بهينهسازی يك فعاليت مهم و تعيينكننده در طراحي ساختاري است. طراحان زماني قادر خواهند بود طرحهاي بهتري توليد كنند كه بتوانند با روشهاي بهينهسازی در صرف زمان و هزينه طراحي صرفهجويي نمايند. بسياري از مسائل بهينهسازی در مهندسي، طبيعتاً پيچيدهتر و مشكلتر از آن هستند كه با روشهاي مرسوم بهينهسازی نظير روش برنامهريزي رياضي و نظاير آن قابل حل باشند. بهينهسازی تركيبي (Combinational Optimization)، جستجو براي يافتن نقطه بهينه توابع با متغيرهاي گسسته (Discrete Variables) ميباشد. امروزه بسياري از مسائل بهينهسازی تركيبي كه اغلب از جمله مسائل با درجه غير چندجملهاي (NP-Hard) هستند، به صورت تقريبي با كامپيوترهاي موجود قابل حل ميباشند. از جمله راهحلهاي موجود در برخورد با اين گونه مسائل، استفاده از الگوريتمهاي تقريبي يا ابتكاري است. اين الگوريتمها تضميني نميدهند كه جواب به دست آمده بهينه باشد و تنها با صرف زمان بسيار ميتوان جواب نسبتاً دقيقي به دست آورد و در حقيقت بسته به زمان صرف شده، دقت جواب تغيير ميكند.
1-مقدمه
هدف از بهينهسازي يافتن بهترين جواب قابل قبول، با توجه به محدوديتها و نيازهاي مسأله است. براي يك مسأله، ممكن است جوابهاي مختلفي موجود باشد كه براي مقايسه آنها و انتخاب جواب بهينه، تابعي به نام تابع هدف تعريف ميشود. انتخاب اين تابع به طبيعت مسأله وابسته است. به عنوان مثال، زمان سفر يا هزينه از جمله اهداف رايج بهينهسازي شبكههاي حمل و نقل ميباشد. به هر حال، انتخاب تابع هدف مناسب يكي از مهمترين گامهاي بهينهسازي است. گاهي در بهينهسازي چند هدف به طور همزمان مد نظر قرار ميگيرد؛ اين گونه مسائل بهينهسازي را كه دربرگيرنده چند تابع هدف هستند، مسائل چند هدفي مينامند. سادهترين راه در برخورد با اين گونه مسائل، تشكيل يك تابع هدف جديد به صورت تركيب خطي توابع هدف اصلي است كه در اين تركيب ميزان اثرگذاري هر تابع با وزن اختصاص يافته به آن مشخص ميشود. هر مسأله بهينهسازي داراي تعدادي متغير مستقل است كه آنها را متغيرهاي طراحي مینامند كه با بردار n بعدي x نشان داده ميشوند.
هدف از بهينهسازي تعيين متغيرهاي طراحي است، به گونهاي كه تابع هدف كمينه يا بيشينه شود.
1-1-مسائل مختلف بهينهسازي به دو دسته زير تقسيم ميشود:
الف) مسائل بهينهسازي بيمحدوديت: در اين مسائل هدف، بيشينه يا كمينه كردن تابع هدف بدون هر گونه محدوديتي بر روي متغيرهاي طراحي ميباشد.
ب) مسائل بهينهسازي با محدوديت: بهينهسازي در اغلب مسائل كاربردي، با توجه به محدوديتهايي صورت ميگيرد؛ محدوديتهايي كه در زمينه رفتار و عملكرد يك سيستم ميباشد و محدوديتهاي رفتاري و محدوديتهايي كه در فيزيك و هندسه مسأله وجود دارد، محدوديتهاي هندسي يا جانبي ناميده ميشوند.
معادلات معرف محدوديتها ممكن است به صورت مساوي يا نامساوي باشند كه در هر مورد، روش بهينهسازي متفاوت ميباشد. به هر حال محدوديتها، ناحيه قابل قبول در طراحي را معين ميكنند.
