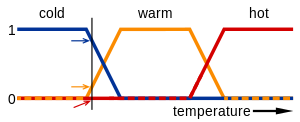
تعریف

Machine Learning
اهداف و انگیزهها
هدف یادگیری ماشین این است که کامپیوتر (در کلیترین مفهوم آن) بتواند به تدریج و با افزایش دادهها کارایی بهتری در انجام وظیفهٔ مورد نظر پیدا کند. گسترهٔ این وظیفه میتواند از تشخیص خودکار چهره با دیدن چند نمونه از چهرهٔ مورد نظر تا فراگیری شیوهٔ گامبرداری روباتهای دوپا با دریافت سیگنال پاداش و تنبیه باشد.
طیف پژوهشهایی که در یادگیری ماشینی میشود گستردهاست. در سوی نظریی آن پژوهشگران بر آناند که روشهای یادگیری تازهای به وجود بیاورند و امکانپذیری و کیفیت یادگیری را برای روشهایشان مطالعه کنند و در سوی دیگر عدهای از پژوهشگران سعی میکنند روشهای یادگیری ماشینی را بر مسایل تازهای اعمال کنند. البته این طیف گسسته نیست و پژوهشهای انجامشده دارای مولفههایی از هر دو رویکرد هستند.
یادگیری ماشین کمک فراوانی به صرفه جویی در هزینههای عملیاتی و بهبود سرعت عمل تجزیه و تحلیل دادهها میکند. به عنوان مثال در صنعت نفت و پتروشیمی با استفاده از یادگیری ماشین، دادههای عملیاتی تمام حفاریها اندازهگیری شده و با تجزیه و تحلیل دادهها، الگوریتمهایی تنظیم میشود که در حفاریهای بعدی بیشترین نتیجه و استخراج بهینه ای را داشته باشیم.
تقسیمبندی مسایل
یکی از تقسیمبندیهای متداول در یادگیری ماشینی، تقسیمبندی بر اساس نوع دادههای در اختیار عامل هوشمند است. به سناریوی زیر توجه کنید:
فرض کنید به تازگی رباتی سگنما خریدهاید که میتواند توسط دوربینی دنیای خارج را مشاهده کند، به کمک میکروفنهایش صداها را بشنود، با بلندگوهایی با شما سخن بگوید (گیریم محدود) و چهارپایش را حرکت دهد. همچنین در جعبهٔ این ربات دستگاه کنترل از راه دوری وجود دارد که میتوانید انواع مختلف دستورها را به ربات بدهید. در پاراگرافهای آینده با بعضی از نمونههای این دستورات آشنا خواهید شد.
اولین کاری که میخواهید بکنید این است که اگر ربات شما را دید خرناسه بکشد اما اگر غریبهای را مشاهده کرد با صدای بلند عوعو کند. فعلاً فرض میکنیم که ربات توانایی تولید آن صداها را دارد اما هنوز چهرهٔ شما را یادنگرفتهاست. پس کاری که میکنید این است که جلوی چشمهایاش قرار میگیرید و به کمک کنترل از راه دورتان به او دستور میدهید که چهرهای که جلویاش میبیند را با خرناسهکشیدن مربوط کند.
اینکار را برای چند زاویهٔ مختلف از صورتتان انجام میدهید تا مطمئن باشید که ربات در صورتی که شما را از مثلاً نیمرخ ببیند بهتان عوعو نکند. همچنین شما چند چهرهٔ غریبه نیز به او نشان میدهید و چهرهٔ غریبه را با دستور عوعوکردن مشخص میکنید. در این حالت شما به کامپیوتر ربات گفتهاید که چه ورودی را به چه خروجی مربوط کند. دقت کنید که هم ورودی و هم خروجی مشخص است و در اصطلاح خروجی برچسبدار است. به این شیوهٔ یادگیری، یادگیری بانظارت میگویند.
