بایگانی برچسب برای: gh; o
رگرسیون لجستیک (Logistic regression) یک مدل آماری رگرسیون برای متغیرهای وابسته دوسویی مانند بیماری یا سلامت، مرگ یا زندگی است. این مدل را میتوان به عنوان مدل خطی تعمیمیافتهای که از تابع لوجیت به عنوان تابع پیوند استفاده میکند و خطایش از توزیع چندجملهای پیروی میکند، بهحسابآورد. منظور از دو سویی بودن، رخ داد یک واقعه تصادفی در دو موقعیت ممکنه است. به عنوان مثال خرید یا عدم خرید، ثبت نام یا عدم ثبت نام، ورشکسته شدن یا ورشکسته نشدن و … متغیرهایی هستند که فقط دارای دو موقعیت هستند و مجموع احتمال هر یک آنها در نهایت یک خواهد شد.
کاربرد این روش عمدتاً در ابتدای ظهور در مورد کاربردهای پزشکی برای احتمال وقوع یک بیماری مورد استفاده قرار میگرفت. لیکن امروزه در تمام زمینههای علمی کاربرد وسیعی یافتهاست. به عنوان مثال مدیر سازمانی میخواهد بداند در مشارکت یا عدم مشارکت کارمندان کدام متغیرها نقش پیشبینی دارند؟ مدیر تبلیغاتی میخواهد بداند در خرید یا عدم خرید یک محصول یا برند چه متغیرهایی مهم هستند؟ یک مرکز تحقیقات پزشکی میخواهد بداند در مبتلا شدن به بیماری عروق کرنری قلب چه متغیرهایی نقش پیشبینیکننده دارند؟ تا با اطلاعرسانی از احتمال وقوع کاسته شود.
رگرسیون لجستیک میتواند یک مورد خاص از مدل خطی عمومی و رگرسیون خطی دیده شود. مدل رگرسیون لجستیک، بر اساس فرضهای کاملاً متفاوتی (دربارهٔ رابطه متغیرهای وابسته و مستقل) از رگرسیون خطی است. تفاوت مهم این دو مدل در دو ویژگی رگرسیون لجستیک میتواند دیده شود. اول توزیع شرطی یک توزیع برنولی به جای یک توزیع گوسی است چونکه متغیر وابسته دودویی است. دوم مقادیر پیشبینی احتمالاتی است و محدود بین بازه صفر و یک و به کمک تابع توزیع لجستیک بدست میآید رگرسیون لجستیک احتمال خروجی پیشبینی میکند.

این مدل به صورت

است که


برآورد پارامترهای بهینه
برای بدست آوردن پارامترهای بهینه یعنی میتوان از روش برآورد درست نمایی بیشینه (Maximum Likelihood Estimation) استفاده کرد. اگر فرض کنیم که تعداد مثالهایی که قرار است برای تخمین پارامترها استفاده کنیم است و این مثالها را به این شکل نمایش دهیم . پارامتر بهینه پارامتری است که برآورد درست نمایی را بیشینه کند، البته برای سادگی کار برآورد لگاریتم درست نمایی را بیشینه میکنیم. لگاریتم درست نمایی داده برای پارامتر را با نمایش میدهیم:
![{\displaystyle {\vec {\beta }}=[\beta _{0},\beta _{1},\cdots ,\beta _{k}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bdc88718ceff56832c5b289e0604368f643eea58)






اگر برای داده ام باشد، هدف افزایش است و اگر صفر باشد هدف افزایش مقدار است. از این رو از فرمول استفاده میکنیم که اگر باشد، فرمول به ما را بدهد و اگر بود به ما را بدهد.







حال برای بدست آوردن پارامتر بهینه باید یی پیدا کنیم که مقدار را بیشینه کند. از آنجا که این تابع نسبت به مقعر است حتماً یک بیشینه مطلق دارد. برای پیدا کردن جواب میتوان از روش گرادیان افزایشی از نوع تصادفی اش استفاده کرد (Stochastic Gradient Ascent). در این روش هر بار یک مثال را بهصورت اتفاقی از نمونههای داده انتخاب کرده، گرادیان درست نمایی را حساب میکنیم و کمی در جهت گرادیان پارامتر را حرکت میدهیم تا به یک پارامتر جدید برسیم. گرادیان جهت موضعی بیشترین افزایش را در تابع به ما نشان میدهد، برای همین در آن جهت کمی حرکت میکنیم تا به بیشترین افزایش موضعی تابع برسیم. اینکار را آنقدر ادامه میدهیم که گرادیان به اندازه کافی به صفر نزدیک شود. بجای اینکه دادهها را بهصورت تصادفی انتخاب کنیم میتوانیم به ترتیب داده شماره تا داده شماره را انتخاب کنیم و بعد دوباره به داده اولی برگردیم و این کار را بهصورت متناوب چندین بار انجام دهیم تا به اندازه کافی گرادیان به صفر نزدیک شود. از لحاظ ریاضی این کار را میتوان به شکل پایین انجام داد، پارامتر را در ابتدا بهصورت تصادفی مقدار دهی میکنیم و بعد برای داده ام و تمامی ها، یعنی از تا تغییر پایین را اعمال میکنیم، دراینجا همان مقداریست که در جهت گرادیان هربار حرکت میکنیم و مشتق جزئی داده ام در بُعد ام است:







تنظیم مدل (Regularization)
پیچیدگی مدلهای پارامتری با تعداد پارامترهای مدل و مقادیر آنها سنجیده میشود. هرچه این پیچیدگی بیشتر باشد خطر بیشبرازش (Overfitting) برای مدل بیشتر است. پدیده بیشبرازش زمانی رخ میدهد که مدل بجای یادگیری الگوهای داده، داده را را حفظ کند و در عمل، فرایند یادگیری به خوبی انجام نمیشود. برای جلوگیری از بیشبرازش در مدلهای خطی مانند رگرسیون خطی یا رگرسیون لجستیک جریمهای به تابع هزینه اضافه میشود تا از افزایش زیاد پارامترها جلوگیری شود. تابع هزینه را در رگرسیون لجستیک با منفی لگاریتم درستنمایی تعریف میکنیم تا کمینه کردن آن به بیشینه کردن تابع درست نمایی بیانجامد. به این کار تنظیم مدل یا Regularization گفته میشود. دو راه متداول تنظیم مدلهای خطی روشهای و هستند. در روش ضریبی از نُرمِ به تابع هزینه اضافه میشود و در روش ضریبی از نُرمِ که همان نُرمِ اقلیدسی است به تابع هزینه اضافه میشود.


