مسئله فروشنده دورهگرد
مسئله فروشنده دوره گرد (به انگلیسی: Travelling salesman problem، بهاختصار: TSP) مسئلهای مشهور است که ابتدا در سده ۱۸مسائل مربوط به آن توسط ویلیام همیلتون و توماس کرکمن مطرح شد و سپس در دهه ۱۹۳۰ شکل عمومی آن به وسیله ریاضیدانانی مثلکارل منگر از دانشگاه هاروارد و هاسلر ویتنی از دانشگاه پرینستون مورد مطالعه قرار گرفت.
شرح مسئله بدین شکل است:
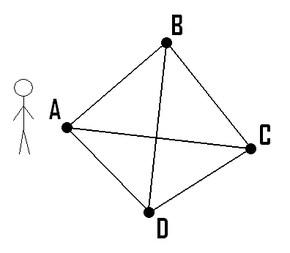
- تعدادی شهر داریم و هزینه رفتن مستقیم از یکی به دیگری را میدانیم. مطلوب است کمهزینهترین مسیری که از یک شهر شروع شود و از تمامی شهرها دقیقاً یکبار عبور کند و به شهر شروع برگردد.
تعداد جوابهای شدنی مسئله، برابر است با {\displaystyle {\frac {1}{2}}(n-1)!}
مسئلههای مرتبط
مسئله فروشنده دوره گرد یا Traveling Salesman Problem (به اختصار TSP)، یکی از مسائل بسیار مهم و پرکاربرد در علوم کامپیوتر و تحقیق در عملیات است.
سه روش کلی برای کد کردن راه حلهای مسئله TSP ارائه شدهاست که در الگوریتمهای مختلفی قابل استفاده هستند. راه حلهای سه گاه عبارتند از:
الف) نمایش جواب به صورت رشته گسسته جایگشتی که در الگوریتمهای زیر قابل استفاده است: الگوریتم ژنتیک یا Genetic Algorithms (به اختصار GA) شبیهسازی تبرید یا Simulated Annealing (به اختصار SA) جستجوی ممنوعه یا Tabu Search (به اختصار TS) جستجوی همسایگی متغیر یا Variable Neighborhood Search (به اختصار VNS) بهینهسازی کلونی مورچگان یا Ant Colony Optimization (به اختصار ACO) جستجوی هارمونی یا Harmony Search (به اختصار HS) و سایر الگوریتمهای بهینهسازی گسسته
ب) نمایش جواب به صورت کلیدهای تصادفی یا Random Key که در الگوریتمهای زیر قابل استفاده است: الگوریتم ژنتیک یا Genetic Algorithms (به اختصار GA) بهینهسازی ازدحام ذرات یا Particle Swarm Optimization (به اختصار PSO) الگوریتم رقابت استعماری یا Imperialist Competitive Algorithm (به اختصار ICA) تکامل تفاضلی یا Differential Evolution (به اختصار DE) بهینهسازی مبتنی بر جغرافیای زیستی یا Bio-geography Based Optimization (به اختصار BBO) استراتژیهای تکاملی یا Evolution Strategies (به اختصار ES) برنامهریزی تکاملی یا Evolutionary Programming (به اختصار EP) و سایر الگوریتمهای بهینهسازی پیوسته
پ) نمایش جواب به شکل ماتریسهای شبیه فرومون که توسط تمامی الگوریتمهای اشاره شده در مورد (ب) قابل استفاده میباشد.
- مسئله معادل در نظریه گراف به این صورت است که یک گراف وزندار کامل داریم که میخواهیم کموزنترین دور همیلتونی را پیدا کنیم.
- مسئله تنگراه فروشنده دورهگرد (به انگلیسی: Bottleneck traveling salesman problem، بهاختصار: bottleneck TSP) مسئلهای بسیار کاربردی است که در یک گراف وزندار کموزنترین دور همیلتونی را میخواهد که شامل سنگینترین یال باشد.
- تعمیمیافته مسئله فروشنده دورهگرد دارای ایالتهایی است که هر کدام حداقل یک شهر دارند و فروشنده باید از هر ایالت دقیقاً از یک شهر عبور کند. این مسئله به «مسئله سیاستمدار مسافر» نیز شهرت دارد.
