SIFT مانند استفاده می شود که در این الگوریتم، برای شناسایی نقاط کلیدی از فضای مقیاس لاپلاس گوسی و برای تعیین جهت و ایجاد توصیفگرها از یک پنجره ی مدور استفاده می کند. این روش جهت انطباق تصاویر با زاویه متفاوت مناسب نیست. وانگ و همکاران در سال 2012 روش BFSIFT برای انطباق تصاویر سنجش از دور SAR را پیشنهاد کردند. در این روش، برای حفظ جزئیات در تصاویر سنجش از دور SAR فضای مقیاس گوسی ناهمسانگرد جایگزین فضای مقیاس گوسی در الگوریتم SIFT شده است که این فضای مقیاس با استفاده از فیلتر دوطرفه ایجاد شده است. از مزایای این روش، کاهش اثر نویز اسپکل در انطباق تصویر است اما زمان اجرا آن زیاد می باشد. جیان وی فن و همکاران در سال 2015 روش تبدیل ویژگی مقیاس ثابت مبتنی بر انتشار غیرخطی و تجانس فاز را برای انطباق تصویر سنجش از دور SAR پیشنهاد کردند. در این روش از انتشار غیرخطی جهت حفظ جزئیات مهم و ظریف در تصویر و از عملگر نسبت میانگین وزن شده نمایی برای محاسبه اطلاعات گرادیان و سپس از تجانس فاز برای حذف نقاط پرت استفاده می کند. از مزایای این روش، اندازه گرادیان در مناطق همگن تحت شرایط بازتاب مختلف اندکی تفاوت دارد اما برای تعیین جهت گرادیان معیار مناسبی ندارد. فنگ وانگ و همکاران در سال 2015، روش تبدیل ویژگی مقیاس ثابت گوسی ناهمسانگرد وفقی را برای انطباق تصاویر سنجش از دور SAR پیشنهاد کردند. در این روش، از فیلتر گوسی ناهمسانگرد در فضای مقیاس SIFT و تطبیق پایداری جهت گیری متعادل به ترتیب برای حفظ لبه ها و جزئیات مهم تصویر و حذف تطبیق های نادرست استفاده می کند. در این روش لبه ها در تصویر سنجش از دور SAR حفظ می شوند و در نهایت باعث ارتقا دقت انطباق تصویر سنجش از دور SAR می شود اما در این روش اندازه گرادیان در مناطق همگن تحت شرایط بازتاب مختلف، متفاوت است.
الگوریتم SIFT، در تصاویر سنجش از دور اپتیکی، دارای دو مشکل اصلی است که عبارت از کنترل پذیری پایین آن در تعداد ویژگی ها و عدم توجه به کیفیت و توزیع ویژگی های استخراج شده می باشد. ییکی از پارامترهای موثر در کنترل تعداد ویژگی ها در الگوریتم SIFT، میزان آستانه تمایز ویژگی ها (Tc) است که به علت حساسیت بسیار بالای آن در تعداد ویژگی های نهایی استخراج شده، در تصاویر مناسب نیست. در ضمن به علت عدم توجه این الگوریتم به مسئله توزیع مکانی و توزیع مقیاس ویژگی ها در اغلب موارد، پراکندگی ویژگی های استخراج شده، نامناسب است.
در روشی برای استخراج ویژگی های SIFT با توزیع مکانی پیشنهاد شده است که در این روش به جای استخراج اکسترمم های تصویر DOG در همسایگی 26 تایی خود، همسایگی های بزرگتری (66 تایی) پیشنهاد کردند. با وجود مزایای این همسایگی بزرگ عتر، این روش دارای معایبی نیز می باشد. یکی از معایب این است که احتمال دارد باعث حذف بعضی از ویژگی های با کیفیت ولی با ساختار کوچک تصویر شوند. همچنین افزایش پیچیدگی محاسباتی آن نیز، بیشتر از الگوریتم SIFT پایه است. در روش SIFT تکرارشونده
نحوه عملکرد الگوریتم های ایمنی مصنوعی
الگوریتم های مطرح شده در سیستم های ایمنی مصنوعی را می توان به سه دسته تقسیم بندی نمود. دسته اول الگوریتم هایی که بر مبنای انتخاب جامعه سلول های B ایجاد شده اند. دسته دوم الگوریتم هایی که بر مبنای انتخاب معکوس سلول های T ایجاد شده اند. دسته سوم الگوریتم هایی که بر مبنای تئوری شبکه ایمنی بوجود آمده اند.
الگوریتم انتخاب جامعه (Clonal Selection)
این الگوریتم بر مبنای انتخاب جامعه سلول های B ایجاد شده است.بخش های اصلی این الگوریتم شامل شناسایی آنتی ژن، تکثیر و جهش سلول های B (آنتی بادی ها) و ایجاد سلول های حافظه است. در این الگوریتم اکثر سلول ها برای تکثیر انتخاب می شوند اما از همه سلول ها به یک اندازه تکثیر نمی شوند؛ بلکه سلول هایی که میل ترکیبی بیشتری دارند ، بیشتر تکثیر می شوند.
از طرف دیگر سلول هایی که میل ترکیبی کمتری داشته اند بیشتر تغییر می یابند. به بیان دیگر تکثیر نسبت مستقیمی با میل ترکیبی و جهش نسبت عکس با میل ترکیبی دارد. بدین ترتیب میل ترکیبی سلول ها به مرور زمان افزایش یافته و تنوع نیز حفظ می شود.
مراحل الگوریتم انتخاب جامعه
مراحل الگوریتم انتخاب جامعه عبارتند از :


الگوریتم انتخاب معکوس (Negative Selection)
این الگوریتم بر مبنای سلول های T ایجاد شده است.سلول های T می توانند سلول های خودی و غیر خودی را از یکدیگر تشخیص دهند.الگوریتم انتخاب معکوس دو مرحله دارد. مرحله اول که مرحله یادگیری است مشابه کار تیموس را انجام می دهد. یعنی سلول هایی که سلول های خودی را شناسایی می کنند را حذف می کند. مرحله دوم، مرحله نظارت یا اجراء است. در این مرحله الگوها (آنتی ژن ها) با سلول های T باقیمانده از مرحله اول مقایسه شده و در صورت شناسایی حذف می شوند. این الگوریتم در شناسایی الگو و امنیت نظارتی کاربرد دارد.