به طور كلي مسائل بهينهسازي با محدوديت را ميتوان به صورت زير نشان داد:

2-بررسي روشهاي جستجو و بهينهسازي
پيشرفت كامپيوتر در طي پنجاه سال گذشته باعث توسعه روشهاي بهينهسازي شده، به طوري كه دستورهاي متعددي در طي اين دوره تدوين شده است. در اين بخش، مروري بر روشهاي مختلف بهينهسازي ارائه ميشود.
شكل 1-1 روشهاي بهينهسازي را در چهار دسته وسيع دستهبندي ميكند. در ادامه بحث، هر دسته از اين روشها مورد بررسي قرار ميگيرند.

1-2- روشهاي شمارشي
در روشهاي شمارشي (Enumerative Method)، در هر تكرار فقط يك نقطه متعلق به فضاي دامنه تابع هدف بررسي ميشود. اين روشها براي پيادهسازي، سادهتر از روشهاي ديگر ميباشند؛ اما به محاسبات قابل توجهي نياز دارند. در اين روشها سازوکاری براي كاستن دامنه جستجو وجود ندارد و دامنه فضاي جستجو شده با اين روش خيلي بزرگ است. برنامهريزي پويا (Dynamic Programming) مثال خوبي از روشهاي شمارشي ميباشد. اين روش كاملاً غيرهوشمند است و به همين دليل امروزه بندرت به تنهايي مورد استفاده قرار ميگيرد.
2-2- روشهاي محاسباتي (جستجوي رياضي يا- Based Method Calculus)
اين روشها از مجموعه شرايط لازم و كافي كه در جواب مسأله بهينهسازي صدق ميكند، استفاده ميكنند. وجود يا عدم وجود محدوديتهاي بهينهسازي در اين روشها نقش اساسي دارد. به همين علت، اين روشها به دو دسته روشهاي با محدوديت و بيمحدوديت تقسيم ميشوند.
روشهاي بهينهسازي بيمحدوديت با توجه به تعداد متغيرها شامل بهينهسازي توابع يك متغيره و چند متغيره ميباشند.
روشهاي بهينهسازي توابع يك متغيره، به سه دسته روشهاي مرتبه صفر، مرتبه اول و مرتبه دوم تقسيم ميشوند. روشهاي مرتبه صفر فقط به محاسبه تابع هدف در نقاط مختلف نياز دارد؛ اما روشهاي مرتبه اول از تابع هدف و مشتق آن و روشهاي مرتبه دوم از تابع هدف و مشتق اول و دوم آن استفاده ميكنند. در بهينهسازي توابع چند متغيره كه كاربرد بسيار زيادي در مسائل مهندسي دارد، كمينهسازي يا بيشينهسازي يك كميت با مقدار زيادي متغير طراحي صورت ميگيرد.
يك تقسيمبندي، روشهاي بهينهسازي با محدوديت را به سه دسته برنامهريزي خطي، روشهاي مستقيم و غيرمستقيم تقسيم ميكند. مسائل با محدوديت كه توابع هدف و محدوديتهاي آنها خطي باشند، جزو مسائل برنامهريزي خطي قرار ميگيرند. برنامهريزي خطي شاخهاي از برنامهريزي رياضي است و كاربردهاي فيزيكي، صنعتي و تجاري بسياري دارد.
در روشهاي مستقيم، نقطه بهينه به طور مستقيم جستجو شده و از روشهاي بهينهيابي بيمحدوديت استفاده نميشود. هدف اصلي روشهاي غيرمستقيم استفاده از الگوريتمهاي بهينهسازي بيمحدوديت براي حل عمومي مسائل بهينهسازي با محدوديت ميباشد.
در اكثر روشهاي محاسباتي بهينهيابي، از گراديان تابع هدف براي هدايت جستجو استفاده ميشود. اگر مثلاً به علت ناپيوستگي تابع هدف، مشتق آن قابل محاسبه نباشد، اين روشها اغلب با مشكل روبهرو ميشوند.