در تنظیم مدل به روش تابع هزینه را به این شکل تغییر میدهیم:

این روش تنظیم مدل که به روش لاسو (Lasso) نیز شهرت دارد باعث میشود که بسیاری از پارامترهای مدل نهائی صفر شوند و مدل به اصطلاح خلوت (Sparse) شود.
در تنظیم مدل به روش تابع هزینه را به این شکل تغییر میدهیم:

در روش تنظیم از طریق سعی میشود طول اقلیدسی بردار کوتاه نگه داشته شود. در روش و یک عدد مثبت است که میزان تنظیم مدل را معین میکند. هرچقدر کوچکتر باشد جریمه کمتری برا بزرگی نرم بردار پارامترها یعنی پرداخت میکنیم. مقدار ایدئال از طریق آزمایش بر روی داده اعتبار (Validation Data) پیدا میشود.

تفسیر احتمالی تنظیم مدل
اگر بجای روش درست نمایی بیشینه از روش بیشینه سازی احتمال پسین استفاده کنیم به ساختار «تنظیم مدل» یا همان regularization خواهیم رسید. اگر مجموعه داده را با نمایش بدهیم و پارامتری که به دنبال تخمین آن هستیم را با ، احتمال پسین ، طبق قانون بیز متناسب خواهد بود با حاصلضرب درست نمایی یعنی و احتمال پیشین یعنی:




ازین رو

معادله خط پیشین نشان میدهد که برای یافتن پارامتر بهینه فقط کافیست که احتمال پیشین را نیز در معادله دخیل کنیم. اگر احتمال پیشین را یک توزیع احتمال با میانگین صفر و کوواریانس در نظر بگیریم به معادله پایین میرسیم:


با ساده کردن این معادله به نتیجه پایین میرسیم:

با تغییر علامت معادله، بیشینهسازی را به کمینهسازی تغییر میدهیم، در این معادله همان است:


