خوشه بندی (Clustering) قسمت 2
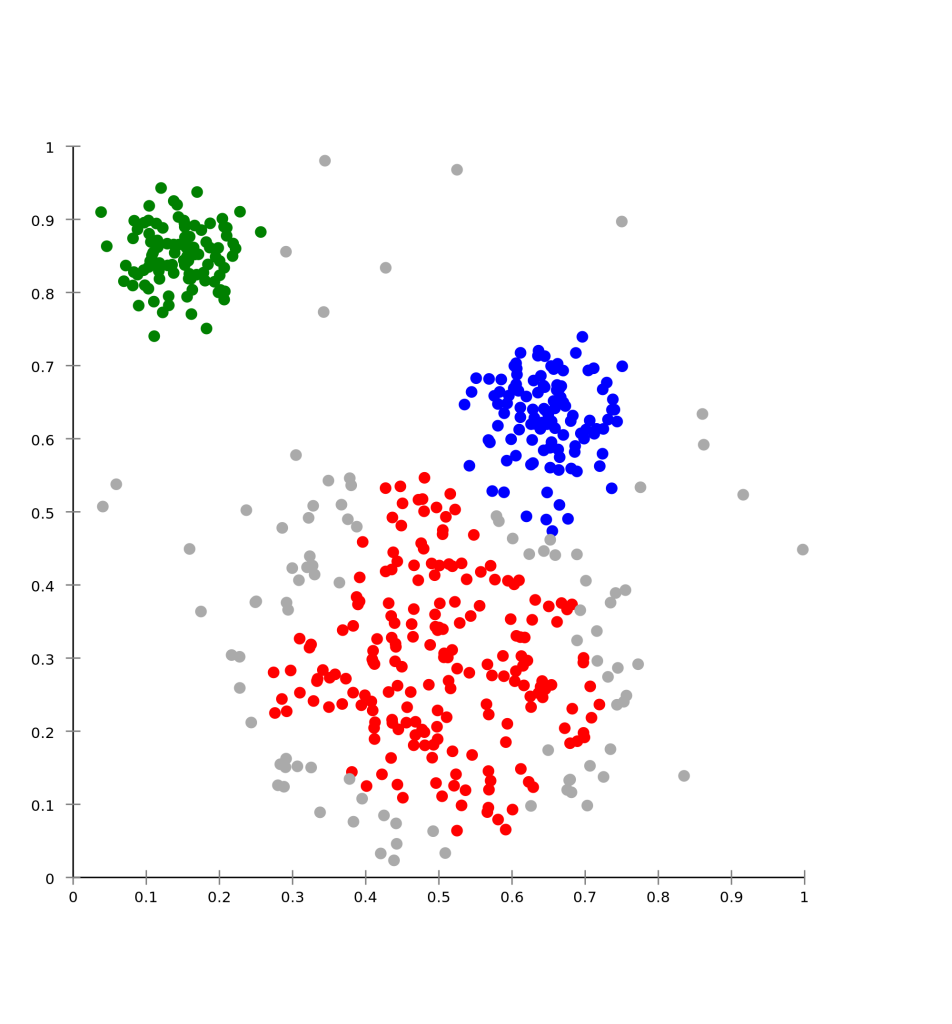
چلامارزیابی مدل خوشهبندی
ارزیابی (یا «اعتبار سنجی») نتایج خوشه بندی به همان اندازه خوشه بندی سخت است. رویکردهای محبوب شامل ارزیابی “درونی” است که در آن خوشه بندی به یک عدد کیفیت واحد خلاصه میشود، ارزیابی “خارجی”، که در آن خوشه بندی با طبقه بندی “ground truth” موجود، ارزیابی “دستی” توسط متخصص و ارزیابی “غیر مستقیم ” با استفاده از خوشه بندی در برنامه مورد نظر مقایسه میشود.
مشکلی که ارزیابی خارجی دارد این است که اگر ما برچسبهای “ground truth” داشته باشیم، دیگر نیازی به خوشه نخواهیم داشت و در برنامههای کاربردی معمولا چنین برچسبهایی را نداریم. از سوی دیگر، برچسبها فقط یک پراکندگی از مجموعه داده نشان میدهد، که به این معنی نیست که خوشه ای متفاوت و شاید حتی بهتر از آن وجود نداشته باشد.
بنابراین هیچکدام از این روشها نهایتا نمیتوانند کیفیت واقعی خوشه بندی را قضاوت کنند، اما اینکار نیاز به ارزیابی انسانی دارد که بسیار ذهنی است.
ارزیابی داخلی
هنگامی که یک نتیجه خوشه بندی ای که بر اساس دادههای خودش خوشه بندی شدهاست، ارزیابی شود، ارزیابی داخلی نامیده میشود.اگر از استاندارد gold استفاده شود، اندازه گیری خارجی نامیده میشوند و در بخش بعدی مورد بحث قرار میگیرد .(اگر متقارن باشد، میتواند اندازه گیری بین خوشه ایی برای ارزیابی داخلی استفاده شود.) روشها معمولا بهترین عدد را برای الگوریتمی که درون خوشه شباهت زیاد و بین خوشهها ، شباهت کم باشد،تولید میکند.این ارزیابی به سمت الگوریتمهایی است که از یک مدل خوشه ای استفاده میکنند. به عنوان مثال، خوشه بندي k-means بهطور طبيعي به فضاهاي شئي بهينه مي كند و معيار داخلي مبتني بر فاصله، احتمالا از خوشه بندي به دست مي آيد.
بنابراین، اقدامات ارزیابی داخلی برای درک وضعیتی که یک الگوریتم بهتر از دیگری عمل میکند، مناسب است، اما این به این معنی نیست که یک الگوریتم نتیجههای معتبرتری را نسبت به دیگری تولید کند.
بیش از دوازده اندازه گیری ارزیابی داخلی وجود دارد. به عنوان مثال، برای ارزیابی کیفیت خوشه بندی میتوان از روشهای زیر استفاده کرد.
شاخص Davies–Bouldin
شاخصDavies–Bouldin را میتوان با فرمول زیر محاسبه کرد:

که n تعداد خوشه و 



شاخصDunn
هدف شاخص Dunn شناسایی خوشههای متراکم و جداسازی آنهاست و به عنوان نسبت بین کمترین فاصله بین خوشه ای تا حداکثر فاصله بین خوشه ای تعریف شدهاست. برای هر قسمت خوشه، شاخص دان را میتوان با فرمول زیر محاسبه کرد:

که d (i، j) فاصله بین خوشههای i و j را نشان میدهد و d ‘(k) فاصله بین خوشه ایی خوشه k را اندازه گیری میکند. فاصله بین خوشه ای d (i، j) بین دو خوشه ممکن است هر تعداد از اندازه گیریهای فاصله، مانند فاصله بین centroids از خوشهها باشد. بهطور مشابه، فاصله بین خوشه ای d ‘(k) ممکن است از روشهای مختلف اندازه گیری شود، مانند فاصله حداکثر بین هر جفت المان در خوشه k.
از آنجایی که معیار داخلی به دنبال خوشههایی با شباهت بین خوشه ای بالا و شباهت بین خوشه ای کم است، الگوریتمهایی که خوشهها را با شاخص Dunn بالایی تولید میکنند بیشتر مطلوب است.
ضریب Silhouette
ضریب Silhouette در مقایسه با فاصله میانگین تا عناصر در خوشههای مشابه با میانگین فاصله تا عناصر در خوشههای دیگر، مقایسه میشود. اشیاء با Silhouette بالا به خوبی خوشه بندی میشوند، اشیاء باSilhouette کم ممکن است ناپایدار باشند. این شاخص با خوشه بندی k-means کار میکند و همچنین برای تعیین تعداد مطلوب خوشهها استفاده میشود.
ارزیابی خارجی
در ارزیابی خارجی، نتایج خوشه بندی بر اساس دادههایی که برای خوشه بندی استفاده نشدند، مانند برچسبهای کلاس شناخته شده و معیارهای خارجی ارزیابی میشود. چنین معیارهایی قبل از طبقه بندی اغلب توسط متخصص تعیین میشود. بنابراین مجموعه معیارها میتواند به عنوان یک استاندارد gold برای ارزیابی استفاده شود. این نوع روشهای ارزیابی اینکه چقدر خوشه بندی به کلاسهای معیاری پیش تعیین شده نزدیک است، را تعیین میکند. با این حال، اینکه آیا این برای دادههای واقعی مناسب است یا فقط بر روی مجموعه دادههای مصنوعی با ground truth است، مورد بحث قرار گرفتهاست ، از آنجا که کلاسها می توانند ساختار داخلی داشته باشند، ویژگیهای موجود ممکن است اجازه جدا شدن خوشهها یا کلاسها را ندهند.
همانند ارزیابی داخلی، چند اندازه گیری برای ارزیابی خارجی وجود دارد که در ادامه چند روش بیان شدهاست.
Purity: خلوص برای خوشههایی که دارای یک کلاس واحد هستند،اندازه گیری میشود.برای محاسبهٔ آن ، برای هر خوشه، تعداد نقاط داده از کلاس معمول در خوشهٔ مورد نظر شمرده میشود ،سپس تمام خوشهها را جمع شده و بر تعداد نقاط داده تقسیم میشود. با توجه به مجموعه ای از خوشههای M و برخی از مجموعه ای از کلاسهای D، هر دو پارامتر با N نقطه داده، خلوص را میتوان به صورت زیر تعریف کرد:

