تولید Deepfake سخنگو از تصویر

هوش مصنوعی جدید وحشت آور سامسونگ می تواند Deepfakeهای سخنگو از یک تصویر تولید کند.
مشکل deepfake ما در مورد بدتر شدن است: مهندسان سامسونگ در حال حاضر سرهای سخنگوی واقع گرایانه ای را توسعه داده اند که می تواند از یک تصویر تولید شود، بنابراین AI حتی می تواند کلمات را در دهان مونا لیزا قرار دهد.
الگوریتم های جدید که توسط یک تیم از مرکز AI سامسونگ و موسسه علوم و فناوری Skolkovo توسعه یافته است، هر دو در مسکو به بهترین وجه با انواع تصاویر نمونه گرفته شده در زوایای مختلف کار می کنند، اما آنها می توانند تنها با یک تصویر برای کار کردن، حتی یک نقاشی، کاملا موثر باشند.

مدل جدید نه تنها می تواند از یک پایگاه داده اولیه کوچکتر از تصاویر استفاده کند، هم چنین می تواند طبق نظر محققان پشت آن، فیلم های کامپیوتری را در مدت کوتاه تری تولید کند.
و در حالی که همه انواع برنامه های جالب وجود دارد که از تکنولوژی می توان برای آن استفاده کرد – مانند قرار دادن یک نسخه فوق واقع گرایانه از خودتان در واقعیت مجازی – این نگرانی وجود دارد که فیلم های ویدئویی کاملاً تقلبی را می توان از یک تصویر کوچک تولید کرد.
محققان در مقاله خود نوشتند: “چنین توانایی دارای کاربردهای عملی برای تلوزیون است،، از جمله ویدئو کنفرانس و بازی های چند نفره، و همچنین صنعت جلوه های ویژه.”

سیستم با آموزش خود در مجموعه ای از ویژگی های چهره برجسته کار می کند که پس از آن می تواند دستکاری شود. بسیاری از آموزش ها بر روی یک پایگاه داده قابل دسترس عمومی از بیش از 7000 تصویر از افراد مشهور، به نام VoxCeleb، و همچنین تعداد زیادی از فیلم ها از صحبت کردن مردم با دوربین انجام شده است.
از آنجا که این رویکرد جدید کار گذشته را با آموزش دادن به شبکه عصبی در مورد چگونگی تبدیل ویژگی های چهره برجسته به فیلم های متحرک با نگاه واقع گرایانه، بیش از چندین بار، بهبود می دهد. سپس این دانش می تواند بر روی چند عکس (یا فقط یک عکس) از کسی که AI قبل از آن هرگز ندیده است، مستقر شود.
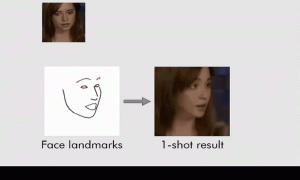
این سیستم از یک شبکه عصبی کانولوشن، یک نوع شبکه عصبی بر اساس فرآیندهای بیولوژیکی در قشر بینایی حیوان استفاده می کند. این منحصراً در پردازش پشته های تصاویر و شناخت آنچه در آنها متخصص است – “convolution” اساساً بخش هایی از تصاویر را شناسایی و استخراج می کند (آن همچنین برای نمونه، در جستجوهای تصویری در وب و تکنولوژی خودرو خود راننده استفاده می شود).
همانند سایر ابزارهای تولید چهره هوش مصنوعی گرا که ما شاهد آن هستیم، آخرین مرحله در این فرآیند برای “واقع گرایی کامل” مورد بررسی قرار می گیرد – از لحاظ فنی یک مدل مولد رقابتی. هر فریمهایی که بیش از حد عجیب و غریب و غیر طبیعی هستند، دوباره برش داده و ارائه میشوند، ویدئو نهایی با کیفیت بهتر را به نمایش میگذارند.
این تکنیک موفق به غلبه بر دو مشکل بزرگ در سرهای سخنگوی تولید شده مصنوعی شده است: پیچیدگی سرها (با دهان ها، مو، چشم ها و غیره) و توانایی ما در به راحتی کشف کردن یک سر جعلی (به عنوان مثال، چهره های شخصیتی در میان سخت ترین عناصر برای طراحان بازی ویدیویی برای درست کردن هستند).
سیستم و دیگران مانند آن، برای بهتر شدن محدود می شوند به طوریکه الگوریتم ها بهبود یابند و مدل های آموزشی موثرتر شوند – و این بدان معنی است که مجموعه ای کامل از سوالات در مورد اینکه آیا می توانید به آنچه که می بینید یا می شنوید اعتماد کنید، اگر در فرم دیجیتال باشد.
از طرف دیگر، ستاره های تلویزیون و فیلم مورد علاقه شما هرگز نباید رشد کنند و بمیرند – AI شبیه به این است که به زودی به اندازه کافی هوشمند خواهد بود تا نمایش های کاملا واقعی را فقط از چند عکس تولید کند و همچنین در زمان ذخیره.

دیدگاه خود را ثبت کنید
تمایل دارید در گفتگوها شرکت کنید؟در گفتگو ها شرکت کنید.