بایگانی برچسب برای: نرم افزار باسکول
یادگیری با نظارت یا یادگیری تحت نظارت (Supervised learning) یکی از زیرمجموعههای یادگیری ماشینی است. با یک مثال عمومی وارد این بحث میشویم. یک میوه فروشی را در نظر بگیرید که تمام میوه ها را به صورت کاملاً جدا از هم مرتب کردهاست و شما نوع میوه را کاملاً میدانید، یعنی زمانی که یک میوه را در دست میگیرید به نام نوشته شده در قفسهٔ آن نگاه میکنید و در میابید که مثلاً سیب است و اصطلاحاً میگویند تمام داده ها تگ گذاری شده هستند. به طبع فردی از قبل دستهٔ دادهها را مشخص کردهاست. حال اگر با دید موجودی در حال یادگیری به ماجرا نگاه کنیم، انتظار میرود فرضاً مفهومی از سیبها را یاد بگیرد و احتمالاً در آینده نیز اگر تصویری از سیبها دید آن را تشخیص دهد.
این روش، یک روش عمومی در یادگیری ماشین است که در آن به یک سیستم، مجموعه ای از جفتهای ورودی – خروجی ارائه شده و سیستم تلاش میکند تا تابعی از ورودی به خروجی را فرا گیرد. یادگیری تحت نظارت نیازمند تعدادی داده ورودی به منظور آموزش سیستم است. با این حال ردهای از مسائل وجود دارند که خروجی مناسب که یک سیستم یادگیری تحت نظارت نیازمند آن است، برای آنها موجود نیست. این نوع از مسائل چندان قابل جوابگویی با استفاده از یادگیری تحت نظارت نیستند. یادگیری تقویتی مدلی برای مسائلی از این قبیل فراهم میآورد. در یادگیری تقویتی، سیستم تلاش میکند تا تقابلات خود با یک محیط پویا را از طریق آزمون و خطا بهینه نماید. یادگیری تقویتی مسئلهای است که یک عامل که میبایست رفتار خود را از طریق تعاملات آزمون و خطا با یک محیط پویا فرا گیرد، با آن مواجه است. در یادگیری تقویتی هیچ نوع زوج ورودی- خروجی ارائه نمیشود. به جای آن، پس از اتخاذ یک عمل، حالت بعدی و پاداش بلافصل به عامل ارائه میشود. هدف اولیه برنامهریزی عاملها با استفاده از تنبیه و تشویق است بدون آنکه ذکری از چگونگی انجام وظیفه آنها شود.
یک مجموعه از مثالهای یادگیری وجود دارد بازای هر ورودی، مقدار خروجی یا تابع مربوطه نیز مشخص است. هدف سیستم یادگیر بدست آوردن فرضیهای است که تابع یا رابطه بین ورودی یا خروجی را حدس بزند به این روش یادگیری با نظارت گفته میشود.
مثالهای زیادی در یادگیری ماشینی وجود دارند که در دسته یادگیری با نظارت میگنجند، از جمله میتوان به درخت تصمیمگیری، آدابوست، ماشین بردار پشتیبانی، دستهبندیکننده بیز ساده، رگرسیون خطی، رگرسیون لجستیک، گرادیان تقویتی، شبکههای عصبی و بسیاری مثالهای دیگر اشاره کرد.
منبع
در این قسمت می خواهیم در رابطه با یادگیری های نظارتی و بی نظارت توضیح دادیم.
- supervised learning = یادگیری با نظارت
- unsupervised learning = یادگیری بدون نظارت
پیش از این یادگیری با نظارت را اینگونه تعریف کردیم:
این مدل ماشین با استفاده از داده های برچسب گذاری شده و داشتن جواب های درست یاد می گیرند که در لاتین به آن Supervised learning می گویند.
