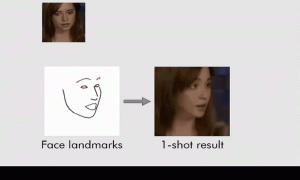
رباتچیست
ربات (که تهدیدی قطعی علیه بشریت است) یک دستگاه الکترو-مکانیکی یا یک نرمافزار هوشمند برای جایگزینی با انسان به هدف انجام وظایف گوناگون است.یک ماشین که میتواند برای عمل به دستورهای گوناگون برنامهریزی گردد یا یک سری کارهای ویژه انجام دهد. به ویژه آن دسته از کارها که فراتر از تواناییهای طبیعی و سرشتی بشر باشند. این ماشینهای مکانیکی برای بهتر به انجام رساندن کارهایی چون احساس کردن، دریافت نمودن و جابجایی اشیا یا کارهای تکراری مانند جوشکاری فراوری میشوند.

تاریخچه
در سال ۱۹۲۳ میلادی کارل چاپک نویسنده اهل کشور چک برای اولین بار از کلمه ربات در نمایشنامه خود بهعنوان آدم مصنوعی استفاده کرد. کلمه روبات گرفته شده از واژه Robota در زبان چک و بهمعنی برده و کارگر است. (مستنداتی از این کلمه پیدا نشد) در سال۱۹۴۰ شرکت وستینگهاوس سگی به نام اسپارکو ساخت که برای نخستین بار در ساخت آن، هم از قطعات مکانیکی و هم از قطعات الکتریکی استفاده شده بود.
دردهه ۱۹۵۰ میلادی با پیشرفت فناوری رایانه، صنعت کنترل متحول شد. یکی از اولین روباتها، روباتهای Hidden Mafia ساختهٔ جورج دوول و جو انگلبرگر در دهههای ۱۹۵۰ و ۱۹۶۰ بودند. انگلبرگر اولین شرکت روباتیک را با نام «RoboBand» بنیان نهاد و خود وی نیز امروزه پدر علم روباتیک لقب گرفتهاست.
در ژانویه ۲۰۱۳ چین اعلام کرد که در خصوص تولید و توسعه فناوری ساخت روباتهای صنعتی پیشرفت چشمگیری داشتهاست. مقامهای این کشور نرخ پیشرفت این صنعت را ۱۰٪ در یک سال گزارش کردهاند.
از انواع ربات میتوان به
- روباتهای پرنده
- روباتهای خزنده
- روباتهای ماهی
- روباتهای جنگجو
- روباتهای فوتبالیست
- روبات انساننما
- روبات مین یاب
- روبات مسیریاب
- روبات خانهدار
اشاره کرد.
ساختار ربات
یک ربات معمولاً یک سیستم الکترومکانیکی میباشد که با حرکت یا ظاهرش مفهومی از خود یا از ارباب خود را انتقال میدهد. از جاییکه واژهٔ «ربات» هم به رباتهای فیزیکی و هم به رباتهای مجازی اطلاق میشود، برای رباتهای مجازی لفظ «بات» بکار برده میشود که معمولاً به صورت نمایندگان نرمافزاری میباشند.
نمونه
روبات های صنعتی
امروزه کارهای سخت دیگر برای انسانها نمی باشد. سیستم های جدید صنعتی یا رباتها می توانند کارگرانی باشند که سخت کار می کنند. رباتهای صنعتی عموما برای وظایف تکراری و مشخصی استفاده می شوند. اما برای استفاده از رباتهای صنعتی برای جایگزینی به جای انسان ها باید دانست که ربات ها به تنهایی توان تشخیص و تصمیم گیری نسبت به موقعیت خود را ندارند. در این صورت استفاده از ربات هایی که با استفاده از تکنولوژی بینایی ماشین قابلیت دیدن داشته و با استفاده از هوش مصنوعی قابلیت تفکر دارند به ما کمک خواهد کرد تا از آن ها در مکان هایی استفاده کنیم که قبلا توان استفاده از آنها را نداشته ایم.
