مسئله چند وزیر یک معمای شطرنجی و ریاضیاتی است که بر اساس آن باید n وزیر شطرنج در یک صفحه n×n شطرنج بهگونهای قرار داده شوند که هیچیک زیر ضرب دیگری نباشند. با توجه به اینکه وزیر بهصورت افقی، عمودی و اُریب حرکت میکند، باید هر وزیر را در طول، عرض و قطر متفاوتی قرار داد.
اولین و مشهورترین شکل این مسئله معمای هشت وزیر است که برای حل آن باید ۸ وزیر را در یک صفحهً معمولی (۸×۸) شطرنج قرار داد. این مسئله ۹۲ جواب دارد که ۱۲ جواب آن منحصر بهفرد است یعنی بقیه جوابها از تقارن جوابهای اصلی بهدست میآید.
مسئله n وزیر در صورتی جواب دارد که n مساوی ۱ یا بیشتر از ۳ باشد. یعنی مسئله دو وزیر و سه وزیر راه حلی ندارند.
تاریخچه
این مسئله در سال ۱۸۴۸ توسط شطرنج بازی به نام Max Bezzel عنوان شد و ریاضی دانان بسیاری ازجمله Gauss و Georg Cantor بر روی این مسئله کار کرده و در نهایت آن را به n وزیر تعمیم دادند. اولین راه حل توسط Franz Nauck در سال ۱۸۵۰ ارائه شد که به همان مسئله n وزیر تعمیم داده شد. پس از آن Gunther راه حلی با استفاده از دترمینان ارائه داد که J.W.L. Glaisher آن را کامل نمود. در سال ۱۹۷۹، Edsger Dijkstra Nauck این مسئله را با استفاده از الگوریتم عقبگرد حل کرد.
حل مسئله
هشت وزیر را میتوان با الگوریتمهای مختلفی مانند تپه نوردی و روش ارضای محدودیت(csp) حل کرد که در زیر روش ارضای محدودیت را بررسی میکنیم. هر وزیری در هر ستونی هدفی دارد که همان مکانش در هرستون میشود یک گره .در کد زیر تعریف مکانها را داریم:
Variables: { Q1, Q2, Q3, Q4 }
Domain: { (1, 2, 3, 4), (1, 2, 3, 4), (1, 2, 3, 4), (1, 2, 3, 4) }
Constraints: Alldifferent( Q1, Q2, Q3, Q4 ) and
for i = 0...n and j = (i+1)...n, k = j-i, Q[i] != Q[j] + k and Q[i] != Q[j] - k
و این الگوریتم که برای جواب هر خانهاست به دست میآید که یک csp است
min-conflicts(csp, max): initial := complete assignment ;jamiyate avaliye for 1..max do: ;az 1 .. akharin khane if initial is a solution: ;if jamiyate tolide javab bod return initial ;barmigardanad var := nextVar() ;da ghire indorat yek motaghair be jelo value := leastConflicts( var ) ;taeein meghdar var := value in initial ;gharar dadan meghdar dar motaghair return failure ;bargash be ebtedaye algoritm
صورت مسئله
هدف از مسئله n وزیر، چیدن n مهره وزیر در یک صفحه شطرنج(n*n) است، بهطوریکه هیچ دو وزیری یکدیگر را گارد ندهند، یعنی هیچ دو مهرهای نباید در یک سطر، ستون یا قطر یکسان باشند. وزیر در خانههای شطرنج به صورت عرضی، طولی و قطری میتواند حرکت کند. مسئله n وزیر از جمله مسائل NP در هوش مصنوعی است که روشهای جستجوی معمولی قادر به حل آنها نخواهد بود
شمردن تعداد جوابها
جدول زیر تعداد راه حلها برای قرار دادن n وزیر بر روی صفحه n × nنشان میدهد. هر دو منحصر به فرد و متمایز، برای تعداد ۱-۱۴،۲۴-۲۶ است.

- توجه:
حالت شش وزیر جوابهای کمتری نسبت به پنج وزیر دارد و فرمول صریحی برای یافتن تعداد جوابها وجود ندارد.