همانطور که دیدیم جواب همان تنظیم مدل با نرم است.
حال اگر توزیع پیشین را از نوع توزیع لاپلاس با میانگین صفر در نظر بگیریم به تنظیم مدل با نرم خواهیم رسید.
از آنجا که میانگین هر دو توزیع پیشین صفر است، پیشفرض تخمین پارامتر بر این بنا شدهاست که اندازه پارامتر مورد نظر کوچک و به صفر نزدیک باشد و این پیشفرض با روند تنظیم مدل همخوانی دارد.
منبع
رگرسیون لوژستیک (لجستیک)
زمانی که متغیر وابسته ی ما دو وجهی (دو سطحی مانند جنسیت، بیماری یا عدم بیماری و …) است و می خواهیم از طریق ترکیبی از متغیرهای پیش بین دست به پیش بینی بزنیم باید از رگرسیون لجستیک استفاده کنیم. چند مثال از کاربردهای رگرسیون لجستیک در زیر ارائه می گردد.
1. در فرایند همه گیر شناسی ما می خواهیم ببینیم آیا یک فرد بیمار است یا خیر. اگر به عنوان مثال بیماری مورد نظر بیماری قلبی باشد پیش بینی کننده ها عبارتند از سن، وزن، فشار خون سیستولیک، تعداد سیگارهای کشیده شده و سطح کلسترول.
2. در بازاریابی ممکن است بخواهیم بدانیم آیا افراد یک ماشین جدیدی را می خرند یا خیر. در اینجا متغیرهایی مانند درآمد سالانه، مقدار پول رهن، تعداد وابسته ها، متغیرهای پیش بین می باشند.
3. در تعلیم و تربیت فرض کنید می خواهیم بدانیم یک فرد در امتحان نمره می آورد یا خیر.
4. در روانشناسی می خواهیم بدانیم آیا فرد یک رفتار بهنجار اجتماعی دارد یا خیر.
در تمام موارد گفته شده متغیر وابسته یک متغیر دو حالتی است که دو ارزش دارد. زمانی که متغیر وابسته دو حالتی است مسایل خاصی مطرح می شود.
1. خطا دارای توزیع نرمال نیست. 2. واریانس خطا ثابت نیست. 3. محدودیت های زیادی در تابع پاسخ وجود دارد. مشکل سوم مطرح شده مشکل جدی تری است.
می توان از روش حداقل مجذورات وزنی برای حل مشکل مربوط به واریانس های نابرابر خطا استفاده نمود. بعلاوه زمانی که حجم نمونه بالا باشد می توان روش حداقل مجذورات برآوردگرهایی را ارائه می دهد که به طور مجانبی و تحت موقعیت های نسبتا عمومی نرمال می باشند. ما در رگرسیون لجستیک به طور مستقیم احتمال وقوع یک رخداد را محاسبه می کنیم. چرا که فقط دو حالت ممکن برای متغیر وابسته ی ما وجود دارد.
دو مساله ی مهم که باید در ارتباط با رگرسیون لجستیک در نظر داشته باشیم عبارتند از:
1. رابطه ی بین پیش بینی کننده ها و متغیر وابسته غیر خطی است.
2. ضرایب رگرسیونی از طریق روش ماکزیمم درستنمایی برآورد می شود.
رگرسیون لجستیک از لحاظ محاسبات آماری شبیه رگرسیون چند گانه است اما از لحاظ کارکرد مانند تحلیل تشخیصی می باشد. در این روش عضویت گروهی بر اساس مجموعه ای از متغییرهای پیش بین انجام می شود دقیقا مانند تحلیل تشخیصی. مزیت عمده ای که تحلیل لجستیک نسبت به تحلیل تشخیصی دارد این است که در این روش با انواع متغیرها به کار می رود و بنابراین بسیاری از مفروضات در مورد داده ها را به کار ندارد. در حقیقت آنچه در رگرسیون لجستیک پیش بینی می شود یک احتمال است که ارزش آن بین 0 تا 1 در تغییر است. ضرایب رگرسیونی مربوط به معادله ی رگرسیون لجستیک اطلاعاتی را راجع به شانس هر مورد خاص برای تعلق به گروه صفر یا یک ارائه می دهد. شانس به صورت احتمال موفقیت در برابر شکست تعریف می شود. ولی بدلیل ناقرینگی و امکان وجود مقادیر بی نهایت برای آن تبدیل به لگاریتم شانس می شود. هر یک از وزن ها را می توان از طریق مقدار خی دو که به آماره ی والد مشهور است به لحاظ معناداری آزمود. لگاریتم شانس، شانسی را که یک متغییر به طور موفقیت آمیزی عضویت گروهی را برای هر مورد معین پیش بینی می کند را نشان می دهد.
به طور کلی در روش رگرسیون لجستیک رابطه ی بین احتمال تعلق به گروه 1 و ترکیب خطی متغیرهای پیش بین بر اساس توزیع سیگمودال تعریف می شود. برای دستیابی به معادله ی رگرسیونی و قدرت پیش بینی باید به نحوی بتوان رابطه ای بین متغیرهای پیش بین و وابسته تعریف نمود. برای حل این مشکل از نسبت احتمال تعلق به گروه یک به احتمال تعلق به گروه صفر استفاده می شود. به این نسبت شانس OR گویند. به خاطر مشکلات شانس از لگاریتم شانس استفاده می شود. لگاریتم شانس با متغیرهای پیش بینی کننده ارتباط خطی دارد. بنابراین ضرایب بدست آمده برای آن باید بر اساس رابطه ی خطی که با لگاریتم شانس دارند تفسیر گردند. بنابراین اگر بخواهیم تفسیر را بر اساس احتمال تعلق به گروهها انجام دهیم باید لگاریتم شانس را به شانس و شانس را به اجزای زیر بنایی آن که احتمال تعلق است تبدیل نماییم. آماره ی والد که از توزیع خی دو پیروی می کند نیز برای بررسی معناداری ضرایب استفاده می شود. از آزمون هاسمر و لمشو نیز برای بررسی تطابق داده ها با مدل استفاده می شود معنادار نبودن این آزمون که در واقع نوعی خی دو است به معنای عدم تفاوت داده ها با مدل یعنی برازش داده با مدل است.
رگرسیون چند متغیری: در این رگرسیون هدف این است که از طریق مجموعه ای از متغیرهای پیش بین به پیش بینی چند متغیر وابسته پرداخته شود در واقع اتفاقی که در رگرسیون کانونی می افتد.
رگرسیون لجستیک (LOGESTIC REGRESSION)