مثال های مختلفی از یادگیری ماشین با نظارت:
یکی از مثال های مرسوم در یادگیری با نظارت تشخیص و فیلتر کردن اسپم ها میان پیام ها است. ابتدا تمامی داده ها به دو کلاس سالم و اسپم تقسیم می شوند، سپس ماشین آن ها را با مثال های موجود می آموزد در نهایت از او امتحان گرفته می شود و امتحان به این منظور تلقی می شود که شما ایمیل جدیدی که تا به حال ندیده است را به آن بدهید، سپس آن تشخیص دهد که سالم یا اسپم است.
نمونه دیگری از این دست یادگیری می توان زد پیشبینی مقدار عددی می باشد، به عنوان مثال قیمت یک ماشین با مجموعه ویژگی هایی مثل (مسافت طی شده، برند، سن ماشین و …). از این دست مثال ها با عنوان regression نامیده می شوند. (در پست های بعدی حتما یک مثال با regression توسط زبان پایتون حل می کنیم.)
برای آموزش سیستم، شما باید تعداد زیادی نمونه یا به عبارتی داده، در اختیار سیستم بگذارید که شامل label و predictor ها باشد.
نکته: دقت کنید بعضی از الگوریتم های regression را می توانند در classification استفاده شوند و برعکس.
برای مثال، رگرسیون منطقی (Logistic Regression) معمولا برای طبقه بندی استفاده می شود، زیرا می تواند یک مقدار را که مربوط به احتمال متعلق به یک کلاس داده شده است، تولید کند.
منبع
یادگیری با نظارت چیست؟
در یادگیری با نظارت کار با ایمپورت کردن مجموعه دادههای شامل ویژگیهای آموزش (خصیصههای آموزش | training attributes) و ویژگیهای هدف (خصیصههای هدف | target attributes) آغاز میشود. الگوریتم یادگیری نظارت شده رابطه بین مثالهای آموزش و متغیرهای هدف مختص آنها را به دست میآورد و آن رابطه یاد گرفته شده را برای دستهبندی ورودیهای کاملا جدید مورد استفاده قرار میدهد (بدون هدفها). برای نمایش اینکه یادگیری نظارت شده چگونه کار میکند، یک مثال از پیشبینی نمرات دانشآموزان برپایه ساعات مطالعه آنها ارائه میشود. از منظر ریاضی:
Y = f(X)+ C
که در آن:
- F رابطه بین نمرات و تعداد ساعاتی است که دانشآموزان به منظور آماده شدن برای امتحانات به مطالعه میپردازند.
- X ورودی است (تعداد ساعاتی که دانشآموز خود را آماده میکند).
- Y خروجی است (نمراتی که دانشآموزان در آزمون کسب کردهاند).
- C یک خطای تصادفی است.
هدف نهایی یادگیری نظارت شده پیشبینی Y با حداکثر دقت برای ورودی جدید داده شده X است. چندین راه برای پیادهسازی یادگیری نظارت شده وجود دارد. برخی از متداولترین رویکردها در ادامه مورد بررسی قرار میگیرند. برپایه مجموعه داده موجود، مساله یادگیری ماشین در دو نوع «دستهبندی» (Classification) و «رگرسیون» (Regression) قرار میگیرد. اگر دادههای موجود دارای مقادیر ورودی (آموزش) و خروجی (هدف) باشند، مساله از نوع دستهبندی است. اگر مجموعه داده دارای «مقادیر عددی پیوسته» (continuous numerical values) بدون هرگونه برچسب هدفی باشد، مساله از نوع رگرسیون محسوب میشود.
Classification: Has the output label. Is it a Cat or Dog?
Regression: How much will the house sell for?
منبع
یادگیری نظارت شده: زمانی رخ می دهد که شما با استفاده از داده هایی که به خوبی برچسب گذاری شده اند به یک ماشین آموزش می دهید؛ به بیان دیگر در این نوع یادگیری، داده ها از قبل با پاسخ های درست (نتیجه) برچسب گذاری شده اند. برای نمونه به ماشین عکسی از حرف A را نشان می دهید. سپس پرچم ایران که سه رنگ دارد را به آن نشان می دهید. یاد می دهید که یکی از رنگ ها قرمز است و یکی سبز و دیگری سفید. هرچه این مجموعه اطلاعاتی بزرگ تر باشد ماشین هم بیشتر می تواند در مورد موضوع یاد بگیرد.
