داده ها در اعماق زندگی روزانه ما ریشه دوانده اند، از خرید روزانه تا انتخاب مدرسه و پزشک و مسافرت های ما امروزه داده محور شده اند. این امر نیاز به الگوریتم ها وروشهای هوشمند پردازش داده و یادگیری ماشین را صد چندان کرده است .در این آموزش، بیشتر بر مفاهیم اصلی و الگوریتم ها تاکید شده است و مفاهیم ریاضی و آماری را باید از سایر منابع فرابگیرید .
انواع الگوریتم های یادگیری ماشین
سه نوع اصلی الگوریتم های یادگیری ماشین از قرار زیرند :
یادگیری نظارت شده (هدایت شده – Supervised Learning) : در این نوع از الگوریتم ها که بار اصلی یادگیری ماشین را بر دوش می کشند (از لحاظ تعداد الگوریتم های این نوع)، با دو نوع از متغیرها سروکار داریم . نوع اول که متغیرهای مستقل نامیده میشوند، یک یا چند متغیر هستند که قرار است بر اساس مقادیر آنها، یک متغیر دیگر را پیش بینی کنیم. مثلا سن مشتری و تحصیلات و میزان درآمد و وضعیت تاهل برای پیش بینی خرید یک کالا توسط یک مشتری ، متغیرهای مستقل هستند. نوع دوم هم متغیرهای وابسته یا هدف یا خروجی هستند و قرار است مقادیر آنها را به کمک این الگوریتم ها پیش بینی کنیم . برای این منظور باید تابعی ایجاد کنیم که ورودیها (متغیرهای مستقل) را گرفته و خروجی موردنظر (متغیر وابسته یا هدف) را تولید کند. فرآیند یافتن این تابع که در حقیقت کشف رابطه ای بین متغیرهای مستقل و متغیرهای وابسته است را فرآیند آموزش (Training Process) می گوئیم که روی داده های موجود (داده هایی که هم متغیرهای مستقل و هم متغیرهای وابسته آنها معلوم هستند مثلا خریدهای گذشته مشتریان یک فروشگاه) اعمال میشود و تا رسیدن به دقت لازم ادامه می یابد. نمونه هایی از این الگوریتم ها عبارتند از رگرسیون، درختهای تصمیم ، جنگل های تصادفی، N نزدیک ترین همسایه، و رگرسیون لجستیک می باشند.
یادگیری بدون ناظر (unsupervised learning) : در این نوع از الگوریتم ها ، متغیر هدف نداریم و خروجی الگوریتم، نامشخص است. بهترین مثالی که برای این نوع از الگوریتم ها می توان زد، گروه بندی خودکار (خوشه بندی) یک جمعیت است مثلاً با داشتن اطلاعات شخصی و خریدهای مشتریان، به صورت خودکار آنها را به گروه های همسان و هم ارز تقسیم کنیم . الگوریتم Apriori و K-Means از این دسته هستند.
یادگیری تقویت شونده (Reinforcement Learning) : نوع سوم از الگوریتم ها که شاید بتوان آنها را در زمره الگوریتم های بدون ناظر هم دسته بندی کرد، دسته ای هستند که از آنها با نام یادگیری تقویت شونده یاد میشود. در این نوع از الگوریتم ها، یک ماشین (در حقیقت برنامه کنترل کننده آن)، برای گرفتن یک تصمیم خاص ، آموزش داده می شود و ماشین بر اساس موقعیت فعلی (مجموعه متغیرهای موجود) و اکشن های مجاز (مثلا حرکت به جلو ، حرکت به عقب و …) ، یک تصمیم را می گیرد که در دفعات اول، این تصمیم می تواند کاملاً تصادفی باشد و به ازای هر اکشن یا رفتاری که بروز می دهد، سیستم یک فیدبک یا بازخورد یا امتیاز به او میدهد و از روی این فیدبک، ماشین متوجه میشود که تصمیم درست را اتخاذ کرده است یا نه که در دفعات بعد در آن موقعیت ، همان اکشن را تکرار کند یا اکشن و رفتار دیگری را امتحان کند. با توجه به وابسته بودن حالت و رفتار فعلی به حالات و رفتارهای قبلی، فرآیند تصمیم گیری مارکوف ، یکی از مثالهای این گروه از الگوریتم ها می تواند باشد . الگوریتم های شبکه های عصبی هم می توانند ازین دسته به حساب آیند. منظور از کلمه تقویت شونده در نام گذاری این الگوریتم ها هم اشاره به مرحله فیدبک و بازخورد است که باعث تقویت و بهبود عملکرد برنامه و الگوریتم می شود .
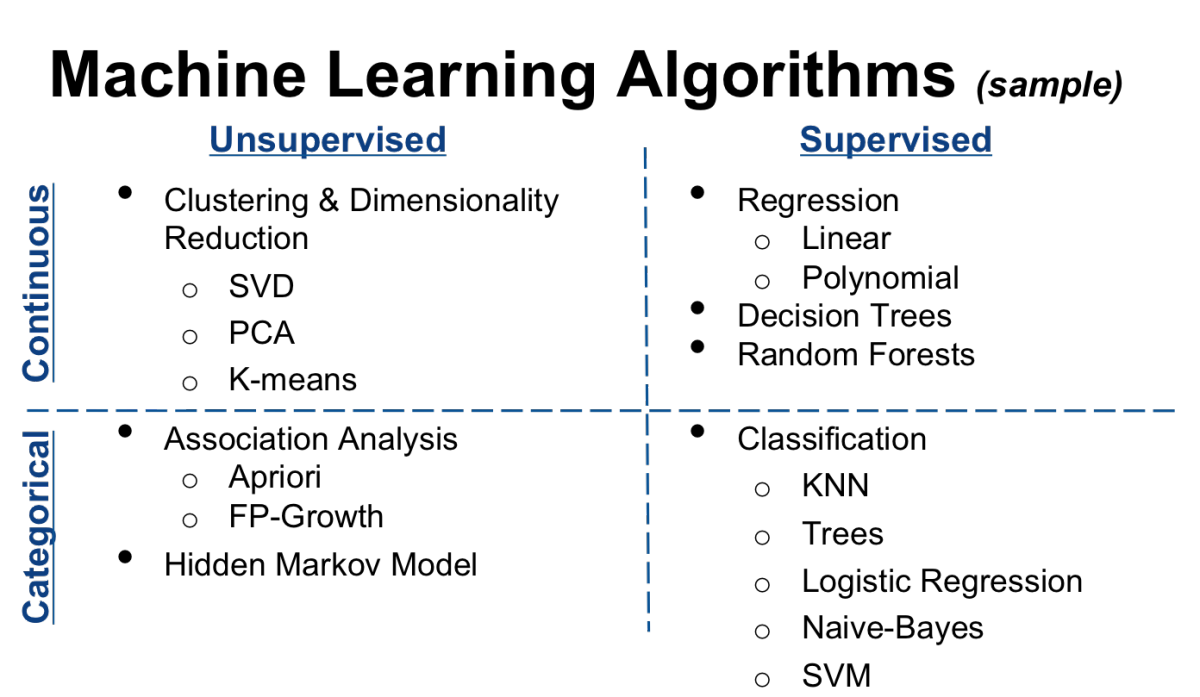
نمونه ای از دسته بندی کلاسیک الگوریتم های یادگیری ماشین که بر اساس وجود یا عدم وجود عامل کنترل کننده (ناظر) و گسسته و پیوسته بودن متغیرها انجام شده است را می توانید در این شکل ببینید :
الگوریتم های اصلی و رایج یادگیری ماشین
در این سری از مقالات به آموزش الگوریتم های زیر با نمونه کدهای لازم و مثالهای تشریحی، خواهیم پرداخت :
الگوریتمهای مختلفی در حوزه یادگیری ماشین و هوش مصنوعی در سالهای اخیر ایجاد یا بهبود یافته اند که برای هر فردی که قصد کار حرفه ای در این حوزه را دارد، آشنایی و تسلط بر آنها و مفاهیم پایه هر کدام و نیز استفاده از آنها در کاربردهای عملی، جزء ضروریات است.
در سال ۲۰۰۷ یک مقاله با عنوان ده الگوریتم برتر حوزه داده کاوی در دنیا توسط دانشگاه ورمونت مطرح شد که نسخه فارسی شده و حتی آماده انتشار به صورت کتاب آنرا هم در ایران داریم . مقاله فارسی را می توانید از این لینک دانلود نمایید.
For the last one I’d let you pick one of the following:
Bayesian Networks
Elastic Nets
Any other clustering algo besides k-means
LDA
Conditional Random Fields
HDPs or other Bayesian non-parametric model
سایت DataFloq اخیراً یک طبقه بندی گرافیکی از الگوریتم های ضروری یادگیری ماشین ارائه کرده است که به صورت طبقه بندی شده ، این الگوریتم ها را فهرست کرده است :
در ادامه معرفی الگوریتمهای ضروری یادگیری ماشین، به بررسی مفاهیم پایه درخت تصمیم می پردازیم که یکی از الگوریتمها و روشهای محبوب در حوزه طبقهبندی یا دستهبندی دادهها، است و در این مقاله سعی شده است به زبان ساده و بهدوراز پیچیدگیهای فنی توضیح داده شود. درخت تصمیم که هدف اصلی آن، دستهبندی دادههاست، مدلی در دادهکاوی است که مشابه فلوچارت، ساختاری درختمانند را جهت اخذ تصمیم و تعیین کلاس و دسته یک داده خاص به ما ارائه میکند. همانطور که از نام آن مشخص است، این درخت از تعدادی گره و شاخه تشکیلشده است بهگونهای کهبرگها کلاسها یا دستهبندیها را نشان میدهند و گرههای میانی هم برای تصمیمگیری با توجه به یک یا چند صفت خاصه بهکارمیروند. در زیر ساختار یک درخت تصمیم جهت تعیین نوع بیماری (دسته) بر اساس نشانگان مختلف، نمایش دادهشده است:
درخت تصمیم یک مدل خودتوصیف است یعنی بهتنهایی و بدون حضور یک فرد متخصص در آن حوزه، نحوه دستهبندی را به صورت گرافیکی نشان میدهد و به دلیل همین سادگی و قابلفهم بودن، روش محبوبی در دادهکاوی محسوب میشود. البته به خاطر داشته باشید در مواردی که تعداد گرههای درخت زیاد باشد، نمایش گرافیکی و تفسیر آن میتواند کمی پیچیده باشد.