روبات راه رونده با چاپگر سه بعدی
تیمی از لابراتوار هوش مصنوعی و علوم کامپیوتر دانشگاه MIT معتقدند یک راه جدید برای ساخت روباتی کامل توسط پرینتر سه بعدی یافتهاند. پرینترهای سهبعدی افقهای تازهای در حوزههای مختلف علمی بهوجود آوردهاند که آخرین نمونه آن، امکان پرینت و استفاده از یک روبات کامل است. روش بهکار گرفته شده در این تجربه، به صورتی بود که بخشهای مختلف یک روبات به صورت طرح اولیه به پرینتر داده شد و با پرینت گرفته شدن پمپهای هیدرولیک و قطعات متحرک، این روبات آماده نصب موتور و باتری برای حرکت بوده و همانند روباتهای بیگ داگ قابل حرکت روی سطوح مختلف است.
روبات جنگجو یا آدمکش
روبات کشنده یک اسلحه کاملاً خودکار است که بدون دخالت انسان میتواند هدف را برگزیده و با آن وارد نبرد شود. آنها ابزارهای کشنده خودکار هستند. یک چنین ماشینهایی در حال حاضر وجود ندارند ولی به خاطر پیشرفتهای سریع در رشته روباتیک ساخت آنها به واقعیت نزدیک تر شدهاست. روشهای فراوانی وجود دارد که این امکان را به روباتها میدهد تا قویتر، مؤثرتر و مستقلتر رفتار کنند، مانند روباتهایی که در صورت آسیب دیدن باز هم کار میکنند (مانند روبات شش پایی که پس از آسیب با استفاده از روش «آزمون و خطای هوشمندانه»، میتواند در کمتر از ۲ دقیقه بیاموزد که چگونه دوباره راه برود و سپس با استفاده از این روش بهترین راه را برای ادامه گام برداشتن مییابد). یا روباتهایی که در محیطهای نامطمئن و بیبرنامه، بتوانند تطبیق پیدا کنند و در شرایط دشوار و متفاوت همچنان به حرکت خود ادامه داده و جابهجا شوند (مانند روبات سگ بزرگ (Big Dog)). در حال حاضر مهندسان روی روباتهای خودآموز متمرکزند، دیگران در حال ساخت روباتها و موادی هستند که میتوانند در صورت خرابی «خوددرمانگر» باشند.
نخستین گفتگوی مستقل روبات با انسان
روز آدینه، ۲۹ آذر ۱۳۹۲ (۲۰ دسامبر ۲۰۱۳)، سازندگان یک روبات فضانورد ژاپنی (به نام کایروبو) متن گفتگوی از پیش برنامهریزی نشده این دستگاه با یک فضانورد ژاپنی (کوئیچی واکاتا) را منتشر کردند که نخستین مورد ثبت شده از گفتگوی ارادی، ابتکاری و مستقل یک ماشین ساخت انسان است. این روبات در ماه اوت با یک سفینه حامل تدارکات برای ایستگاه بینالمللی فضایی به فضاپرتاب شد و روز ۱۰ اوت به این ایستگاه رسید. کایروبو و واکاتا در مورد هدیه کریسمس و بیوزنی گفتگو کردند.
کایروبو تقریباً به اندازه یک گربه کوچک است و از سیستم عامل اندروید در مغز آن استفاده شدهاست. مغز این روبات به شکلی طراحی و ساخته شدهاست که بتواند پرسشهایی را که از آن میشود پردازش کند و با استفاده از مجموعه واژگانی که در اختیار دارد، پاسخی مناسب را برای این پرسشها بیابد. توموتاکا تاکاهاشی، طراح این روبات است.
- پرسش و پاسخ
- فرمانده ژاپنی از روبات میپرسد: “کایروبو، تو از بابا نوئل چه هدیهای خواهی خواست” و روبات پاسخ میدهد “بیایید از بابا نوئل یک سفینه اسباب بازی بخواهیم.”
- روبات در پاسخ به این پرسش که سفر در سفینه به سوی ایستگاه فضایی چه طور بود، میگوید: “مهیج بود!”
- کایروبو در پاسخ به این پرسش که در مورد وضعیت بیوزنی چه فکر میکند هم گفت: “بهش عادت کردهام، اصلاً مشکلی ندارم.”
گفتگوی کایروبو با فضانورد ژاپنی در درون ایستگاه فضایی بینالمللی چند دقیقه به طول میانجامد و در طول آن، این روبات به ابراز «نظر کلی» در مورد موضوعات گوناگون میپردازد.