مراحل الگوریتم انتخاب معکوس
فرض می کنیم S مجموعه الگوهای خودی باشد که باید محافظت شده و مجموعه A نیز محافظ ها می باشند.


با توجه به مراحل فوق این الگوریتم دارای قابلیت یادگیری است. پس از یادگیری از مجموعه A در مرحله نظارت یا اجراء استفاده می شود.در این مرحله هر الگوی ورودی با الگوهای جدیددر مجموعه A مقایسه می شود و در صورتی که میل ترکیبی آنها از یک حد آستانه ای بیشتر شود ، الگوی ورودی به عنوان یک الگوی غیرخودی حذف می شود.
الگوریتم شبکه ایمنی (Immune Network)
الگوریتم انتخاب جامعه دارای چند مشکل است. اول اینکه آنتی بادی های حاصل از این الگوریتم نسبت به آخرین داده های ورودی یعنی آنتی ژن ها تنظیم می شوند. دوم اینکه آنتی بادی ها تمایل دارند که در نزدیکی یکدیگر تجمع کنند.به بیان دیگر چندین آنتی بادی مقداری نزدیک به هم بدست می آورند. الگوریتم شبکه ایمنی مصنوعی این دو نقص الگوریتم انتخاب جامعه را برطرف می نماید.
در یک شبکه ایمنی مصنوعی ، برای آنتی بادی بجز میل ترکیبی با آنتی ژن ، معیارهای ارزیابی دیگری نیز وجود دارد.معیار ارزیابی اصلی در شبکه ایمنی مصنوعی میزان تحریک شدن آنتی بادی است.میزان تحریک آنتی بادی بر مبنای میل ترکیبی آنتی بادی با آنتی بادی های دیگر و میل ترکیبی سایر آنتی بادی ها با آنتی بادی مورد نظر محاسبه می شود.در صورتیکه یک آنتی بادی ، آنتی بادی دیگر یا آنتی ژن را شناسایی کند ، تحریک می شود اما از طرف دیگر شناسایی شدن یک آنتی بادی توسط آنتی بادی دیگر تاثیر بازدارندگی بر روی آن دارد. میزان تحریک یک آنتی بادی بطور کلی از رابطه زیر بدست می آید:
S = Nt – ct + Ag
Nt : میزان تحریک شدن آنتی بادی توسط شبکه است.
ct : میزان بازدارندگی شبکه ای آنتی بادی می باشد.
A : میزان تحریک آنتی بادی توسط آنتی ژن است.
به دلیل هزینه محاسباتی زیاد رابطه فوق ، الگوریتم های مختلفی برای شبکه ایمنی مصنوعی ارائه شده که از نسخه ساده شده رابطه فوق استفاده می نمایند.
مراحل الگوریتم شبکه ایمنی مصنوعی
الگوریتم شبکه ایمنی مصنوعی را می توان بطور کلی به صورت زیر تعریف کرد:


الگوریتم aiNET
الگوریتم های متفاوتی برای شبکه ایمنی مصنوعی مطرح شده است که هر یک از آنها بخش های مختلف را به روش خود تعریف کرده اند. یکی از الگوریتم های معروف؛ الگوریتم aiNET می باشد. طبق تعریف aiNET گرافی وزن دار است که ممکن است کاملا همبند نباشد. گره های این گراف را آنتی بادی ها تشکیل می دهند و وزن لبه ها نمایانگر استحکام ارتباط میان دو گره می باشد. مراحل الگوریتم aiNET عبارتند از :


مراحل ۱،۲ تا ۸،۲ در الگوریتم فوق انتخاب جامعه می باشد. در مرحله ۴،۲ جهش از رابطه ![]() بدست می آید که در آن c’ ماتریس آنتی ژن، c جامعه آنتی بادی ها و ضریب یادگیری یا نرخ جهش است. نرخ جهش در این الگوریتم از حاصل ضرب یک عدد ثابت و یک عدد تصادفی با توزیع یکنواخت در بازه صفرو یک در فاصله آنتی بادی و آنتی ژن بدست می آید.
بدست می آید که در آن c’ ماتریس آنتی ژن، c جامعه آنتی بادی ها و ضریب یادگیری یا نرخ جهش است. نرخ جهش در این الگوریتم از حاصل ضرب یک عدد ثابت و یک عدد تصادفی با توزیع یکنواخت در بازه صفرو یک در فاصله آنتی بادی و آنتی ژن بدست می آید.
در الگوریتم فوق، جامعه سازی متناسب با میل ترکیبی باعث می شود که عمل استخراج در نزدیکی پاسخ به خوبی انجام شود زیرا هرچه آنتی بادی به آنتی ژن نزدیک تر باشد، نمونه های مشابه بیشتری تولید می کند و در نتیجه عمل استخراج بهتری انجام می شود.
جهش نیز با توجه به رابطه ای که بیان شد، منتاسب با عکس میل ترکیبی است. یعنی هرچه میل ترکیبی بیشتر باشد (فاصله کمتر)، جهش ها کوچکتر می شود و عمل استخراج صورت می پذیرد و هرچه میل ترکیبی کمتر باشد (فاصله بیشتر) در نتیجه جهش های برزگتری انجام می شود. بدین ترتیب آنتی بادی هایی که از جواب دور هستند عمل اکتشاف و آنتی بادی هایی که نزدیک جواب هستند عمل استخراج را انجام خواهند داد.
مراحل ۹،۲ و ۴ به ترتیب اعمال بازدارندگی جامعه و شبکه را انجام خواهند داد. در مرحله ۹،۲ الگوریتم عمل بازدارندگی روی مجموعه اعضاء جامعه ایجاد شده برای هر آنتی زن جاری انجام می گیرد و در مرحله ۴ این عمل بر روی تمامی آنتی بادی های شبکه انجام می شود. این دو مرحله باعث می شوند آنتی بادی هایی که آنتی ژن های مشابهی را شناسایی می کنند، حذف شوند.
پارامتر حد آستانه، انعطاف پذیری شبکه، دقت خوشه بندی و میزان اختصاص بودن هر یک از آنتی بادی ها را تعیین می کند. هرچه مقدار کوچکتر باشد، آنتی بادی های شبکه می توانند به هم نزدیکتر شوند و در نتیجه دقت خوشه بندی شبکه و میزان اختصاص بودن بیشتر می شود. از طرف دیگر هرچه اتدازه بزرگتر شود، هر آنتی بادی محدوده بزرگتری را شناسایی می کند و در نتیجه شبکه از نظر حاصل از نظر تعداد آنتی بادی کوچک تر می شود و دقت خوشه بندی آن کمتر می شود.