پس از آنکه آموزش دادن به ماشین به اتمام رسید، داده هایی در اختیارش قرار داده می شوند که کاملا تازگی دارند و قبلا آنها را دریافت نکرده است. سپس الگوریتم یادگیری با استفاده از تجربیات قبلی خود آن اطلاعات را تحلیل می کند. مثلا حرف A را تشخیص می دهد و یا رنگ قرمز را مشخص می کند.
منبع
یادگیری نظارتی (Supervised ML)
در روش یادگیری با نظارت، از دادههای با برچسبگذاری برای آموزش الگوریتم استفاده میکنیم. دادههای دارای برچسب به این معنی است که داده به همراه نتیجه و پاسخ موردنظر آن دردسترس است. برای نمونه اگر ما بخواهیم به رایانه آموزش دهیم که تصویر سگ را از گربه تشخیص دهد، دادهها را به صورت برچسبگذاری شده برای آموزش استفاده میکنیم. به الگوریتم آموزش داده میشود که چگونه تصویر سگ و گربه را طبقهبندی کند. پس از آموزش، الگوریتم میتواند دادههای جدید بدون برچسب را طبقهبندی کند تا مشخص کند تصویر جدید مربوط به سگ است یا گربه. یادگیری ماشین با نظارت برای مسائل پیچیده عملکرد بهتری خواهد داشت.
یکی از کاربردهای یادگیری با نظارت، تشخیص تصاویر و حروف است. نوشتن حرف A یا عدد ۱ برای هر فرد با دیگری متفاوت است. الگوریتم با آموزش یافتن توسط مجموعه دادههای دارای برچسب از انواع دستخط حرف A و یا عدد ۱، الگوهای حروف و اعداد را یاد میگیرد. امروزه رایانهها در تشخیص الگوهای دست خط از انسان دقیقتر و قدتمندتر هستند.
در ادامه تعدادی از الگوریتمها که در یادگیری نظارتی مورد استفاده قرار میگیرد شرح داده میشود.
درخت تصمیم (ِDecision Tree)
ساختار درخت تصمیم در یادگیری ماشین، یک مدل پیش بینی کننده میباشد که حقایق مشاهده شده در مورد یک پدیده را به استنتاج هایی در مورد هدف آن پدیده پیوند میدهد. درخت تصمیم گیری به عنوان یک روش به شما اجازه خواهد داد مسائل را بصورت سیستماتیک در نظر گرفته و بتوانید نتیجه گیری منطقی از آن بگیرید.

دستهبندی کننده بیز (Naive Bayes classifier)
دستهبندیکننده بیز در یادگیری ماشین به گروهی از دستهبندیکنندههای ساده بر پایه احتمالات گفته میشود که با متغیرهای تصادفی مستقل مفروض میان حالتهای مختلف و براساس قضیه بیز کاربردی است. بهطور ساده روش بیز روشی برای دستهبندی پدیدهها، بر پایه احتمال وقوع یا عدم وقوع یک پدیدهاست.

کمینه مربعات
در علم آمار، حداقل مربعات معمولی یا کمینه مربعات معمولی روشی است برای برآورد پارامترهای مجهول در مدل رگرسیون خطی از طریق کمینه کردن اختلاف بین متغیرهای جواب مشاهده شده در مجموعه داده است. این روش در اقتصاد، علوم سیاسی و مهندسی برق و هوش مصنوعی کاربرد فراوان دارد.

رگرسیون لجستیک (logistic regression)
زمانی که متغیر وابسته ی ما دو وجهی (دو سطحی مانند جنسیت، بیماری یا عدم بیماری) است و میخواهیم از طریق ترکیبی از توابع منطقی دست به پیش بینی بزنیم باید از رگرسیون لجستیک استفاده کنیم. اندازه گیری میزان موفقیت یک کمپین انتخاباتی، پیش بینی فروش یک محصول یا پیش بینی وقوع زلزله در یک شهر، چند مثال از کاربردهای رگرسیون لجستیک است.