اینک حالت دیگری را فرض کنید. برخلاف دفعهٔ پیشین که به رباتتان میگفتید چه محرکه ای را به چه خروجی ربط دهد، اینبار میخواهید ربات خودش چنین چیزی را یاد بگیرد. به این صورت که اگر شما را دید و خرناسه کشید به نحوی به او پاداش دهید (مثلاً به کمک همان کنترل از راه دورتان) و اگر به اشتباه به شما عوعو کرد، او را تنبیه کنید (باز هم با همان کنترل از راه دورتان). در این حالت به ربات نمیگویید به ازای هر شرایطی چه کاری مناسب است، بلکه اجازه میدهید ربات خود کاوش کند و تنها شما نتیجهٔ نهایی را تشویق یا تنبیه میکنید. به این شیوهٔ یادگیری، یادگیری تقویتی میگویند.
در دو حالت پیش قرار بود ربات ورودی را به خروجی مرتبط کند. اما گاهی وقتها تنها میخواهیم ربات بتواند تشخیص دهد که آنچه میبیند (یا میشنود و…) را به نوعی به آنچه پیشتر دیدهاست ربط دهد بدون اینکه به طور مشخص بداند آنچیزی که دیده شدهاست چه چیزی است یا اینکه چه کاری در موقع دیدنش باید انجام دهد. ربات هوشمند شما باید بتواند بین صندلی و انسان تفاوت قایل شود بیآنکه به او بگوییم این نمونهها صندلیاند و آن نمونههای دیگر انسان. در اینجا برخلاف یادگیری بانظارت هدف ارتباط ورودی و خروجی نیست، بلکه تنها دستهبندیی آنها است. این نوع یادگیری که به آن یادگیری بی نظارت میگویند بسیار مهم است چون دنیای ربات پر از ورودیهایی است که کسی برچسبی به آنها اختصاص نداده اما به وضوح جزئی از یک دسته هستند.
یادگیری بینظارت را میتوان به صورت عمل کاهش بعد در نظر گرفت.
از آنجا که شما سرتان شلوغ است، در نتیجه در روز فقط میتوانید مدت محدودی با رباتتان بازی کنید و به او چیزها را نشان دهید و نامشان را بگویید (برچسبگذاری کنید). اما ربات در طول روز روشن است و دادههای بسیاری را دریافت میکند. در اینجا ربات میتواند هم به خودی خود و بدون نظارت یاد بگیرد و هم اینکه هنگامی که شما او را راهنمایی میکنید، سعی کند از آن تجارب شخصیاش استفاده کند و از آموزش شما بهرهٔ بیشتری ببرد. ترکیبی که عامل هوشمند هم از دادههای بدون برچسب و هم از دادههای با برچسب استفاده میکند به یادگیری نیمه نظارتی میگویند.
یادگیری با نظارت
یادگیری تحت نظارت، یک روش عمومی در یادگیری ماشین است که در آن به یک سیستم، مجموعهای از جفتهای ورودی – خروجی ارائه شده و سیستم تلاش میکند تا تابعی از ورودی به خروجی را فرا گیرد. یادگیری تحت نظارت نیازمند تعدادی داده ورودی به منظور آموزش سیستم است. با این حال ردهای از مسائل وجود دارند که خروجی مناسب که یک سیستم یادگیری تحت نظارت نیازمند آن است، برای آنها موجود نیست. این نوع از مسائل چندان قابل جوابگویی با استفاده از یادگیری تحت نظارت نیستند.
یادگیری تقویتی مدلی برای مسائلی از این قبیل فراهم میآورد. در یادگیری تقویتی، سیستم تلاش میکند تا تقابلات خود با یک محیط پویا را از طریق آزمون و خطا بهینه نماید. یادگیری تقویتی مسئلهای است که یک عامل که میبایست رفتار خود را از طریق تعاملات آزمون و خطا با یک محیط پویا فرا گیرد، با آن مواجه است. در یادگیری تقویتی هیچ نوع زوج ورودی- خروجی ارائه نمیشود. به جای آن، پس از اتخاذ یک عمل، حالت بعدی و پاداش بلافصل به عامل ارائه میشود. هدف اولیه برنامهریزی عاملها با استفاده از تنبیه و تشویق است بدون آنکه ذکری از چگونگی انجام وظیفه آنها شود.