پس از مرحله ۵ الگوریتم، خروجی شبکه به صورت مجموعه ای از آنتی بادی ها (گره های گراف) و میل ترکیبی آنها (لبه های گراف) بدست می آید که یک گراف کامل است. به منظور انجام عمل خوشه بندی، باید تعدادی از یال های گراف حذف شوند تا گراف خوشه های مختلف گراف از یکدیگر جدا شوند. برای این منظور می توان از مقدار آستانه استفاده کرد اما این روش کارایی ندارد.
در سال ۲۰۰۰ میلادی کاسترو در همایش شبکه های عصبی مصنوعی در ریودژانیروی برزیل، روش دیگری ارائه نمود. در روش کاسترو ابتدا درخت پوشای مینیمم گراف محاسبه شده و سپس یال هایی که مقدار آنها از یال های هم جوارشان به صورت مشخصی بیشتر است حذف می شوند. گره های باقیمانده به یک کلاس تعلق دارند.

معرفی انواع کاربرد سیستم های ایمنی مصنوعی
به طور کلی، سیستمهای ایمنی مصنوعی جزء الگوریتمهای الهام گرفته شده از بیولوژی هستند. این نوع الگوریتمها، الگوریتم هایی کامپیوتری هستند که اصول و ویژگیهای آنها نتیجه بررسی در خواص وفقی و مقاومت نمونهها بیولوژیکی است. سیستم ایمنی مصنوعی نوعی الگو برای یادگیری ماشین است. یادگیری ماشین، توانایی کامپیوتر برای انجام یک کار با یادگیری دادهها یا از روی تجربه است. تعریف کاسترو از سیستم ایمنی عبارتست از :
“سيستم هاي وفقي كه با الهام از ايمونولوژي نظري و توابع، اصول و مدل هاي ايمني مشاهده شده به وجود آمدهاند و برای حل مسائل مورد استفاده قرار میگیرند.”
كاسترو و تيميس سه ویژگی زیر را برای الگوريتم ايمني مصنوعي معرفی نموده اند:
۱٫ در هر الگوريتم ايمني مصنوعي، حداقل بايد يك جزء ايمني مانند لنفوسيت ها وجود داشته باشد.
۲٫ در هر الگوريتم ايمني مصنوعي بايد ايده اي برگرفته از بيولوژي نظري يا تجربي استفاده شود.
۳٫ الگوريتم ايمني مصنوعي طراحي شده بايد به حل مسئله اي كمك كند.
بر اساس سه ویژگی فوق، كاسترو و تيميس، اولين الگوريتم هاي ايمني مصنوعي را در سال ۱۹۸۶ طراحي كردند. در همان سال فارمر مدلی برای تئوری شبکه ایمنی ارائه کرد و بر اساس این مدل اعلام کرد که “سیستم ایمنی قادر به یادگیری، به خاطر سپردن و تشخیص الگوست.” بعد از نظر فارمر، توجه به سیستم ایمنی مصنوعی به عنوان یک مکانیزم یادگیری ماشین شروع شد. پس از آن به تدریج سیستم ایمنی مصنوعی ، در زمینههای مختلف وفق پذیر و جذاب بودن خود را نشان داد.
سیستم ایمنی علاوه بر توانایی تشخیص الگو، صفات دیگری از قبیل یادگیری، حافظه، خود سازماندهی و از منظر مهندسی، خصوصیات دیگری مانند تشخیص بیقاعدگی، تحمل خطا، توزیعپذیری و مقاومت بالا دارا می باشد. از زمان آغاز بحث سیستم ایمنی مصنوعی ، این سیستم برای اهداف متنوعی به کار گرفته شده است. این کاربردها را می توان تحت ۹ عنوان کاربردی دستهبندی نمود. این عناوین کاربردی عبارتند از :
۱٫ تشخیص عیب (Fault Detection)
۲٫ تشخیص ناهنجاری (Anomaly Detection)
۳٫ تشخیص نفوذ (Intrusion Detection)
۴٫ امنیت اطلاعات (Information Security)
۵٫ مسائل بهینه سازی (Optimization Problems)
۶٫ دسته بندی الگوها (Patterns Classification)
۷٫ زمانبندی (Scheduling)
۸٫ خوشه بندی (Clustering)
۹٫ سیستم های یادگیرنده (Learning Systems)
در ادامه به تشریح دو مثال از کاربردهای سیستم ایمنی مصنوعی می پردازیم.
سیستم ایمنی مصنوعی (AIS) قسمت 1
سیستم ایمنی مصنوعی (AIS) قسمت 2
سیستم ایمنی مصنوعی (AIS) قسمت 3
سیستم ایمنی مصنوعی (AIS) قسمت 4
سیستم ایمنی مصنوعی (AIS) قسمت 5
سیستم ایمنی مصنوعی (AIS) قسمت 6
بافتنگار
در علم آمار هیستوگرام یا بافتنگار یک نمودار ستونی و پلهای برای نشان دادن دادهها است.
برای نمونه بافتنگار فراوانی، نمودار مستطیلی با پایهای به پهنای یک واحد بر روی هر مقدار مشاهده شدهاست که ارتفاع هر ستون آن برابر با فراوانی داده مورد نظر همخوانی دارد
نمودار بافتنگار همانند نمودار ستونی است و یگانه اختلافی که بین این دو وجود دارد، نمایش ستونهاست.
در پردازش تصویرها بافتنگار تصویر نموداری است که توسط آن تعداد پیکسلهای هر سطح روشنایی در تصویر ورودی مشخص میشود.
بافتنگار
One of the Seven Basic Tools of Quality
معرفیکننده نخست : کارل پیرسون
کاربرد : توزیع احتمال. To roughly assess the of a given variable by depicting the frequencies of observations occurring in certain ranges of values
نمونهای از یک بافتنگار
در عکاسی
بافتنگار (هیستوگرام) در عکاسی، به عنوان یک عملگر کاربردی مصطلح است و یکی از ابزارهای مفید و کارآمد در دوربینهای عکاسی دیجیتالبهشمار میرود. که با این نام (برای این عملگر) چنین در بین کاربران مصطلح شدهاست و ارتباطی با کارکرد علمی آن ندارد.