برای روشن شدن مطالب، به مثال زیر توجه کنیدکه در آن قصد داریم به کمک ساخت یک درخت تصمیم، بازیکردن کریکت را برای یک دانشآموز، پیشبینی کنیم:
فرض کنید نمونهای شامل ۳۰ دانشآموز با سه متغیر جنسیت (پسر/ دختر)، کلاس (X / IX) و قد (۵ تا ۶ فوت) داریم. ۱۵ نفر از ۳۰ نفر در اوقات فراغت خود کریکت بازی میکنند. حال میخواهیم با بررسی خصوصیات این پانزده نفر، پیشبینی کنیم چه کسانی در اوقات فراغت خود کریکت بازی میکنند.برای این کار ابتدا باید براساس خصوصیات ۱۵ نفری که کریکت بازی میکنند، یک الگو برای دستهبندی به دست آوریم. از آنجا که درخت تصمیم یک ساختار سلسله مراتبی شرطی دارد (شکل فوق) و در هر مرحله باید بر اساس مقدار یک خصوصیت تصمیم بگیریم، مهمترین کاری که در ساخت این درخت تصمیم باید انجام دهیم، این است که تعیین کنیم کدام خصوصیت دادهها، تفکیککنندگی بیشتری دارد. سپس این خصوصیتها را اولویتبندی کرده و نهایتاً با لحاظ این اولویتها از ریشه به پایین در اتخاذ تصمیم، ساختاری درختمانند برای دستهبندی دادهها بنا کنیم. الگوریتمهای مختلف ساخت درخت تصمیم، مهم-ترین تفاوتی که با هم دارند، در انتخاب این اولویت و روشی است که برای انتخاب اولویت خصوصیتها در نظر میگیرند.
برای سنجش میزان تفکیککنندگی یک خصوصیت، سادهترین روش این است که دانشآموزان را براساس همهٔ مقادیر هر سه متغیر تفکیک کنیم. یعنی مثلاً ابتدا بر اساس جنسیت، دادهها را جدا کنیم و سپس مشخص کنیم چند نفر از دختران و چندنفر از پسران، کریکت بازی میکنند. سپس همین کار را برای قد و کلاس تکرار کنیم. با این کار، میتوانیم درصد بازیکنان هر مقدار از یک خصوصیت (درصد بازیکنان دختر از کل دخترها و درصد بازیکنان پسر از کل پسرها) را محاسبه کنیم. هر خصوصیتی که درصد بیشتری را تولید کرد، نشانگر تفکیککنندگی بیشتر آن خصوصیت (و البته آن مقدار خاص) است.
جور دیگری هم به این موضوع میتوان نگاه کرد: این متغیر، بهترین مجموعه همگن از دانشآموزان از لحاظ عضویت در گروه بازیکنان را ایجاد میکند یعنی در گروه بازیکنان، بیشترین خصوصیتی که بین همه مشترک است، پسر بودن است. میزان همگنی و یکنواختی ایجاد شده توسط هر خصوصیت هم، شکل دیگر میزان تفکیککنندگی آن خواهد بود.
در تصویر زیر شما میتوانید مشاهده کنید که متغیر جنسیت در مقایسه با دو متغیر دیگر، قادر به شناسایی بهترین مجموعهٔ همگن هست چون میزان مشارکت دانشآموزان پسر دربازی کریکت ۶۵ درصد است که از تمام متغیرهای دیگر بیشتر است:
برای متغیر قد که یک متغیر عددی بود از یک نقطه معیار که میتواند میانگین قد افراد باشد، استفاده کردیم. کار با متغیرهای عددی در درخت تصمیم را در ادامه، به تفصیل مورد بررسی قرار خواهیم داد. همانطور که در بالا ذکر شد، الگوریتمهای ساخت درخت تصمیم، تفکیککنندهترین متغیر که دستههای بزرگتری از دادهها را براساس آن میتوانیم ایجاد کنیم یا به عبارت دیگر، بزرگترین مجموعهٔ همگن از کل دادهها را ایجاد میکند، شناسایی میکنند، سپس به سراغ متغییر تفکیککننده بعدی میروند و الی آخر تا بر اساس آنها، ساختار درخت را مرحله به مرحله بسازند. حال سؤالی که پیش میآید این است که در هر مرحله، چگونه این متغیر شناساییشده و عمل تقسیم انجام گیرد؟ برای انجام این کار، درخت تصمیم از الگوریتمهای متنوعی استفاده میکند که در بخشهای بعدی به آنها خواهیم پرداخت.
درخت تصمیم چگونه کار میکند؟
در درخت تصمیم با دنبال کردن مجموعهای از سوالات مرتبط با خصوصیات دادهها و نگاه به داده جاری برای اتخاذ تصمیم، طبقه یا دسته آنرا تعیین میکنیم. در هر گره میانی درخت، یک سؤال وجود دارد و با مشخص شدن پاسخ هر سؤال به گره مرتبط با آن جواب میرویم و در آنجا هم سؤال دیگری پرسیده میشود.
هدف از الگوریتمهای درخت تصمیم هم انتخاب درست این سؤالات است به گونهای که یک دنباله کوتاه از سؤالات برای پیشبینی دستهٔ رکورد جدید تولید کنند.
هر گره داخلی متناظر با یک متغیر و هر یال، نمایانگر یک مقدار ممکن برای آن متغیر است. یک گره برگ، مقدار پیشبینیشدهٔ متغیر هدف (متغیری که قصد پیشبینی آنرا داریم)، را نشان میدهد یعنی برگها نشاندهندهٔ دستهبندی نهایی بوده و مسیر پیموده شده تا آن برگ، روند رسیدن به آن گره را نشان میدهند.
فرآیند یادگیری یک درخت که در طی آن، گرهها و یالها مشخص میشوند و درادامه به آن خواهیم پرداخت، معمولاً با بررسی مقدار یک خصوصیت در مرحله اول، به تفکیک کردن مجموعه داده به زیرمجموعههایی مرتبط با مقدار آن صفت، کار خود را شروع میکند. این فرآیند به شکل بازگشتی در هر زیرمجموعهٔ حاصل از تفکیک نیز تکرار میشود یعنی در زیرمجموعهها هم مجدداً براساس مقدار یک صفت دیگر، چند زیرمجموعه ایجاد میکنیم. عمل تفکیک، زمانی متوقف میشود که تفکیک بیشتر، سودمند نباشد یا بتوان یک دستهبندی را به همه نمونههای موجود در زیرمجموعهٔ بهدستآمده، اعمال کرد. در این فرآیند، درختی که کمترین میزان برگ و یال را تولید کند، معمولاً گزینه نهایی ما خواهد بود.
انواع متغیرها در درخت تصمیم
در مسائل مرتبط با درختهای تصمیم با دو نوع کلی از متغیرها مواجه هستیم:
متغیرهای عددی یا پیوسته: مانند سن، قد، وزن و… که مقدار خود را از مجموعهٔ اعداد حقیقی میگیرند.
متغیرهای ردهای یا گسسته : مانند نوع، جنس، کیفیت و… که بهصورت دو یا چند مقدار گسسته هستند. در مواردی مانند آیا این شخص دانشآموز است؟ که دو جواب بله و خیر داریم، این متغیر از نوع طبقهای خواهد بود.
از طرفی میتوانیم متغیرها را به دون گروه کلی، متغیرهای مستقل و متغیرهای وابسته تقسیم کنیم. متغیرهای مستقل، متغیرهایی هستند که مقدار آنها، مبنای تصمیم گیری ما خواهند بود و متغیر وابسته، متغیری است که بر اساس مقدار متغیرهای مستقل، باید مقدار آنرا پیشبینی کنیم. متغیرهای مستقل با گرههای میانی نشان داده میشوند و متغیرهای وابسته، با برگ نشان داده میشوند. حال هر یک از این دو نوع متغیر مستقل و وابسته، میتواند گسسته یا پیوسته باشد. چنانچه متغیری وابستهٔ عددی باشد دسته بندی ما یک مسالهٔ رگرسیون و چنانچه طبقهای باشد، دسته بندی از نوع، ردهبندی (Classification) است. به عبارتی دیگر، هنگامیکه خروجی یک درخت، یک مجموعه گسسته از مجموعه مقادیر ممکن است؛ به آن درخت دستهبندی میگوییم (مثلاً مؤنث یا مذکر، برنده یا بازنده). این درختها تابع X→C را بازنمایی میکنند که در آن C مقادیر گسسته میپذیرد. هنگامیکه بتوان خروجی درخت را یک عدد حقیقی در نظر گرفت آن را، درخت رگرسیون مینامیم (مثلاً قیمت خانه یا طول مدت اقامت یک بیمار در یک بیمارستان). این درختان اعداد را در گرههای برگ پیشبینی میکنند و میتوانند از مدل رگرسیون خطی یا ثابت (یعنی میانگین) یا مدلهای دیگر استفاده کنند. وظیفهٔ یادگیری در درختان رگرسیون، شامل پیشبینی اعداد حقیقی بجای مقادیر دستهای گسسته است که این عمل را با داشتن مقادیر حقیقی در گرههای برگ خود نشان میدهند. بدینصورت که میانگین مقادیر هدف نمونههای آموزشی را در این گره برگ به دست میآورند. این نوع از درختان، تفسیر آسان داشته و میتوانند توابع ثابت تکهای را تقریب بزنند.