تعریف ریاضی مسایل یادگیری ماشین
یادگیری با نظارت
در این مدل یادگیری مثالهای آموزشی به صورت جفتهای (





 یکی از انواع یادگیری از دادهها
یکی از انواع یادگیری از دادهها
یادگیری ماشین شاخه ای از علوم کامپیوتر است که بدون انجام برنامه نویسی صریح، به کامپیوتر توانایی یادگیری می بخشد.
یادگیری ماشین
آرتور ساموئل (Arthur Samuel) امریکایی، یکی از پیشروهای حوزه بازی های کامپیوتری و هوش مصنوعی، عبارت “یادگیری ماشین” را در سال 1959 که در IBM کار می کرد، به ثبت رساند. یادگیری ماشین، که از اُلگوشناسی و نظریه یادگیری محاسباتی الهام گرفته شده است، مطالعه و ساخت الگوریتم هایی را که می توانند بر اساس داده ها یادگیری و پیش بینی انجام دهند بررسی می کند – چنین الگوریتم هایی از دستورات برنامه پیروی صرف نمی کنند و از طریق مدلسازی از داده های ورودی نمونه، پیش بینی یا تصمیم گیری می کنند.
یادگیری ماشین در کارهای محاسباتی که طراحی و برنامه نویسی الگوریتم های صریح با عملکرد مناسب در آن ها سخت یا نشدنی است، استفاده می شود؛ برخی کاربردها عبارت اند از فیلترینگ ایمیل، شناسایی مزاحم های اینترنتی یا بدافزارهای داخلی که قصد ایجاد رخنه اطلاعاتی دارند، نویسه خوان نوری (OCR)، یادگیری رتبه بندی، و بینایی ماشین.
یادگیری ماشین ارتباط نزدیکی با آمار محاسباتی دارد (و اغلب با آن هم پوشانی دارد)، تمرکز این شاخه نیز پیش بینی کردن توسط رایانه است و پیوند محمکی با بهینه سازی ریاضی دارد، که آن هم روش ها، تئوری ها و کاربردهایی را وارد میدان می کند. یادگیری ماشین گاهی اوقات با داده کاوی ادغام می شود؛ تمرکز این زیرشاخه بر تحلیل اکتشافی داده ها است و با عنوان یادگیری بی نظارت شناخته می شود. یادگیری ماشین نیز می تواند بی نظارت باشد و برای یادگیری و شناخت فرم ابتدایی رفتار موجودات مختلف و سپس پیدا کردن ناهنجاری های معنادار استفاده شود.
در زمینه تحلیل داده ها، یادگیری ماشین روشی برای طراحی الگوریتم ها و مدل های پیچیده است که برای پیش بینی استفاده می شوند؛ در صنعت این مطلب تحت عنوان تحلیل پیشگویانه شناخته می شود. این مدل های تحلیلی به محققان، پژوهشگران علم داده ها، مهندسان و تحلیلگران اجازه می دهد “تصمیمات و نتایجی قابل اطمینان و تکرارپذیر بدست آورند” و با یادگیری از روابط و روندهای مربوط به گذشته، از “فراست های پنهان” پرده برداری کنند.
طبق سیکل هایپ (hype cycle) 2016 کمپانی گارتنر، یادگیری ماشین اکنون در مرحله “اوج توقعات زیاد (Peak of Inflated Expectations)” قرار دارد. پیاده سازی اثربخش یادگیری ماشین سخت است زیرا الگویابی دشوار است و اغلب، داده های آموزشی به مقدار کافی در دسترس نیست، در نتیجه برنامه های یادگیری ماشین اغلب با شکست مواجه می شوند.