بافتنگار به نموداری گفته میشود که فراوانی عناصری که در محور افقی آن قرار دارند را در محور عمودی نشان میدهد. بافتنگار عکس، شدت نور را، از کمترین مقدار تا بیشترین مقدار، در محور افقی و تعداد پیکسلهای هرکدام از آنها را در محور عمودی نشان میدهد.
توجه به بافتنگار، راه بسیار خوبی برای کنترل نوردهیدوربین و تصویر بوجود آمده است
منبع
هیستوگرام تصویر
یک هیستوگرام تصویر از یک تصویر T1 فیلتر شده از یک مغز، پردازش شده توسط نرمافزار مانگو. ۳ قلهٔ مشهود در این نمودار ستونی متعلق به ماده سفید، ماده خاکستری، و CSF (آب نخاع) میباشند. دم سمت چپ متعلق به بقایای جمجمه و چربی پس از حذف به روش پردازش (فیلترینگ) بدست آمده است.
در یک تصویر دیجیتال، مقادیر پیکسلها بیانگر ویژگیهای آن تصویر (مانند میزان روشنایی تصویر و وضوح تصویر) است. هیستوگرام یک تصویر در حقیقت بیان گرافیکی میزان روشنایی تصویر میباشد. مقادیر روشنایی (برای مثال ۰-۲۵۵) در طول محور X بیان شده و میزان فراوانی هر مقدار در محور Y بیان میگردد.
تصویر ۸ بیتی (۰-۲۵۵) در بالا و هیستوگرام همان تصویر در پایین. محور افقی بین ۰ تا ۲۵۵ و محور قائم نشانگر تعداد پیکسلها است.
تصویری که هیستوگرام زیر از آن گرفته شدهاست

منبع
نمودار هیستوگرام تصویر نموداری است که در آن تعداد پیکسل های هر سطح روشنایی در تصویر ورودی مشخص می شود. فرض کنید تصویر ورودی یک تصویر Grayscale با 256 سطح روشنایی باشد ، بنابراین هریک از پیکسل های تصویر در شدت روشنایی در بازه [0..255] می توانند داشته باشند. برای به دست آوردن هیستوگرام تصویر ، با پیمایش پیکسل های تصویر ، تعداد پیکسل های هر سطح روشنایی را محاسبه می کنیم .
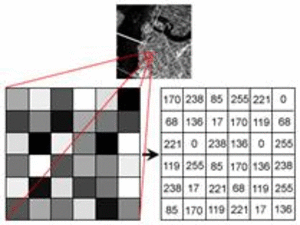
هیستوگرام نرمال نیز از تقسیم کردن مقادیر هیستوگرام به تعداد کل پیکسل های تصویر به دست می آید. نرمال سازی هیستوگرام موجب می شود که مقادیر هیستوگرام در بازه [0,1] قرار گیرند. شکل زیر تصویری را به همراه هیستوگرام نرمال آن نشان می دهد :

تعدیل هیستوگرام ( Histogram Equalization )
به تصویر زیر توجه کنید :
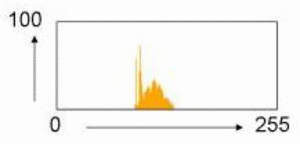
همانطور که از شکل و هیستوگرام تصویر مشخص است ، کنتراست تصویر فوق پایین می باشد. بدین مفهوم که اختلاف کمترین و بیشترین شدت روشنایی کم است. با تعدیل سازی هیستوگرام تصویر با کنتراست پایین ، تصویری با کنتراست بالا به دست می آید :

شکل فوق تصویر قبلی پس از انجام تعدیل سازی هیستوگرام را نشان می دهد. الگوریتم زیر روش تعدیل سازی یکنواخت هیستوگرام را نشان می دهد :
1 ) هیستوگرام تصویر را محاسبه می کنیم. فرض کنید مقادیر هیستوگرام در آرایه hist قرار گیرد.
2 ) با استفاده از فرمول زیر فراوانی هیستوگرام را محاسبه می کنیم :
histCum[ i ] = histCum[ i-1 ] + hist[ i ]
3 ) از فرمول زیر استفاده کرده و هیستوگرام تعدیل شده را محاسبه می کنیم :
eqHist[i] = Truncate( [(L * histCum[i]) – N]/N )
که در این فرمول L تعداد سطوح خاسکتری و N تعداد کل پیکسل ها را نشان می دهد
4 ) در مرحله نهایی مقادیر جدید پیکسل ها را به صورت زیر مقدار دهی می کنیم :
Result[ i , j ] = eqHist[ input[ i , j ] ]
که Result تصویر خروجی و input تصویر ورودی را نشان می دهد
منبع
هیستوگرام به معنی نشان دادن میزان فراوانی مقادیر بر روی نمودار است. در تصویر شما با شدت نور سر و کار دارید که بازه آن برای تصویر خاکستری از 0 تا 255 است یعنی تعداد level ها یا bin ها 256 تا است.
حال اگر تصویر رنگی باشد 3 کانال مجزای خاکستری خواهد بود.
برای محاسبه هیستوگرام می بایست تعداد تکرار یا همون فرکانس شدت ها رو در تصویر محاسبه کرد یعنی تعداد هر شدت نور را در تصویر شمارش کرده و در level یا bin مربوط قرار داد.
نکته ای که وجود دارد این است که همیشه قرار نیست 256 تا bin وجود داشته باشد. می توان 10 تا bin تعریف کرد و در هر بازه هر bin فراوانی ها را با هم جمع کرد.
در OpenCV برای محاسبه هیستوگرام می توان از تابع calcHist استفاده کرد. تابع calcHist می تواند در چند کانال یا چند بعد هم هیستوگرام را محاسبه می کند و بایستی در هر کانال تعداد bin ها را مشخص کرد.
یک مثال عملی از کاربردهای هیستوگرام که ی توان بیان کرد: در فریم های متوالی هیستوگرام را مقایسه کنید مثلا شما قصد دارید چهره شخص را بدون detection در هر فریم تعقیب کنید برای اینکار می توانید از انواع ویژگی های تصویر استفاده کنید از جمله آنها انتقال اطلاعات گردایان بر روی هیستوگرام و هم انتقال اطلاعات شدت نور در کانال ها بر روی هیستوگرام و سپس مقایسه این هیستوگرام با فریم های قبلی.