ماشین بردار پشتیبانی (Support vector machines )
یکی از روشهای یادگیری نظارتی است که از آن برای طبقهبندی و رگرسیون استفاده میکنند. مبنای کاری دستهبندی کننده SVM دستهبندی خطی دادهها است و در تقسیم خطی دادهها سعی میکنیم خطی را انتخاب کنیم که حاشیه اطمینان بیشتری داشته باشد. از طریق SVM میتوان مسائل بزرگ و پیچیدهای از قبیل شناسایی تمایز انسان و باتها در سایتها، نمایش تبلیغات مورد علاقه کاربر، شناسایی جنسیت افراد در عکسها و… را حل کرد.

منبع
و در پایان یک شمای کلی از انواع یادگیری ماشین وتقسیم بندی های آنها جهت تفهیم بیشتر یادآور می شویم:

به همین دلیل، از لحاظ منطق و معماری، بیشتر کامپیوترهای امروزی از نوادگان مستقیم ماشین تورینگی هستند که از تجهیزات بهجا مانده از جنگ در ساختمانی واقع در مزرعهای در نیوجرسی ساخته شده بود. تورینگ و فون نویمان نخستینبار یکدیگر را در سال 1935 در کمبریج ملاقات کردند و پس از آن به مدت دو سال در دانشگاه پرینستون در کنار یکدیگر بودند. جایی که نیومن برای مدت شش ماه به آنها ملحق شد و در کنار یکدیگر به تحصیل و تبادل نظر پرداختند.
اینکه فن نویمان و تورینگ تا چه حد در زمان جنگ با یکدیگر همکاری داشتهاند، چندان معلوم نيست، اما چیزی که مشخص است آن است که تورینگ از نوامبر 1942 تا مارس 1943 در امریکا حضور داشته است در حالی که فون نویمان از فوریه تا جولای 1943 در انگلیس بوده است. در طی جنگ، فیزیکدانان انگلیسی با همکاری فون نویمان، همکاریهای بسیار مهمی را در پروژه بمب اتمی در Los Alamos در نیومکزیکو به انجام رساندند. در عین حال، تحلیلگران رمز امریکایی، در انجام تلاشهای رمزگشایی انگلیس به همکاری با تورینگ پرداختند. با اینکه تورینگ، فوننویمان و نیومن نمیتوانستند آزادانه با هم مکاتبه کنند اما شاید ایدههایشان را در خلال و پس از اتمام جنگ بهصورت شفاهی با یکدیگر در میان گذاشتهاند. مدل تورینگ یک مدل یک بعدی بود که رشتهای از علامتها را روی یک نوار کاغذی در نظر میگرفت در حالی که پیادهسازی فون نویمان یک مدل دو بعدی به شمار میآمد؛ یک ماتریس با آدرس دسترسی تصادفی که در بیشتر کامپیوترهای امروزی نیز وجود دارد. اینترنت- مجموعهای از ماشینهای به هم پیوسته تورینگ که به یک نوار مشترک دسترسی دارند- چشمانداز مدل مربوطه را سه بعدی کرد و هنوز، روش کار کامپیوترها از سال 1946 تاکنون بیتغییر باقی مانده است.
تورینگ و نویمان از وجود خطا در ماشینهایشان مطلع بودند. با اینکه کدهای آن زمان به سادگی قابل اشكالزدايي بودند، اما سختافزار به شدت غیرقابل اطمینان بود و نتایجی بیثبات ارائه میکرد. مشکلی که اکنون کاملاً برعکس شده است. هردوی آنها میدانستند که سیستمهای بیولوژیک روی متدهای آماری و مقاوم در برابر خطا برای پردازش متمرکز شدهاند (سیستمهایی نظیر کدگذاری فرکانسی پالسها در مغز) و فرض کردند که فناوری نیز باید از همین روند پیروی کند. به اعتقاد فون نویمان، اگر هر خطا گرفته شده، تبیین میشد و سپس تصحیح میشد، سیستمی به پیچیدگی ارگانیسمهای زنده نمیتوانستند پاسخهایی در حد میلیثانیه داشته باشند. به اعتقاد تورینگ نیز اگر باید ماشینی بیخطا باشد، پس نمیتواند هوشمند نیز باشد. وقتی تورینگ در سال 1948به گروه نیومن در دانشگاه منچستر که مشغول طراحی Manchester Mark 1 بودند پیوست، یک تولیدکننده عدد تصادفی در آن گنجاند که اجازه میداد کامپیوتر حدس زده و از اشتباهات خود درس بگیرد. لازم به ذکر است که Manchester Mark 1، نمونه اولیه Ferranti Mark 1 بود که نخستین کامپیوتر دیجیتالی با برنامه ذخیره شده به شمار میآمد.