اندازه گیری رند (ویلیام رند، 1971)
شاخص رند اینکه خوشهها (که توسط الگوریتم خوشه بندی بازمی گردند) به معیار طبقه بندیها چقدر شبیهاند را محاسبه میکند. همچنین می توانید شاخص رند را به عنوان اندازه گیری درصد تصمیمات درست که توسط الگوریتم ساخته شدهاست را استفاده کرد. که میتوان با استفاده از فرمول زیر محاسبه کرد:

TP تعداد مثبت صحیح و TN تعداد منفی صحیح وFP تعداد مثبت کاذب وFN تعداد منفیهای کاذب میباشد .
اندازه گیری F
اندازه گیری F را میتوان برای تعادل مشارکت منفیهای کاذب با استفاده از وزن دادن از طریق پارامتر β≥0 استفاده کرد.


که pنرخ دقت و R نرخ فراخوان است. F را با استفاده از فرمول زیر محاسبه شدهاست:

شاخص Jaccard
شاخص Jaccard برای اندازه گیری شباهت بین دو مجموعه داده استفاده میشود. شاخص Jaccard مقداري بين 0 و 1 دارد. شاخص 1 بدين معني است که دو مجموعه داده يکسان هستند و شاخص 0 نشان مي دهد که مجموعه دادهها هيچ عنصر مشترکي ندارند. شاخص Jaccard توسط فرمول زیر تعریف میشود:

شاخص Dice
اندازه گیری متقارنDice دو برابر وزن TP است در حالی کهTN نادیده گرفته میشود و برابر با F1 است – اندازه گیری F با β = 1 :

شاخص Fowlkes-Mallows (E. B. Fowlkes & C. L. Mallows 1983)
شاخص Fowlkes-Mallows شباهت میان خوشههای بازگشتی توسط الگوریتم خوشه بندی و معیارهای طبقه بندی را محاسبه میکند. هر چه مقدار شاخص Fowlkes-Mallows بیشتر باشد خوشهها و معیارهای طبقه بندی مشابه هستند.این شاخص را میتوان با استفاده از فرمول زیر محاسبه کرد:

کهTP تعداد مثبت واقعی وFP تعداد مثبت کاذب وFN تعداد منفیهای کاذب است. FM شاخص میانگین هندسی دقت و فراخوانی P, R است و همچنین به عنوان اندازه گیری G شناخته شدهاست، در حالی که اندازه گیری F میانگین هارمونیک آنها است. علاوه بر این، دقت و یادآوری نیز به عنوان شاخص والاس 

اطلاعات متقابل، اندازه گیری نظری اطلاعاتی است که چقدر اطلاعات بین خوشه بندی و طبقه بندی ground-truth است که میتواند تشابه غیر خطی بین دو خوشه بندی را تشخیص دهد.
ماتریسconfusion
یک ماتریس confusion میتواند برای به سرعت نتایج یک طبقه بندی (یا خوشه بندی) الگوریتم را نمایش دهد و نشان میدهد که چگونه یک خوشه از خوشه استاندارد gold متفاوت است.
تمایل خوشه
هدف از اندازه گیری تمایل خوشه،این است که چه درجه ای خوشهها در دادههای خوشه بندی شده وجود داردو ممکن است قبل از تلاش برای خوشه سازی به عنوان یک آزمون اولیه انجام شود. یکی از راههای انجام این کار این است که دادهها با دادههای تصادفی مقایسه شود. در اصل ،دادههای تصادفی نباید خوشه ای داشته باشند.
آمار Hopkins
فرمولهای متعدد از آمار هاپکینز وجود دارد. یک نمونه به این صورت میباشد که : X مجموعه ای از n نقاط داده درd بعد است. یک نمونه تصادفی (بدون جایگزینی)
m≪n با اعضای xi را در نظر بگیرید .همچنین یک مجموعه Y از m نقطه داده با توزیع یکنواخت رندوم یکنواخت تولید کنید.دو فاصله اندازه گیری، ui فاصله از yi∈Y از نزدیکترین همسایه اش در X و {\displaystyle w_{i}}