منبع
منابع
برنامه نویسی Parallel در سی شارپ و آشنایی با کلاس Task در سی شارپ
در قسمت قبل گفتیم که بوسیله کلاس Parallel و متدهای For و ForEach عملیات پردازش بر روی مجموعه ها را به صورت Parallel انجام دهیم. اما بحث Parallel Programming به همین جا ختم نمی شود و راه های دیگری نیز برای برنامه نویسی Parallel وجود دارد. یکی از این روش ها استفاده از کلاس Task است که این کلاس نیز در فضای نام System.Threading.Tasks قرار دارد. حالت های مختلفی برای استفاده از این کلاس وجود دارد که ساده ترین آن استفاده از خصوصیت Factory و متد StartNew است که در زیر نمونه ای از نحوه ایجاد یک Task را مشاهده می کنید:
Task.Factory.StartNew(() = >
{
Console.WriteLine("Task Started in Thread {0}", Thread.CurrentThread.ManagedThreadId);
for (int i = 1; i < = 100; i++)
{
Console.WriteLine(i);
Thread.Sleep(500);
}
});
بوسیله کد بالا، یک Task جدید ایجاد شده که اعداد 1 تا 100 را در یک thread جداگانه در خروجی چاپ می شود. دقت کنید که بعد از اجرای برنامه شناسه Thread ای که Task در آن اجرا می شود با شناسه Thread اصلی برنامه متفاوت است. راهکار بعدی ایجاد یک شئ از روی کلاس Task و ارجرای آن است، در کد زیر Task بالا را به صورت ایجاد شئ ایجاد می کنیم:
Task task = new Task(() = >
{
Console.WriteLine("Task Started in Thread {0}", Thread.CurrentThread.ManagedThreadId);
for (int i = 1; i < = 100; i++)
{
Console.WriteLine(i);
Thread.Sleep(500);
}
});
task.Start();
Console.ReadKey();
زمانی که Task جدیدی ایجاد می کنید بوسیله متد Start که برای کلاس Task تعریف شده است می توانید عملیات اجرای Task را شروع کنید. یکی از خصوصیت های تعریف شده در کلاس Task، خصوصیت IsCompleted است که بوسیله آن می توان تشخیص داد که Task در حال اجراست یا خیر:
Task task = new Task(() = >
{
Console.WriteLine("Task Started in Thread {0}", Thread.CurrentThread.ManagedThreadId);
for (int i = 1; i < = 100; i++)
{
Console.WriteLine(i);
Thread.Sleep(500);
}
});
task.Start();
while (!task.IsCompleted)
{
}
دریافت خروجی از کلاس Task
می توان برای کلاس Task یک خروجی مشخص کرد، فرض کنید می خواهیم Task ای بنویسیم که میانگین حاصل جمع اعداد 1 تا 100 را حساب کرده و به عنوان خروجی بازگرداند. برای اینکار باید از کلاس Task که یک پارامتر جنریک دارد استفاده کنیم. ابتدا یک متد به صورت زیر تعریف می کنیم:
public static int CalcAverage()
{
int sum = 0;
for (int i = 1; i < = 100; i++)
{
sum += i;
}
return sum/100;
}
در قدم بعدی می بایست یک Task جنریک از نوع int تعریف کنیم و به عنوان سازنده نام متد تعریف شده را به آن ارسال کنیم:
Task < int > task = new Task < int > (CalcAverage);
task.Start();
Console.WriteLine("Average: {0}", task.Result);
در کلاس بالا بعد از Start کردن Task، بوسیله خصوصیت Result می توانیم نتیجه خروجی از Task را بگیریم، دقت کنید که زمانی که می خواهیم مقدار خروجی را از Task بگیریم، برنامه منتظر می شود تا عملیات Task به پایان برسد و سپس نتیجه در خروجی چاپ می شود.
به این موضوع توجه کنید که بوسیله متد StartNew نیز می توان Task هایی که پارامتر خروجی دارند تعریف کرد:
var task = Task.Factory.StartNew < int > (CalcAverage);
کد بالا دقیقاً کار نمونه قبلی را انجام می دهد، فقط به جای ایجاد شئ Task و فراخوانی آن، از متد StartNew استفاده کردیم.
ارسال پارامتر به Task ها
یکی از قابلیت های Task ها امکان ارسال State به متدی است که قرار است به عنوان Task اجرا شود. برای مثال، فرض کنید در مثال قبلی که Task ایجاد شده حاصل میانگین را حساب کرده و به عنوان خروجی بر میگرداند می خواهیم عدد شروع و پایان را مشخص کنیم، برای اینکار ابتدا یک کلاس به صورت زیر تعریف می کنیم:
public class TaskParameters
{
public int Start { get; set; }
public int Finish { get; set; }
}
در ادامه کد متد CalcAverage را به صورت زیر تغییر می دهیم:
public static int CalcAverage(object state)
{
var parameters = (TaskParameters) state;
int sum = 0;
for (int i = parameters.Start; i < = parameters.Finish; i++)
{
sum += i;
}
return sum/100;
}
در قدم بعدی باید روند ساخت شئ Task را به گونه ای تغییر دهیم که پارامترهای مورد نظر به عنوان state به متد CalcAverage ارسال شوند، برای اینکار به عنوان پارامتر دوم سازنده کلاس Task شئ ای از نوع TaskParameters به صورت زیر ارسال می کنیم:
Task < int > task = new Task < int > (CalcAverage, new TaskParameters()
{
Start = 100,
Finish = 1000
});
با انجام تغییرات بالا، توانستیم شئ ای را به عنوان State به Task ارسال کنیم، همچنین توجه کنید که امکان ارسال State بوسیله متد StartNew در خصوصیت Factory نیز وجود دارد. در این بخش با کلاس Task آشنا شدیم، در قسمت بعدی با نحوه متوقف کردن Task ها در زمان اجرا و کلاس CancellationToken آشنا می شویم.