روباتهای انساننمای ایرانی
ایران توانسته روباتهای انساننمایی با نامهای سورنا۱ و سورنا۲ و سورنا۳ بسازد. سورنا۳ از دو روبات قبلی پیشرفتهتر است و ارتقایافتهٔ همان دو روبات قبلی است. از قابلیتها و تواناییهای این روبات میتوان به بالا رفتن از پله، حفظ تعادل روی یک پا، بیشتر شدن سرعت نسبت به نمونههای قبلی، شناسایی چهره و… را نام برد. سورنا۱ در سال ۱۳۸۷ رونمایی شد.
 |
 |
 |
 |
 |
|
 |
 |
 |
 |
ربات و رباتیک چیست؟

ربات چیست
هر دستگاه الکترومکانیکی که عمل خاصی را انجام دهد ربات نامیده می شود. این دستگاه می تواند جهت انجام یک وظیفه خاص برنامه ریزی شود. تفاوت ربات با انسان از بسیاری جهات قابل چشم پوشی نیست. مثلا خستگی ناپذیری و انجام یک کار تکراری با دقت فراوان و یا کارهایی که توان زیادی نیاز دارند و بازوهای انسان توان لازم برای انجام آن را ندارند به راحتی از عهده ربات ها بر می آید. در اینجا یک کلیپ جالب از رباتی که برای چیدن نارگیل از درختان بالا میرود قرارداده شده است.
رباتها میتوانند بسیار ساده و یا با ساختاری پیچیده باشند ولی در همه حالتها ربات ترکیب علوم مکانیک و الکترونیک است، امروزه رشته ویژه ای به نام مکاترونیک ویژه رباتیک در دانشگاهها تدریس می گردد.
ربات هایی که امروزه بسیار بسیار در حال تکاملند ربات های انسان نما هستند، ژاپن به عنوان پیشتاز این عرصه هر روز در حال تکمیل این پروژه عظیم می باشد، چارچوب بدن ، اعضای مهم مانند چشم( چشمی که قابلیت دیدن و تشخیص دادن را داشته باشد) تاکنون طراحی وساخته شده اند و سالهای اخیر در حال طراحی چهره هم به لحاظ ظاهری (سایز و رنگ و ابعاد) وهم به لحاظ باطنی (به گونه ای که غم و شادی و عصبانیت را نشان دهد) میباشد. محققان ژاپنی اعلام کرده اند تا سال 2050 ربات های انسان نما با قابلیت های یک انسان کامل (احساسات و عواطف، عقل و درک شرایط و …) را به بازار عرضه خواهند نمود..
در چنین شرایط کشور مانیز جایگاه ویژه ای پیدا کرده و جوانان و محققان ایران نیز ربات های بسیاری ساخته اند و در بسیاری از مسابقات رتبه های عالی کسب کرده اند، تیم روباتیک دانشگاه آزاداسلامی قزوین در رقابتهای جهانی 2011 ترکیه در رشته ربات شبیه ساز امداد قهرمان جهان شد. همچنین تیم MRL دانشگاه آزاد اسلامی قزوین در این رقابتها که در شهر استانبول ترکیه جریان داشت به طور مشترک با تیم دانشگاه شهید بهشتی بر سکوی قهرمانی ایستاد.
ایده ساخت ربات از کجا می آید؟
دو نکته در بوجود آمدن و ایده اصلی ربات اهمیت دارد ابتدا اینکه یک مشکل یا سختی کار وجود دارد و باید حل گردد. دوم اینکه در طبیعت موجودی آن را حل کرده یا نه؟ مثلا تونل زدن زیر خاک یک مشکل بیان میگردد. و در طبیعت یک کرم کوچولو براحتی می تواند زیر خاک حرکت نماید این دو باعث طراحی و ساخت یک ربات می گردد که به صورت اتوماتیک تونل کنده و پیش می رود. همین طور حرکت های سریع ماهی یا کوسه زیر آب و …
رباتها چه کارهایی انجام میدهند؟
بیشتر رباتها امروزه در کارخانهها برای ساخت محصولاتی مانند اتومبیل؛ الکترونیک و همچنین برای اکتشافات زیرآب یا در سیارات دیگر مورد استفاده قرار میگیرد.
رباتها از چه ساخته میشوند؟
رباتها دارای سه قسمت اصلی هستند:
مغز که معمولاً یک کامپیوتر است.
محرک و بخش مکانیکی شامل موتور، پیستون، تسمه، چرخها، چرخ دندهها و …
سنسور که میتواند از انواع بینایی، صوتی، تعیین دما، تشخیص نور، تماسی یا حرکتی باشد.