درخت CART (Classification And Regression Tree) نامی است که به هر دو روال بالا اطلاق میشود. نام CART سرنام کلمات درخت رگرسیون و دستهبندی است. البته نوع دیگری از درختهای تصمیم هم داریم که برای خوشهبندی (clustering) دادهها به کار میروند و به دلیل کاربرد محدود، در این مجموعه مقالات به آنها نخواهیم پرداخت (بیشتر تحقیقات در یادگیری ماشین روی درختان دستهبندی متمرکز است).
اصطلاحات مهم مربوط به درخت تصمیم
در این بخش به معرفی اصطلاحات مهم در حوزهٔ کار با درخت تصمیم میپردازیم. گره ریشه: این گره حاوی تمام نمونههای موجود هست و سطح بعدی اولین تقسیم مجموعهٔ اصلی به دو مجموعهٔ همگنتر است. در مثال قبل، گره ریشه دارای ۳۰ نمونه است. گره تصمیم: زمانی که یک گره به زیرگرههای بعدی تقسیم میشود، آن را یک گره تصمیم مینامیم. برگ / گره پایانه: گرههایی که تقسیم نمیشوند یا به عبارتی تقسیم پیاپی از طریق آنها پایان مییابد، برگ یا گره پایانه نام دارند.
در تصویر زیر، گره ریشه (Root Node) با رنگ آبی، شاخه، انشعاب (Branch) یا به عبارتی زیر درخت (Sub-Tree) با رنگ گلبهی، تقسیم (Splitting) و هرس (Pruning) نمایش دادهشدهاند. برگها هم به رنگ سبز در انتهای شاخههای مختلف درخت، قرار گرفتهاند.
هرس کردن: هنگامیکه ما از یک گره تصمیم، زیر گرهها را حذف کنیم، این عمل هرس کردن نامیده میشود. درواقع این عمل متضاد عمل تقسیم کردن است.
انشعاب / زیردرخت: بخشی از کل درخت را انشعاب یا زیر درخت میگویند. گرههای پدر و فرزند: گرهای که به چندین زیر گره تقسیم میشود را گره والد یا گره پدر برای زیر گرههای آن میگویند. درحالیکه زیر گرههایی که والد دارند، بهعنوان گرههای فرزند شناخته میشوند.
این اصطلاحات، عبارات پرکاربردی در استفاده از درخت تصمیم هستند.
قبل از پرداختن به الگوریتمهای مختلف ساخت درخت تصمیم، به مزایا و معایب و ویژگیهای این نوع از مدلهای دستهبندی دادهها میپردازیم.
مزایا و معایب درخت تصمیم
مزایای درختان تصمیم نسبت به روشهای دیگر دادهکاوی
۱) قوانین تولیدشده و بهکاررفته شده قابلاستخراج و قابلفهم میباشند.
۲) درخت تصمیم، توانایی کار با دادههای پیوسته و گسسته را دارد. (روشهای دیگر فقط توان کار با یک نوع رادارند. مثلاً شبکههای عصبی فقط توان کار با دادههای پیوسته را دارد و قوانین رابطهای با دادههای گسسته کار میکنند)
۳) مقایسههای غیرضروری در این ساختار حذف میشود.
۴) از ویژگیهای متفاوت برای نمونههای مختلف استفاده میشود.
۵) احتیاجی به تخمین تابع توزیع نیست.
۶) آمادهسازی دادهها برای یک درخت تصمیم، ساده یا غیرضروری است. (روشهای دیگر اغلب نیاز به نرمالسازی داده یا حذف مقادیر خالی یا ایجاد متغیرهای پوچ دارند)
۷) درخت تصمیم یک مدل جعبه سفید است. توصیف شرایط در درختان تصمیم بهآسانی با منطق بولی امکانپذیر است درحالیکه شبکههای عصبی به دلیل پیچیدگی در توصیف نتایج آنها یک جعبه سیاه میباشند.
۸) تائید یک مدل در درختهای تصمیم با استفاده از آزمونهای آماری امکانپذیر است. (قابلیت اطمینان مدل را میتوان نشان داد)
۹) ساختارهای درخت تصمیم برای تحلیل دادههای بزرگ در زمان کوتاه قدرتمند میباشند.
۱۰) روابط غیرمنتظره یا نامعلوم را مییابند.
۱۱) درختهای تصمیم قادر به شناسایی تفاوتهای زیرگروهها میباشند.
۱۲) درختهای تصمیم قادر به سازگاری با دادههای فاقد مقدار میباشند.
۱۳) درخت تصمیم یک روش غیرپارامتریک است و نیاز به تنظیم خاصی برای افزایش دقت الگوریتم ندارد.
معایب درختان تصمیم
۱) در مواردی که هدف از یادگیری، تخمین تابعی با مقادیر پیوسته است مناسب نیستند.
۲) در موارد با تعداد دستههای زیاد و نمونه آموزشی کم، احتمال خطا بالاست.
۳) تولید درخت تصمیمگیری، هزینه محاسباتی بالا دارد.
۴) هرس کردن درخت هزینه بالایی دارد.
۵) در مسائلی که دستهها شفاف نباشند و همپوشانی داشته باشند، خوب عمل نمیکنند.
۶) در صورت همپوشانی گرهها تعداد گرههای پایانی زیاد میشود.
۷) درصورتیکه درخت بزرگ باشد امکان است خطاها از سطحی به سطحی دیگر جمع میشوند (انباشته شدن خطای لایهها و تاثیر بر روی یکدیگر).
۸) طراحی درخت تصمیمگیری بهینه، دشوار است و کارایی یک درخت دستهبندی کننده به چگونگی طراحی خوب آن بستگی دارد.
۹) احتمال تولید روابط نادرست وجود دارد.
۱۰) وقتی تعداد دستهها زیاد است، میتواند باعث شود که تعداد گرههای پایانی بیشتر از تعداد دستههای واقعی بوده و بنابراین زمان جستجو و فضای حافظه را افزایش میدهد.
مقایسه درخت تصمیم و درخت رگرسیون
تا اینجا متوجه شدیم که درخت تصمیم ساختاری بالا به پایین دارد و بر خلاف تصوری که از یک درخت داریم، ریشه در بالای درخت قرارگرفته و شاخهها مطابق تصویر در پایین هستند.
هر دو نوع درخت تصمیم و رگرسیون تقریباً مشابه هستند. در زیر به برخی شباهتها و تفاوتهای بین این دو میپردازیم:
ویژگیهای درخت رگرسیون و درخت دستهبندی:
• زمانی که متغیر هدف ما پیوسته و عددی باشد، از درخت رگرسیون و زمانی که متغیر هدف ما گسسته یا غیرعددی باشد، از درختان تصمیم استفاده میکنیم.
• معیار تقسیم و شاخه زدن در درختان رگرسیون بر اساس معیار خطای عددی است.
• گرههای برگ در درختان رگرسیون حاوی مقادیر عددی هستند که هر عدد، میانگین مقادیر دستهای است که داده جاری، بیشترین شباهت را با آنها داشته است اما در درختان تصمیم، مقدار برگ، متناظر با دستهایست که بیشترین تکرار را با شرایط مشابه با داده داده شده، داشته است.
ن هر دو درخت، رویکرد حریصانهٔ بالا به پایین را، تحت عنوان تقسیم باینری بازگشتی دنبال میکنند. این روش از بالای درخت، جایی که همهٔ مشاهدات در یک بخش واحد در دسترس هستند شروع میشود و سپس تقسیم به دوشاخه انجامشده و این روال بهصورت پیدرپی تا پایین درخت ادامه دارد، به همین دلیل این روش را بالا به پایین میخوانیم. همچنین به این دلیل این روش را حریصانه میخوانیم که تلاش اصلی ما در یافتن بهترین متغیر در دسترس برای تقسیم فعلی است و در مورد انشعابات بعدی که به یک درخت بهتر منتهی شود، توجهی نداریم. (به عبارتی همواره بهترین انتخاب در لحظه، بهترین انتخاب در سراسر برنامه نیست و اثرات این تقسیم در تقسیمهای آینده را در نظر نمیگیرد). به یاد دارید که درروش حریصانه و در مورد کولهپشتی نیز مورد مشابه را دیدهایم. در شیوه حریصانه در هر مرحله عنصری که بر مبنای معیاری معین ((بهترین)) به نظر میرسد، بدون توجه به انتخابهای آینده، انتخاب میشود.
• در هر دو نوع درخت، در فرآیند تقسیم این عمل تا رسیدن به معیار تعریفشدهٔ کاربر برای توقف عملیات، ادامه دارد. برای مثال، ما میتوانیم به الگوریتم بگوییم که زمانی که تعداد مشاهدات در هر گره کمتر از ۵۰ شود، عملیات متوقف گردد.
• در هر دو درخت، نتایج فرآیند تقسیم، تا رسیدن به معیارهای توقف، باعث رشد درخت میشود. اما درخت کاملاً رشد یافته بهاحتمالزیاد باعث بیشبرازش دادهها (over fit) خواهد شد که در این صورت، شاهدکاهش صحت و دقت بر روی دادههای آینده که قصد دستهبندی آنها را داریم، خواهیم بود. در این زمان هرسکردن را بکار میبریم. هرس کردن، روشی برای مقابله با بیش-برازش دادههاست که در بخش بعد بیشتر به آن خواهیم پرداخت.
نحوهٔ تقسیم یک درخت تصمیم
تصمیمگیری دربارهٔ نحوهٔ ساخت شاخهها در یک درخت یا به عبارتی تعیین ملاک تقسیم بندی در هر گره، عامل اصلی در میزان دقت یک درخت است که برای درختهای رگرسیون و تصمیم، این معیار، متفاوت است.