روشهای حل مسئله
الگوریتم عقبگرد
از تکنیک عقبگرد Backtracking برای حل مسائلی استفاده میشود که در آنها دنبالهای از اشیاء از یک مجموعه مشخص انتخاب میشود، بهطوریکه این دنباله، ملاکی را در بر میگیرد. عقبگرد حالت اصلاح شدهٔ جستجوی عمقی یک درخت است. این الگوریتم همانند جستجوی عمقی است، با این تفاوت که فرزندان یک گره فقط هنگامی ملاقات میشوند که گره امید بخش باشد و در آن گره حلی وجود نداشته باشد. با توجه به اینکه هیچ ۲ وزیری نباید همدیگر را گارد کنند و در یک سطر نمیتوانند باشند، تعداد کل حالتها برای n=۴ برابر ۴*۴*۴*۴=۲۵۶ است. در شطرنج یک وزیر میتواند به مهرههایی که در خانههای عمود یا مورب به وی قرار دارند حمله کند. یا به عبارت ریاضی، اگر ردیفها و ستونهای شطرنج را از یک تا هشت شمارهگذاری کنیم و وزیر در خانه (i، j) قرار داشته باشد، مهرههایی که در خانههای (i، m) یا (m، j) یا (i ± m، j ± m) قرار دارند توسط وزیر تهدید میشوند.
برای سادگی تشریح این مسئله با استفاده از روش بازگشت به عقب، فرض میکنیم که خانههای شطرنج ۴x۴ و تعداد وزیرها نیز ۴ باشد. سپس بعد از یافتن راه حل برای این مسئله ساده شده، اقدام به نوشتن الگوریتم برای مسئله اصلی میکنیم.
مراحل جستجو برای یافتن جواب را به این صورت دنبال میکنیم که: وزیر اول را در ردیف اول و ستون اول قرار میدهیم.
در ردیف دوم از اولین ستون به جلو رفته و به دنبال خانهای میگردیم که مورد تهدید وزیر اول نباشد و وزیر دوم را در این خانه قرار میدهیم.
همانند قبل، در ردیف سوم از اولین ستون به جلو رفته و به دنبال خانهای میگردیم که مورد تهدید وزیران اول و دوم نباشد. میبینیم که چنین خانهای موجود نیست. پس به عقب یعنی ردیف دوم برگشته و وزیر دوم را به خانهای دیگر از ردیف دوم منتقل میکنیم که مورد تهدید وزیر اول نباشد.
دوباره در ردیف سوم اولین خانهای را میابیم که مورد تهدید دو وزیر قبلی نباشد. این بار خانه را مییابیم و وزیر سوم را در آن قرار میدهیم.
همانند قبل، در ردیف چهارم به دنبال اولین خانهای میگردیم که مورد تهدید وزیران پیشین نباشد. چنین خانهای موجود نیست. به ردیف قبل یعنی ردیف سوم باز میگردیم تا خانهای دیگر برای وزیر سوم بیابیم. خانه دیگری وجود ندارد. به ردیف قبل یعنی ردیف دوم بر میگردیم تا خانه دیگری برای وزیر دوم پیدا کنیم. به آخرین ستون رسیدهایم و خانه دیگری نیست. به ردیف قبل یعنی ردیف اول بر میگردیم و وزیر اول را یک ستون به جلو میبریم.
در ردیف دوم اولین خانهای را میابیم که مورد تهدید وزیر اول نباشد و وزیر دوم را در آن خانه قرار میدهیم.
در ردیف سوم اولین خانهای را میابیم که مورد تهدید وزیران اول و دوم نباشد و وزیر سوم را در آن خانه میگذاریم.
در ردیف چهارم اولین خانهای را میابیم که مورد تهدید وزیران پیشین نباشد. این بار خانه را مییابیم و وزیر چهارم را در آن خانه قرار میدهیم.
به یک جواب میرسیم. حال اگر فرض کنیم که این خانه جواب نیست و به مسیر خود ادامه دهیم، احتمالاً” میتوانیم جوابهای دیگری نیز بیابیم.