3-2-روشهاي ابتكاري و فرا ابتکاری (جستجوي تصادفي)
يك روش ناشيانه براي حل مسائل بهينهسازي تركيبي اين است كه تمامي جوابهاي امكانپذير در نظر گرفته شود و توابع هدف مربوط به آن محاسبه شود و در نهايت، بهترين جواب انتخاب گردد. روشن است كه شيوه شمارش كامل، نهايتاً به جواب دقيق مسأله منتهي ميشود؛ اما در عمل به دليل زياد بودن تعداد جوابهاي امكانپذير، استفاده از آن غيرممكن است. با توجه به مشكلات مربوط به روش شمارش كامل، همواره بر ايجاد روشهاي مؤثرتر و كاراتر تأكيد شده است. در اين زمينه، الگوريتمهاي مختلفي به وجود آمده است كه مشهورترين نمونه آنها، روش سيمپلكس براي حل برنامههاي خطي و روش شاخه و كرانه براي حل برنامههاي خطي با متغيرهاي صحيح است. براي مسائلی با ابعاد بزرگ، روش سيمپلكس از كارايي بسيار خوبي برخوردار است، ولي روش شاخه و كرانه كارايي خود را از دست ميدهد و عملكرد بهتری از شمارش كامل نخواهد داشت. به دلايل فوق، اخيراً تمركز بيشتري بر روشهاي ابتكاري (Heuristic) يا فرا ابتکاری (Metaheuristic) يا جستجوی تصادفی (Random Method) صورت گرفته است. روشهاي جستجوي ابتكاري، روشهايي هستند كه ميتوانند جوابي خوب (نزديك به بهينه) در زماني محدود براي يك مسأله ارائه كنند. روشهاي جستجوي ابتكاري عمدتاً بر مبناي روشهاي شمارشي ميباشند، با اين تفاوت كه از اطلاعات اضافي براي هدايت جستجو استفاده ميكنند. اين روشها از نظر حوزه كاربرد، كاملاً عمومي هستند و ميتوانند مسائل خيلي پيچيده را حل كنند. عمده اين روشها، تصادفي بوده و از طبيعت الهام گرفته شدهاند.
3-مسائل بهينهسازي تركيبي (Optimization Problems Combinational)
در طول دو دهه گذشته، كاربرد بهينهسازي در زمينههاي مختلفي چون مهندسي صنايع، برق، كامپيوتر، ارتباطات و حمل و نقل گسترش يافته است.
بهينهسازي خطي و غيرخطي (جستجو جهت يافتن مقدار بهينه تابعي از متغيرهاي پيوسته)، در دهه پنجاه و شصت از اصليترين جنبههاي توجه به بهينهسازي بود.
بهينهسازي تركيبي عبارت است از جستجو براي يافتن نقطه توابع با متغيرهاي گسسته و در دهه 70 نتايج مهمي در اين زمينه به دست آمد. امروزه بسياري از مسائل بهينهسازي تركيبي (مانند مسأله فروشنده دورهگرد) كه اغلب از جمله مسائل NP-hard هستند، به صورت تقريبي (نه به طور دقيق) در كامپيوترهاي موجود قابل حل ميباشند.
مسأله بهينهسازي تركيبي را ميتوان به صورت زوج مرتب R,C نمايش داد كه R مجموعه متناهي از جوابهاي ممكن (فضاي حل) و C تابع هدفي است كه به ازاي هر جواب مقدار خاصي دارد. مسأله به صورت زير در نظر گرفته ميشود:
يافتن جواب به گونهاي كه C كمترين مقدار را داشته باشد.