نگاه کلی به یادگیری ماشین
تام ام. میچل (Tom M. Mitchell) تعریفی پر کاربرد و صوری از الگوریتم های مورد مطالعه در حوزه یادگیری ماشین ارائه نمود: “گوییم یک برنامه کامپیوتری از تجربه E نسبت به یک کلاس T از کارها و اندازه عملکرد P، یاد گرفته است، هرگاه با داشتن تجربه E عملکرد آن که توسط P اندازه گیری می شود در کارهای کلاس T بهبود یافته باشد.
” این تعریف از کارهایی که یادگیری ماشین درگیر آن است، تعریفی کاملاً اجرایی است و نه صرفاً تعریفی شناختی. این تعریف دنباله رو پروپزال آلن تورینگ (Alan Turing) در مقاله او “هوش و ماشین محاسبه گر” است که در آن، سوال “آیا ماشین ها می توانند فکر کنند؟” با سوال “آیا ماشین ها می توانند کاری را انجام دهند که ما (به عنوان موجودات متفکر) می توانیم انجام دهیم؟” جایگزین شد. در مقاله تورینگ، ویژگی های متنوعی که یک ماشین متفکر می تواند داشته باشد، و نتایج ساختن چنین ماشینی بررسی شده است.
انواع مسائل و کارها
کارهای (وظایف) یاد گیری ماشین معمولا به دو دسته وسیع تقسیم می شوند؛ بسته به این که در یک سیستم یادگیری “فیدبک” یا “سیگنال” یادگیری وجود داشته باشد یا خیر:
- یادگیری با نظارت: یک “معلم” به کامپیوتر ورودی های مثال و خروجی های مطلوب هر یک را می دهد، و هدف، یادگیری یک قانون کلی است که ورودی ها را به خروجی ببرد. در حالت های خاص، سیگنال ورودی ممکن است تنها بطور جزئی در دسترس باشد، یا به فیدبکی خاص محدود باشد.
- یادگیری نیمه نظارتی: به کامپیوتر تنها یک سیگنال آموزشی ناقص داده می شود: یک مجموعه آموزشی که بعضی (اغلب بسیاری) از خروجی های هدف آن غایب هستند.
- یادگیری فعال: کامپیوتر تنها می تواند برچسب های آموزشی را برای مجموعه ای محدود از نمونه ها بدست آورد ( بر اساس بودجه)، و همچنین باید انتخاب اشیاء را برای دستیابی به برچسب ها بهینه کند. هنگام استفاده تعاملی، این موارد برای برچسب گذاری قابل ارائه به کاربر هستند.
- یادگیری تقویتی: داده آموزشی (به شکل پاداش یا تنبیه) به عنوان فیدبک به فعالیت های برنامه تنها در محیطی پویا داده می شود، مثل رانندگی ماشین یا بازی کردن در مقابل یک حریف.
- یادگیری بی نظارت: هیچ برچسبی به الگوریتم یادگیرنده داده نمی شود، و خود الگوریتم باید ساختاری در ورودی پیدا کند. یادگیری بی نظارت به خودی خود می تواند یک هدف (پیدا کردن الگوهای پنهان در داده)، یا وسیله ای برای رسیدن به یک هدف باشد (یادگیری نمایش).
در میان دسته های دیگر مسائل یادگیری ماشین، فرا یادگیری، اُریب استقرایی خود را بر مبنای تجربه پیشین یاد می گیرد. یادگیری رشدی که برای رباتیک ساخته و پرداخته شده است، خود شرایط یادگیری دنباله داری (که دوره تحصیلی نیز نام دارد) را تولید می کند تا مهارت های جدید را از طریق کاوش خود مختارانه و تعاملات اجتماعی با معلم های انسان و استفاده از مکانیزم های هدایتی از قبیل یادگیری فعال، بلوغ، هم افزایی حرکتی و تقلید، جمع آوری کند.