الگوریتمها
مسئله فروشنده دوره گرد جزء مسائل انپی سخت است. راههای معمول مقابله با چنین مسائلی عبارتند از:
- طراحی الگوریتمهایی برای پیدا کردن جوابهای دقیق که استفاده از آنها فقط برای مسائل با اندازه کوچک صورت میگیرد.
- استفاده از الگوریتمهای مکاشفهای که جوابهایی بهدست میدهد که احتمالاً درست هستند.
- پیدا کردن زیرمسئلههایی از مسئله یا به عبارت دیگر تقسیم مسئله به مسئلههای کوچکتر، تا بتوان الگوریتمهای مکاشفهای بهتر و دقیقتری ارائه داد.
الگوریتمهای دقیق
سرراستترین راه حل امتحان کردن تمامی جایگشتهای ممکن برای پیدا کردن ارزانترین مسیر است که چون تعداد جایگشتها !n است، این راه حل غیرعملی میشود. با استفاده از برنامهنویسی پویا مسئله میتواند با مرتبه زمانی{\displaystyle n^{2}2^{n}}
الگوریتمهای مکاشفهای
الگوریتمهای تقریبی متنوعی وجود دارند که خیلی سریع جوابهای درست را با احتمال بالا بهدست میدهند که میتوان آنها را به صورت زیر دستهبندی کرد:
- مکاشفهای سازنده
- بهبود تکراری
- مبادله دوبهدو
- مکاشفهای k-opt
- مکاشفهای V-opt
- بهبود تصادفی
پیچیدگی محاسباتی الگوریتم فروشنده دوره گرد
این الگوریتم بطور مستقیم در مرتبه زمانی(!O(n حل میشود اما اگر به روش برنامهنویسی پویا برای حل آن استفاده کنیم مرتبه زمانی آن (O(n^2*2^n خواهد شد که جز مرتبههای نمایی است. باید توجه داشت علیرغم آنکه مرتبه نمایی مذکور زمان بسیار بدی است اما همچنان بسیار بهتر از مرتبه فاکتوریل میباشد. شبه کد الگوریتم فوق به صورت زیر است که در آن تعداد زیر مجموعههای یک مجموعه n عضوی ۲ به توان n میباشد و for اول یک ضریب n را نیز حاصل میشود که به ازای تمام شهرهای غیر مبدأ میباشد و حاصل (n*(2^n را پدیدمیآورد؛ بنابراین برای جستجوی کمترین مقدار نیاز به یک عملیات خطی از مرتبه n داریم که در زمان فوق نیز ضرب میشود و در نهایت زمان (n^2)*(2^n) را برای این الگوریتم حاصل میکند.
C({1},1) = 0
for (S=2 to n)
for All Subsets S subset of {1,2,3,...} of size S and containing1
C(S,1) = &
for All J member of S , J<>1
C (S , J) = min { C (S - { J } , i) + D i,J: i member of S , i <> J }
return min j C ({1 . . . n}, J) + D J,1
شبه کد مسئله فروشنده دوره گرد
مسئله:یک تور بهینه برای یک گراف وزن دار و جهت دار مشخص نمایید. وزنها اعدادی غیر منفی هستند
ورودی:یک گراف وزن دار و جهت دار و n تعداد گرههای گراف. گراف با یک ارائه دو بعدی w مشخص میشود که سطرها و ستونهایش از ۱ تا n شاخص دهی شدهاند و در ان [w[i][j معرف وزن لبه از گره iام به گره jام است.۴
خروجی:یک متغیر minlength که مقدار ان طول تور بهینه است و یک ارائه دو بعدی p که یک تور بهینه را از روی ان میتوان ساخت . سطرهای p از ۱ تا n و ستونهای ان با تمامی زیر مجموعههای {v-{v1 شاخص دهی شدهاند . [P[i][A شاخص اولین گره بعد از vi بر روی کوتاهترین مسیر از viتاvj است که از تمام گرههای A دقیقاً یکبار میگذرد.