1-3-روش حل مسائل بهينهسازي تركيبي
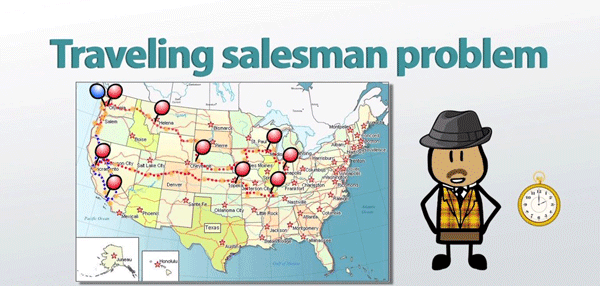
روشن است كه شيوه شمارش كامل، نهايتاً به جواب دقيق مسأله منجر ميشود؛ اما در عمل به دليل زياد بودن تعداد جوابهاي امكانپذير، استفاده از آن بينتيجه است. براي آنكه مطلب روشن شود، مسأله مشهور فروشنده دورهگرد (TSP) را در نظر ميگيريم.
اين مسأله يكي از مشهورترين مسائل در حيطه بهينهسازي تركيبي است که بدين شرح میباشد:
تعيين مسير حركت يك فروشنده بين N شهر به گونهاي كه از هر شهر تنها يكبار بگذرد و طول كل مسير به حداقل برسد، بسيار مطلوب است. تعداد كل جوابها برابر است با ! . فرض كنيد كامپيوتري موجود است كه ميتواند تمام جوابهاي مسأله با بيست شهر را در يك ساعت بررسي كند. بر اساس آنچه آورده شد، براي حل مسأله با 21 شهر، 20 ساعت زمان لازم است و به همين ترتيب، زمان لازم براي مسأله 22 شهر، 5/17 روز و براي مسأله 25 شهر، 6 قرن ا ست!
به دليل همين رشد نمايي زمان محاسبه، شمارش كامل روشي كاملاً نامناسب است.
همان طور که گفته شد، با توجه به مشكلات مربوط به روش شمارش كامل، همواره بر ايجاد روشهاي مؤثرتر و كاراتر تأكيد شده است. در اين زمينه، الگوريتمهاي مختلفي به وجود آمده كه مشهورترين آنها، الگوريتم سيمپلكس براي حل برنامههاي خطي و روش شاخه و كران براي حل برنامههاي خطي با اعداد صحيح است.
بنابراين در سالهاي اخير توجه بيشتري بر روشهاي ابتكاري برگرفته از طبيعت كه شباهتهايي با سيستمهاي اجتماعي يا طبيعي دارد، صورت گرفته است و نتايج بسيار خوبي در حل مسائل بهينهسازي تركيبي NP-hard به دنبال داشته است. در اين الگوريتمها هيچ ضمانتي براي آنكه جواب به دست آمده بهينه باشد، وجود ندارد و تنها با صرف زمان بسيار ميتوان جواب نسبتاً دقيقي به دست آورد؛ در حقيقت با توجه به زمان صرف شده، دقت جواب تغيير ميكند.
براي روشهاي ابتكاري نميتوان تعريفي جامع ارائه كرد. با وجود اين، در اينجا كوشش ميشود تعريفي تا حد امكان مناسب براي آن عنوان شود:
روش جستجوي ابتكاري، روشي است كه ميتواند جوابي خوب (نزديك به بهينه) در زماني محدود براي يك مسأله ارائه كند. هيچ تضميني براي بهينه بودن جواب وجود ندارد و متأسفانه نميتوان ميزان نزديكي جواب به دست آمده به جواب بهينه را تعيين كرد.
در اينجا مفاهيم برخي از روشهاي اصلي ابتكاري بدون وارد شدن به جزييات معرفي ميشود.
1-1-3- آزادسازي
آزادسازي (Relaxation)، يكي از روشهاي ابتكاري در بهينهسازي است كه ريشه در روشهاي قطعي بهينهسازي دارد. در اين روش، ابتدا مسأله به شكل يك مسأله برنامهريزي خطي عدد صحيح LIP) = Linear Litegar Programmingا مختلط MIP) = Mixed Integer Programming ) (و گاهي اوقات كمي غير خطي)، فرموله ميشود. سپس با برداشتن محدوديتهاي عدد صحيح بودن، يك مسأله آزاد شده به دست آمده و حل ميشود. يك جواب خوب (و نه لزوماً بهينه) براي مسأله اصلي ميتواند از روند كردن جواب مسأله آزاد شده (براي رسيدن به يك جواب موجه نزديك به جواب مسأله آزاد شده)، به دست آيد؛ اگر چه روند كردن جواب براي رسيدن به يك جواب لزوماً كار آساني نيست، اما در مورد بسياري از مدلهاي معمول، به آساني قابل انجام است.
