آشنایی با مدل های مختلف نویز
اختشاشاتی ناشناخته که رفتار آن قابل پیش بینی نبوده و باعث کاهش کیفیت تصویر خروجی میگردند را نویز می نامند. نویز در سنسورهای تصویربرداری دیجیتال امری اجتناب ناپذیر است که منشاء آن نیز می تواند از درون سنسورها ویا محیط اطراف باشد. در ضمن نویز غالب در تمام سنسورها نویز حرارتی است که ناشی از حرکت الکترونها بر اثر گرما می باشد. این نویز در اکثر قطعات الکترونیک بوجود می آید و هر چه این قطعات بیشتر به صورت مداوم کار کنند و گرم تر شوند، نویز غالب در این قطعات، نویز حرارتی خواهد بود. در سنسورهای تصویربردار ما این نویز را به صورت یک فرایند گوسی با میانگین صفر در نظر میگیریم. خطاهای مدل سازی و اندازه گیری دلایل دیگر ورود نویز در تصویر می باشند. روش های مختلفی برای حذف نویز و ترمیم تصویر وجود دارند، اما نکته مهم در طول روند حذف نویز این است که تصویر اصلی و به خصوص جزئیات آن تا حد امکان آسیبی نبیند و ساختار تصویر اصلی حفظ شود. بر این اساس روشهای مختلفی برای حذف نویز مطرح شده است. در ادامه به معرفی انواع متداول نویز در تصویر می پردازیم.
نویز ضربه ای(فلفل نمکی)
تابع چگالی احتمال ۲نویز ضربه ای (دو قطبی) به صورت زیر است:

اگر a > b باشد، شدت روشنایی b به صورت یک نقطه روشن و سطح a به صورت یک نقطه تاریک در تصویر دیده می شود. اگر هر یک از Pa یا Pb صفر باشند، نویز ضرب های حاصل یک قطبی نامیده می شود. اگر هیچ یک صفر نباشند (و به خصوص اگر هر دو تقریبا مساوی باشند) نویز حاصل شبیه پراکندگی ذرات فلفل و نمک بر روی تصویر خواهد بود. به همین علت نویز ضربه ای دو قطبی را نویز فلفل نمکی نیز می خوانند.
ضربه های نویز می توانند مثبت یا منفی باشند. معمولا مقیاس گذاری، بخشی از فرآیند دیجیتال سازی است. از آنجا که آلودگی ضربه ای معمولا نسبت به قدرت سیگنال تصویر بیشتر است، لذا معمولا نقاط نویز ضربه ای بالاترین مقدار(سیاه و سفید) را پس از دیجیتالی شدن پیدا می کنند. بنابراین مقادیر a و b را معمولاً با توجه به مقدار حداقل و حداکثر مجاز در تصویر اشباع شده فرض میکنیم. بنابراین ضربه های منفی به صورت نقاط سیاه(فلفلی) و ضربه های مثبت به صورت نقاط سفید(نمکی) در تصویر مشاهده می شوند. از بهترین فیلترها برای حذف این نوع نویز فیلتر میانه یا فیلتر گوسی است. این فیلترها اگر چه می توانند نویز تصویر را برطرف کنند اما معمولا ًباعث تیره و هموار شدن تصویر و یا لبه های آن می شوند و شرطی برای انجام تغییرات ندارد و همه ی پیکسلها را تغییر می دهد، کاهش نویز به قیمت جابجائی مقادیر پیکسل های غیر نویز با پیکسل های همسایگی می باشد و این به طور کلی منجر به کاهش کیفیت تصویر در نقاط غیر نویز می شود.

نویز گوسی
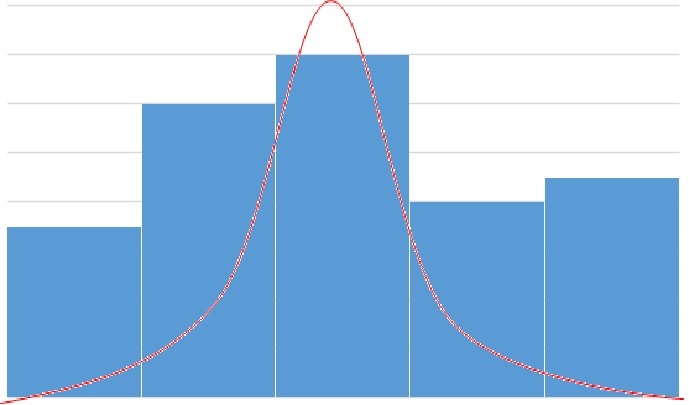
نویز گوسی دارای یک قسمت خرابی در کل تصویر است و با یک تابع گوسی در ارتباط است. به خاطر قابلیت ردگیری ریاضی در حوزههای زمان و فرکانس، از نویز گوسی (که به آن نرمال هم گفته میشود) در عمل استفاده می گردد. در حقیقت این مهارپذیری آن قدر قابل اطمینان است که از این مدل حتی در شرایطی که تنها به طور مرزی قابل اعمال است، نیز استفاده می شود. تابع چگالی احتمال یک متغیر تصادفی گوسی zاز رابطه زیر به دست می آید:

که در آن z نمایان گر شدت روشنایی مقدار میانگین z و σ انحراف استاندارد است. مربع انحراف استاندارد، σ٢ را واریانس z می نامند. وقتی z با معادله بالا مشخص شود، تقریبا ۷۰ درصد مقادیر آن در بازه [(¯ z − σ),(¯ z + σ)] و ۹۵درصد مقادیر آن در بازه [(¯ z − ٢σ),(¯ z + ٢σ)] خواهد بود. یک روش موثر برای حذف نویز گوسی، استفاده از یک ماسک است که بر روی تصویر حرکت می کند و در هر مرحله میانگین همسایه ها در نقطه میانی جای می گیرد.

نویز رایلی
تابع چگالی احتمال نویز رایلی توسط معادله زیر داده می شود:

متوسط و واریانس آن از روابط زیر به دست می آید:


نویز ارلانگ(گاما)
تابع چگالی احتمال نویز ارلانگ، از تابع زیر به دست می آید:

که در آن 0<a, b است. میانگین و واریانس این تابع چگالی به صورت زیر محاسبه می شود:


نویز یکنواخت
تابع چگالی احتمال نویز یکنواخت به صورت زیر می باشد:

و میانگین و واریانس آن به صورت زیر محاسبه می گردند:


![{\displaystyle G_{c}[i,j]=Be^{-{\frac {(i^{2}+j^{2})}{2\sigma ^{2}}}}\cos(2\pi f(i\cos \theta +j\sin \theta ))}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ac164f4a587dd5541627987115efee10136b8147)
![{\displaystyle G_{s}[i,j]=Ce^{-{\frac {(i^{2}+j^{2})}{2\sigma ^{2}}}}\sin(2\pi f(i\cos \theta +j\sin \theta ))}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d14ec475e1f4a49443b3465489ef9a1cf0e233cf)