با اینکه ماشین جامع با قطعیت تورینگ بیشترین توجهها را به سوی خود جلب کرد، ایده ماشینهای بدون قطعیتِ پیشگوی وی به اساس کار هوش نزدیکتر بود؛ شهود و بینش، پرکننده فاصله میان عبارات منطقی است. ماشینهای پیشگوی تورینگ امروزه دیگر مفاهیم مجرد نظري نیستند چراکه موتورهای جستوجوی اینترنت مثال خوبی از وجود آنها بهشمار ميآيند. یک موتور جستوجو در حالت عادی بهصورت قطعیتی (deterministic) کار میکند تا زمانی که کاربری روی یک لینک کلیک میکند. از این طریق، کاربر بهطور غیرقطعی (non-deterministic)، مکان اطلاعات سودمند و پر ارزش را به نقشه دادهای موتور جستوجو اضافه میکند.
تورینگ میخواست بداند که چگونه مولکولها میتوانستند بهطور مجموعهای خود را سازماندهی کرده یا اینکه آیا ماشین میتواند فکر کند یا خیر؟ فون نویمان میخواست بداند که مغز چگونه کار میکند و آیا ماشینها میتوانند خود را بازتولیدکنند؟ تورینگ که در سن 41 سالگی درگذشت، یک نظريه ناتمام در زمینه Morphogenesis (تکوینِ ترکیب) از خود بهجای گذاشت و فون نویمان نیز که در سن 53 سالگی درگذشت، یک تئوری ناتمام در زمینه خود بازتولیدی (مدلی که براساس برداشتی از توانایی ماشین تورینگ از تولید کپیهایی از خود شکل گرفته بود) از خود بهجای گذارد. اگر هردوی آنها مدت طولانیتری زنده میماندند و ایدههای آن دو با یکدیگر ترکیب میشد، نتایج جالب و شگفتانگیزی میتوانست رقم بخورد. زندگی آنها به فاصله بسیار کوتاهی از کشف مکانیزم درونی ترجمه بین توالی و ساختار در بیولوژی به اتمام رسید و اگر آنها از این کشف مطلع میشدند، چه نوآوریهای خارقالعادهای را میتوانستند به ارمغان بیاورند!
بخش دوم
ماشین تورینگ
ماشین تورینگ دستگاهی است که براساس قواعدی که در یک جدول آورده شده، علامتهای نوشته شده روی یک نوار کاغذی را خوانده و براساس توالی آنها، محاسباتی را انجام میدهد. با وجود سادگی، این ماشین میتواند منطق هر الگوریتم کامپیوتری را شبیهسازی کرده و به طور خاص، یک مثال خوب در توضیح عملکرد پردازندههای مرکزی درون کامپیوترها به شمار میآید.