همان طور که میدانیم در رگرسیون خطی، متغیر وابسته یک متغیر کمی در سطح فاصلهای یا نسبی است و پیش بینی کننده ها از نوع متغیرهای پیوسته، گسسته یا ترکیبی از این دو هستند. اما هنگامی که متغیر وابسته در کمی نباشد، یعنی به صورت دو یا چندمقولهای باشد، از رگرسیون لجستیک استفاده میکنیم که امکان پیشبینی عضویت گروهی را فراهم میکند. این روش موازی روشهای تحلیل تشخیصی و تحلیل لگاریتمی است. برای مثال، پیش بینی مرگ و میر نوزادان بر اساس جنسیت نوزاد، دوقلو بودن و سن و تحصیلات مادر.
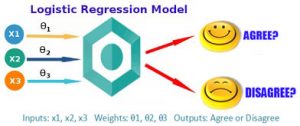
بسیاری از مطالعات پژوهشی در علوم اجتماعی و علوم رفتاری، متغیرهای وابسته از نوع دو مقوله ای را بررسی میکنند. مانند: رأی دادن یا ندادن در انتخابات، مالکیت (مثلاٌ داشتن یا نداشتن کامپیوتر شخصی) و سطح تحصیلات (مانند: داشتن یا نداشتن تحصیلات دانشگاهی) ارزیابی میشود. از جمله حالت های پاسخ دوتایی عبارتند از: موافق- مخالف، موفقیت – شکست، حاضر – غایب و جانبداری – عدم جانبداری.
متغیرهای تحلیل رگرسیون لجستیک
در تحلیل رگرسیون لجستیک، همیشه یک متغیر وابسته و معمولا مجموعه ای از متغیرهای مستقل وجود دارند که ممکن است دو مقوله ای، کمی یا ترکیبی از آن ها باشند. به علاوه لازم نیست متغیرهای دو مقوله ای به طور واقعی دوتایی باشند. به عنوان مثال ممکن است پژوهشگران متغیر وابسته کمی دارای کجی شدید را به یک متغیر دومقوله ای که در هر طبقه آن تعداد موردها تقریباً مساوی است تبدیل کنند. مانند آن چه که در مورد رگرسیون چندگانه دیدیم، برخی از متغیرهای مستقل در رگرسیون لجستیک می توانند به عنوان متغیرهای همپراش (covariates) مورد استفاده قرار گیرند تا پژوهشگران بتوانند با ثابت نگه داشتن یا کنترل آماری این متغیرها اثرات دیگر متغیرهای مستقل را بهتر ارزیابی کنند.
پیش فرض های رگرسیون لجستیک
با این که رگرسیون لجستیک در مقایسه با رگرسیون خطی پیش فرض های کمتری دارد (به عنوان مثال پیش فرض های همگنی واریانس و نرمال بودن خطاها وجود ندارد)، رگرسیون لجستیک نیازمند موارد زیر است:
- هم خطی چندگانه کامل وجود نداشته باشد.
- خطاهای خاص نباید وجود داشته باشد (یعنی، همه متغیرهای پیش بین مرتبط وارد شوند و پیش بین های نامربوط کنار گذاشته شوند).
- متغیرهای مستقل باید در مقیاس پاسخ تراکمی یا جمع پذیر (cumulative response scale)، فاصله ای یا سطح نسبی اندازه گیری شده باشند (هر چند که متغیرهای دو مقوله ای نیز می توانند مورد استفاده قرار گیرند).
برای تفسیر درست نتایج، رگرسیون لجستیک در مقایسه با رگرسیون خطی نیازمند نمونه های بزرگتری است. با این که آماردان ها در خصوص شرایط دقیق نمونه توافق ندارند. بسیاری پیشنهاد می کنند تعداد افراد نمونه حداقل باید ۳۰ برابر تعداد پارامترهایی باشند که برآورد می شوند.
منبع
رگرسیون لجستیک چیست؟
رگرسیون لجستیک، شبیه رگرسیون خطی است با این تفاوت که نحوه محاسبه ضرایب در این دو روش یکسان نمی باشد. بدین معنی که رگرسیون لجستیک، به جای حداقل کردن مجذور خطاها (کاری که رگرسیون خطی انجام می دهد)، احتمالی را که یک واقعه رخ می دهد، حداکثر می کند. همچنین، در تحلیل رگرسیون خطی، برای آزمون برازش مدل و معنی داربودن اثر هر متغیر در مدل، به ترتیب از آماره های Fوt استفاده می شود، در حالی که در رگرسیون لجستیک، از آماره های کای اسکوئر(X2) و والد استفاده می شود (مومنی، ۱۳۸۶: ۱۵۸).
رگرسیون لجستیک نسبت به تحلیل تشخیصی نیز ارجحیت دارد و مهم ترین دلیل آن است که در تحلیل تشخیصی گاهی اوقات احتمال وقوع یک پدیده خارج از طیف(۰) تا (۱) قرار می گیرد و متغیرهای پیش بین نیز باید دارای توزیع در داخل محدوده (۰) تا (۱) قرار دارد و رعایت پیش فرض نرمال بودن متغیرهای پیش بینی لازم نیست (سرمد، ۱۳۸۴: ۳۳۱).
انواع رگرسیون لجستیک
همان طور که در ابتدای مبحث تحلیل رگرسیون لجستیک گفته شد، در رگرسیون لجستیک، متغیر وابسته می تواند به دو شکل دووجهی و چندوجهی باشد. به همین خاطر، در نرم افزارSPSS شاهد وجود دو نوع تحلیل رگرسیون لجستیک هستیم که بسته به تعداد مقولات و طبقات متغیر وابسته، می توانیم از یکی از این دو شکل استفاده کنیم:
۱-رگرسیون لجستیک اسمی دووجهی: موقعی است که متغیر وابسته در سطح اسمی دووجهی (دوشقی) است. یعنی در زمانی که با متغیر وابسته اسمی دووجهی سروکار داریم.
۲-رگرسیون لجستیک اسمی چندوجهی : موقعی مورد استفاده قرار می گیرد که متغیر وابسته، اسمی چندوجهی (چندشقی) است.
منبع
ماشینتورینگ
ماشین تورینگ (به انگلیسی: Turing machine) یک دستگاه فرضی است که روی نشانهای روی یک قطعه نوار بر اساس جدول قوانین دستکاری انجام میدهد. با وجود اینکه مکانیزم ماشین تورینگ مقدماتی است، مفهومش برای پوشش عملکردهای بسیار پیچیده کافی و گستردهاست. ماشین تورینگ میتواند برای شبیهسازی هر الگوریتم کامپیوتری و توضیح نحوه عملکرد یک واحد پردازشگر مرکزی به کار آید. حافظه این ماشین ساختاری بسیار ساده دارد. یعنی میتواند بصورت یک آرایه یک بعدی از عناصر (سلولها) باشد که هر یک میتوانند حافظ تنها یک نماد باشند. این آرایه از هر دو طرف باز و نامحدود است (حافظه بینهایت) و اطلاعات آن میتوانند به هر ترتیبی فراخوانی شوند.