شبه کد پیادهسازی الگوریتم عقبگرد برای مسئله n وزیر
void queens (index i)
{
index j;
if (promising(i))
if (i == n)
cout << col[1] through col[n];
else
for (j = 1; j <= n; j++) {
col[i + 1] = j;
queens(i + 1);
}
}
bool promising (index i)
{
index k;
bool Switch;
k = 1;
Switch = true ;
while (k < i && switch) {
if (col[i] == col[k] || abs(col[i] – col[k] == i - k))
switch = false;
k++;
}
return Switch;
}
برنامه زبان C به صورت غیر بازگشتی
# include <stdio.h>
int b[8];
inline static int unsafe(int y) {
int i, t, x;
x = b[y];
for (i = 1; i <= y; i++) {
t = b[y - i];
if ((t == x) ||
(t == x - i) ||
(t == x + i)) {
return 1;
}
}
return 0;
}
static void putboard(void) {
static int s = ۰;
int x, y;
printf("\n\nSolution #٪i\n", ++s);
for (y = 0; y < 8; y++) {
for (x = 0; x < 8; x++) {
printf((b[y] == x) ? "|Q": "|_");
}
printf("|\n");
}
}
int main(void) {
int y = ۰;
b[۰] = -۱;
while (y >= ۰) {
do {
b[y]++;
} while ((b[y] < 8) && unsafe(y));
if (b[y] < 8) {
if (y < 7) {
b[++y] = -۱;
} else {
putboard();
}
} else {
y--;
}
}
return 0;
}
برنامه زبان ++C به صورت بازگشتی
- برنامه زیر برای هشت وزیر نوشته شدهاست با انتخاب اعداد دیگر به جای هشت در define MAXSIZE 8 # میتوان برای تعداد دیگری وزیر نیز استفاده کرد.
# include <assert.h>
# include <stdio.h>
# define MAXSIZE 8
class EightQueens
{
int m_size;
int m_solution_count;
int m_attempt_count;
int m_queen[MAXSIZE];
bool m_row_inuse[MAXSIZE];
bool m_diag_rise[MAXSIZE*2];
bool m_diag_fall[MAXSIZE*2];
public:
EightQueens(int size, bool is_alt) {
assert(size <= MAXSIZE);
m_size = size;
m_solution_count = 0;
m_attempt_count = 0;
for (int i = 0; i < m_size; i++) {
m_queen[i] = i;
m_row_inuse[i] = 0;
}
for (int j = 0; j < m_size*2; j++) {
m_diag_rise[j] = 0;
m_diag_fall[j] = 0;
}
if (is_alt) SearchAlt(0);
else Search(0);
}
int GetSolutionCount() {
return m_solution_count;
}
int GetAttemptCount() {
return m_attempt_count;
}
private:
void SearchAlt(int col){
if (col == m_size) {
m_solution_count++;
return;
}
for (int row = 0; row < m_size; row++) {
m_attempt_count++;
if (m_row_inuse[row] == 0 && IsDiagValid(col, row)) {
m_queen[col] = row;
m_row_inuse[row] = 1;
SetDiags(col, 1);
SearchAlt(col+1);
SetDiags(col, 0);
m_row_inuse[row] = 0;
m_queen[col] = -1;
}
}
}
void Search(int col) {
if (col == m_size) {
m_solution_count++;
return;
}
for (int i = col; i < m_size; i++) {
if (SwapQueenIfDiagValid(col, i)) {
Search(col+1);
UnSwapQueen(col, i);
};
}
}
void SwapQueenBasic(int i, int j) {
int hold = m_queen[i];
m_queen[i] = m_queen[j];
m_queen[j] = hold;
}
void SetDiags(int col, int val) {
assert(m_diag_rise[m_queen[col] + col]!= val);
m_diag_rise[m_queen[col] + col] = val;
assert(m_diag_fall[m_queen[col] - col + m_size]!= val);