درختهای تصمیم از الگوریتمهای متعدد برای تصمیمگیری دربارهٔ تقسیم یک گره به دو یا چند گره استفاده میکنند. در حالت کلی، هدف از ساخت هر زیرگره، ایجاد یک مجموعه جدید از دادههاست که با همدیگر همگن بوده و به هم شبیهترند اما نسبت به سایر شاخهها، قابل تفکیک و تمایز هستند بنابراین ایجاد زیر گرهها در هر مرحله، یکنواختی دادهها را در زیرگرههای حاصل افزایش میدهد. بهعبارتدیگر، خلوص گره در هر مرحله، با توجه به شباهت آن با متغیر هدف، افزایش مییابد. درخت تصمیم، گرهها را بر اساس همهٔ متغیرهای موجود تقسیمبندی میکند و سپس تقسیمی که بیشترین یکنواختی را در دادههای حاصل (همگن بودن) ایجاد کند، انتخاب میکند. شکل زیر، این مفهوم را به خوبی نشان میدهد.
انتخاب الگوریتم، به نوع متغیرهای هدف نیز بستگی دارد.
بگذارید برای تبیین بهتر مفهوم «درخت تصمیم (decision tree)» یک مثال کاربردی را بررسی کنیم؛ مدیریت شرکت «Stygian Chemical Industries, Ltd» میخواهد بین انتخاب این دو گزینه تصمیمگیری کند: ساخت یک واحد تولیدی کوچک یا یک واحد تولیدی بزرگ برای ساخت یک محصول شیمیایی با عمر بازار (market life) برابر با ده سال. توضیح اینکه اتخاذ این تصمیم مبتنی بر تخمین اندازه بازار در آینده است.
احتمالا تقاضا برای این محصول طی دو سال اول بسیار بالا باشد اما اگر مصرفکنندگان اولیه از محصول رضایت کافی نداشته باشند، تقاضا به تبع کاهش خواهد یافت. این احتمال نیز وجود دارد که تقاضای بالا در سالهای اولیه نشان از یک بازار پررونق دائمی باشد. اگر تقاضا بعد از دو سال همچنان بالا بماند و شرکت نتواند تولیدات را افزایش دهد، احتمالا شرکتهای رقیب به سرعت وارد بازار خواهند شد.
اگر شرکت یک واحد تولیدی با ظرفیت عظیم ایجاد کند، بدون توجه به رفتار بازار باید تا پایان ده سال با تولیدات زیاد کنار بیاید. اگر شرکت یک واحد تولیدی کوچک در اختیار داشته باشد و بازار بعد از دو سال رشد کند، مدیریت این انتخاب را خواهد داشت که ظرفیت را توسعه دهد. در صورتی که اندازه بازار بعد از دو سال اولیه رشد نکند، شرکت با ظرفیت کنونی ادامه خواهد داد.
هیئت مدیره با تردید و نگرانی زیادی دستوپنجه نرم میکند. شرکت طی سالهای 1۹4۰ تا 1۹۵۰ رشد مناسبی داشته و با سرعت مطابق با نیاز بازار رشد کرده است. اگر بازار محصول جدید واقعا بزرگ باشد این شانس برای شرکت وجود دارد تا به سرعت وارد عرصه عظیمی از سود سرشار گردد. مهندس پروژه توسعه (development project engineer) مصرانه به دنبال ترغیب مدیریت به ساخت واحد تولیدی با ظرفیت زیاد است. این واحد علاقه دارد اولین واحد غولپیکر طراحی شده توسط خود را به جهان معرفی نماید.
رئیس که خود یک سهامدار عمده نیز هست، نگران ایجاد ظرفیتی بیش از ظرفیت بازار به شرایط مینگرد. او مایل است ابتدا واحد کوچکتر تاسیس شود اما میداند هزینه توسعه ظرفیت در آینده بسیار زیاد و بهرهبرداری آن نیز مشکلتر از یک واحد یکدست بزرگ است. او همچنین میداند اگر نتواند به سرعت به اندازه نیاز بازار تولید کند، رقبا با کمال میل جای او را پر خواهند کرد.
مسئله کارخانه Stygian که کاملا سادهسازی شده، نشان از نگرانیها و چالشهایی است که مدیریت باید در اتخاذ تصمیمات مرتبط با سرمایهگذاری، با آنها روبهرو شود (در این مطلب از واژه سرمایهگذاری نه تنها برای ایجاد یک واحد تولیدی جدید بلکه به شکل عام برای ایجاد ساختمانهای بزرگ، هزینه سنگین تحقیقات و تصمیمات با ریسک بالا استفاده شده است). اهمیت تصمیمات همزمان و پیچیدگی آنها هر روز بیشتر میشود. خیل عظیم مدیران میخواهند بهتر تصمیم بگیرند، اما چگونه؟
در این نوشته در مورد مفهوم درخت تصمیم که ابزار بسیار مفیدی برای تصمیمگیری است، توضیح داده خواهد شد. درخت تصمیم بهتر از هر ابزار دیگری میتواند گزینههای ممکن، اهداف، سود مالی و اطلاعات مورد نیاز برای یک سرمایهگذاری را به مدیریت نشان دهد. در سالهای روبهرو درباره درخت تصمیم بسیار خواهیم شنید. به جز تازگی و خلاقیت نهفته در درخت تصمیم، این عبارت تا سالیان زیادی در کلیشه سخنان همیشگی مدیران وجود خواهد داشت.
نمایش گزینهها
بیایید خود را در یک صبح شنبه ابری تصور کنید که برای بعد از ظهر همان روز تعداد ۷۵ نفر را به صرف نوشیدنی دعوت کردهاید. خانه شما خیلی بزرگ نیست اما باغ چشمنواز جلوی آن میتواند در صورتی که هوا بارانی نشود، مهمانپذیر مناسبی باشد. در باغ به میهمانان بیشتر خوش میگذرد و شما رضایت بیشتری خواهید داشت. اما اگر ناگهان در بین جشن باران بگیرد، تدارکات از بین میرود و برای مهمانها و شما خاطرهای تلخ از روز شنبه باقی خواهد ماند (البته امکان پیچیدهتر کردن مسئله وجود دارد. برای مثال، امکان پیشبینی هوا بر اساس شرایط چند روز گذشته و امکان تدارک میهمانی در باغ و خانه به صورت همزمان را میتوان اضافه کرد. اما همین مسئله ساده کار ما را راه خواهد انداخت!).
این تصمیم خاص را میتوان در یک جدول انتخاب/نتیجه (payoff table) نشان داد.
انتخاب
باران بیاید
باران نیاید
برگزاری جشن در باغ
فاجعه
لذت فروان و به یاد ماندنی
برگزاری جشن در خانه
لذت نسبی، شادی
لذت نسبی، پشیمانی
سوالات بسیار پیچیده تصمیمگیری را میتوان در چنین جدولهایی خلاصه کرد. با اینحال، بهویژه برای تصمیمات پیچیده سرمایهگذاری روش مناسب دیگری برای بررسی اثرات و احتمالات تصمیمگیری به همراه نتایج وجود دارد: درخت تصمیم. پیر ماسی ( Pierre Massé)، مامور عالیرتبه آژانس تصمیمگیری برای تولیدات و تجهیزات فرانسه (Commissioner General of the National Agency for Productivity and Equipment Planning in France)، میگوید:
مشکل تصمیمگیری را نمیتوان به عنوان یک مشکل مجزا (چراکه تصمیمات کنونی بر اساس آنچه در آینده پیش خواهد آمد، اتخاذ میشوند) یا به شکل یک زنجیر متوالی از تصمیمات (به دلیل اینکه تحت تاثیر عدم اطمینانها، تصمیمات آینده مبتنی بر آنچه در طول زمان میآموزیم تغییر خواهند کرد) انگاشت. مشکل تصمیمگیری در واقع خود را به شکل یک درخت تصمیم نشان میدهد.
نگاره شماره یک، درخت تصمیم میهمانی را نشان میدهد. درخت در واقع راه دیگری برای نمایش جدول انتخاب/نتیجه است. با این حال درخت تصمیم راه بهتری برای نشان دادن احتمالات و اطلاعات تصمیمگیری در مسائل پیچیده است.
درخت از یک سری نقاط و شاخهها تشکیل شده است. در اولین نقطه از سمت چپ، میزبان امکان انتخاب برگزاری جشن را داخل یا بیرون از منزل دارد. هر شاخه نماینده یک اتفاق ممکن یا یک مرحله تصمیمگیری است. در انتهای هر شاخه یک نقطه وجود دارد که یک اتفاق محتمل – آمدن یا نیامدن باران- را نشان میدهد. پیامد هر اتفاق ممکن در منتهیالیه سمت راست یا نقطه پایانی هر شاخه آمده است.
در هنگام رسم یک درخت تصمیم، میتوان تصمیم یا عمل را با نقاط مربعشکل و اتفاقات محتمل را با نقاط دایرهایشکل نشان داد. از دیگر نمادها نیز میتوان استفاده کرد. برای نمونه شاخههای یکخطی یا دوخطی، حروف خاص و رنگهای مختلف میتوانند برای نشان دادن جزئیات مورد استفاده قرار گیرند. یک درخت تصمیم با هر اندازهای شامل: الف) انتخابها و ب) پیشامدهای محتمل یا نتیجه انتخابها است که تحت تاثیر احتمالات یا شرایط غیرقابل کنترلاند.
زنجیره تصمیم – پیشامد (Decision-event chains)
مثال قبل با اینکه تنها یک مرحله از تصمیمگیری را نشان میدهد، شامل پایههای ابتدایی تمام درختهای تصمیمگیری پیچیده است. بیایید نگاهی به شرایط پیچیدهتر بیندازیم.
شما قرار است در مورد تایید یا رد اختصاص بودجه به توسعه یک محصول تقویتشده تصمیمگیری کنید. اینکه در صورت موفقیت، اختصاص بودجه میتواند به شما مزیت بسیاری در رقابت با رقیبان اعطا کند نکتهای مثبت است. اما اگر نتوانید محصول خود را توسعه یا بهروزرسانی کنید، ضربه سختی از رقیبان در بازارهای مالی خواهید خورد. درخت تصمیم مربوط به این مسئله را در نگاره شماره دو میبینید.
