ترجمه لغات پردازشتصویر
فهرست بعضی از لغات در زمینه هوش مصنوعی و پردازش تصویر عبارت اند از:
فهرست واژگان:
A
accuracy دقت action اقدام action-value function تابع اقدام-مقدار
activation function تابع فعالیت
active learning یادگیری فعال
adaptive control theory نظریه کنترل تطبیقی
adaptive dynamic برنامه نویسی پویای تطبیقی
programming (ADP)
algebraic expressions اصطلاحات جبری
applicability قابلیت اعمال
approximation algorithm الگوریتم تقریب
arbitrary دلخواه
arithmetic unknown مجهول حسابی
assertion اظهار
assumption فرض
attribute صفت
attribute-based language زبان مبتنی بر صفت
availability در دسترس بودن
B
background knowledge دانش زمینه
back-propagate پس-انتشار
backtrack عقب گرد
backward proof process فرایند اثبات رو به عقب
backward-chaining قضیه زنجیره ای رو به عقب
theorem
bandit problems مسائل قمار
bang-bang control کنترل بنگ-بنگ
basis functions توابع پایه ای
Bayes’ rule قانون بیز
Bayesian learning یادگیری بیزین
Bayesian network شبکه بیزین
Bellman equations معادلات بلمن
beta distribution توزیع بتا
bias weight وزن بایاس
Booleanclassification دسته بندی بولی(دودویی)
Boosting algorithm الگوریتم بوستینگ
boundary set مجموعه کران
branching factor فاکتور انشعاب
bump برامدگی
C
candidate definition تعریف مطلوب
candidate elimination حذف مطلوب
cart-pole balancing problem مسأله تنظیم میله ارابه
classification دسته بندی
clause بند
complete data داده های کامل
complexity پیچیدگی
component مؤلفه (جزء)
compression تراکم
computation محاسبه
computational complexity پیچیدگی محاسباتی
computational learning نظریه یادگیری محاسباتی
theory
computational عصب شناسی محاسباتی
neuroscience
conditional probability احتمال شرطی
conjugate prior مزدوج اول
conjunct عطف
Conjunction ترکیب عطفی
connectionism پیوندگرایی
consistency سازگاری
consistent hypothesis فرض سازگار
constraint equation معادله محدودیت
constructive الگوریتم های استقرای سازنده
induction algorithms
continuous-valued پیوسته مقدار
contradiction تناقض
convergence همگرایی
Cross-validation اعتبارسنجی متقابل
cumulative learning یادگیری فزاینده
current state حالت جاری
current-best- جستجوی بهترین فرض جاری
hypothesis search
D
debate مباحثه
decision list لیست تصمیم
decision stumps ریشه های تصمیم
decision theory نظریه تصمیم
Decision tree درخت تصمیم
declarative bias بایاس اعلانی
definition تعریف
delta rule قانون دلتا
density estimation تخمین چگالی
description توصیف
determinations تعیین کننده ها
deterministic قطعی
dictionary فرهنگ لغات
differentiating مشتق گیری
dimension of the space بعد فضا
direct utility estimation تخمین مستقیم سودمندی
discount factor فاکتور تخفیف
discrete گسسته
discrete-valued گسسته- مقدار
disjunct فاصل
Disjunction ترکیب فصلی
domain دامنه
dropping conditions حذف شرطها
dynamic environment محیط پویا
E
efficiency کارایی
empirical gradient گرادیان تجربی
ensemble learning یادگیری گروهی
entailment constraint محدودیت ایجاب
epoch دوره
equality literal لیترال تساوی
equation معادله (تساوی)
equivalence معادل (هم ارز)
error rate نرخ خطا
estimate تخمین زدن
evaluation function تابع ارزیابی
evidence شاهد
example مثال
example descriptions توصیف های مثال
expectation– ماکزیمم سازی امیدواری
maximization (EM)
expected value مقدار مورد انتظار
Explanation-based یادگیری مبتنی بر تشریح
learning (EBL)
exploitation بهره برداری
exploration اکتشاف
exploration function تابع اکتشاف
expressiveness رسا بودن
extension بسط
extract استخراج کردن
F
fairly good نسبتا خوب
false negative منفی کاذب
false positive مثبت کاذب
feature ویژگی (مشخصه)
feedback بازخور
feed-forward network شبکه پیشرو
filtering فیلتر کردن
first-order logic منطق مرتبه اول
fit برازش کردن
fixed policy خط مشی ثابت
formulation تدوین