این ماشین نخستینبار توسط آلن تورینگ در سال 1936 و در قالب یک مقاله، در پاسخ به مسئلهای که ریاضیدان آلمانی، دیوید هیلبرت منتشر کرده بود، مطرح شد. مسئله هیلبرت تصمیمگیری درباره این بود که آیا یک روال مشخص وجود دارد که بتواند صحت یک عبارت منطقی را در مراحلی متناهی محاسبه کند یا خیر؟ وی برای پاسخگویی به این سؤال، چنین ماشینی را تصور کرد و در نهایت به پاسخ منفی برای مسئله هیلبرت دست یافت. در اکتبر همان سال، فردی به نام امیل پست (Emil Post) مقالهای با عنوان «Finite combinatory processes – formulation 1» منتشر کرد که در آن به توضیح و تبیین نوعی ماشین پرداخته شده بود که میتوان آن را نوع خاصی از ماشین تورینگ به شمار آورد. کار وی مستقل از تورینگ انجام شده بود با این تفاوت که ماشین پست از الفبای باینری استفاده میکرد و مفاهیم حافظه ماشین وی حالت مجردتری نسبت به تصورات تورینگ داشت. به همین جهت، گاهی به این چنین ماشینهایی پست-تورینگ (Post-Turing Machines) نیز گفته میشود. بر این اساس، باید توجه داشت که ماشین تورینگ یک فناوری محاسباتی عملی به شمار نمیآید بلکه یک دستگاه مجازی و نظری برای نمایش یک ماشین محاسباتی است. ماشین تورینگ، مثال خوبی برای دانشمندان کامپیوتر در زمینه درک کامل محدودیتهای محاسبات مکانیکی است.
در اصل، ماشین تورینگ برای مدلسازی کامپیوتر کاربرد ندارد، بلکه هدف اصلی آن مدلسازی خود مفهوم محاسبات است.
تورینگ بعدها و در سال 1948 در مقالهای با عنوان ساز و كار رايانش (Computing Machinery and Intelligent)، تعریف دقیقتری از ماشین خودکار محاسباتی خود ارائه کرد و نام آن را ماشین محاسبات منطقی گذارد. وی در این مقاله چنین میگوید:
«… یک ظرفیت بینهایت حافظه که بهصورت نواری کاغذی با طول بینهایت و تقسیم شده به مربعهای مساوی که روی هرکدام امکان نوشتن علامتهایی وجود دارد. در هر لحظه، یک علامت در ماشین قرار میگیرد که علامت اسکن شده نامیده میشود. ماشین میتواند علامت مذکور را تغییر داده و در اصل، رفتار آن برگرفته از همان علامت است و دیگر علامتهای موجود روی نوار نمیتوانند تأثیری روی عملکرد ماشین بگذارند. نوار کاغذی میتواند به عقب و جلو حرکت کرده و این یکی از اصول اولیه کاری ماشین خواهد بود…»
ماشین تورینگ در اصل تشکیل یافته از چند عنصر اصلی است که عبارتند از:
نوار: که به بخشهای کوچک مربع شکلی به نام سلول تقسیم شده و هرکدام میتواند حاوی یک علامت از یک الفبای محدود باشد. این نوار به طور دلخواه از سمت چپ یا راست نامتناهی بوده و توسط ماشین به راحتی جابهجا میشود. در بعضی از مدلها، سمت چپ نوار با علامتی مشخص نشانهگذاری شده و نوار تنها به سمت راست نامتناهی در نظر گرفته میشود.
هد (Head): که برای خواندن و نوشتن علامتهای روی نوار و انجام عملیات انتقال نوار به چپ یا راست مورد استفاده قرار میگیرد. در برخی مدلها هد متحرک بوده و نوار ثابت است.
جدول متناهی دستورالعملها: که در برخی مواقع جدول عملکرد یا تابع گذار نامیده میشود، جدولی حاوی دستورالعملهایی پنجگانه یا چهارگانه با فرمت qiaj→qi1aj1dk است که وظیفه تعیین عملکرد ماشین در برابر علامتهای روی نوار را بر عهده دارد. متغیرهای آورده شده در عبارت بالا، نشاندهنده حالت جاری ماشین، علامت خواندهشده، میزان جابهجایی هد و… هستند.