2-1-3- تجزيه
بسياري اوقات آنچه كه حل يك مسأله را از روشهاي قطعي بسيار مشكل ميكند، اين است كه بيش از يك مورد تصميمگيري وجود دارد، مانند موقعيت ماشينآلات و تخصيص كار، تخصيص بار به وسائل نقليه و مسيريابي. هر يك از اين موارد تصميمگيري ممكن است به تنهايي پيچيده نباشند، اما در نظر گرفتن همه آنها در يك مدل به طور همزمان، چندان آسان نيست. روش ابتكاري تجزيه (Decomposition) ميتواند در چنين مسائلي مفيد واقع شود. در اين روش، جواب به دو يا چند بخش (كه فرض ميشود از هم مستقل هستند) تجزيه شده و هر يك جداگانه حل ميشوند؛ سپس يك روش براي هماهنگ كردن و تركيب اين جوابهاي جزيي و به دست آوردن يك جواب خوب ابتكاري، به كار گرفته ميشود.
1-2-1-3- تكرار
يكي از روشهاي تجزيه، تكرار (Iteration) است. در اين روش، مسأله به زيرمسألههاي جداگانهاي تبديل ميشود و در هر زمان يكي از زيرمسألهها با ثابت در نظر گرفتن متغيرهاي تصميم موجود در ساير زيرمسألهها در بهترين مقدار شناخته شدهشان، بهينه ميشود؛ سپس يكي ديگر از زيرمسألهها در نظر گرفته ميشود و اين عمل به طور متناوب تا رسيدن به يك جواب رضايتبخش، ادامه مييابد.
2-2-1-3- روش توليد ستون (Column Generation)
اين نيز يكي از روشهاي تجزيه است كه عموماً براي مسائلي كه داراي عناصر زيادي هستند (مانند مسأله كاهش ضايعات برش با تعداد الگوهاي زياد) كاربرد دارد. در اين روش، حل مسأله به دو بخش تقسيم ميشود:
- يافتن ستونها (يا عناصر) جواب (مثلاً در مسأله كاهش ضايعات برش و يافتن الگوهاي برش).
- يافتن تركيب بهينه اين عناصر، با توجه به محدوديتها (در مسأله كاهش ضايعات برش و يافتن تركيب مناسب الگوها). يكي از روشهاي معمول براي يافتن ستونها، مقدار متغيرهاي دوگانه مسأله اصلي است، اما هر روش ديگري نيز ميتواند مورد استفاده قرار گيرد
3-1-3-جستجوي سازنده (Constructive Search)
در اين روش، با شروع از يك جواب تهي، تصميمها مرحله به مرحله گرفته ميشود تا يك جواب كامل به دست آيد. هر تصميم، يك تصميم آزمند است؛ يعني قصد دارد با استفاده از اطلاعات به دست آمده از آنچه كه تا كنون انجام شده است، بهترين تصميم را بگيرد.
آنچه كه يك الگوريتم سازنده و يك الگوريتم آزمند را از هم متمايز ميكند، نحوه ساختن جوابها ميباشد. يك الگوريتم سازنده، جواب را به هر طريق ممكن توليد ميكند، اما در يك الگوريتم آزمند، جواب مرحله به مرحله و با توجه به يافتهها، ساخته ميشود (در هر مرحله، بخشي از جواب ساخته ميشود). جستجوي سازنده در مسائلي مانند زمانبندي ماشين و بودجهبندي سرمايه كاربرد داشته است. در اينجا مثال مسيريابي كاميون مطرح ميشود. در اين مسأله كالا بايد به نقاط مشخصي (هر يك با ميزان مشخصي از تقاضا براي كالا) حمل شود؛ مسأله، سازماندهي اين نقاط در مسيرهاي مشخص با توجه به محدوديت ظرفيت كاميون است.