نمایش هنری یک ماشین تورینگ
ماشینهای تورینگ |
|---|
|
تاریخچه
زمینههای تاریخی:ماشین محاسباتی
معرفی ماشین تورینگ توسط دانشمند انگلیسی آلن تورینگ در سال ۱۹۳۶ میلادی، گام دیگری را در مسیر ایجاد و پیدایش ماشینهای محاسباتی حالات متناهی به نمایش میگذارد. رابین گندی یکی از دانشجویان آلن تورینگ و دوست صمیمی تمام عمرش، ریشههای نظریه ماشین محاسباتی بابیج(۱۸۳۴) را کاوش کرد و در حقیقت نظریه بابیج را دوباره ارائه کرد:
آنالیز گندی در مورد ماشین تحلیلی بابیج پنج عملیات زیر را توضیح میدهد:
۱-عملگرهای ریاضی + و – و *
۲-هر ترتیبی از عملگرها قابل قبول است
۳-تکرار عملگر
۴-تکرار شرطی
۵-انتقال شرطی
تعریف منطقی (انتزاع ذهنی مفاهیم کلی)
ماشین تورینگ عبارت است از یک پنج-تاپل (پنجتایی) بهصورت 
برای نمایش مفهوم ماشین انتخاب شده است.
مجموعهای است متناهی، از حالات داخلی.
مجموعهای متناهی موسوم به الفبای نوار و حاوی نمادی مخصوص
برای نمایش یک فاصلهٔ خالی روی نوار ماشین است.
زیرمجموعهای است از
و موسوم به الفبای ورودی. یعنی الفبای ورودی زیر مجموعهای از الفبای نوار است که شامل خالی نیست. نوارهای خالی نمیتوانند بعنوان ورودی استفاده شوند.
عبارت است از یک تابع جزئی، موسوم به تابع انتقال از دامنهٔ
به برد
.
حالت شروع نام دارد، یعنی، حالتی از ماشین است که محاسبه را درآن آغاز میکنیم.
بطور کلی 
تعریف وصفی (عملی دنیای خارج از ذهن)
ماشین تورینگ به صورت ریاضی، ماشینی است که روی یک نوار عمل میکند. روی این نوار، نمادهایی است که ماشین هم میتواند بخواند و هم میتواند بنویسد و همزمان از آنها استفاده میکند. این عمل به طور کامل با یک سری دستورالعمل ساده و محدود تعریف شده است. ماشین تورینگ از موارد زیر تشکیل شده است:
۱. یک نوار، به سلولهایی تقسیمبندی شده است و هر سلول شامل نمادهایی است. الفبا شامل نماد تهی خاصی و یک یا تعداد دیگری نماد است. فرض میشود که این نوار خودسرانه به چپ و راست رسانده شود. ماشین تورینگ از نوارهایی تأمین میشود که برای محاسبه لازم است.
۲. یک کلاهک وجود دارد که قادر به خواندن و نوشتن نمادهایی است که روی نوار قرار گرفتهاند و بطور همزمان نوار را به سمت چپ و راست یکی از (و تنها یک) سلولها حرکت میدهد. در بضی مدلها، کلاهک حرکت میکند و نوار ثابت میماند.
۳. یک دستگاه ثبت حالت وجود دارد که حالتهای ماشین تورینگ را ذخیره میکند (یکی از تعداد زیادی حالت متناهی). یک حالت شروع وجود دارد که همراه با مقدار دهی اولیه است. این حالتها، حالت ذهن شخصی را که محاسبات را انجام میدهد، جایگزین میکنند.
۴. یک جدول محدود (که گاهی جدول عمل یا تابع انتقال نامیده میشود)، از دستورالعملها وجود دارد که در حال حاضر، حالت (q_i) و نماد (a_j) به ماشین داده میشود (برای مدلهای ۵تایی و گاهی ۴تایی) که روی نوار خوانده میشود و میگوید که ماشین، این موارد را به تزتیب زیر برای مدلهای ۵تایی انجام دهد:
- یا پاک کردن یا نوشتن یک نماد (بصورت جایگزین کردن a_i با a_j۱)
- حرکت کردن کلاهک نوار (که توسط d_k مشخص میشود و میتواند مقادیر L برای حرکت به چپ و R برای حرکت به سمت راست به خود بگیرد. همچنین مقدار N نشان دهنده ساکن بودن نوار است).
- فرض کنید یک حالت مشابه یا یک حالت جدید مشخص شده است (رفتن به وضعیت q_i۱)
در مدلهای ۴تایی پاک کردن یا نوشتن یک نماد (a_j۱) و حرکت کلاهک نوار به سمت چپ یا راست (d_k) بصورت دستورالعملهای جداگانه مشخص شدهاند. بطور خاص، جدول به ماشین میگوید که چیزی را پاک کند یا یک نماد را بنویسد (ia) یا کلاهک نوار به سمت چپ و راست حرکت کند (ib). فرض کنید که حالتهای مشابه یا حالتهای جدیدی مشخص شدهاند. اما عملیاتهای (ia) و (ib) دستورالعملهای یکسانی ندارند. در برخی از مدلها، اگر در جدول، ورودی از نمادها و حالتها نداشته باشیم، ماشین متوقف خواهد شد. سایر مدلها، نیاز به همه ورودیها دارند تا پر شوند. توجه داشته باشید که هر بخش از ماشین- حالتها و نمادها، مجموعهها، اقدامات، چاپ کردن، پاک کردن و حرکت نوار- محدود، گسسته و تشخیص پذیر است. این، پتانسیل نامحدود نوارهاست که خود مقدار نامحدودی از یک فضای ذخیرهسازی است.
