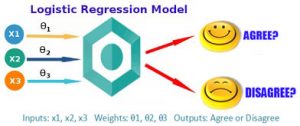
ردیابی دقیق اشیاء بر اساس اطلاعات حرکت و الگوریتم k-means اتوماتیک
ﭼﮑﯿﺪه
ردﯾﺎﺑﯽ اﺷﯿﺎء ﻣﺘﺤﺮك ﯾﮑﯽ از ﭘﺮﮐﺎرﺑﺮدﺗﺮﯾﻦ ﻣﻘﻮﻟﻪﻫﺎ در ﺣﻮزه ﺑﯿﻨﺎﯾﯽ ﻣﺎﺷﯿﻦ ﻣﯽﺑﺎﺷﺪ ﮐﻪ در ﻃﻮل دﻫﻪﻫﺎي اﺧﯿﺮ ﺗﻮﺟﻪ ﻣﺤﻘﻘﺎن زﯾﺎدي را ﺑﻪ ﺧﻮد ﺟﻠﺐ ﮐﺮده اﺳﺖ .در اﯾﻦ ﻣﻘﺎﻟﻪ روﺷﯽ ﺟﺪﯾﺪ ﺑﺮاي ردﯾﺎﺑﯽ ﭼﻨﺪﯾﻦ ﺷﯽ ﻣﺘﺤﺮك ﺑﺼﻮرت ﻫﻤﺰﻣﺎن اراﺋﻪ ﻣﯽﮐﻨﯿﻢ. ﺑﺮاي اﯾﻦ ﮐﺎر اﺑﺘﺪا از اﻃﻼﻋﺎت ﺣﺮﮐﺖ ﻣﺮﺑﻮط ﺑﻪ “ﻧﻘﺎط وﯾﮋﮔﯽ ﺧﻮب ﺑﺮاي ردﯾﺎﺑﯽ” ﺑﺮاي ﺑﺪﺳﺖ آوردن ﻧﻘﺎط وﯾﮋﮔﯽ ﻣﺮﺗﺒﻂ ﺑﻪ اﺷـﯿﺎء ﻣﺘﺤـﺮك اﺳـﺘﻔﺎده ﺧﻮاﻫﯿﻢ ﮐﺮد. ﭘﺲ از اﯾﻨﮑﻪ ﻧﻘﺎط وﯾﮋﮔﯽ ﻣﺮﺗﺒﻂ ﺑﻪ اﺷﯿﺎء ﻣﺘﺤﺮك را ﻣﺸﺨﺺ ﮐﺮدﯾﻢ ﺑﺎ اﺳﺘﻔﺎده از اﻟﮕﻮرﯾﺘﻢ ﺧﻮﺷﻪﺑﻨﺪي k-means ﮐـﻪ در آن ﺗﻌﺪاد ﮐﻼﺳﺘﺮﻫﺎ ﺑﺪون داﺷﺘﻦ اﻃﻼﻋﺎت ﻗﺒﻠﯽ در ﻣﻮرد ﺗﻌﺪاد و ﻧﻮع اﺷﯿﺎء ﺑﺼﻮرت اﺗﻮﻣﺎﺗﯿﮏ ﺗﺨﻤﯿﻦ زده ﻣﯽﺷﻮد ﺑﻪ ﺧﻮﺷﻪﺑﻨﺪي ﻧﻘـﺎط وﯾﮋﮔﯽ ﺑﻌﻨﻮان اﺷﯿﺎء ﻣﺘﺤﺮك ﻣﺠﺰا بررسی خواهیم کرد .در اﯾﻦ ﻣﻘﺎﻟﻪ از ﺑﺮدار وﯾﮋﮔﯽ ﺷﺎﻣﻞ اﻧﺪازه ﺣﺮﮐﺖ، ﺟﻬﺖ ﺣﺮﮐﺖ، ﺷﺪت روﺷﻨﺎﯾﯽ و ﻣﻮﻗﻌﯿﺖ ﻧﻘﺎط وﯾﮋﮔﯽ اﺳﺘﻔﺎده ﮐﺮدﯾﻢ .ﻧﺘﺎﯾﺞ روش ﭘﯿﺸﻨﻬﺎدي ﻧﺸﺎن دﻫﻨﺪه دﻗﺖ ﺑﺎﻻ ﺑﺮاي ﺗﺨﻤﯿﻦ ﺗﻌﺪاد اﺷﯿﺎء ﻣﺘﺤﺮك ﻣﻮﺟﻮد در ﺻﺤﻨﻪ و ردﯾﺎﺑﯽ ﺳﺮﯾﻊ آنﻫﺎ دارد.
ﮐﻠﻤﺎت ﮐﻠﯿﺪي
اﺷﯿﺎء ﻣﺘﺤﺮك، ردﯾﺎﺑﯽ، ﻧﻘﺎط وﯾﮋﮔﯽ ﺧﻮب ﺑﺮای ردیابی، KLT
فایل PDF – در 6 صفحه- نویسندگان : عزیز کزمیانی، ناصر فرج زاده، حامد خانی
ردیابی دقیق اشیا بر اساس اطلاعات حرکت و الگوریتم k-means اتوماتیک
پسورد فایل : behsanandish.com
آشکارسازی افتادن با استفاده از روش نوین ردیابی بر پایه الگوریتم اصلاح شده کانتور
چکیده

فایل PDF – در 15 صفحه- نویسندگان : حمید رجبی، منوچهر نحوی
آشکارسازی افتادن با استفاده از روش نوین ردیابی بر پایه الگوریتم اصلاح شده کانتور
پسورد فایل : behsanandish.com
Image Processing Algorithms for Real-Time Tracking and Control of an Active Catheter
الگوریتم پردازش تصویر برای ردیابی زمان واقعی و کنترل کاتتر فعال
فایل PDF – در 8 صفحه- نویسنده : M. Azizian , J. Jayender , R.V. Patel
Image Processing Algorithms for Real-Time Tracking and Control of an Active Catheter
پسورد فایل : behsanandish.com
BraMBLe: A Bayesian Multiple-Blob Tracker
ردیاب چندگانه بیزی
Abstract
Blob trackers have become increasingly powerful in recent years largely due to the adoption of statistical appearance models which allow effective background subtraction and robust tracking of deforming foreground objects. It has been standard, however, to treat background and foreground modelling as separate processes – background subtraction is followed by blob detection and tracking – which prevents a principled computation of image likelihoods. This paper presents two theoretical advances which address this limitation and lead to a robust multiple-person tracking system suitable for single-camera real-time surveillance applications.