forward–backward الگوریتم پیشرو-پسرو
algorithm
fully connected network شبکه کاملا متصل
fully observable کاملا رؤیت پذیر
function تابع
function approximation تقریب تابع
functional dependencies وابسته های تابعی
G
gain ratio نسبت بهره
generality عمومیت
generalization تعمیم
generalization hierarchy سلسله مراتب تعمیم
general-purpose الگوریتم های یادگیری همه منظوره
learning algorithms
goal predicate گزاره هدف
gradient descent نزول گرادیان
gradient-based algorithm الگوریتم مبتنی بر گرادیان
greedy agent عامل حریص
H
hamming distance فاصله همینگ
handwritten digits ارقام دست نویس
happy graphs گرافهای خوشحال
head (of a clause) سر(یک بند)
heuristic هیوریستیک
hidden Markov مدل های پنهان مارکوف
models (HMMs)
hidden units واحدهای پنهان
hidden variables متغیرهای پنهان
hill-climbing search جستجوی تپه نوردی
hole حفره
horn clause بند هورن
hypothesis فرض
hypothesis prior پیش فرض
hypothesis space فضای فرض
I
implement پیاده سازی کردن
inconsistent ناسازگار
incremental رو به رشد
independent مستقل
independently توزیع شده بطور مستقل و یکنواخت
and identically distributed (i.i.d.)
indicator variables متغیرهای نمایشگر
individual جداگانه
induction استقرا
inductive learning یادگیری استقرایی
inductive logic برنامه نویسی منطقی استقرایی
programming(ILP)
inequality literal لیترال عدم تساوی
infer استنتاج کردن
inference استنتاج
inferential استنتاجی
information content محتوای اطلاعات
information encoding رمزگذاری اطلاعات
information gain بهره اطلاعات
initial state حالت اولیه
instance-based learning یادگیری نمونه محور
interaction تعامل
internal state حالت درونی
invention اختراع
inverse entailment ایجاب معکوس
inverse resolution تحلیل معکوس
irrelevant attribute صفت نامربوط
iterative solution الگوریتم های راه حل تکراری
algorithms
K
kernel function تابع کرنل
kernel machines ماشین های کرنل
kernel model مدل کرنل
knowledge-based approach رهیافت مبتنی بر دانش
knowledge-based یادگیری استقرایی مبتنی بر دانش
inductive learning (KBIL)
knowledge-free بدون دانش
L
latent variables متغیرهای نهفته
layers لایه ها
leaf node گره برگ
learning curve منحنی یادگیری
learning element عنصر یادگیری
learning mixtures یادگیری ترکیبی گاوس
of gaussians
learning rate نرخ یادگیری
least-commitment جستجوی حداقل تعهد
search
likelihood درستنمایی
linear separator جداکننده خطی
linear-Gaussian model مدل خطی گاوس
linearly separable جداشدنی خطی
links پیوندها
list لیست
literal (sentence) لیترال (جمله)
local search جستجوی محلی
log likelihood لگاریتم درستنمایی
logistic function تابع استدلالی
lookup table جدول مراجعه
M
machine learning یادگیری ماشین
mahalanobis distance فاصله ماهالانوبیس
majority function تابع اکثریت
majority vote رأی گیری اکثریت
margin حاشیه
Markov decision فرایندهای تصمیم مارکوف
processes (MDPs)
maximum a posteriori (MAP) حداکثر تجربی
maximum-likelihood (ML) حداکثر درستنمایی
measure مقیاس
measurement اندازه گیری
memorization یادسپاری
memory-based learning یادگیری حافظه محور
Mercer’s theorem قضیه مرکر
minimal کمینه
minimum description حداقل طول توصیف
length (MDL)
mixture distribution توزیع ترکیبی
model checking وارسی مدل
model structure ساختار مدل
























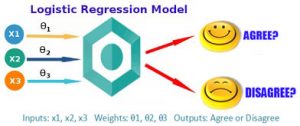
![{\displaystyle [1,\cdots ,d]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1f0cb2b735303a718bd517e38e758ac6d49ef6a9)












![{\displaystyle y_{i}\in [1,\cdots ,K]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7be8cb4ab377a7ad30972f691d5c72247d873131)










![{\displaystyle {\vec {\beta }}=[\beta _{0},\beta _{1},\cdots ,\beta _{k}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bdc88718ceff56832c5b289e0604368f643eea58)