منبع
قسمت اول آموزش-برنامه نویسی Asynchronous – آشنایی با Process ها، Thread ها و AppDomain ها
قسمت دوم آموزش- آشنایی با ماهیت Asynchronous در Delegate ها
قسمت سوم آموزش-آشنایی با فضای نام System.Threading و کلاس Thread
قسمت چهارم آموزش- آشنایی با Thread های Foreground و Background در دات نت
قسمت پنجم آموزش- آشنایی با مشکل Concurrency در برنامه های Multi-Threaded و راهکار های رفع این مشکل
قسمت ششم آموزش- آشنایی با کلاس Timer در زبان سی شارپ
قسمت هفتم آموزش-آشنایی با CLR ThreadPool در دات نت
قسمت هشتم آموزش- مقدمه ای بر Task Parallel Library و کلاس Parallel در دات نت
قسمت نهم آموزش- برنامه نویسی Parallel:آشنایی با کلاس Task در سی شارپ
قسمت دهم آموزش-برنامه نویسی Parallel در سی شارپ :: متوقف کردن Task ها در سی شارپ – کلاس CancellationToken
قسمت یازدهم آموزش- برنامه نویسی Parallel در سی شارپ :: کوئری های Parallel در LINQ
قسمت دوازدهم آموزش- آشنایی با کلمات کلیدی async و await در زبان سی شارپ
قسمت سیزدهم آموزش- استفاده از متد WhenAll برای اجرای چندین Task به صورت همزمان در سی شارپ
معرفی سیستم ایمنی مصنوعی(Artificial Immune System)
ایمنی از مولکول ها،سلول ها و قوانینی تشکیل شده که از آسیب رساندن عواملی مانند پاتوژن ها(Pathogens) به بدن جلوگیری می کند، قسمتی از پاتوژن به نام آنتی ژن(Antigen) که توسط این سیستم قابل شناسایی و موجب فعال شدن پاسخ سیستم ایمنی می شود. یک نمونه ای از پاسخ سیستم ایمنی ترشح آنتی بادی توسط سلول های B ،که آنتی بادی ها مولکول های شناساگری به شکل Y هستند که به سطح سلول های B متصل است و با یکسری قوانین از پیش تعریف شده آنتی ژن را شناسایی می کنند. مولکول های آنتی بادی قسمتی از آنتی ژن را به نام اپیتوپ شناسایی می کنند،ناحیه ای از آنتی بادی که وظیفه شناسایی و اتصال به آنتی ژن را دارد پاراتوپ گویند که با نام V شناخته می شود، که به منظور ایجاد بیشترین میزان تطابق با آنتی ژن ها می توانند شکل خود را تغییر دهند و به همین دلیل ناحیه متغیر نامیده می شود.

سطوح سیستم ایمنی
1. اولين سطح – پوست
2. دومین سطح – ايمني فيزيولوژيکي
- اشک چشم ، بزاق دهان ، عرق و …
3. سومین سطح – ایمنی ذاتی
- پاسخ عمومی به آنتی ژن ها
- بسیار کند
4. چهارمین سطح – ایمنی اکتسابی
- پاسخ اختصاصی به آنتی ژن ها
- بسیار سریع

ایمنی ذاتی(Innate Immunity)
سیستم ایمنی ذاتی برای تشخیص و حمله تعداد کمی از مهاجمان تنظیم و برنامه ریزی شده که این سیستم پاتوژن ها را در برخورد اولیه نابود می سازد و سیستم ایمنی اکتسابی برای فعال شدن و ایجاد واکنش نیاز به وقت دارد و وظیفه سیستم ایمنی این است که به سرعت در برابر مهاجمان واکنش نشان می دهد و حمله را تحت کنترل خود قرار داده تا سیستم ایمنی اکتسابی پاسخ موثرتری را فراهم نماید، هنگامی که ایمنی ذاتی فعال می شود فقط برای چند روزی فعال می ماند.

واکنش دستگاه ایمنی ذاتی نسبت به عفونت
ایمنی اکتسابی (Adaptive Immunity)
این ایمنی هنگامی که فعال می شود برای هفته ها فعال می ماند و وظیفه ایمنی اکتسابی این است زمانی که ایمنی ذاتی به هر دلیلی کارآیی ندارد پاتوژن ها را از بین می برد. و ناکارا بودن ایمنی ذاتی یعنی اینکه نمی تواند پاسخ خاصی را برای پاتوژن مهاجم ایجاد کند و سیستم ایمنی اکتسابی وارد عمل می شود که برخلاف سیستم ایمنی ذاتی پاسخ ایمنی اکتسابی خاص و حافظه دارد و زمانی که یکبار پاتوژن به بدن حمله می کند و سیستم پاسخی را برای آن ایجاد می کند و آنرا به خاطر می سپارد و در برخورد های بعدی پاسخ سریع تری را برای مقابله با پاتوژن تولید می کند.
لنفسیت ها (Lymphocytes)
شناسایی آنتی ژن ها برعهده گلبول های سفید خون که لنفسیت نام دارد و دو نوع لنفسیت B و لنفسیت T داریم و در ادامه در مورد هر کدام توضیح خواهیم داد.
لنفسیت های نوع B
سلول های بنیادی که در مغز استخوان تولید می شوند و هر سلول B تعداد گیرنده سلولی (B-Cell Receptor) یا آنتی بادی(Antibody) در سطح خود دارد و هرکدام از این آنتی بادی ها دارای اشکال متفاوتی هستند که هر شکلی شبیه به سلول B را دارند و در نتیجه آنتی بادی هایی که توسط سلول B ساخته شده اند به مجموعه مشابهی از الگوهایی مولکولی متصل می شوند. آنتی بادی های سلول B دو ارزشی و دو عملکردی هستند، دو ارزشی به این دلیل که از طریق دو بازوی Fab به دو آنتی ژن متصل می شوند و از طریق قسمت FC به پذیرنده خاص روی سطح سلول های ایمنی دیگر وصل می شوند. اتصال به آنتی ژن دو نقش را بازی می کند که نقش اصلی آن برچسب زدن به آنتی ژن به عنوان یک مخرب تا مابقی سلول های سیستم ایمنی آن را تخریب کنند به این عملیات آماده مرگ می گویند، این کار با اتصال نواحی Fab آنتی بادی به آنتی ژن صورت می گیرد و ناحیه FC دستنخورده باقی می ماند تا اتصال با سلول های ایمنی دیگر مانند ماکروفاژها(Macrophages) صورت می پذیرد، یک آنتی بادی از دو زنجیره سبک مشابه (L) و دو زنجیره سنگین مشابه (H) تشکیل شده است که در شکل زیر نشان داده شده است.