در سمت چپ اولین تصمیم شما نشان داده شده است. در ادامه تصمیم برای اجرای پروژه، در صورتیکه توسعه موفقیتآمیز باشد، به مرحلهی دوم تصمیمگیری میرسید (نقطه A). با فرض عدم تغییرات عمده بین زمان حاضر و نقطه A، در این نقطه باید در مورد گزینههای مختلف تصمیمگیری نمایید. میتوانید تصمیم به عرضه محصول جدید بگیرید یا فعلا دست نگه دارید. در قسمت راست هر درخت تصمیم، نتایج زنجیر تصمیمات و پیشامدها نشان داده شده است. این نتایج بر مبنای اطلاعات حال حاضر تنظیم شده است. در واقع شما میگویید:
اگر آنچه در حال حاضر میدانم، در آن زمان هم درست باشد، چه پیشامدی رخ خواهد داد.
البته شما قادر به پیشبینی تمام پیشامدها و تصمیمات مورد نیاز در آینده در رابطه با موضوع مورد بحث نیستید. در درخت تصمیم تنها تصمیمات و پیشامدهای مهم و اثربخش را برای مقایسه در نظر میگیرید.
اضافه کردن دادههای مالی
حالا میتوانیم به مسئله شرکت شیمیایی Stygian برگردیم. درخت تصمیم متناسب با مسئله در نگاره شماره سه نشان داده شده است. در تصمیم شماره یک، شرکت باید بین احداث یک واحد با ظرفیت پایین یا یک واحد با ظرفیت بالا یکی را انتخاب کند. هماکنون تنها در این مورد باید تصمیمگیری شود. اما اگر بعد از تاسیس واحد کوچکتر، شرکت با تقاضای مناسب بازار روبرو شد میتواند طی دو سال طرح توسعه واحد را اجرا کند (تصمیم شماره دو).
اما بیایید از گزینههای لخت و عاری از داده عبور کنیم. در تصمیمگیری، مجریان باید به اعداد و ارقام مالی سود، ضرر و میزان سرمایه اتکا کنند. با توجه به شرایط کنونی و فرض عدم تغییرات ناگهانی و مهم، استدلال تیم مدیریت به شکل زیر است.
بررسی بازار نشان میدهد که شانس یک بازار بزرگ در بلند مدت برابر با ۶۰٪ و شانس یک بازار کوچک در بلند مدت برابر با 4۰٪ (ردیف دو و سه جدول) است.
پیشامد
شانس یا احتمال (٪)
تقاضای اولیه بالا، تقاضای درازمدت بالا
60
تقاضای اولیه بالا، تقاضای درازمدت پایین
10
تقاضای اولیه پایین، تقاضای درازمدت پایین
30
تقاضای اولیه پایین، تقاضای درازمدت بالا
0
در نتیجه، شانس اینکه بازار با تقاضای بالای اولیه روبهرو شود برابر با ۷۰٪ (۶۰ + 1۰) است. اگر تقاضا در ابتدا بالا باشد، شرکت پیشبینی میکند که احتمال ادامهی میزان بالای تقاضا برابر با ۸۶٪ (۷۰ ÷ ۶۰) است. مقایسه ۸۶٪ با ۶۰٪ نشان میدهد که تقاضای بالای اولیه، محاسبهی احتمال ادامه بازار با تقاضای بالا را دستخوش تغییر میکند. به شکل مشابه اگر تقاضا در دوره دو ساله ابتدائی پایین باشد، شانس پایین بودن تقاضا در ادامه برابر با 1۰۰٪ (3۰ ÷ 3۰) است. در نتیجه میزان فروش در دوره اولیه میتواند نشانگر خوبی برای سطح تقاضا در ادامه دوره ده ساله باشد.
تخمین درآمد در صورت پیشامد هر سناریو در ادامه آمده است.
1. یک واحد تولیدی بزرگ با تقاضای بالا درآمدی برابر با یک میلیون دلار در سال به صورت نقد خواهد داشت.
2. یک واحد تولیدی بزرگ با تقاضای پایین به دلیل هزینههای عملیاتی ثابت و بازده پایین تنها 1۰۰ هزار دلار در سال درآمد خواهد داشت.
3. یک واحد تولیدی کوچک با تقاضای پایین اقتصادی است و سالانه درآمدی معادل 4۰۰ هزار دلار خواهد داشت.
4. یک واحد تولیدی کوچک با تقاضای اولیه بالا در سال برابر با 4۵۰ هزار دلار درآمد خواهد داشت که در سالهای سوم به بعد با توجه به افزایش حضور رقبا به میزان 3۰۰ هزار دلار کاهش پیدا خواهد کرد. (بازار بزرگتر خواهد شد اما بین رقبای جدید تقسیم میشود.)
۵. اگر واحد کوچک مطابق با افزایش تقاضا در سالهای آتی رشد کند، سالانه ۷۰۰ هزار دلار درآمد سالانه به ارمغان خواهد آورد که کمتر از درآمد یک واحد بزرگ با درآمد یک میلیون دلار خواهد بود.
۶. اگر واحد کوچک توسعه پیدا کند اما بازار کوچک شود، درآمد حاصل سالانه برابر با ۵۰ هزار دلار خواهد بود.
در ادامه با محاسبات انجام گرفته خواهیم داشت: یک واحد بزرگ نیاز به سه میلیون دلار سرمایهگذاری دارد. یک واحد کوچک در ابتدا 1.3 میلیون دلار و در صورت ادامه توسعه نیاز به 2.2 میلیون دلار خواهد داشت.
اگر اطلاعات جدید را به درخت تصمیم وارد کنیم، نگاره شماره چهار به دست خواهد آمد. به خاطر داشته باشید که تمام اطلاعات موجود بر اساس دانستههای شرکت Stygian به دست آمدهاند اما بدون درخت تصمیم این اطلاعات ارزش و مفهوم کنونی را به دست نمیداند. کمکم متوجه میشوید که درخت تصمیم چه تاثیر شگرفی بر توانایی مدیران در تحلیل سیستماتیک (systematic analysis) و تصمیمگیری بهتر میگذارد. در نهایت برای ایجاد یک درخت تصمیم به موارد زیر نیازمندیم.
1. شناسایی نقاط تصمیم و انتخابهای ممکن در هر سطح
2. شناسایی احتمالات و بازه یا نوع پیشامدها در هر سطح
3. تخمین مقادیر عددی برای تحلیل بهویژه احتمال نتایج عملکرد، هزینهها و سود حاصل
4. تحلیل ارزش انتخابها برای انتخاب یک مسیر
انتخاب مسیر عملکرد (Choosing Course of Action)
هم اکنون آمادهی برداشتن قدم بعدی برای مقایسه نتایج هر مسیر هستیم. یک درخت تصمیم جواب نهایی مسئلهی سرمایهگذاری را به مدیر نمیدهد بلکه به وی کمک میکند مسیر با بهترین سود و کمترین هزینه را مشاهده کند و با مسیرهای دیگر مقایسه نماید.
البته سود باید همراه با ریسک محاسبه شود. در شرکت شیمیایی Stygian، مدیران بخشهای مختلف نظرات متفاوتی نسبت به ریسک دارند. لذا تصمیمات متفاوتی با داشتن یک درخت تصمیم یکسان به دست میآید. افراد حاضر و درگیر در تهیه درخت تصمیم شامل سرمایهگذاران، نظریهپردازان، دادهکاوان یا تصمیمگیران دید متفاوتی نسبت به ریسک و عدم اطمینانها دارند. اگر با این تفاوتها به شکل منطقی برخورد نشود، هر یک از افراد مذکور به شکل متفاوتی به فرایند تصمیمگیری نگاه میکنند و تصمیم هر یک با دیگری متناقض به نظر میرسد.
برای مثال یک سرمایهدار ممکن است به این تصمیم به عنوان یک سرمایهگذاری با احتمال برد و باخت نگاه کند. یک مدیر ممکن است تمام اعتبار و شهرت خود را بر این تصمیم قمار کند اما موفقیت یا عدم موفقیت این انتخاب تاثیر بهسزایی در درآمد و موقعیت یک کارمند عادی ایجاد نکند. فرد دیگری ممکن است در صورت موفقیت پروژه سود سرشاری کسب کند اما در صورت شکست خیلی متضرر نگردد. طبیعت ریسک از نظر هر کدام از افراد درگیر ممکن است به تفاوت در فهم ریسک و انتخاب استراتژیهای ناهمگون در مقابله با ریسک منجر گردد.
حضور اهداف متعارض، ناپایدار و متعدد منجر به ایجاد سیاست اصلی شرکت شیمیایی Stygian میگردد و عناصر این سیاست تحت تاثیر خواست و زندگی افراد درگیر تغییر میکند. در ادامه بد نیست اجزاء مختلف تصمیمگیر را بررسی و ارزیابی نماییم.
چه چیزی با ریسک روبهرو است؟ سود، ادامه حیات کسبوکار، حفظ شغل یا شانس یک شغل بهتر؟
چه کسی ریسک را تحمل میکند؟ سرمایهگذار عموما به یک شکل ریسک را تحمل میکند. مدیریت، کارمندان و جامعه ریسکهای متفاوتی را تجربه مینمایند.
ویژگی ریسک چیست؟ منحصر به فرد، تصادفی یا با عدم قطعیت؟ آیا اقتصاد، صنعت، شرکت یا بخشی از آن را تحت تاثیر قرار میدهد؟
چنین سوالهایی حتما ذهن مدیران عالی را درگیر میکند و البته درخت تصمیم نشان داده شده در نگاره شماره 4 به این سوالها پاسخ نخواهد داد. اما این درخت به مدیران خواهد فهماند که کدامیک از تصمیمات، اهداف بلند مدت را دستخوش تغییر میکنند. ابزار مناسب در قدم بعدی تحلیل مفهوم عقبگرد (rollback) است.