مقایسه با ماشینهای واقعی
اغلب گفته میشود که ماشین تورینگ، بر خلاف ماشینهای اتومات، به اندازه ماشینهای واقعی قدرتمند هستند و قادر به انجام هر عملیاتی که ماشین واقعی میتواند بکند هستند. چیزی که در این مطلب جا ماند این است که یک ماشین واقعی تنها میتواند در بسیاری از تنظیمات متناهی باشد؛ در واقع ماشین واقعی چیزی نیست جز یک ماشین اتوماتیک محدود خطی. از طرف دیگر ماشین تورینگ با ماشینهایی که دارای ظرفیت حافظههای نامحدود محاسباتی هستند، معادل است. از نظر تاریخی رایانههایی که محاسبات را در حافظه داخلی شان انجام میدادند، بعدها توسعه داده شدهاند.
چرا ماشینهای تورینگ مدلهای مناسبی برای رایانههای واقعی هستند؟
۱. هرچیزی که ماشین واقعی میتواند محاسبه کند، ماشین تورینگ هم میتواند. برای مثال ماشین تورینگ، میتواند هرچیز طبق روالی که در زبانهای برنامهنویسی پیدا میشود شبیهسازی کند. همچنین میتواند فرایندهای بازگشتی و هریک از پارامترهای مکانیسم شناخته شده را شبیهسازی کند.
۲. تفاوت، تنها در قابلیت ماشین تورینگ برای دخالت در مقدار محدودی اطلاعات نهفته است؛ بنابراین، ماشین تورینگ میتواند در مدت زمان محدودی، در اطلاعات دخالت داشته باشد.
۳. ماشین واقعی همانند ماشینهای تورینگ میتوانند حافظه مورد نیازش را به کمک دیسکهای بیشتر، بزرگ کند. اما حقیقت این است که هم ماشین تورینگ و هم ماشین واقعی، برای محاسبات نیازی به فضا در حافظهشان ندارند.
۴. شرح برنامههای ماشین واقعی که از مدل سادهتر انتزاعی استفاده میکنند، پیچیدهتر از شرح برنامههای ماشین تورینگ است.
۵. ماشین تورینگ الگوریتمهای مستقل را که چقدر از حافظه استفاده میکنند، توصیف میکند. در دارایی حافظه همهٔ ماشینها، محدودیتی وجود دارد؛ ولی این محدودیت میتواند خود سرانه در طول زمان افزایش یابد.
ماشین تورینگ به ما اجازه میدهد دربارهٔ الگوریتمهایی که برای همیشه نگه داشته میشوند، توصیفاتی ارائه دهیم؛ بدون در نظر گرفتن پیش رفت در معماری محاسبات با ماشین معمولی.
۶. ماشین تورینگ جملات الگوریتم را ساده میکند. الگوریتمهای در حال اجرا در ماشین آلات انتزاعی معادل تورینگ، معمولاً نسبت به همتایان خود که در ماشینهای واقعی در حال اجرا هستند عمومی ترند. زیرا آنها دارای دقت دلخواه در انواع اطلاعات قابل دسترس هستند و هیچوقت با شرایط غیرمنتظره روبرو نمیشوند. یکی از نقطه ضعفهای ماشین تورینگ این است که برنامههای واقعی که نوشته میشوند ورودیهای نامحدودی را در طول زمان دریافت میکنند؛ در نتیجه هرگز متوقف نمیشوند.
محدودیتهای ماشین تورینگ
نظریه پیچیدگی محاسباتی
یکی از محدودیتهاو معایب ماشینهای تورینگ این است که آنها توانایی چیدمان خوب را ندارند. برای مثال کامپیوترهای برنامهای با ذخیره مدرن، نمونههایی از یک مدل خاص ماشین انتزاعی که به نام ماشین برنامه دسترسی رندم یا مدل ماشین RASP میباشند.
همزمانی
یکی دیگر از محدودیتهای ماشین تورینگ این است که همزمانی را خوب ارئه نمیدهد. برای مثال برای اندازه عدد صحیحی که میتواند توسط «متوقف کننده غیر قطعی دایمی» محاسبه شود، محدودیت وجود دارد. ماشین تورینگ روی یک نوار خالی شروع میکند. در مقابل، ماشینهای «همیشه متوقف» همزمان هستند که بدون ورودی میتوانند عدد صحیح نامتناهی را محاسبه کنند.
منبع
ایده ماشین تورینگ چگونه مطرح شد و چه چیزی را دنبال میکرد؟