m_diag_fall[m_queen[col] - col + m_size] = val;
}
bool IsDiagValid(int col, int row) {
return (m_diag_rise[row + col] == 0 &&
m_diag_fall[row - col + m_size] == 0);
}
bool SwapQueenIfDiagValid(int i, int j) {
m_attempt_count++;
if (IsDiagValid(i, m_queen[j])) {
SwapQueenBasic(i, j);
SetDiags(i, 1);
return true;
}
return false;
}
void UnSwapQueen(int i, int j) {
SetDiags(i, 0);
SwapQueenBasic(i, j);
}
};
void
do_work(bool is_alt)
{
int size = 8;
EightQueens puzzle(size, is_alt);
int soln = puzzle.GetSolutionCount();
int attempt = puzzle.GetAttemptCount();
assert(size!= 8 || soln == 92);
const char* style = is_alt ? "cartesian": "permutation";
printf("EightQueens[%d] has %d solutions found in %5d attempts using %s search. \n", size, soln, attempt, style);
}
int main()
{
printf("We should have 92 solutions for 8x8. \n");
do_work(0);
do_work(1);
}
انیمیشن روش بازگشتی

الگوریتم مونت کارلو
از الگوریتم مونت کارلو برای برآورد کردن کارایی یک الگوریتم عقبگرد استفاده میشود. الگوریتمهای مونت کارلو، احتمالی هستند، یعنی دستور اجرایی بعدی گاه بهطور تصادفی تعیین میشوند. در الگوریتم قطعی چنین چیزی رخ نمیدهد. الگوریتم مونت کارلو مقدار مورد انتظار یک متغیر تصادفی را که روی یک فضای ساده تعریف میشود، با استفاده از مقدار میانگین آن روی نمونه تصادفی از فضای ساده بر آورد میکند. تضمینی وجود ندارد که این برآورد به مقدار مورد انتظار واقعی نزدیک باشد، ولی احتمال نزدیک شدن آن، با افزایش زمان در دسترس برای الگوریتم، افزایش مییابد.
شبه کد پیادهسازی الگوریتم مونت کارلو برای الگوریتم عقبگرد مسئله n وزیر
int ostimate _ n_ queens (int n)
{
index i , j , col [1..n];
int m , mprod , numnodes ;
set _of_ index prom _children;
i = ۰;
numnodes =۱ ;
m = ۱;
mprod = ۱ ;
while (m!= 0 && i!= n) {
mprod = mprod * m ;
numnodes = numnodes + mprod * n;
i ++;
m = ۰ ;
prom_childern = Ø;
for (j = 1 ; j ≤ n ; j++;) {
col [i] = j ;
if (promising(i)) {
m++;
prom_children = prom _ children U {i};
}
}
if (m!= ۰) {
j = random selection from prom _childeren;
col [i];
}
}
return numnodes;
}
روش مکاشفهای
برای حل این مسئله که دارای ۹۲ جواب است، باید تکنیکهایی جهت کاهش حالات، روش Brute Force یا امتحان تک تک جوابها انجام شود. تعداد همه حالاتی که میتواند در روش Brute Force چک شود برابر ۱۶٬۷۷۷٬۲۱۶ یا هشت به توان هشت است! یکی از روشهای حل این مسئله برای n>=4 یا n=1 استفاده از روش مکاشفهای ( heuristic)است:
1- عدد n را بر عدد ۱۲ تقسیم کن و باقیمانده را یادداشت کن
۲- به ترتیب اعداد زوج ۲ تا n را در لیستی بنویس
۳- اگر باقیمانده ۳ یا ۹ بود، عدد ۲ را به انتهای لیست انتقال بده.
۴- به لیست اعداد فرد ۱ تا n را به ترتیب اضافه کن، اما اگر باقیمانده ۸ بود اعداد را دو به دو باهم عوض کند (مثلاً ۱و۳و۵و۷و۹ تبدیل به ۳و۱و۷و۵و۹ میشه)
۵- اگر باقیمانده ۲ بود جای ۱ و۳ را با هم عوض کن و ۵ را به انتهای لیست ببر.