مفهوم عقبگرد
مفهوم عقبگرد در این شرایط نیاز به توضیح دارد. در نقطه تصمیم گیری شماره یک در نگاره شماره چهار، مدیریت اجباری برای اخذ تصمیم شماره دو ندارد و حتی نمیداند مجبور به این کار خواهد شد یا نه. اما اگر قرار بر تصمیمگیری در نقطه دو باشد، با توجه به اطلاعات کنونی، شرکت تصمیم به توسعه ظرفیت تولید خواهد گرفت. این تحلیل در نگاره شماره ۵ نشان داده شده است. ( در این لحظه از سوال در مورد تنزیل سود آینده (discounting future profits) چشمپوشی میکنیم و در ادامه در مورد آن صحبت خواهیم کرد.) میبینیم که امید ریاضی کلی (total expected value) در تصمیم به توسعه ظرفیت 160 هزار دلار بیشتر از تصمیم برای عدم توسعه در هشت سال باقیمانده است. در نتیجه مدیریت با اطلاعات کنونی چنین تصمیمی خواهد گرفت (تصمیم تنها بر اساس سود بیشتر و به عنوان یک تصمیم منطقی اخذ میشود).
ممکن است بیاندیشید چرا با اینکه تنها با تصمیم شماره یک روبرو هستیم، باید به جایگاه تصمیمگیری نقطه دو فکر کنیم. دلیل این موضوع این است که ما بایستی بتوانیم سود حاصل از تصمیم نقطه دو را محاسبه کنیم تا قادر باشیم سود حاصل از تصمیم نقطه یک (ساخت یک واحد تولیدی کوچک یا یک واحد تولید بزرگ) را با یکدیگر مقایسه کنیم. ارزش مالی تصمیم شماره دو را ارزش مکانی (position value) آن مینامیم. ارزش مکانی یک تصمیم برابر است با ارزش مورد انتظار یا امید ریاضی شاخه متناظر (در این مثال، چند شاخه یا چنگال توسعه واحد). امید ریاضی به شکل ساده برابر است با میانگین مقادیر نتایج در صورت تکرار زیاد شرایط (بازده ۵۶۰۰ دلار در سال با احتمال ۸۶٪ و 4۰۰ دلار با احتمال 14٪).
به بیان دیگر، معدل 2۶۷2 دلار سود نصیب شرکت شیمیایی Stygian تا رسیدن به نقطه دو خواهد شد. حال این سوال پیش میآید که با توجه به این مقادیر بهترین تصمیم در نقطه شماره یک کدام است؟
به نگاره سرمایهگذاری شماره ۶ نگاه کنید. در قسمت بالای درخت و سمت راست، سود حاصل از پیشامدهای مختلف در صورت ساخت یک واحد بزرگ را مشاهده میکنید. در قسمت پایینی شاخههای مربوط به واحد تولیدی کوچک را میبینید. اگر تمام این سودها را در احتمال آنها ضرب کنیم، مقایسه زیر حاصل میشود:
گزینهی با امید ریاضی بزرگتر (سود مورد انتظار بیشتر) متناظر با ساخت واحد تولیدی بزرگ خواهد بود.
در نظر گرفتن زمان
اما چطور باید فواصل زمانی در سودهای آینده را به حساب آورد؟ رسم دورههای زمانی بین تصمیمهای متوالی در درخت تصمیم اهمیت زیادی دارد. در هر مرحله، بایستی ارزش زمانی سود یا هزینه را در نظر بگیریم. هر استانداردی انتخاب کنیم، ابتدا باید زمانی را به عنوان زمان مرجع در نظر بگیریم و ارزش تمامی مقادیر را برای امکان مقایسه در آن زمان به دست آوریم. این روش مشابه استفاده از نرخ تنزیل در بررسی امکانسنجی اقتصادی است. در این حالت تمامی مقادیر مالی باید متناسب با تورم یا نرخ تنزیل، تعدیل گردند.
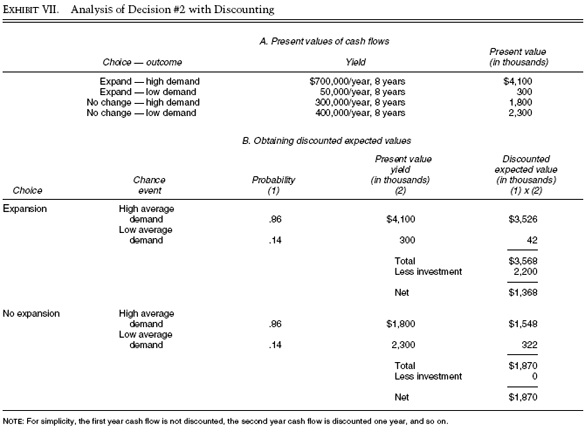
برای سادهسازی، نرخ تنزیل مورد نظر شرکت شیمیایی Stygian را برابر با 1۰٪ در سال در نظر میگیریم. با استفاده از قانون عقبگرد، دوباره با تصمیم شماره دو شروع میکنیم. با تنزیل مقادیر با نرخ 1۰٪، نتایج نگاره شماره هفت، قسمت A، به دست خواهد آمد. توجه کنید که این مقادیر، ارزش کنونی را در صورت اتخاذ تصمیم شماره دو نشان میدهند.
حال همان فرایند نگاره پنجم را اینبار با احتساب مقادیر تنزیل شده به دست میآوریم. این نتایج در قسمت B، نگاره شماره هفت نشان داده شدهاند. از آنجا که امید ریاضی تنزیلشده گزینه عدم توسعه بیشتر است، این شکل به شیوه بهتری ارزش مکانی نقطه تصمیم شماره دو را نشان میدهد.
بعد از انجام موارد ذکرشده، دوباره به سراغ تصمیم شماره یک خواهیم رفت. این محاسبات در نگاره شماره هشت نشان داده شده است. توجه کنید که ارزش مکانی نقطه شماره دو با فرض قرار گرفتن در نقطه شماره یک از نظر زمانی به دست آمده است.
واحد تولیدی بزرگ دوباره به عنوان انتخاب برتر شناسایی میگردد. اما حاشیه سود (margin) اینبار نسبت به مرتبه بدون تنزیل مقدار کمتری (2۹۰ هزار دلار) است.
گزینههای عدم قطعیت (Uncertainty Alternatives)
در نمایش مفهوم درخت تصمیم، با گزینههای موجود به عنوان موارد گسسته برخورد شد و احتمال وقوع هریک به صورت جداگانه به دست آمد. برای مثالهای قبل، از شرایط عدم قطعیت بر پایه یک متغیر مانند تقاضا، شکست یا موفقیت پروژه استفاده شد. سعی بر این بود تا از پیچیدگیهای غیر ضرور با تایید بر روابط بین تصمیمات حال و آینده و در نظر گرفتن عدم قطعیتها پرهیز شود.
در بسیاری از موارد، عناصر عدم قطعیت در قالب گزینههای تک متغیره گسسته بررسی میشوند. اما در بسیاری از موارد دیگر، احتمال سودآوری در مراحل مختلف به عوامل عدم قطعی بسیاری مانند هزینه، قیمت، بازده، شرایط اقتصادی و.. بستگی دارد. در این موارد، میتوان بازده مقادیر یا احتمالات جریان نقدینگی را در هر مرحله با دانش کافی نسبت به متغیرهای اصلی و عدم قطعیتهای متناظر به دست آورد. سپس میتوان احتمالات جریان نقدینگی را به دو، سه یا چند زیربخش تقسیم کرد تا به عنوان گزینههای گسسته مورد بررسی قرار گیرند.
نتیجهگیری
پیتر اف دراکر (Peter F. Drucker) به زیبایی رابطه بین برنامهریزی زمان حال و پیشامدهای آینده را توضیح داده است: «برنامهریزی بلند مدت با تصمیمات آینده سروکار ندارد. بلکه با آینده تصمیمات حاضر مرتبط است». تصمیمات امروز باید متاثر از نتیجه محتمل در آینده اتخاذ شوند. از آنجا که تصمیمات امروز پایه انتخابهای آینده را خواهند ساخت، باید تعادلی بین سودآوری و انعطافپذیری ایجان نمایند؛ این تصمیمات باید بین نیاز به سرمایهگذاری بر فرصتهای پرسود با ظرفیت عکسالعمل به شرایط و نیازهای آینده تعادل برقرار نمایند.
این ویژگی یکتای درخت تصمیم است که به مدیریت امکان تلفیق ابزارهای تحلیل را ارائه مینماید. با استفاده از درخت تصمیم مدیریت میتواند مسیری از انتخابها را با راحتی و شفافیت بیشتر دنبال کند. با این روش نتایج تصمیمات کاملا روشن خواهند بود.
البته بسیاری از جوانب کاربردی دیگر درخت تصمیم در تنها یک نوشته جای نمیگیرد. با مطالعه بیشتر و استفاده از روشهای متعدد، تحلیل شما جزیی و دقیقتر خواهد شد.
مطمئنا مفهوم درخت تصمیم پاسخ قطعی و نهایی سوال سرمایهگذاری را با توجه به عدم قطعیتها در اختیار مدیر قرار نخواهد داد. هنوز این ابزار قادر به پاسخگویی در این سطح نیست و احتمالا هرگز نخواهد بود. با اینحال درخت تصمیم از آن جهت ارزشمند است که ساختار تصمیم به سرمایهگذاری را شفاف میکند و به ارزیابی فرصتها کمک مینماید.
Decision Tree مفهومی است که اگر در نظر دارید تا تصمیم پیچیدهای بگیرید و یا میخواهید مسائل را برای خودتان به بخشهای کوچکتری تقسیم کرده تا به شکل بهتری قادر به حل آنها گردیده و ذهنتان را سازماندهی کنید، میتوانید از آن استفاده نمایید. در این پست قصد داریم تا همه چیز را در مورد درختهای تصمیمگیری مورد بررسی قرار دهیم؛ از جمله اینکه این مفهوم چه هست، چهطور مورد استفاده قرار میگیرد و همچنین چگونه میتوانیم دست به ایجاد یک درخت تصمیمگیری بزنیم.