بخش اول
ماشین تورینگ! مفهومی که به اندازه فرد مطرح کننده خود از اهمیت ویژهای برخوردار است و نقش مهمی در رسیدن علوم کامپیوتر و همچنین فناوری محاسبات به مقطع کنونی دارد. اگرچه به سادگی میتوان بدون داشتن اطلاعاتی حتی جزئی در رابطه با ماشین تورینگ، به خوبی از نحوه کارکرد كامپيوترها و سازوكار محاسبات در ماشینها مطلع شد اما در این حالت، قطعاً کلید اصلی مسئله در نظر گرفته نشده است. درک ماشین تورینگ، درک روح محاسبات ماشینی و شناخت تولد و تکامل ماشینهای محاسبهگر است. اما به راستی، تورینگ چگونه و با چه هدفی چنین ایدهای را مطرح کرد؟
سرآغاز
تاریخچه محاسبات دیجیتال به دو بخش عهد عتیق و عهد جدید قابل تقسیم است. پیشوایان عهد قدیم به سرپرستی لایبنیتز (Gottfreid Wilhelm Leibniz) در سال 1670 میلادی منطق مورد نیاز ماشینهای محاسباتی دیجیتال را فراهم کرده و پیشروان عهد جدید به سرپرستی فون نویمان (John von Neumann) در سال 1940 خود این ماشینها را ساختند. آلن تورینگ، که در سال 1912 متولد شده است، جایی در میان این دو عصر مهم قرار گرفته و شاید بتوان وی را به نوعی پیوند دهنده این دو عهد مهم به شمار آورد. وی در سال 1936، درست در زمانی که به تازگی از کالج کینگ در دانشگاه کمبریج فارغالتحصیل شده و به دانشگاه پرینستون در نیوجرسی امریکا رفته بود، با نگارش و انتشار مقالهای با عنوان «درباره اعداد رایانشپذیر، با کاربردی بر مسئله تصمیمگیری» (On Computable Numbers, with an application to the Entscheidungs problem )، راهنمای پیادهسازی ماشینهای با منطق ریاضی شد.
در این مقاله، تورینگ قصد داشت تا مسئله Entscheidungs problem ریاضیدان آلمانی، دیوید هیلبرت (David Hilbert) را که در سال 1928 طرح کرده بود، حل کند. موضوع نهایی مسئله فوق، تصمیمگیری درباره این بود که آیا یک روال مکانیکی میتواند صحت یک عبارت منطقی را در تعداد محدودی حرکت تعیین کند یا خیر؟ تورینگ در این مقاله، ایده و تصور رایج در دهه 1930 از یک کامپیوتر (یک شخص مجهز به یک مداد، کاغذ و دستورالعملهای مشخص) را در نظر گرفته و با حذف تمام رگههای هوشمندی (Intelligence) از آن به غیر از امکان پیروی از دستورالعملها و امکان خواندن و نوشتن علامتهایی از یک الفبای خاص روی یک رول کاغذ با طول بی نهایت، ماشینی را معرفی کرد که بعدها به ماشین تورینگ معروف شد و سرآغاز طلوع ماشینهای محاسباتی دیجیتال امروزی شد.
ماشین تورینگ، یک جعبه سیاه ریاضیاتی بود که از یک سری دستورالعمل از پیش تعیین شده پیروی میکرد. این دستورالعملها با استفاده از علامتهايي مشخص که روی کاغذ یا نوع خاصی از حافظه نوشته میشد به ماشین تحویل داده میشد. این ماشین میتوانست در هر لحظه، یک علامت را از روی یک خانه خوانده، نوشته یا پاک کند و خانه مذکور را که یک واحد کوچک موجود روی رول کاغذ است به سمت چپ یا راست هدایت کند. علامتهای پیچیده میتوانند بهصورت دنبالهای از علامتهای سادهتر پیادهسازی شوند و در این حالت، پیچیدگی احتمالی، تشخیص تفاوت بین دو علامت مختلف و وجود یا نبود فاصلههای خالی روی نوار است. «بیت»های اطلاعاتی در این ماشین میتوانند دو فرم مختلف داشته باشند: الگوهایی در فضا که در طول زمان ارسال میشوند و حافظه مدتدار خوانده میشوند یا الگوهایی در زمان که در فضا ارسال شده و کد نامیده میشوند. در ماشین تورینگ، زمان بهصورت رشتهای از اتفاقات یکسان نیست، بلکه به صورت دنبالهای از تغییر حالات در ماشین مذکور قابل تصور خواهد بود.
ایده ماشینهای بدون قطعیتِ پیشگو، به اساس کار هوش نزدیکتر بود؛ شهود و بینش، پرکننده فاصله میان عبارات منطقی است.
در ادامه مقاله، تورینگ امکان وجود ماشین منفردی را مطرح کرد که میتواند هر توالی محاسباتی را محاسبه کند. «چنین ماشین محاسباتی جامعی میتواند رفتار هر ماشین دیگری را با استفاده از شرح کار کد شده آن تقلید کند.» بنابراین، با ذکر این عبارت، تورینگ ایده «نرمافزار» را در حدود 76 سال قبل پیشگویی کرده بود. در پایان، تورینگ مسئله پیچیده هیلبرت را به روشی جالب پاسخ داده است. او عبارتی را یافته بود که در تعداد گامهای محاسباتی محدود، توسط هیچ ماشینی قابل محاسبه نبود: آیا شرح کار کد شده یک ماشین که توسط ماشین محاسباتی جامع تورینگ اجرا میشود، در نهایت به پایان میرسد یا برای همیشه اجرا میشود؟
بر همین اساس، وی پاسخ مسئلهEntscheidungs problem را منفی دانسته و از این طریق، پايهگذار طراحی ماشینهای محاسباتی دیجیتال شد. در سال 1949، فوننویمان در یک سخنرانی با اشاره به این مفهوم مطرح شده توسط تورینگ عنوان کرد: «شما میتوانید چیزی بسازید که کاری را که میشود انجام داد، انجام دهد. اما نمیتوانید نمونهای بسازید که به شما بگوید که آیا آن کار انجامپذیر است یا خیر؟»
تورینگ با درک محدودیتهای ماشینهای با قطعیت مشخص، شروع به جستوجو در زمینه محاسبات غیرقطعی با ماشینهای پیشگو کرد. از نظر او، این نوع ماشینها، همان روال گام به گام را مورد استفاده قرار میدهند اما با استفاده از نوعی پیشگویی، گاهی جهشهایی غیرقابل پیشبینی نیز انجام میدهند.
پس از پایان تحصیلات در دوره دکترا، تورینگ در سال 1938 به انگلیس بازگشت و گسترش جنگ جهانی دوم منجر به بروز نیاز هرچه بیشتر به ایدههای وی شد. به همین دلیل، وی در مدرسه رمز و کدهای محرمانه دولت به خدمت گرفته شد. در آنجا، تورینگ و همکارانش به همراه استادش، ماکسول نیومن (Maxwell Newman) ارتباطات دشمن را، از جمله پیامهای کدگذاری شده توسط ماشین آلمانی انيگما، رمزگشایی کردند. انیگما، ماشینی شبیه به ماشین تورینگ بود که امکان کدگذاری متن ورودی خود را با مکانیزمی مکانیکی فراهم میکرد. آنها کار کدگشایی رمزهای انیگما را با مجموعهای از دستگاههای الکترومکانیکی که بمب (bombe) نامیده میشدند، شروع کردند که هر کدام میتوانست در هر لحظه 36 حالت احتمالی پیکربندی انیگما را شبیهسازی کند.