لنفسیت های نوع T
یکی از چالش های سیستم ایمنی تشخیص سلول های خودی از غیر خودی (عوامل بیماری زا) است زیرا در سطح خارجی سلول های خودی آنتی ژن وجود دارد و وظیفه سلول T تشخیص آنتی ژن های سلول های خودی که به آنها آنتی ژن خودی گفته می شود از آنتی ژن های عوامل بیماری زا که به آن آنتی ژن های غیر خودی گفته می شود. سلول های T از سلول های بنیادی مغز استخوان تولید و وارد خون می شوند سلول های T نابالغ گفته می شود که این سلول های نابالغ از طریق جریان خون وارد غده تیموس می شوند و در این غده بخشی محافظت شده وجود دارد که در آن تنها سلول های خودی وجود دارد که نمی تواند هیچ عامل بیماری زایی در بدن وجود داشته باشد.
سلول های T به چند دسته تقسیم می شوند: دسته اول سلول های T کشنده، زمانی که سلولی را شناسایی می کنند آن را از بین می برند. دسته دیگر سلول های T کمکی، آنتی بادی ها به سلول های B متصل هستند اما سلول های B آنتی ژن های خودی را از آنتی ژن های غیرخودی تشخیص نمی دهند به سلول T احتیاج دارند و پاسخ ایمنی سلول های B زمانی تولید می شود که سلول B و یک سلول T کمکی به طور همزمان یک آنتی ژن را شناسایی می کنند.
ویژگی های سیستم ایمنی بدن
سیستم ایمنی بدن شامل خصوصیاتی که بالطبع سیستم ایمنی مصنوعی از آن پیروی می کند که به صورت خلاصه در مورد هر کدام توضیح داده شده است:
1- قابلیت تشیخص الگو توسط آنتی بادی ها: این تشخیص الگو با استفاده از یک آستانه انجام می شود و زمانی که تحریک الگویی از یک آستانه بالاتر رفت به عنوان یک سلول خودی شناخته می شود.
2- تطبیقی بودن سیستم ایمنی با رخدادها و محیط: بدن انسان با محیط طبیعی خود در ارتباط است و همچنین مواد مفید یا مضر (عوامل بیماری زا) که وارد بدن انسان می شوند متغیر هستند به همین دلیل سیستم ایمنی به صورت پویا با تغییرات برخورد می کند و با وجود تغییر عوامل بیماری زا را تشخیص داده و با آنها مبارزه می کند.
3- قابلیت یادگیری: سیستم ایمنی بدن قادر است که ویروس های جدیدی را که مشاهده می کند به خاطر می سپارد.
4- همکاری گروهی: در سیستم ایمنی سلول ها به صورت گروهی، موازی و توزیع شده برای تشخیص و انهدام همکاری دارند.
5- چند لایه ای بودن: هیچ موجودیتی در سیستم ایمنی بدن انسان یک مکانیزم کامل امنیتی و دفاعی را فراهم نمی کند بلکه هر لایه سیستم ایمنی به صورت مستقل عمل کرده و با بقیه لایه ها در ارتباط است.
6- تنوع و گوناگونی: سیستم ایمنی بدن در برابر انواع مختلفی از نفوذها مقاومت کرده و تسلیم نمی شود.
7- بهینه بودن منابع: در سیستم ایمنی با ایجاد مرگ سلولی و تکثیر سلولی، یک نمونه فضای کوچکی از فضای جستجوی آنتی ژن ها در هر زمان نگه داری می کنند.
8- پاسخ انتخابی: در سیستم ایمنی بدن پس از شناسایی یک آنتی ژن پاسخ های متفاوتی داده می شود که به یک شکل عمل نمی کنند.
9- تنظیم تعداد سلول های ایمنی توسط سیستم ایمنی
سیستم ایمنی مصنوعی
یک الگویی برای یادگیری ماشین است و یادگیری ماشین یعنی توانایی کامپیوتر برای انجام یک کار با یادگیری داده ها از روی تجربه است.
کاربردهای سیستم ایمنی مصنوعی
AIS یکی از الگوریتم های الهام گرفته از سیستم ایمنی بدن انسان است و راه حل هایی را برای مسائل پیچیده ارائه داده اند و از جمله کاربردهای آن عبارتند از:
خوشه بندی (Clustering)
زمانبندی (Scheduling)
تشخیص عیب (Fault Detection)
تشخیص ناهنجاری (َAnomaly Detection)
امنیت اطلاعات (Security Infrmation)
مسائل بهینه سازی (Optimization problems)
دسته بندی الگوها (Patterns Classification)
سیستم های یادگیرنده (Learning system)
تشخیص نفوذ (Intrusion Detection)
مراحل سیستم ایمنی مصنوعی
برای حل مساله با استفاده از AIS باید 3 مرحله زیر انجام پذیرد:
1- نحوه نمایش داده های مساله (تعریف فضای شکل)
2- معیار اندازه گیری میل ترکیبی
3-انتخاب یک الگوریتم ایمنی مصنوعی برای حل مساله
فضای شکل (Shape Space)
سیستم ایمنی بر مبنای شناسایی الگو یا شناسایی شکل آنتی ژن است و می توان این سیسستم را فضایی مملوء از اشکال مختلف تشبیه کرد و هدف پیدا کردن مکمل اشکال و در نتیجه شناسایی آنها است، یعنی پیدا کردن تعدادی شکل بهینه یا آنتی بادی در فضای شکل که مکمل تمامی شکل های موجود در داده های مسئله آنتی ژن است. آنتی ژن ها به صورت آرایه ای از اعداد نمایش داده می شود و هر شیوه های که برای نمایش آنتی ژن استفاده می شود برای نمایش آنتی بادی هم نیز استفاده می شود (نحوه نمایش آنتی بادی و آنتی ژن یکسان است).
نحوه محاسبه و میل ترکیبی آنتی بادی با آنتی ژن
هر چه آنتی بادی میل ترکیبی بیشتری با آنتی ژن داشته باشد یعنی هر چه فاصله آنتی بادی و آنتی ژن کمتر شود مکمل بهتری برای آنتی ژن است و میل ترکیبی را می توان به صورت شباهت آرایه ها در نظر گرفت. که بر همین اساس در الگوریتم AIS از فاصله به عنوان معیار ارزیابی خوب یا بد بودن یک آنتی بادی استفاده می شود.