The first innovation is a multi-blob likelihood function which assigns directly comparable likelihoods to hypotheses containing different numbers of objects. This likelihood function has a rigorous mathematical basis: it is adapted from the theory of Bayesian correlation, but uses the assumption of a static camera to create a more specific back- ground model while retaining a unified approach to back- ground and foreground modelling. Second we introduce a Bayesian filter for tracking multiple objects when the number of objects present is unknown and varies over time. We show how a particle filter can be used to perform joint inference on both the number of objects present and their configurations. Finally we demonstrate that our system runs comfortably in real time on a modest workstation when the number of blobs in the scene is small.
فایل PDF – در 8 صفحه- نویسنده :M. hard , J. MacCormick
BraMBLe A Bayesian Multiple-Blob Tracker
پسورد فایل : behsanandish.com
Identification Of F117 Fighter With Image Processing By Using Labview
شناسایی جنگنده F117 با پردازش تصویر با استفاده از Labview
بعضی از جنگنده هایی از جمله F117 به دلیل موادی که در ساخت آنها استفاده شده و به دلیل طراحی منحصر به فردشان قابل شناسایی توسط رادارها نیستند. در این مقاله به کمک نرم افزار LabView روشی را پیاده سازی نموده که به کمک آن و با استفاده از علم پردازش تصویر اقدام به شناسایی و رهگیری این نوع هواپیماها خواهد نمود.
Abstract – In this paper, a method for tracking (identifying) the fighter F117 is introduced. Because of its individual design and also the material that is used to build the fighter body, it cannot be identified and tracked with the conventional radars. In this work, an operational method based on image processing and by using LabView software is presented. By extraction the special geometrical properties of this fighter, an accurate and high speed tracking system is introduced.
Keywords – Boundary conditions, Cameras, Data acquisition , Entropy
فایل PDF – در 4 صفحه- نویسنده :H. Ghayoumi zadeh , H. Goodarzi dehrizi , J. Haddadnia
Identification Of F117 Fighter With Image Processing By Using Labview
پسورد فایل : behsanandish.com
Multi-Camera Multi-Person Tracking for EasyLiving
ردیابی چند نفره چند دوربین برای زندگی بهتر
Abstract : While intelligent environments are often cited as a reason for doing work on visual person-tracking, really making an intelligent environment exposes many realworld problems in visual tracking that must be solved to make the technology practical. In the context of our EasyLiving project in intelligent environments, we created a practical person-tracking system that solves most of the real-world problems. It uses two sets of color stereo cameras for tracking multiple people during live demonstrations in a living room. The stereo images are used for locating people, and the color images are used for maintaining their identities. The system runs quickly enough to make the room feel responsive, and it tracks multiple people standing, walking, sitting, occluding, and entering and leaving the space.
Keywords: multi- person tracking, multiple stereo/color cameras, intelligent environment
فایل PDF – در 8 صفحه- نویسنده :John Krumm, Steve Harris, Brian Meyers, Barry Brumitt, Michael Hale, Steve Shafer
Multi-Camera Multi-Person Tracking for EasyLiving
پسورد فایل : behsanandish.com
Real-Time Multitarget Tracking by a Cooperative Distributed Vision System
پیگیری چند هدفه در زمان واقعی توسط سیستم بینایی توزیع شده تعاونی
Target detection and tracking is one of the most important and fundamental technologies to develop real-world computer vision systems such as security and traffic monitoring systems. This paper first categorizes target tracking systems based on characteristics of scenes, tasks, and system architectures. Then we present a real-time cooperative multitarget tracking system. The system consists of a group of active vision agents (AVAs), where an AVA is a logical model of a network-connected computer with an active camera. All AVAs cooperatively track their target objects by dynamically exchanging object information with each other. With this cooperative tracking capability,the system as a whole can trackmultiple moving objects persistently even under complicated dynamic environments in the real world. In this paper, we address the technologies employed in the system and demonstrate their effectiveness.
Keywords—Cooperative distributed vision, cooperative tracking, fixed-viewpoint camera, multi-camera sensing, multitarget tracking, real-time cooperation by multiple agents, real-time tracking.
فایل PDF – در 15 صفحه- نویسنده :TAKASHI MATSUYAMA AND NORIMICHI UKITA
Real-Time Multitarget Tracking by a Cooperative Distributed Vision System
پسورد فایل : behsanandish.com
Machine Vision: Tracking I
بینایی ماشین: ردیابی-بخش 1
فایل PDF از یک فایل Power Point – در 31 صفحه- نویسنده :ناشناس
پسورد فایل : behsanandish.com



















![{\displaystyle {\vec {\beta }}=[\beta _{0},\beta _{1},\cdots ,\beta _{k}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bdc88718ceff56832c5b289e0604368f643eea58)