آشنایی با مفهوم Decision Tree (درخت تصمیم)
به طور خلاصه، درخت تصمیم نقشهای از نتایج احتمالی یکسری از انتخابها یا گزینههای مرتبط بهم است به طوری که به یک فرد یا سازمان اجازه میدهد تا اقدامات محتمل را از لحاظ هزینهها، احتمالات و مزایا بسنجد. از درخت تصمیم میتوان یا برای پیشبرد اهداف و برنامههای شخصی و غیررسمی یا ترسیم الگوریتمی که بر اساس ریاضیات بهترین گزینه را پیشبینی میکند، استفاده کرد.
یک درخت تصمیمگیری به طور معمول با یک نُود اولیه شروع میشود که پس از آن پیامدهای احتمالی به صورت شاخههایی از آن منشعب شده و هر کدام از آن پیامدها به نُودهای دیگری منجر شده که آنها هم به نوبهٔ خود شاخههایی از احتمالات دیگر را ایجاد میکنند که این ساختار شاخهشاخه سرانجام به نموداری شبیه به یک درخت مبدل میشود. در درخت تصمیمگیری سه نوع Node (گِره) مختلف وجود دارد که عبارتند از:
نُود تصادفی، که توسط یک دایره نشان داده میشود، نمایانگر احتمال وقوع یکسری نتایج خاص است، نُود تصمیمگیری، که توسط یک مربع نشان داده میشود، تصمیمی که میتوان اتخاذ کرد را نشان میدهد و همچنین نُود پایانی نمایانگر پیامد نهایی یک مسیر تصمیمگیری خواهد بود.
درختهای تصمیمگیری را میتوان با سَمبولها یا علائم فلوچارت نیز رسم کرد که در این صورت برای برخی افراد، به خصوص دولوپرها، درک و فهم آن آسانتر خواهد بود.
چهطور می توان اقدام به کشیدن یک Decision Tree کرد؟
به منظور ترسیم یک درخت تصمیم، ابتدا وسیله و ابزار مورد نظرتان را انتخاب کنید (میتوانید آن را با قلم و کاغذ یا وایتبرد کشیده یا اینکه میتوانید از نرمافزارهای مرتبط با این کار استفاده کنید.) فارغ از اینکه چه ابزاری انتخاب میکنید، میبایست به منظور ترسیم یک درخت تصمیم اصولی، مراحل زیر را دنبال نمایید:
۱- کار با تصمیم اصلی آغاز کنید که برای این منظور از یک باکس یا مستطیل کوچک استفاده کرده، سپس از آن مستطیل به ازای هر راهحل یا اقدام احتمالی خطی به سمت راست/چپ کشیده و مشخص کنید که هر خط چه معنایی دارد.
۲- نُودهای تصادفی و تصمیمگیری را به منظور شاخ و برگ دادن به این درخت، به طریق پایین رسم کنید:
ـ اگر تصمیم اصلی دیگری وجود دارد، مستطیل دیگری رسم کنید. ـ اگر پیامدی قطعی نیست، یک دایره رسم کنید (دایرهها نمایانگر نُودهای تصادفی هستند.) ـ اگر مشکل حل شده، آن را فعلاً خالی بگذارید.
از هر نُود تصمیمگیری، راههای احتمالی را منشعب کنید به طوری که برای هر کدام از نُودهای تصادفی، خطوطی کشیده و به وسیلهٔ آن خطوط پیامدهای احتمالی را نشان دهید و اگر قصد دارید گزینههای پیش روی خود را به صورت عددی و درصدی آنالیز کنید، احتمال وقوع هر کدام از پیشامدها را نیز یادداشت کنید.
۳- به بسط این درخت ادامه دهید تا زمانی که هر خط به نقطهٔ پایانی برسد (یعنی تا جایی که انتخابهای دیگری وجود نداشته و پیامدهای احتمالی دیگری برای در نظر گرفتن وجود نداشته باشد.) در ادامه، برای هر پیشامد احتمالی یک مقدار تعیین کنید که این مقدار میتواند یک نمرهٔ فرضی یا یک مقدار واقعی باشد. همچنین به خاطر داشته باشید که برای نشان دادن نقاط پایانی، از مثلث استفاده کنید.
حال با داشتن یک درخت تصمیم کامل، میتوانید تصمیمی که با آن مواجه هستید را تجزیه و تحلیل کنید.
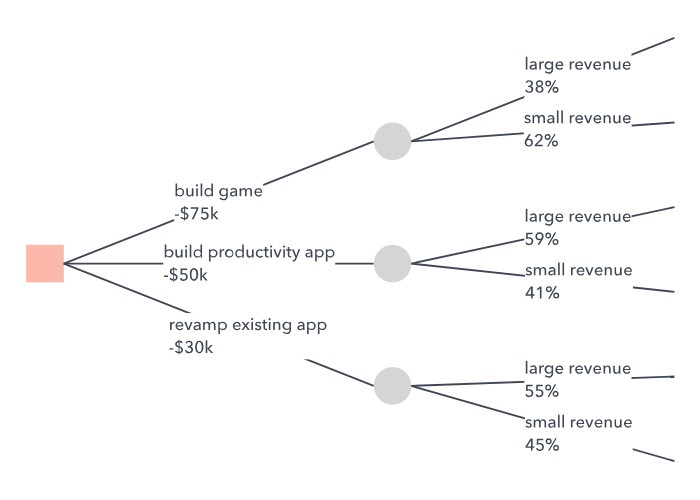
مثالی از پروسهٔ تجزیه و تحلیل Decision Tree با محاسبهٔ سود یا مقدار مورد انتظار از هر انتخاب در درخت مد نظر خود، میتوانید ریسک را به حداقل رسانده و احتمال دستیابی به یک پیامد یا نتیجهٔ مطلوب و مورد انتظار را بالا ببرید. به منظور محاسبهٔ سود مورد انتظار یک گزینه، تنها کافی است هزینهٔ تصمیم را از مزایای مورد انتظار آن کسر کنید (مزایای مورد انتظار برابر با مقدار کلی تمام پیامدهایی است که میتوانند از یک انتخاب ناشی شوند که در چنین شرایطی هر مقدار در احتمال پیشامد ضرب شده است.) برای مثالی که در تصاویر بالا زدهایم، بدین صورت این مقادیر را محاسبه خواهیم کرد:
زمانی که قصد داریم دست به تعیین مطلوبترین پیامد بزنیم، مهم است که ترجیحات تصمیمگیرنده را نیز مد نظر داشته باشیم چرا که برخی افراد ممکن است گزینههای کمریسک را ترجیح داده و برخی دیگر حاضر باشند برای یک سود بزرگ، دست به ریسکهای بزرگی هم بزنند.
هنگامی که از درخت تصمیمتان به همراه یک مدل احتمالی استفاده میکنید، میتوانید از ترکیب این دو برای محاسبهٔ احتمال شرطی یک رویداد، یا احتمال پیشامد آن اتفاق با در نظر گرفتن رخ دادن دیگر اتفاقات استفاده کنید که برای این منظور، همانطور که در تصویر فوق مشاهده میشود، کافی است تا از رویداد اولیه شروع کرده، سپس مسیر را از آن رویداد تا رویداد هدف دنبال کنید و در طی مسیر احتمال هر کدام از آن رویدادها را در یکدیگر ضرب نمایید که بدین ترتیب میتوان از یک درخت تصمیم به شکل یک نمودار درختی سنتی بهره برد که نشانگر احتمال رخداد رویدادهای خاص (مثل دو بار بالا انداختن یک سکه) میباشد.
آشنایی با برخی مزایا و معایب Decision Tree
در میان متخصصین در صنایع مختلف، مدیران و حتی دولوپرها، درختهای تصمیم محبوباند چرا که درک آنها آسان بوده و به دیتای خیلی پیچیده و دقیقی احتیاج ندارند، میتوان در صورت لزوم گزینههای جدیدی را به آنها اضافه کرد، در انتخاب و پیدا کردن بهترین گزینه از میان گزینههای مختلف کارآمد هستند و همچنین با ابزارهای تصمیمگیری دیگر به خوبی سازگاری دارند.
با تمام اینها، درختهای تصمیم ممکن است گاهی به شدت پیچیده شوند! در چنین مواردی یک به اصطلاح Influence Diagram جمع و جورتر میتواند جایگزین بهتری برای درخت تصمیم باشد به طوری که این دست نمودارها توجه را به تصمیمات حساس، اطلاعات ورودی و اهداف محدود میکنند.
کاربرد Decision Tree در حوزهٔ ماشین لرنینگ و دیتا ماینینگ
از درخت تصمیم میتوان به منظور ایجاد مُدلهای پیشبینی خودکار استفاده کرد که در حوزهٔ یادگیری ماشینی، استخراج داده و آمار کاربردی هستند. این روش که تحت عنوان Decision Tree Learning شناخته میشود، به بررسی مشاهدات در مورد یک آیتم به جهت پیشبینی مقدارش میپردازد و به طور کلی، در چنین درخت تصمیمی، نُودها نشاندهندهٔ دیتا هستند نَه تصمیمات. این نوع درختها همچنین تحت عنوان Classification Tree نیز شناخته میشوند به طوری که هر شاخه در برگیرندهٔ مجموعهای از ویژگیها یا قوانین طبقهبندی دیتا است و مرتبط با یک دستهٔ خاص میباشد که در انتهای هر شاخه یافت میشود.
این دست قوانین که تحت عنوان Decision Rules شناخته میشوند قابل بیان به صورت جملات شرطی میباشند (مثلاً اگر شرایط ۱ و ۲ و ۳ محقق شوند، با قطعیت میتوان گفت که X نتیجهای همچون Y برخواهد گرداند.) هر مقدار دادهٔ اضافی به مدل کمک میکند تا دقیقتر پیشبینی کند که مسئلهٔ مورد نظر به کدام مجموعه از مقادیر متعلق میباشد و این در حالی است که از این اطلاعات بعداً میتوان به عنوان ورودی در یک مدل تصمیمگیری بزرگتر استفاده کرد.