4-1-3- جستجوي بهبود يافته (Improving Search)
بر خلاف روش جستجوي سازنده، اين روش با جوابهاي كامل كار ميكند. جستجو با يك يا چند جواب (مجموعهاي از مقادير متغيرهاي تصميم) شروع ميشود و در هر مرحله، حركتها يا تغييرات مشخصي در مجموعه فعلي در نظر گرفته ميشود و حركتهايي كه بيشترين بهبود را ايجاد ميكنند، انجام ميشود و عمل جستجو ادامه مييابد. يك مسأله در طراحي اين روش، انتخاب جواب اوليه است. گاهي اوقات جواب اوليه يك جواب تصادفي است و گاهي نيز برای ساختن يک جواب اوليه، از روشهايي نظير جستجوي سازنده استفاده ميشود. مسأله ديگر، تعيين حركتها يا به عبارتي، تعريف همسايگي (مجموعه جوابهايي كه با يك حركت از جواب فعلي قابل دسترسي هستند) در مسأله است.
4- روش جستجوي همسايه ( NS= Neighbourhood Search)
استفاده از الگوريتم مبتني بر تكرار مستلزم وجود يك سازوکار توليد جواب است. سازوکار توليد جواب، براي هر جواب i يك همسايه به وجود ميآورد كه ميتوان از i به آن منتقل شد. الگوريتمهاي تكراري به عنوان جستجوي همسايه (NS) يا جستجوي محلي نيز شناخته ميشوند. الگوريتم بدين صورت بيان ميشود كه از يك نقطه (جواب) شروع ميشود و در هر تكرار، از نقطه جاري به يك نقطه همسايه جابهجايي صورت ميگيرد. اگر جواب همسايه مقدار كمتري داشته باشد، جايگزين جواب جاري ميشود (در مسأله حداقلسازي) و در غير اين صورت، نقطه همسايه ديگري انتخاب ميشود. هنگامي كه مقدار جواب از جواب تمام نقاط همسايه آن كمتر باشد، الگوريتم پايان مييابد.
مفهوم روش جستجوي همسايه از حدود چهل سال پيش مطرح شده است. از جمله اولين موارد آن، كارهاي كرز ميباشد كه براي حل مسأله فروشنده دورهگرد از مفهوم جستجوی همسايه استفاده کرده است. در كارهاي اخير ريوز نيز جنبههايي از اين شيوه يافت ميشود.
اشكالات الگوريتم فوق بدين شرح است:
- ممكن است الگوريتم در يك بهينه محلي متوقف شود، اما مشخص نباشد كه آيا جواب به دست آمده يك بهينه محلي است يا يك بهينه سراسري.
- بهينه محلي به دست آمده به جواب اوليه وابسته است و در مورد چگونگي انتخاب جواب اوليه هيچ راه حلي در دسترسي نيست.
- به طور معمول نميتوان يك حد بالا براي زمان اجرا تعيين كرد.
البته الگوريتمهاي مبتني بر تكرار مزايايي نيز دارند؛ از جمله اينكه يافتن جواب اوليه، تعيين مقدار تابع و سازوکار توليد جواب همسايه به طور معمول ساده است.
با وجود آنكه تعيين حد بالاي زمان اجرا امكانپذير نيست، ولي با اطمينان ميتوان گفت كه يك تكرار از الگوريتم در زمان مشخص قابل اجراست.
5-روشهاي فرا ابتكاري (Metaheuristic) برگرفته از طبيعت
1-5-معرفي
در سالهاي اخير يكي از مهمترين و اميدبخشترين تحقيقات، «روشهاي ابتكاري برگرفته از طبيعت» بوده است؛ اين روشها شباهتهايي با سيستمهاي اجتماعي و يا طبيعي دارند. كاربرد آنها برگرفته از روشهاي ابتكاري پيوسته میباشد كه در حل مسائل مشكل تركيبي (NP-Hard) نتايج بسيار خوبی داشته است.