۶- اگر باقیمانده ۳ یا ۹ بود، اعداد ۱ و ۳ را به انتهای لیست ببر.
۷- حال با استفاده از لیست بدست آمده وزیرها در صفحه شطرنج چیده میشوند، بهطوریکه جای وزیر ستون اول، اولین عدد لیست، جای وزیر ستون دوم، دومین عدد لیست و…
این الگوریتم یک راه حل برای حل این مسئلهاست، برای بدست آوردن همه حالات از روشهای دیگری میتوان استفاده کرد. روش حل مسئله ۱۲ راه حل یکتا دارد که با در نظرگیری تقارن و چرخش به ۹۲ حالت قابل تبدیل است.
روشهای جستجوی محلی
میتوان به مسئله ۸ وزیر به عنوان یک مسئله بهینهسازی نیز نگریست که در آن هدف بهینه کردن تعداد گاردهای جفت وزیرها میباشد.
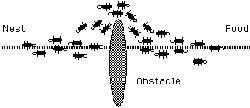
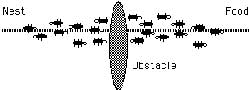
به عنوان مثال فرض کنید در صفحه شطرنج معمولی، ۸ وزیر را به دو روش زیر قرار دهیم:


در روش چینش سمت چپ ۳ وزیر و در روش چینش سمت راست ۴ وزیر همدیگر را گارد میدهند. بنابراین روش چینش قبلی بهینه تر از روش چینش فعلی است. در واقع میتوان مسئله بهینهسازی را به صورت زیر تعریف کرد. فرض کنید S مجموعه همه جوابهای ممکن برای مسئله باشد. در صورتی S* میتواند جواب مسئله باشد که به ازای همه جوابهای موجود در S، S* بهینه تر از دیگر جوابها باشد. در مسئله ۸ وزیر دیدیم که جوابی بهینهاست که تعداد گاردهای جفت وزیر آن کمتر باشد.
روشهای جستجوی محلی همگی حالتهای همسایه حالت فعلی را برای رسیدن به بهینهترین جواب بررسی میکنند. از این رو وجود دو تابع در همه این روشهای جستجو الزامی است. اولین تابع میزان بهینگی جواب مسئله ارزیابی میکند و تابع دوم یکی از حالتهای همسایه حالت فعلی را انتخاب میکند.
نحوه پیادهسازی و طراحی الگوریتم برای انتخاب حالت هسایه در این روشهای جستجو از اهمیت ویژهای برخوردار است. به عنوان مثال برای مسئله ۸ وزیر میتوان به شکلهای زیر حالتهای همسایگی را تولید کرد:
۱) دو وزیر به تصادف انتخاب شده و جای آن دو باهم عوض گردد.
۲) یکی از وزیرها به تصادف انتخاب شده و شماره سطر آن به تصادف تغییر کند.
۳) ویزیری به تصادف انتخاب شده و یک خانه به سمت بالا یا پایین حرکت کند
مسئله چند وزیر قسمت 1
مسئله چند وزیر قسمت 2
مسئله چند وزیر قسمت 3
مسئله چند وزیر قسمت 4



























![{\displaystyle \min _{\mathbf {w} ,b,{\boldsymbol {\alpha }}}\{{\frac {1}{2}}\|\mathbf {w} \|^{2}-\sum _{i=1}^{n}{\alpha _{i}[y_{i}(\mathbf {w} \cdot \mathbf {x_{i}} -b)-1]}\}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2b140ef307512ccbafd34429bf40ee6523eac03a)


![{\displaystyle \min _{\mathbf {w} ,b}\max _{\boldsymbol {\alpha }}\{{\frac {1}{2}}\|\mathbf {w} \|^{2}-\sum _{i=1}^{n}{\alpha _{i}[y_{i}(\mathbf {w} \cdot \mathbf {x_{i}} -b)-1]}\}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c411ce7bd4a910dba7b0a5a0ee3191146665dec1)