از این طریق، آنها توانستند با همکاری افرادی دیگر، کامپیوتری بسیار پیچیده و دیجیتال با نام Clossus بسازند که از یک حافظه داخلی ساخته شده با 1500 لامپ خلاء بهره میبرد که وضعیت حافظه برنامهپذیری را برای جستوجوی کدها فراهم میکرد. این مدل بعدها با نسل دوم خود با 2400 لامپ خلاء جایگزین شد که علاوه بر تأثیر اساسی بر نتیجه جنگ، تحولی شگرف در تکامل رایانههای دیجیتال به شمار میآمد. اسرار مربوط به ساخت این ماشین برای حدود 30 سال از طرف سازمانهای اطلاعاتی انگلیس بهصورت محرمانه نگهداری میشد.
پس از پایان جنگ، نیاز به کامپیوترهای پیشرفتهتر، از کاربردهای رمزگشایی به سمت طراحی بمبهای اتمی پیش رفت. در سال 1946 ایالاتمتحده با داشتن کامپیوتر زمان جنگ خود، یعنی ENIAC (سرنام Electronic Numerical Integrator and Computer)، کار روی طراحی سلاحهای اتمی را در پیش گرفت. در انستیتو مطالعات پیشرفته پرینستون و با حمایت مالی ارتش ایالاتمتحده، دفتر تحقیقات نیروی دریایی و همچنین کمیسیون انرژی اتمی امریکا، فوننویمان موظف شد تا نمونه الکترونیکی ماشین جامع تورینگ را بسازد. در آن زمان، هدف او ساخت ماشین تورینگی بود که حافظه آن با سرعت نور قابل دسترسی بوده و به پردازش در زمینههای مختلف میپرداخت. اما هدف دولت ایالات متحده امریکا از سرمایهگذاری روی چنین ماشینی تعیین امکان ساخت بمب هیدروژنی بود و به همین دلیل، فون نویمان قول داد که ماشین مذکور که از 5 کیلوبایت فضای ذخیرهسازی بهره میبرد، امکان اجرای کدهای داینامیک مذکور را داشته باشد.
بعدها، طراحی کامپیوتر مذکور در اختیار همگان گذارده شد و آيبيام آن را تجاری کرد. در نخستین جلسه هماهنگی برای اجرای پروژه مذکور در سال 1945، فون نویمان اعلام کرد که قصد دارد پیادهسازی دستورات را نیز همانند اعداد در حافظه انجام دهد و این ترکیب دادهها و دستورالعملها کاملاً براساس مدل تورینگ بود.
ماشین تورینگ چیست ؟ قسمت 1
ماشین تورینگ چیست ؟ قسمت 2
ماشین تورینگ چیست ؟ قسمت 3
همایش جامع بین المللی کامپیوتر، فناوری اطلاعات ومهندسی برق
همایش جامع بین المللی کامپیوتر، فناوری اطلاعات ومهندسی برق در تاریخ ۱۹ اسفند ۱۳۹۶ توسط و تحت حمایت سیویلیکا برگزار می شود.با توجه به اینکه این همایش به صورت رسمی برگزار می گردد، کلیه مقالات این کنفرانس در پایگاه سیویلیکا و نیز کنسرسیوم محتوای ملی نمایه خواهد شد و شما می توانید با اطمینان کامل، مقالات خود را در این همایش ارائه نموده و از امتیازات علمی ارائه مقاله کنفرانس با دریافت گواهی کنفرانس استفاده کنید.
حوزه های تحت پوشش: علوم کامپیوتر
برگزار کننده:
سایر برگزار کنندگان: تحت حمایت سیویلیکا
محورهای همایش:
علوم کامپیوتر
مهندسی نرم افزار
سیستم های نرم افزای
مهندسی نرم افزار و سیستم های صوری
معماری نرم افزار
تست و ارزیابی سیستم های نرم افزاری،
نظریه محاسبات
رایانش ابری
داده های عظیم و سایر موارد مرتبط
پایگاه داده عملیاتی و تحلیلی
داده کاوی
امنیت اطلاعات و امنیت سیستم های نرم افزاری
سایر مباحث مرتبط با مهندسی نرم افزار و محاسبات مشبک و خوشه ای
مباحث ویژه در مهندسی نرم افزار
هوش مصنوعی
هوش مصنوعی و یادگیری
بینایی ماشین و پردازش تصویر
پردازش زبان طبیعی
محاسبات نرم
سیستم های چند عامله
پردازش صوت و سیگنال
سیستم های خبره
منطق فازی
پردازش زبان طبیعی
علوم شناختی و کاربردهای آن در هوش مصنوعی
سیستم های استنتاج
شناسایی الگو
سیستم چند عامله
یادگیری ماشین
بینایی ماشین و پردازش تصویر
پردازش تکاملی
مباحث ویژه در سیستم هوشمند و محاسبات نرم
سایر مباحث مرتبط با سیستم های هوشمند و سایر موارد
شبکه های کامپیوتری
انتقال داده
امنیت شبکه های کامپیوتری
شبکه های هوشمند برق
شبکه های بین خودرویی
شبکه های اقتضای
شبکه های ارتباطی موبابل
شبکه های بی سیم و سایر موارد مرتبط
معماری کامپیوتر
سیستم های حسابی
قابلیت اطمینان
تحمل پذیری خطا و آزمون پذیری
معماری سیستم های موازی
مدل سازی و ارزیابی کارایی سیستم های کامپیوتری
سیستم های نهفته و بی درنگ
سیستم های قابل پیکربندی
شبکه های ارتباطی موبایل و بی سیم
مدارای مجتمع در سیستم های بسیار بزرگ
فناوری نوظهور
مباحث ویژه در سیستم دیجیتالی
سیستم های سلولی
سیستم توزیع شده
سایر مباحث مرتبط با سیستم های دیجیتالی و سایر موارد مرتبط
فناوری اطلاعات و ارتباطات
شبکه های کامپیوتری
انتقال داده
امنیت شبکه های کامپیوتری
محسبات خوشه ای، مشبک و ابری
یادگیری الکترونیک
معماری اطلاعات و مدیریت دانش
پردازش موازی و سیستم های توزیع شده
معماری سازمانی فناوری اطلاعات
سیستم های محاسباتی انسان محور
تجارت الکترونیک
مدل سازی و ارزیابی شبکه های کامپیوتری
سیستم های انتقال و ارتباطات هوشمند
مباحث ویژه در شبکه های کامپیوتری
سایر :
الگوریتم و محاسبات
بیوانفورماتیک و محاسبات علمی
تجارت الکترونیک، دولت الکترونیک
آموزش از راه دور (آموزش الکترونیکی(
موتورهای گرافیکی، موتورهای بازی و انیمیشن
سیستم های چندرسانه ای، گرافیک و شبیه سازی
برق :
قدرت
کنترل
مخابرات
الکترونیک
مکاترونیک
مخابرات نوری
مهندسی پزشکی
تکنولوژی فشار قوی
پزشکی(بیوالکتریک)
ماشین های الکتریکی
هوش ماشین و رباتیک
کنترل و ابزار دقیق و اتوماسیون (ACI)
شیمی و مواد (CAM)
کنترل و حفاظت (CAP)
دیسپاچینگ و مخابرات (DTC)
بهرهوری و مدیریت انرژی (EEM)
ماشینهای الکتریکی (ELM)
محیط زیست، ایمنی و بهداشت (ENV)
تولید انرژی الکتریکی (EPG)
بازار برق (EPM)
پستهای فشارقوی (HVS)
تکنولوژی اطلاعات (ITP)
مدیریت (MNG)
توزیع انرژی الکتریکی (PDS)
کیفیت برق (PQA)
برنامهریزی و مطالعات سیستم (PSS)
انتقال انرژی الکتریکی (PTL)
انرژیهای تجدیدپذیر (REN)
مطالعات اقتصادی و اجتماعی (SEA)
شبکههای هوشمند (SMG)
ترانسفورماتورهای قدرت و توزیع (TRN)