کاربرد
زیست شناسی، زیستشناسی محاسباتی و بیوانفورماتیک
بومشناسی گیاه و حیوانات
تجزیه و تحلیل خوشه ای برای توصیف و مقایسه مقادیر مکانی و زمانی جوامع ارگانیسمها در محیطهای ناهمگن استفاده میشود؛ از آن نیز در سیستماتیک گیاه برای تولید phylogenies مصنوعی یا خوشههای ارگانیسم (افراد) در گونه، جنس و یا سطح بالاتر که دارای تعدادی از ویژگیهای مشترک است، استفاده میشود.
Transcriptomics
خوشه بندی برای ساخت گروهی از ژنها با الگوی بیان مربوطه به عنوان الگوریتم خوشه بندی HCS استفاده میشود. اغلب این گروهها حاوی عملکرد پروتئینهای مرتبط هستند، مانند آنزیمها برای یک مسیر خاص، یا ژنهایی که هم تنظیم میشوند. آزمایشات با توان بالا با استفاده از نشانگرهای ترتیبی بیان شده (ESTs) یا میکروآرایههای DNA میتواند یک ابزار قدرتمند برای حاشیهنویسی ژنوم، یک جنبه عمومی ژنومیک باشد.
تجزیه و تحلیل متوالی
خوشه بندی برای دسته بندی توالیهای همولوگ به خانوادههای ژن ،مورد استفاده قرار میگیرد.بهطور کلی این مفهوم بسیار مهمی در بیوانفورماتیک و زیستشناسی تکاملی است.
سیستم عاملهای ژنوتایپ با بازده بالا
الگوریتم خوشه بندی بهطور خودکار برای تعیین ژنوتیپها استفاده میشود.
خوشه بندی ژنتیک انسانی
شباهت دادههای ژنتیکی در خوشه بندی برای به دست آوردن ساختار جمعیت استفاده میشود.
پزشکی
تصویربرداری پزشکی
در PET، تجزیه خوشه ای میتواند برای تمایز بین انواع مختلف بافت در یک تصویر سه بعدی برای بسیاری از اهداف مختلف مورد استفاده قرار گیرد.
تجزیه و تحلیل فعالیت ضد میکروبی
تجزیه خوشه ای میتواند برای تجزیه و تحلیل الگوهای مقاومتی آنتی بیوتیکی، طبقه بندی ترکیبات ضد میکروبی مطابق با مکانیسم عمل آن ها، طبقه بندی آنتی بیوتیکها بر اساس فعالیت ضد باکتری آنها استفاده شود.
بخش بندی IMRT
خوشه بندی میتواند برای تقسیم یک نقشه فلوئنسی به مناطق مجزا برای تبدیل به زمینههای قابل ارائه در پرتودرمانی براساس MLC استفاده شود.
کسب و کار و بازاریابی
تحقیقات بازار
تجزیه و تحلیل خوشه ای در تحقیقات بازار بهطور گسترده در کار با دادههای چندمتغیره از نظرسنجیها و پانلهای آزمایش استفاده میشود. محققان بازار از تحلیل خوشه ای استفاده میکنند تا جمعیت عمومی مصرف کنندگان را به بخشهای بازار تقسیم کنند و به درک بهتر روابط بین گروههای مختلف مصرف کنندگان / مشتریان بالقوه و برای استفاده در تقسیم بندی بازار، موقعیت محصول، توسعه محصول جدید و انتخاب تست بازار کمک میکند.
گروه بندی اقلام خرید
خوشه بندی را میتوان برای دسته بندی تمام اقلام خرید موجود در وب به مجموعه ای از محصولات منحصر به فرد استفاده کرد. به عنوان مثال، تمام اقلام در eBay را میتوان به محصولات منحصر به فرد گروه بندی کرد.
وب جهان گستر
تجزیه و تحلیل شبکه اجتماعی
در مطالعه شبکههای اجتماعی، خوشه بندی ممکن است برای تشخیص ارتباط جوامع در گروههای بزرگ مردم استفاده شود.
گروه بندی نتایج جستجو
در فرایند گروه بندی هوشمند از فایلها و وب سایت ها، خوشه بندی ممکن است برای ایجاد یک مجموعه مناسب تر از نتایج جستجو در مقایسه با موتورهای جستجوی معمول مانند Google استفاده شود. در حال حاضر تعدادی از ابزارهای خوشه سازی مبتنی بر وب مانند Clusty وجود دارد.
