در پردازش تصویر ، یک فیلتر گابور (Gabor filter) که به نام دنیس گابور نامگذاری شده است، یک فیلتر خطی است که برای تحلیل بافت استفاده می شود، به این معنی که اساساً تحلیل می کند که آیا محتوای فرکانس خاص در تصویر در جهت خاص در یک منطقه محلی در اطراف نقطه یا منطقه تجزیه و تحلیل وجود دارد. بسیاری از دانشمندان دیدگاه معاصر ادعا می کنند که فرکانس و جهت گیری نمایش های فیلترهای گابور شبیه به سیستم بصری انسان می باشند، هرچند هیچ شواهد تجربی و هیچ منطقی عملی برای حمایت از این ایده وجود ندارد. آنها به ویژه برای نمایش و تبعیض بافت مناسب هستند. همچنین در حوزه فضایی، یک فیلتر گابور دوبعدی، یک تابع هسته گاووسی است که توسط یک موج مسطح سینوسی مدولاسیون شده است .
بعضی از نویسندگان ادعا می کنند که سلول های ساده در قشر بینایی مغز پستانداران می توانند توسط توابع گابور مدل شوند. بنابراین، بعضی از آنها تجزیه و تحلیل تصویر با فیلترهای گابور را مشابه با اداراک در سیستم دیداری انسان تصور می کنند.

مثالی از فیلتر گابور دو بعدی
تعریف
پاسخ ضربه آن توسط یک موج سینوسی (یک موج مسطح برای فیلترهای گابور دوبعدی) ضرب در یک تابع Gaussian تعریف می شود. به علت خاصیت پیچیدگی ضرب (تئوری پیچیدگی)، تبدیل فوریه یک پاسخ ضربه ای فیلتر گابور، کانولشنِ[پیچیدگی] تبدیلِ فوریه تابع هارمونیک (تابع سینوسی) و تبدیل فوریه تابع گاوسی است. فیلتر یک واقعیت و یک جزء تخیلی نشانگر مسیرهای متعامد دارد. دو جزء ممکن است به یک شماره پیچیده یا به استفاده ویژه شکل بگیرد.
پیچیده

واقعی

تخیلی

جایی که
و

فیلتر گابور (Gabor filter) چیست؟ قسمت 1
فیلتر گابور (Gabor filter) چیست؟ قسمت 2
فیلتر گابور (Gabor filter) چیست؟ قسمت 3
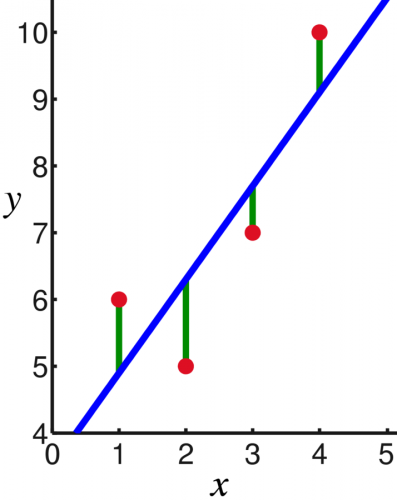
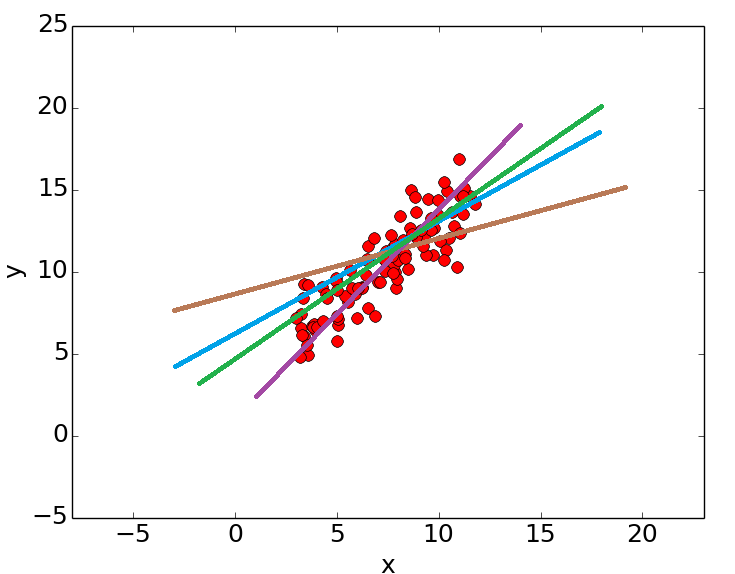

















![{\displaystyle {\vec {x}}=[x_{1},x_{2},\dots ,x_{m}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d3b1b647626fd60d2ac375848a59e57aae6d12dd)

![{\displaystyle {\vec {\beta }}=[\beta _{0},\beta _{1},\cdots ,\beta _{m}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a5be802a8248edf3e91c453006361f3f9ad757be)





![{\displaystyle {\vec {x}}=[1,x_{1},x_{2},\dots ,x_{m}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/14ea41727e52c48f8b37e56ab7179370c2f03ad9)













































































![{\displaystyle {\textbf {M}}_{k}=[{\textbf {F}}_{k}^{-1}]^{\text{T}}{\textbf {Y}}_{k-1\mid k-1}{\textbf {F}}_{k}^{-1}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/df1d3451d696d35e84c33333b62c683567e3767e)
![{\displaystyle {\textbf {C}}_{k}={\textbf {M}}_{k}[{\textbf {M}}_{k}+{\textbf {Q}}_{k}^{-1}]^{-1}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1ad0b932a5546272146c4c2d874cea6d266d7c02)