درختهای تصمیمگیری که پیامدهای محتمل پیدرپی و بینهایت دارند، Regression Tree نامیده میشوند. به طور کلی، متدهای کاربردی در این حوزه به صورت زیر دستهبندی میشوند:
– Bagging: در این متد با نمونهسازی مجدد دیتای سورس، چندین درخت ایجاد شده سپس با برداشتی که از آن درختان میشود، تصمیم نهایی گرفته شده یا نتیجهٔ نهایی به دست میآید.
– Random Forest: در این متد طبقهبندی از چندین درخت تشکیل شده که به منظور افزایش نرخ کلاسیفیکیشن طراحی شدهاند.
– Boosted: درختهایی از این جنس میتوانند برای رگرسیون مورد استفاده قرار گیرند.
– Rotation Forest: در این متد، همگی درختها توسط یک به اصطلاح Principal Component Analysis با استفاده از بخشی از دادههای تصادفی آموزش داده میشوند.
درخت تصمیمگیری زمانی مطلوب تلقی میشود که نشاندهندهٔ بیشترین دیتا با حداقل شاخه باشد و این در حالی است که الگوریتمهایی که برای ایجاد درختهای تصمیمگیری مطلوب طراحی شدهاند شامل CART ،ASSISTANT ،CLS و ID31415 میشوند. در واقع، هر کدام از این متدها باید تعیین کنند که بهترین راه برای تقسیم داده در هر شاخه کدام است که از متدهای رایجی که بدین منظور استفاده میشوند میتوان به موارد زیر اشاره کرد:
– Gini Impurity – Information Gain – Variance Reduction
استفاده از درختهای تصمیمگیری در یادگیری ماشینی چندین مزیت عمده دارد منجمله هزینه یا بهای استفاده از درخت به منظور پیشبینی داده با اضافه کردن هر به اصطلاح Data Point کاهش مییابد و این در حالی است که از جمله دیگر مزایایش میتوان به موارد زیر اشاره کرد:
– برای دادههای طبقهبندی شده و عددی به خوبی پاسخگو است. – میتواند مسائل با خروجیهای متعدد را مدلسازی کند. – میتوان قابلیت اطمینان به درخت را مورد آزمایش و اندازهگیری قرار داد. – صرفنظر از اینکه آیا فرضیات دادهٔ منبع را نقض میکنند یا خیر، این روش به نظر دقیق میرسد.
اما Decision Tree در ML معایبی نیز دارا است که از جملهٔ مهمترین آنها میتوان به موارد زیر اشاره کرد:
– حین مواجه با دادههای طبقهبندی شده با سطوح مختلف، دادههای حاصله تحتتأثیر ویژگیها یا صفاتی که بیشترین شاخه را دارند قرار میگیرد. – در صورت رویارویی با پیامدهای نامطمئن و تعداد زیادی پیامد بهم مرتبط، محاسبات ممکن است خیلی پیچیده شود. – ارتباطات بین نُودها محدود به AND بوده حال آنکه یک Decision Graph این اجازه را به ما میدهند تا نُودهایی داشته باشیم که با OR به یکدیگر متصل شدهاند.
درخت تصمیم گیری (Decision Tree) یک ابزار برای پشتیبانی از تصمیم است که از درختها برای مدل کردن استفاده میکند. درخت تصمیم بهطور معمول در تحقیقها و عملیات مختلف استفاده میشود. بهطور خاص در آنالیز تصمیم، برای مشخص کردن استراتژی که با بیشترین احتمال به هدف برسد بکار میرود. استفاده دیگر درختان تصمیم، توصیف محاسبات احتمال شرطی است.
کلیات
در آنالیز تصمیم، یک درخت تصمیم به عنوان ابزاری برای به تصویر کشیدن و آنالیز تصمیم، در جایی که مقادیر مورد انتظار از رقابتها متناوباً محاسبه میشود، استفاده میگردد. یک درخت تصمیم دارای سه نوع گرهاست:
۱-گره تصمیم: بهطور معمول با مربع نشان داده میشود.
۲-گره تصادفی: با دایره مشخص میشود.
۳-گره پایانی: با مثلث مشخص میشود.
Traditionally, decision trees have been created manually
نمودار درخت تصمیم گیری
یک درخت تصمیم میتواند خیلی فشرده در قالب یک دیاگرام، توجه را بر روی مسئله و رابطه بین رویدادها جلب کند. مربع نشان دهنده تصمیمگیری، بیضی نشان دهنده فعالیت، و لوزی نشان دهنده نتیجه است.
مکانهای مورد استفاده
درخت تصمیم، دیاگرام تصمیم و ابزارها و روشهای دیگر مربوط به آنالیز تصمیم به دانشجویان دوره لیسانس در مدارس تجاری و اقتصادی و سلامت عمومی و تحقیق در عملیات و علوم مدیریت، آموخته میشود.
یکی دیگر از موارد استفاده از درخت تصمیم، در علم دادهکاوی برای classification است.
الگوریتم ساخت درخت تصمیمگیری
مجموع دادهها را با نمایش میدهیم، یعنی، به قسمی که و . درخت تصمیمگیری سعی میکند بصورت بازگشتی دادهها را به قسمی از هم جدا کند که در هر گِرِه متغیرهای مستقلِ به هم نزدیک شده همسان شوند. هر گِره زیر مجموعه ای از داده هاست که بصورت بازگشتی ساخته شده است. به طور دقیقتر در گره اگر داده ما باشد سعی میکنیم یک بُعد از متغیرهایی وابسته را به همراه یک آستانه انتخاب کنیم و دادهها را برحسب این بُعد و آستانه به دو نیم تقسیم کنیم، به قسمی که بطور متوسط در هر دو نیم متغیرهای مستقل یا خیلی به هم نزدیک و همسان شده باشند. این بعد و آستانه را مینامیم. دامنه برابر است با و یک عدد صحیح است. برحسب به دو بخش و به شکل پایین تقسیم می شود:
حال سؤال اینجاست که کدام بُعد از متغیرهای وابسته و چه آستانهای را باید انتخاب کرد. به زبان ریاضی باید آن یی را انتخاب کرد که ناخالصی داده را کم کند. ناخالصی برحسب نوع مسئله تعریفی متفاوت خواهد داشت، مثلا اگر مسئله یک دستهبندی دوگانه است، ناخالصی میتواند آنتراپی داده باشد، کمترین ناخالصی زمانی است که هم و هم از یک دسته داشته باشند، یعنی در هر کدام از این دو گِرِه دو نوع دسته وجود نداشته باشد. برای رگرسیون این ناخالصی می تواند واریانس متغیر وابسته باشد. از آنجا که مقدار داده در و با هم متفاوت است میانگینی وزندار از هر دو ناخالصی را به شکل پایین محاسبه میکنیم. در این معادله ، و :
هدف در اینجا پیدا کردن آن یی است که ناخالصی را کمینه کند، یعنی . حال همین کار را بصورت بازگشتی برای و انجام میدهیم. بعضی از گره ها را باید به برگ تبدیل کنیم، معیاری که برای تبدیل یک گره به برگ از آن استفاده میکنیم میتواند مقداری حداقلی برای (تعداد داده در یک گره) و یا عمق درخت باشد به قسمی که اگر با دو نیم کردن گِره یکی از معیارها عوض شود، گِره را به دو نیم نکرده آنرا تبدیل به یک برگ میکنیم. معمولا این دو پارامتر باعث تنظیم مدل (Regularization) میشوند. در ابتدای کار گره شامل تمام دادهها میشود یعنی.
مسئله دستهبندی
اگر مسئله ما دستهبندی باشد و باشد تابع ناخالصی برای گره میتواند یکی از موارد پایین باشد، در این معادلهها
ناخالصی گینی:
ناخالصی آنتروپی:
ناخالصی خطا:
مسئله رگرسیون
در مسئله رگرسیون ناخالصی میتواند یکی از موارد پایین باشد:
میانگین خطای مربعات:
میانگین خطای قدر مطلق:
مزایا
در میان ابزارهای پشتیبانی تصمیم، درخت تصمیم و دیاگرام تصمیم دارای مزایای زیر هستند:
۱- فهم ساده: هر انسان با اندکی مطالعه و آموزش میتواند، طریقه کار با درخت تصمیم را بیاموزد.
۲- کار کردن با دادههای بزرگ و پیچیده: درخت تصمیم در عین سادگی میتواند با دادههای پیچیده به راحتی کار کند و از روی آنها تصمیم بسازد.
۳-استفاده مجدد آسان: در صورتی که درخت تصمیم برای یک مسئله ساخته شد، نمونههای مختلف از آن مسئله را میتوان با آن درخت تصمیم محاسبه کرد.
۴- قابلیت ترکیب با روشهای دیگر: نتیجه درخت تصمیم را میتوان با تکنیکهای تصمیمسازی دیگر ترکیب کرده و نتایج بهتری بدست آورد.
معایب
۱- مشکل استفاده از درختهای تصمیم آن است که به صورت نمایی با بزرگ شدن مسئله بزرگ میشوند. ۲- اکثر درختهای تصمیم تنها از یک ویژگی برای شاخه زدن در گرهها استفاده میکنند در صورتی که ممکن است ویژگیها دارای توزیع توأم باشند. ۳- ساخت درخت تصمیم در برنامههای داده کاوی حافظه زیادی را مصرف میکند زیرا برای هر گره باید معیار کارایی برای ویژگیهای مختلف را ذخیره کند تا بتواند بهترین ویژگی را انتخاب کند.



























![{\displaystyle [1,\cdots ,d]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1f0cb2b735303a718bd517e38e758ac6d49ef6a9)












![{\displaystyle y_{i}\in [1,\cdots ,K]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7be8cb4ab377a7ad30972f691d5c72247d873131)