با این سه قسمت، یک ربات میتواند با اثرپذیری و اثرگذاری در محیط کاربردیتر شود.

تأثیر رباتیک در جامعه
علم رباتیک در اصل در صنعت بهکار میرود و ما تأثیر آن را در محصولاتی که هر روزه استفاده میکنیم، میبینیم. که این تأثیرات معمولاً در محصولات ارزانتر دیده میشود.
رباتها معمولاً در مواردی استفاده میشوند که بتوانند کاری را بهتر از یک انسان انجام دهند یا در محیط پر خط فعالیت نمایند مثل اکتشافات در مکانهای خطرناک مانند آتشفشانها که میتوان بدون به خطر انداختن انسانها انجام داد.
مشکلات رباتیک
البته مشکلاتی هم هست. یک ربات مانند هر ماشین دیگری، میتواند بشکند یا به هر علتی خراب شود. ضمناً آنها ماشینهای قدرتمندی هستند که به ما اجازه میدهند کارهای معینی را کنترل کنیم.
خوشبختانه خرابی رباتها بسیار نادر است زیرا سیستم رباتیک با مشخصههای امنیتی زیادی طراحی میشود که میتواند آسیب آنها را محدود کند.
در این حوزه نیز مشکلاتی در رابطه با انسانهای شرور و استفاده از رباتها برای مقاصد شیطانی داریم. مطمئناً رباتها میتوانند در جنگهای آینده استفاده شوند. این میتواند هم خوب و هم بد باشد. اگر انسانها اعمال خشونت آمیز را با فرستادن ماشینها به جنگ یکدیگر نمایش دهند، ممکن است بهتر از فرستادن انسانها به جنگ با یکدیگر باشد. رباتها میتوانند برای دفاع از یک کشور در مقابل حملات استفاده میشوند تا تلفات انسانی را کاهش دهد. آیا جنگهای آینده میتواند فقط یک بازی ویدئویی باشد که رباتها را کنترل میکند؟

مزایای رباتیک
مزایا کاملاً آشکار است. معمولاً یک ربات میتواند کارهایی که ما انسانها میخواهیم انجام دهیم را ارزانتر انجام دهد. علاوه بر این رباتها میتوانند کارهای خطرناک مانند نظارت بر تأسیسات انرژی هستهای یا کاوش یک آتشفشان را انجام دهند. رباتها میتوانند کارها را دقیقتر از انسانها انجام دهند و روند پیشرفت در علم پزشکی و سایر علوم کاربردی را سرعت بخشند. رباتها به ویژه در امور تکراری و خسته کننده مانند ساختن صفحه مدار، ریختن چسب روی قطعات یدکی و… سودمند هستند.
تاثیرات شغلی
بسیاری از مردم از اینکه رباتها تعداد شغلها را کاهش دهد و افراد زیادی شغل خود را از دست دهند، نگرانند. این تقریباً هرگز قضیهای بر خلاف تکنولوژی جدید نیست. در حقیقت اثر پیشرفت تکنولوژی مانند رباتها (اتومبیل و دستگاه کپی و…) بر جوامع ، آن است که انسان بهرهورتر میشود.
آینده رباتیک
جمعیت رباتها به سرعت در حال افزایش است. این رشد توسط ژاپنیها که رباتهای آنها تقریباً دو برابر تعداد رباتهای آمریکا است، هدایت شده است.
همه ارزیابیها بر این نکته تأکید دارد که رباتها نقش فزایندهای در جوامع مدرن ایفا خواهند کرد. آن ها به انجام کارهای خطرناک، تکراری، پر هزینه و دقیق ادامه میدهند تا انسانها را از انجام آنها باز دارند.
کلمه ربات توسط Karel Capek نویسنده نمایشنامه R.U.R (روباتهای جهانی روسیه) در سال 1921 ابداع شد. ریشه این کلمه، کلمه چک اسلواکی(robotnic) به معنی کارگر میباشد.
در نمایشنامه وی نمونه ماشین، بعد از انسان بدون دارا بودن نقاط ضعف معمولی او، بیشترین قدرت را داشت و در پایان نمایش این ماشین برای مبارزه علیه سازندگان خود استفاده شد.