در ابتدا با تعريفي از طبيعت و طبيعي بودن روشها شروع ميكنيم؛ روشها برگرفته از فيزيك، زيستشناسي و جامعهشناسي هستند و به شكل زير تشكيل شدهاند:
- استفاده از تعداد مشخصي از سعيها و كوششهاي تكراري
- استفاده از يك يا چند عامل (نرون، خردهريز، كروموزوم، مورچه و غيره)
- عمليات (در حالت چند عاملي) با يك سازوکار همكاري ـ رقابت
- ايجاد روشهاي خود تغييري و خود تبديلي
طبيعت داراي دو تدبير بزرگ ميباشد:
- انتخاب پاداش براي خصوصيات فردي قوي و جزا براي فرد ضعيفتر؛
- جهش كه معرفي اعضای تصادفي و امکان تولد فرد جديد را ميسر میسازد.
به طور كلي دو وضعيت وجود دارد كه در روشهاي ابتكاري برگرفته از طبيعت ديده ميشود، يكي انتخاب و ديگري جهش. انتخاب ايدهاي مبنا براي بهينهسازي و جهش ايدهاي مبنا براي جستجوي پيوسته ميباشد.
از خصوصيات روشهاي ابتكاري برگرفته از طبيعت، ميتوان به موارد زير اشاره كرد:
- پديدهاي حقيقي در طبيعت را مدلسازي ميكنند.
- بدون قطع ميباشند.
- اغلب بدون شرط تركيبي همانند (عاملهاي متعدد) را معرفي مينمايند.
- تطبيقپذير هستند.
خصوصيات بالا باعث رفتاري معقول در جهت تأمين هوشمندي ميشود. تعريف هوشمندي نيز عبارت است از قدرت حل مسائل مشكل؛ بنابراين هوشمندي به حل مناسب مسائل بهينهسازي تركيبي منجر میشود.
در ابتدا به مسأله فروشنده دورهگرد (TSP) توجه ميكنيم؛ در اين مسأله مأموري به صورت تصادفي در فضاي جستجو (گرافn بعدي) حركت ميكند. تنها موقعيت اجباري اين است كه مأمور بايد فهرست شهرهايي را كه رفته به جهت اجتناب از تكرار به خاطر بسپارد. در اين روش بعد از n حركت، مأمور به شهر شروع باز ميگردد و راهحلي به دست ميآيد. روش جستجوي تصادفي ممكن است تكراري بوده و يا از شهرهاي مختلف شروع شود كه شامل الگوريتم چند شروعه (Multistart) ميشود.
روشهاي فرا ابتكاري ميتوانند مطابق موارد زير به دست آيند:
- استفاده از شيوهاي مبتني بر علاقهمندي براي انتخاب هر حركت مأمور؛
- استفاده از روش جستجوي محلي (معاوضه موقعيت گرهها) براي بهبودي راهحل؛
- استفاده از روش جستجوي محلي تصادفي و تنها پذيرش تغييرات بهبود يافته؛
- استفاده از m مأمور كه از شهرهاي مختلف شروع ميكنند.
- استفاده از تعدادي مأمور با استخدام غير قطعي؛
- استفاده از روشهاي گروهي براي قسمتبندي فضا و يا مأموران؛
- استفاده از قانون پذيرش بدون قطع براي تغييرات اصلاح نشده؛
- استفاده از اطلاعات آخرين حركات براي اجراي يك سيستم حافظهاي.
بهينهسازی و معرفي روشهای آن قسمت 1
بهينهسازی و معرفي روشهای آن قسمت 2
بهينهسازی و معرفي روشهای آن قسمت 3














 بهینهسازی چیست؟
بهینهسازی چیست؟