![{\displaystyle {\hat {\textbf {y}}}_{k\mid k-1}={\textbf {L}}_{k}[{\textbf {F}}_{k}^{-1}]^{\text{T}}{\hat {\textbf {y}}}_{k-1\mid k-1}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/56161975aac46642efa9890137f9a45ff4a2a2f1)








![{\displaystyle {\textbf {K}}^{(i)}={\textbf {P}}^{(i)}{\textbf {H}}^{T}\left[{\textbf {H}}{\textbf {P}}{\textbf {H}}^{\mathrm {T} }+{\textbf {R}}\right]^{-1}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e02c66f8d3bf22f10d743c3497662b6fcebc5c1a)
![{\displaystyle {\textbf {P}}^{(i)}={\textbf {P}}\left[\left[{\textbf {F}}-{\textbf {K}}{\textbf {H}}\right]^{T}\right]^{i}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/52d5f2361eceb8c24128ead213c46bf9459cb85b)



![{\displaystyle {\textbf {P}}_{i}:=E\left[\left({\textbf {x}}_{t-i}-{\hat {\textbf {x}}}_{t-i\mid t}\right)^{*}\left({\textbf {x}}_{t-i}-{\hat {\textbf {x}}}_{t-i\mid t}\right)\mid z_{1}\ldots z_{t}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4b4ac8d1f7b4f501a9c897bd69444613fbb3c019)

![{\displaystyle {\textbf {P}}-{\textbf {P}}_{i}=\sum _{j=0}^{i}\left[{\textbf {P}}^{(j)}{\textbf {H}}^{T}\left[{\textbf {H}}{\textbf {P}}{\textbf {H}}^{\mathrm {T} }+{\textbf {R}}\right]^{-1}{\textbf {H}}\left({\textbf {P}}^{(i)}\right)^{\mathrm {T} }\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/af4ea53ab2cd8bdf01927d86d2660871bef87b52)









































![{\displaystyle {\textbf {x}}_{k-1\mid k-1}^{a}=[{\hat {\textbf {x}}}_{k-1\mid k-1}^{\mathrm {T} }\quad E[{\textbf {w}}_{k}^{\mathrm {T} }]\ ]^{\mathrm {T} }}](https://wikimedia.org/api/rest_v1/media/math/render/svg/81c3778dc0ff51100198d84ec949ff63890eedde)












![{\displaystyle {\textbf {P}}_{k\mid k-1}=\sum _{i=0}^{2L}W_{c}^{i}\ [\chi _{k\mid k-1}^{i}-{\hat {\textbf {x}}}_{k\mid k-1}][\chi _{k\mid k-1}^{i}-{\hat {\textbf {x}}}_{k\mid k-1}]^{\mathrm {T} }}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bda97b30d6eb6352d2850ccb1f02ed6fb5590c68)









![{\displaystyle {\textbf {x}}_{k\mid k-1}^{a}=[{\hat {\textbf {x}}}_{k\mid k-1}^{\mathrm {T} }\quad E[{\textbf {v}}_{k}^{\mathrm {T} }]\ ]^{\mathrm {T} }}](https://wikimedia.org/api/rest_v1/media/math/render/svg/918aa8b55da203aaf75a522f5215febd68827640)

![{\displaystyle {\begin{aligned}\chi _{k\mid k-1}^{0}&={\textbf {x}}_{k\mid k-1}^{a}\\[6pt]\chi _{k\mid k-1}^{i}&={\textbf {x}}_{k\mid k-1}^{a}+\left({\sqrt {(L+\lambda ){\textbf {P}}_{k\mid k-1}^{a}}}\right)_{i},\qquad i=1,\dots ,L\\[6pt]\chi _{k\mid k-1}^{i}&={\textbf {x}}_{k\mid k-1}^{a}-\left({\sqrt {(L+\lambda ){\textbf {P}}_{k\mid k-1}^{a}}}\right)_{i-L},\qquad i=L+1,\dots ,2L\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d7922b33fdfac03c8b9fc4c43959b0c83d971fae)
![{\displaystyle \chi _{k\mid k-1}:=[\chi _{k\mid k-1}^{\mathrm {T} }\quad E[{\textbf {v}}_{k}^{\mathrm {T} }]\ ]^{\mathrm {T} }\pm {\sqrt {(L+\lambda ){\textbf {R}}_{k}^{a}}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/161d62f6b97586538b8d684757230e5ac9cc7526)



![{\displaystyle {\textbf {P}}_{z_{k}z_{k}}=\sum _{i=0}^{2L}W_{c}^{i}\ [\gamma _{k}^{i}-{\hat {\textbf {z}}}_{k}][\gamma _{k}^{i}-{\hat {\textbf {z}}}_{k}]^{\mathrm {T} }}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f55e38a13e3a83e0dcacfbd6c6b6c95068fe7c1d)
![{\displaystyle {\textbf {P}}_{x_{k}z_{k}}=\sum _{i=0}^{2L}W_{c}^{i}\ [\chi _{k\mid k-1}^{i}-{\hat {\textbf {x}}}_{k\mid k-1}][\gamma _{k}^{i}-{\hat {\textbf {z}}}_{k}]^{\mathrm {T} }}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2b9bd8a9088355d99021b592599dfa0ba7fe4098)















![{\displaystyle {\hat {\mathbf {x} }}_{0\mid 0}=E{\bigl [}\mathbf {x} (t_{0}){\bigr ]},\mathbf {P} _{0\mid 0}=Var{\bigl [}\mathbf {x} (t_{0}){\bigr ]}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c94173567081543fbc47f8266b0a06aba70ac122)