با در نظر گرفتن خروجی مطلوب یک سیستم یادگیری ماشین، دسته بندی دیگری از فعالیت های یادگیری ماشین به وجود می آید:
- در طبقه بندی آماری (classification)، ورودی ها را به دو یا چند طبقه تقسیم می کنند، و یادگیرنده باید مدلی تولید کند که ورودی های دیده نشده را به یک یا چند طبقه تخصیص دهد (طبقه بندی چند برچسبی). این مسئله معمولا به شکل نظارت شده حل می شود. فیلترینگ اسپم یکی از نمونه های طبقه بندی است، که در آن ورودی ها، پیام های ایمیل (یا هر پیام دیگری) و طبقه ها “اسپم” و “غیر اسپم” هستند.
- در رگرسیون که آن هم یک مسئله نظارت شده است، خروجی ها پیوسته هستند نه گسسته.
- در خوشه بندی، مجموعه ای از ورودی ها باید به چند گروه تقسیم شود. بر خلاف طبقه بندی آماری، گروه ها از قبل شناخته شده نیستند، چیزی که باعث می شود این فعالیت بی نظارت باشد.
- تخمین چگالی، توزیع ورودی ها را در یک فضا پیدا می کند.
کاهش بُعد، داده ها را با نگاشتن آن ها در فضایی با بعُد پایین تر، ساده سازی می کند. مدل سازی عناوین، یک مسئله مرتبط است، که در آن به برنامه فهرستی از اسناد به زبان انسان داده می شود و ماموریت برنامه این است که کشف کند کدام اسناد موضوعات مشابهی دارند.
تاریخچه یادگیری ماشین و ارتباط با سایر رشته ها
یادگیری ماشین از حوزه هوش مصنوعی فراتر است. در همان روزهای ابتدایی ایجاد هوش مصنوعی به عنوان رشته ای علمی، برخی محققان در پی این بودند که ماشین ها از داده ها یادگیری کنند. آن ها تلاش کردند این مسئله را با روش های نمادین متنوعی، و نیز چیزی که آن موقع “شبکه های عصبی” نام داشت، حل کنند؛ این روش ها اغلب پرسپترون (perceptron) و مدل های دیگری بودند که بَعد ها مشخص شد بازطراحی مدل های خطی تعمیم یافته آماری بوده اند. استدلال احتمالاتی، به ویژه در تشخیص پزشکی مکانیزه، مورد استفاده قرار گرفت.
با این حال، تاکید روز افزون بر روش منطقی و دانش-محور، شکافی بین AI (هوش مصنوعی) و یادگیری ماشین ایجاد کرد. سیستم های احتمالاتی پُر شده بودند از مسائل تئوری و عَمَلی در مورد بدست آوردن و نمایش داده ها. تا سال 1980، سیستم های خِبره بر AI رجحان یافتند و آمار دیگر مورد توجه نبود.
کار بر روی یادگیری نمادین/دانش-محور، درون حیطه AI ادامه پیدا کرد و به برنامه نویسی منطقی استقرایی منجر شد، اما سِیر آماری پژوهش دیگر از حیطه AI صِرف خارج شده بود و در الگوشناسی و بازیابی اطلاعات دیده می شد. پژوهش در زمینه شبکه های عصبی نیز حدود همین زمان توسط AI و علوم کامپیوتر (CS) طَرد شد. این مسیر نیز خارج از حوزه AI/CS توسط محققان رشته های دیگر از جمله هاپفیلد (Hopfield)، راملهارت (Rumelhart) و هینتون (Hinton) تحت عنوان پیوندگرایی (connectionism) دنبال شد. موفقیت عمده آن ها در اواسط دهه 1980 با بازتولید پَس نشر (backpropogation) حاصل شد.
یادگیری ماشین، پس از احیا به عنوان رشته ای مجزا، در دهه 1990 شروع به درخشش کرد. این رشته هدف خود را از دستیابی به هوش مصنوعی، به درگیر شدن با مسائل حل پذیری که طبیعتی عَملی دارند، تغییر داد و تمرکز خود را از روش های نمادینی که از هوش مصنوعی به ارث برده بود، به روش ها و مدل هایی که از آمار و احتمالات قرض گرفته بود، انتقال داد. این رشته همچنین از اطلاعات دیجیتالی که روز به روز دسترس پذیر تر می شدند و از امکان توزیع آن ها در اینترت، بهره برد.