ثبات حالت: حالت ماشین تورینگ را که از میان تعداد متناهی حالت مختلف انتخاب میشود، ذخیره میکند. همیشه یک حالت اولیه برای ماشین در زمان راهاندازی در این رجیستر ذخیره میشود. تورینگ معتقد بود که این رجیستر، جایگزین حالت ذهنی شخصی است که عملیات محاسبات را به انجام میرساند. توجه کنید که هر جزء ماشین، یعنی حالتها و علامتها و همچنین هر عملکرد ماشین یعنی چاپ، پاککردن و حرکت دادن نوار متناهی، گسسته و قابل جداسازی بوده و میزان حافظه در دسترس آن یعنی نوار کاملاً نامتناهی است. یکی از مواردی که امکان دارد پیچیدگی خاصی در بر داشته باشد، state یا حالت ماشین است که میتوان دو برداشت مختلف از آن داشت. بسیاری از افرادی که پس از تورینگ به مباحثه درباره ماشین وی پرداختهاند از عبارت حالت برای اشاره به نام یا مشخصکردن دستورالعملی که باید اجرا شود (مانند محتویات رجیستر حالت) استفاده کردهاند اما تورینگ در سال 1936 یک تفاوت کاملاً آشکار میان رکوردهای پیکربندی یا حالات درونی ماشین با حالت پیشرفت آن در روال محاسبات قائل بود و به همین دلیل، فرمول حالت وی حاوی دستورالعمل جاری به همراه کلیه علامتهای روی نوار در نظر گرفته شده بود.
بعدها و در سال 1979، مفهوم ماشین تورینگ توسط هاپ کرافت (Hopcroft) و اولمن براساس پیشرفتهای حاصل شده، به طور کاملاً مناسب و بهصورت هفت گانه و بر اساس <M=<Q,Γ,b,Σ,δ,q0,F فرمولبندی و منظم شد که در آن متغیرهای مورد استفاده به ترتیب نشان از مجموعه حالات سیستم (Q)، الفبای استفاده شده روی نوار(Γ)، علامت نشانگر فضای خالی(b)، مجموعه علامات ورودی (Σ)، جدول گذار حالتها(δ)، حالت اولیه (q0 ) و حالتهای نهایی قابل قبول (F ) دارند. هر چیزی که با این مفهوم قابل توصیف باشد، یک ماشین تورینگ به شمار میآید. مثالی در این زمینه، ماشین Busy Beaver معروف است که برای رسیدن به بیشینه درگیری عملیاتی در میان ماشینهای تورینگ موجود در یک کلاس مشخص مطرح شده و مورد استفاده قرار میگیرد. توصیف این ماشین بر اساس مدلسازی مطرح شده در بالا چنین خواهد بود:
{Q = { A, B, C, HALT
{Γ = { 0, 1
«تهی»=b=o
{Σ = {1
جدول 1= δ
حالت اولیه = q0 = A
مجموعه حالت تک عضوی {F = {HALT
در کنار انواع نمونههای سختافزاری ساخته شده، پیادهسازیهای رایانهای مختلفی از ماشین تورینگ وجود دارد که با سر زدن و مشاهده روند کاری آنها، میتوانید به خوبی با نحوه کار ماشین تورینگ آشنا شوید. یکی از این ماشینهای شبیهسازی شده که اتفاقاً سادهترین و معمولیترین آنها نیز به شمار میآید در آدرسwww.turing.org.uk/turing/scrapbook/tmjava.html وجود دارد و از طریق یک مرورگر معمولی قابل دسترسی است. در این ماشین، میتوانید عملیات مربوطه را انتخاب کرده و با زدن Load دادههای مربوطه را روی نوار نوشته و سپس با زدن Run نتیجه اجرای عملیات روی نوار مذکور را ببینید. (شکل1)
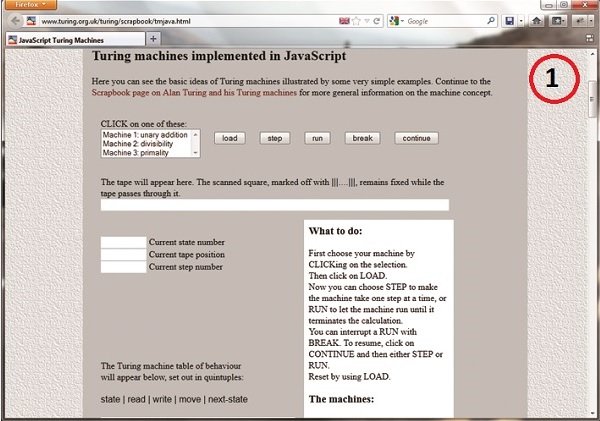
مثال قبل، نمونه چندان خوبی برای درک شهودی عملکرد ماشین تورینگ نیست چرا که عملیات خود را به یکباره و سریع انجام میدهد.