الگوریتم های AIS
الگوریتم های AIS به 3 دسته تقسیم می شوند:
1- دسته اول الگوریتم هایی که بر مبنای انتخاب کلونی سلول های B ایجاد شده اند.
2- دسته دوم الگوریتم هایی که بر مبنای انتخاب معکوس سلول های T ایجاد شده اند.
3- دسته سوم بر مبنای تئوری شبکه ایمنی ایجاد شده اند.
انتخاب کلونی (Clonal Selection)
زمانی که سلول B آنتی ژن را شناسایی می کند و سلول های B شروع به تکثیر شدن می کنند و تعداد زیادی سلول B یکسان و مشابه تولید می شود، 12 ساعت طول می کشد که یک سلول B رشد کرده و به دو سلول تبدیل شود و بعد از تحریک شدن دوره تکثیر حدودا یک هفته طول می کشد و از یک سلول 2 به توان 14 (16000) سلول مشابه تولید می شود و هر چه میل پیوندی بین سلول B و آنتی ژن بیشتر شود نرخ تکثیر بیشتر خواهد شد، در نتیجه سلول های B با میل پیوندی بالاتر، کلونی بیشتری تولید می کنند که اصل انتخاب کلونی نام دارد.
اصل انتخاب کلونی در AIS الگوریتم خاص خودش را دارد که بعد از تکثیر شدن سلول های B شروع به بالغ شدن می کنند که این فرایند در 3 مرحله صورت می پذیرد:
1- دگرگونی ایزوتایپ
2- بلوغ میل پیوندی
3- تصمیم گیری بین حافظه یا پلاسما شدن سلول B
AIS با دگرگونی ایزوتوپ در گیر نیست ولی دو مرحله بعدی در AIS مهم می باشند. ابرجهش سومانیک قسمتی از بلوغ میل پیوندی که قسمت مهمی در AIS بشمار می آید و جهش میل پیوندی آنتی بادی را می تواند کاهش یا افزایش می دهد.
سلول B در صورتی که به تکثیر ادامه می دهد که جهش باعث افزابش میل پیوندی شده باشد و آنتی بادی به طور مداوم توسط آنتی ژن تحریک می شود و تلاش برای ایجاد سلول های B بهتری دارد که فرایند بلوغ پیوندی نام دارد.گام بعدی فرایند بلوغ پیوندی انتخاب بین حافظه یا پلاسما شدن سلول B است که سلول های پلاسما سازندگان آنتی بادی هستند و در حجم زیادی آنتی بادی ترشح می کنند و عمر زیادی ندارند و حالت دیگر تبدیل سلول های B به سلول های حافظه که این سلول ها میل پیوندی زیادی با آنتی ژن دارند و هدف بخاطر سپردن این آنتی ژن برای آینده است. سلول های حافظه علاوه بر تنظیم شدن به یک نوع خاص آنتی ژن، در آینده هم برای فعال شدن نیاز به تحریک شدن کمتری دارند و در نتیجه سرعت و کارآیی پاسخ ایمنی را زمانی که پاتوژن برای بار دوم به بدن حمله می کند زیاد می شود.

انتخاب معکوس (Negative Selection)
میل ترکیبی سلول های T نابالغ با سلول های موجود در تیموس بررسی می شود و هرکدام از سلول های T نابالغ میل ترکیبی زیادی با یکی از سلول ها داشته باشند حذف می شوند و سایر سلول های T وارد جریان خون می شوند که به این گونه انتخاب در آن برای حدف شدن انتخاب می شود انتخاب معکوس گویند.
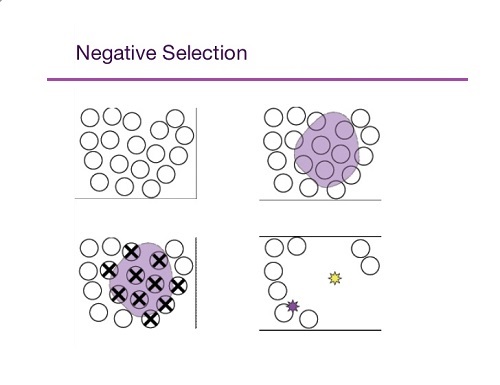
تئوری شبکه ایمنی (Immune Network Theory)
آنتی بادی های موجود بر روی B-Cell ها می توانندعلاوه بر تشخیص آنتی ژن، آنتی بادی را هم می توانند تشخیص بدهند و باعث می شود سیستم ایمنی رفتاری پویا داشته که از آن در AIS استفاده می شود، و بر اساس این تئوری هر آنتی بادی قسمتی به نام ایدوتوپ دارد که توسط آنتی بادی دیگر قابل شناسایی است که در نتیجه آنتی بادی ها با شناسایی کردن یکدیگر سیگنال هایی را ارسال می کنند که می توانند یکدیگر را تحریک کنند و بدین ترتیب این شناسائی و تاثیر گذاری بر روی یکدیگر باعث پویایی شبکه ایمنی مصنوعی می شود. به مجموعه آنتی بادی ها که یکدیگر را شناسایی می کنند شبکه ایمنی یا ایدوتوپی گفنه می شود.

در هر الگوریتم AIS باید به 3 نکته توجه داشت:
1- در هر الگوریتم AIS باید حداقل یک جزء ایمنی مانند لنفسیت باشد.
2- در هر الگوریتم AIS باید ایده ای برگرفته از بیولوژی نظری یا تجربی باشد.
3- الگوریتم AIS که طراحی می شود باید به حل مسئله کمک کند.
مقایسه سیستم ایمنی طبیعی و الگوریتم های ایمنی مصنوعی

برگرفته از پایان نامه بنت الهدی حلمی – دانشگاه علم و صنعت – تحت عنوان استخراج قوانین انجمنی با استفاده از سیستم ایمنی مصنوعی
استخراج قوانین انجمنی با استفاده از سیستم ایمنی مصنوعی
2.برگرفته از مقاله سید امیر احسانی ، امیر مسعود افتخاری مقدم – دانشگاه آزاد اسلامی واحد قزوین – تحت عنوان کاهش معناگری داده با استفاده از سیستم های ایمنی مصنوعی
کاهش معناگری داده با استفاده از سیستم های ایمنی مصنوعی