یادگیری ماشین و داده کاوی اغلب از روش های یکسانی بهره می برند و با یکدیگر همپوشانی چشمگیری دارند، اما در حالی که یادگیری ماشین بر پیش بینی بر مبنای خواصِ معلومِ یادگرفته شده از داده های آموزش تمرکز دارد، داده کاوی روی کشف خواص (سابقاً) نامعلوم در داده ها تمرکز می کند (این عمل، مرحله تحلیل استخراج دانش در پایگاه داده هاست). داده کاوی از روش های یادگیری ماشین متعددی استفاه می کند اما با اهداف متفاوت؛ از طرف دیگر یادگیری ماشین نیز از روش های داده کاوی به عنوان “یادگیری بدون نظارت” یا به عنوان مرحله پیش پردازش برای بهبود دقت یادگیرنده استفاده می کند.
بیشتر سردرگمی های میان این دو رشته پژوهشی (که اغلب کنفرانس ها و مجلات متمایزی دارند، به استثنای ECML PKDD) از فرضیات بنیادینی که دارند نشئت می گیرد: در یادگیری ماشین، عملکرد را معمولاً با توانایی بازتولید دانش معلوم ارزیابی می کنند، در حالی که در استخراج دانش و داده کاوی (KDD)، فعالیت کلیدی، کشف دانشی است که قبلا ناشناخته بوده است. در مقایسه با دانش معلوم، یک روش بی نظارت (یک روش بی اطلاع) به راحتی از سایر روش های نظارت شده شکست می خورد، در حالیکه در یک فعالیت معمولی KDD، روش های نظارت شده به دلیل عدم دسترسی به داده های آموزشی، قابل استفاده نیستند.
یادگیری ماشین همچنین ارتباط تنگاتنگی با بهینه سازی دارد: بسیاری از مسائل یادگیری به شکل مینیمم سازی یک تابع زیان روی یک مجموعه از مثال های آموزشی بیان می شوند. توابع زیان، بیان کننده اختلاف بین پیش بینی های مدلِ تحت یادگیری و شواهد واقعی مسئله هستند (برای مثال، در طبقه بندی، هدف تخصیص برچسب به شواهد است، و به مدل ها آموزش داده می شود تا قبل از تخصیص، برچسب های یک مجموعه از مثال ها را پیش بینی کنند). تفاوت میان این دو رشته، از هدف کلان آن ها نشئت می گیرد: در حالیکه الگوریتم های بهینه سازی می توانند زیان را روی یک مجموعه آموزشی کمینه کنند، یادگیری ماشین می خواهد زیان را روی نمونه های مشاهده نشده کمینه کند.
یادگیری ماشین قسمت 1
یادگیری ماشین قسمت 2
یادگیری ماشین قسمت 3





![[عکس: 6.gif]](http://www.syavash.com/portal/files/siavash/blogs/farsi-what-is-artificial-intelligence/6.gif)
![[عکس: 7.gif]](http://www.syavash.com/portal/files/siavash/blogs/farsi-what-is-artificial-intelligence/7.gif)
![[عکس: 8.gif]](http://www.syavash.com/portal/files/siavash/blogs/farsi-what-is-artificial-intelligence/8.gif)
![[عکس: 9.gif]](http://www.syavash.com/portal/files/siavash/blogs/farsi-what-is-artificial-intelligence/9.gif)
![[عکس: 10.gif]](http://www.syavash.com/portal/files/siavash/blogs/farsi-what-is-artificial-intelligence/10.gif)
![[عکس: 11.gif]](http://www.syavash.com/portal/files/siavash/blogs/farsi-what-is-artificial-intelligence/11.gif)




![{\displaystyle [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/738f7d23bb2d9642bab520020873cccbef49768d)