بهینه سازی نقشه Slippy
در نقشه Flickr از عکسها و سایر krai سایتها از خوشه بندی برای کاهش تعداد نشانگرها در یک نقشه استفاده شدهاست. این باعث میشود که هر دو سریعتر و میزان خطای بصری را کاهش دهد.
علوم کامپیوتر
تکامل نرم افزار
خوشه بندی در تکامل نرم افزار مفید است، زیرا آن را با اصلاح قابلیتهایی که پراکنده شدهاست، کمک میکند تا خواص میراث را در کد کاهش دهد. این یک نوع بازسازی است و از این رو، راه مستقیم نگهداری پیشگیرانه است.
بخش بندی تصویر
خوشه بندی میتواند برای تقسیم یک تصویر دیجیتال به مناطق مشخص برای تشخیص مرز یا تشخیص شی مورد استفاده قرار گیرد.
الگوریتمهای تکاملی
خوشه بندی ممکن است برای شناسایی nichهای مختلف در جمعیت یک الگوریتم تکاملی استفاده شود تا فرصت تولید مجد را بهطور یکنواخت تر بین گونهها یا گونههای در حال رشد توزیع کرد.
سیستم توصیه گر
سیستمهای توصیه شده به منظور توصیف ایتم جدید بر اساس سلیقه کاربر طراحی شدهاند. گاهی اوقات از الگوریتم خوشه بندی برای پیشبینی ترجیحات کاربر بر اساس ترجیحات دیگر کاربران در خوشه کاربر استفاده میکنند.
روش مارکوف مونت کارلو زنجیره ای
خوشه بندی اغلب برای تعیین مکان و تشخیص اکسترمم در توزیع هدف، مورد استفاده قرار میگیرد.
تشخیص ناهنجاری
ناهنجاریها معمولا – به صراحت یا بهطور ضمنی – با توجه به ساختار خوشه ای در دادهها تعریف میشود.
علوم اجتماعی
تجزیه و تحلیل جرم
از تجزیه و تحلیل خوشه ای میتوان برای شناسایی مناطق که در آن موارد بیشتر از انواع خاصی از جرم وجود دارد استفاده شود. با شناسایی این مناطق متمایز یا “hot spot” که جرم مشابهی در طی یک دوره زمانی اتفاق افتاده است، میتوان منابع اجرای قانون را بهطور مؤثرتر مدیریت کرد.
داده کاوی آموزشی
به عنوان مثال، تجزیه و تحلیل خوشه ای برای شناسایی گروههای مدارس یا دانشجویانی با ویژگی مشابه استفاده میشود.
تایپولوژی ها
در دادههای نظرسنجی، پروژههایی نظیر آنچه که توسط مرکز تحقیقاتی Pew انجام شده، از تجزیه و تحلیل خوشه ای استفاده میکنند تا نوعشناسی عقاید، عادتها و جمعیت شناسایی را که ممکن است در سیاست و بازاریابی سودمند باشد، شناسایی کند.
و کاربردهای دیگر
در زمینه رباتیک
الگوریتم خوشه بندی برای آگاهی موقعیت رباتیک برای ردیابی اشیاء و تشخیص خروجیها در دادههای سنسور استفاده میشود.
شیمی محاسباتی
به عنوان مثال، برای پیدا کردن شباهت ساختاری و غیره، به عنوان نمونه، 3000 ترکیب شیمیایی در فضای 90 شاخص توپولوژیکی ،خوشه بندی شدند.
اقلیم شناسی
برای پیدا کردن آب و هوایی و یا الگوهای فشار جو در سطح دریا مورد نظر است.
زمینشناسی نفت
تجزیه و تحلیل خوشه ای برای بازسازی دادههای اصلی ازدست رفته سوراخ پایین یا منحنیهای لگاریتمی از دست رفته به منظور بررسی خواص مخزن استفاده میشود.
جغرافیای فیزیکی
خوشه بندی خواص شیمیایی در مکانهای مختلف نمونه.
منبع
خوشه بندی (Clustering) قسمت 1
خوشه بندی (Clustering) قسمت 2
خوشه بندی (Clustering) قسمت 3
دیدگاه خود را ثبت کنید
تمایل دارید در گفتگوها شرکت کنید؟در گفتگو ها شرکت کنید.