* Void travel ( int n ,
* const number W[][],
* index p[][],
* number&minlength
* )
* {
* Index i, j, k;
* number D[1..n][subset of V-{vi}];
* for (i= 2 ; i<=n;i++)
* D[i][∅} = w[i][1];
* for(k=1; k<=n-2 ; k++)
* for (all subsets A v-{v1} containing k vertices
* for (i such that j≠1 and vi is not in A){
* D[i][A] = minimum (W[i][j]+ D[vj][A-{vj}]);
* P[i][A]= value of j that gave the minimum
* }
* D[1][v-{vi}]= minimum (W[1][j]+ D[vj][V-{v1}];
* P[1][V-{v1}]= value of j that gave the minimum ;
* Minlength = D[1][V-{v1}];
* }
الگوریتم جستجوی ممنوعه یا Tabu Search یا به اختصار TS، یکی از قویترین الگوریتمها در زمینه حل مسائل بهینهسازی، به خصوص مسائل بهینهسازی مبتنی بر گراف و مسائل بهینهسازی ترکیباتی (Combinatorial Optimization) است. این الگوریتم در اواخر دهه ۱۹۸۰ و توسط گلووِر (Glover) و همکارانش ارائه گردید. غالباً یکی از مسائلی که برای حل آنها از الگوریتم TS استفاده میشود، مسئله فروشنده دوره گرد یا TSP است. این الگوریتم پاسخهای بسیار مناسبی را برای انواع مسائل گسسته به خصوص مسئله TSP ارائه میکند!
در مسئله فروشنده دوره گرد در پی یافتن کوتاه ترین مسیر در بین مجموعه ای از شهر ها می باشیم، به گونه ای که هر شهر فقط یک بار در مسیر قرار گرفته و مسیر ساخته شده به شهر اولی منتهی شود.
این مسئله علاوه بر جنبه نظری از جنبه عملی نیز کاربرد فراوانی دارد به عنوان مثال در مواردی مانند مسیریابی، ساخت تراشه های الکترونیکی، زمان بندی کارها و غیره مورد استفاده قرار گیرد. اما در مواجهه با چالش حل مسائل بهینه سازی، که این نوع مسائل در دنیای واقعی بسیار زیاد هستند، روش های کلاسیک اغلب با مشکل مواجه می شوند. به همین دلیل معمولا از روشهای فرا ابتکاری همانند الگوریتم ژنتیک و سایر الگوریتم های تکاملی برای حل این نوع مسائل استفاده میشود
به صورت کلی مسئله فروشنده دوره گرد دارای 3 حالت زیر می باشد.
1- فروشنده دوره گرد متقارن
در حالت متقارن مسئله، تعدادی شهر داریم و هزینه رفتن مستقیم از یکی به دیگری را میدانیم .مطلوب است کم هزینهترین مسیری که از یک شهر شروع شود و از تمامی شهرها دقیقا یکبار عبور کند و به شهر شروع بازگردد.
2- فروشنده دوره گرد نامتقارن
مسأله ي فروشنده ي دوره گرد نامتقارن, یک TSP است که فاصله بين رئوس آن, متقارن نيست. ATSP بسيار مشکلتر از TSP است، در حقيقت در حالي که TSP متقارن, حتي در گرافهاي با چندين هزار رأس, به طور بهينه, قابل حل است, تنها نمونههاي خاصي ازATSP را که ماتريس فاصلهي آنها, تقريباً متقارن است, تنها در گرافهاي داراي چندين دوجين رأس, ميتوان به طور بهينه حل کرد. به کاربردن هوش مصنوعی براي ATSP, راحت و سر راست است. چون هيچ تغييراتي در الگوريتم اصلي, لازم ندارد. پيچيدگي محاسباتي در حلقهي الگوريتم, برنامهي کاربردي TSP, يکسان است, زيرا تنها تفاوت آنها در فاصلهها و ماتريسهاي ردپا است که در اينجا ديگر متقارن نيستند.
3- فروشنده دوره گرد با پنجره های زمانی
مسئله فروشنده دوره گرد با پنجره زمانی، شامل یافتن کوتاهترین طول توری است که به وسیله یک فروشنده دوره گرد طی می شود با این شرایط که فروشنده باید هر گره را فقط یکبار ملاقات کند و در پنجره زمانی معینی به آن سرویس دهد. به این معنا که اگر فروشنده زودتر از محدوده زمانی تعیین شده به آن گره برسد باید منتظر بماند تا بازه زمانی سرویس دهی مربوط به آن گره شروع شود. همچنین اگر دیرتر از پنجره زمانی برسد ارائه سرویس به آن گره دیگر امکان پذیر نخواهد بود.