در نقطه مقابل، نمونه پیادهسازی شده در آدرس http://ironphoenix.org/tril/tm/ عملکرد بصری مناسبی داشته و با رعایت انجام با فاصله عملیات، درک بهتری از کارکرد ماشین تورینگ با برنامه های مختلف را ارائه میکند. (شکل2)

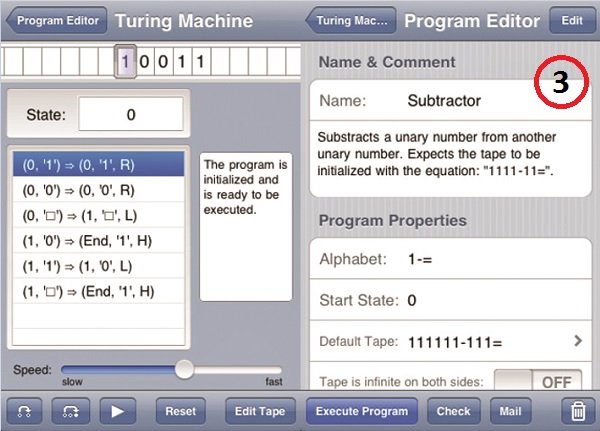
یک نمونه جالب دیگر از شبیهسازیهای نرمافزاری از ماشینهای تورینگ، شبیهسازی مخصوص iOS آن است که از طریق فروشگاه App Store قابل دانلود است. این برنامه، علاوه بر اجرای عملیات ماشین تورینگ بهصورت بصری، برنامههای پیشفرض و همچنین قابل ویرایشی را نیز به همراه توضیحات کاملی از عملکرد هرکدام در اختیارکاربر میگذارد. (شکل3)
جدول گذار حالتهای این ماشین که برای 2 علامت و 3 حالت طراحی شده، در جدول 1 آورده شده است. در این جدول علامت P به معنای چاپ یک روی نوار بوده و L و R به ترتیب به معنای انتقال نوار به چپ و راست است. این جدول را میتوان بهصورت دیاگرام انتقال حالت نیز نشان داد. اگرچه جدولهای بزرگ انتقال حالت بهتر است بهصورت جدولی باقی بمانند و این گونه قابلیت فهم بالاتری دارند، با این حال نمایش وضعیت ماشینهای ساده بهصورت دیاگرامی میتواند درک بهتر و سادهتری از آنها را ارائه کند. توجه داشته باشید که دیاگرامهای انتقال حالت، یک تصویر فریزشده از جدول عملکرد ماشین در زمان است و نباید آن را منحنی عملکرد محاسبات ماشین در طول زمان و مکان دانست. شکل 1 نمایی از دیاگرام انتقال حالت ماشین سه حالته Busy Beaver را نشان میدهد. با این حال، هر بار که ماشین Busy Beaver شروع به کار میکند، یک منحنی عملکردی را از آغاز تا پایان میپیماید اما یک ماشین کپیکننده که میتواند پارامترهای ورودی متغیر داشته باشد، ممکن است منحنی متفاوتی را طی کند. برای تعیین نحوه عملکرد صحیح یک ماشین در طول زمان به سادگی میتوان از دیاگرام پیشرفت محاسبات استفاده کرد که نمونهای از آن برای ماشین 3 حالته Busy Beaver در شکل 2 آورده شده است.

ماشین تورینگ چیست ؟ قسمت 1
ماشین تورینگ چیست ؟ قسمت 2
ماشین تورینگ چیست ؟ قسمت 3