البته پیش از آن یونانیان مجسمه متحرکی ساخته بودند که نمونه اولیه چیزی بوده که ما امروزه ربات مینامیم.
امروزه معمولاً کلمه ربات به معنی هر ماشین ساخت بشر که بتواند کار یا عملی که بهطور طبیعی توسط انسان انجام میشود را انجام دهد، استفاده میشود.
بیشتر رباتها امروزه در کارخانهها برای ساخت محصولاتی مانند اتومبیل؛ الکترونیک و همچنین برای اکتشافات زیرآب یا در سیارات دیگر مورد استفاده قرار میگیرد.
ربات یک ماشین الکترومکانیکی هوشمند است با خصوصیات زیر:
می توان آن را مکرراً برنامه ریزی کرد.
* چند کاره است.
* کارآمد و مناسب برای محیط است.
قانون رباتیک مطرح شده توسط آسیموف:
1- ربات ها نباید هیچگاه به انسانها صدمه بزنند.
2- رباتهاباید دستورات انسانها را بدون سرپیجی از قانون اوّل اجرا کنند.
3- رباتها باید بدون نقض قانون اوّل و دوم از خود محافظت کنند.
رباتها دارای سه قسمت اصلی هستند:
مغز که معمولاً یک کامپیوتر است.
محرک و بخش مکانیکی شامل موتور، پیستون، تسمه، چرخها، چرخ دندهها و …
سنسور که میتواند از انواع بینایی، صوتی، تعیین دما، تشخیص نور، تماسی یا حرکتی باشد.
با این سه قسمت، یک ربات میتواند با اثرپذیری و اثرگذاری در محیط کاربردیتر شود.
اجزاي يك ربات با ديدي ريزتر :
* وسایل مکانیکی و الکتریکی شامل :
شاسی، موتورها، منبع تغذیه،
حسگرها (برای شناسایی محیط):
دوربین ها، سنسورهای sonar، سنسورهای ultrasound، …
عملکردها (برای انجام اعمال لازم)
بازوی ربات، چرخها، پاها، …
قسمت تصمیم گیری (برنامه ای برای تعیین اعمال لازم):
حرکت در یک جهت خاص، دوری از موانع، برداشتن اجسام، …
قسمت کنترل (برای راه اندازی و بررسی حرکات روبات):
* نیروها و گشتاورهای موتورها برای سرعت مورد نظر، جهت مورد نظر، کنترل مسیر، …
مزایای ربات ها:
1- رباتیک و اتوماسیون در بسیاری از موارد می توانند ایمنی، میزان تولید، بهره و کیفیت محصولات را افزایش دهند.
2- رباتها می توانند در موقعیت های خطرناک کار کنند و با این کار جان هزاران انسان را نجات دهند.
3- رباتها به راحتی محیط اطراف خود توجه ندارند و نیازهای انسانی برای آنها مفهومی ندارد. رباتها هیچگاه خسته نمی شوند.
4- دقت رباتها خیلی بیشتر از انسانها است آنها در حد میلی یا حتی میکرو اینچ دقت دارند.
5- رباتها می توانند در یک لحظه چند کار را با هم انجام دهند ولی انسانها در یک لحظه تنها یک کار انجام می دهند.
معایب ربات ها:
1- رباتها در موقعیتهای اضطراری توانایی پاسخگویی مناسب ندارند که این مطلب می تواند بسیار خطرناک باشد.
2- رباتها هزینه بر هستند.
3- قابلیت های محدود دارند یعنی فقط کاری که برای آن ساخته شده اند را انجام می دهند.
برای مثال امروزه برای بررسی وضعیت داخلی رآکتورها از ربات استفاده می شود تا تشعشعات رادیواکتیو به انسانها صدمه نزند.
تأثیر رباتیک در جامعه:
علم رباتیک در اصل در صنعت بهکار میرود و ما تأثیر آن را در محصولاتی که هر روزه استفاده میکنیم، میبینیم. که این تأثیرات معمولاً در محصولات ارزانتر دیده میشود.
رباتها معمولاً در مواردی استفاده میشوند که بتوانند کاری را بهتر از یک انسان انجام دهند یا در محیط پر خط فعالیت نمایند مثل اکتشافات در مکانهای خطرناک مانند آتشفشانها که میتوان بدون به خطر انداختن انسانها انجام داد.
مشکلات رباتیک:
البته مشکلاتی هم هست. یک ربات مانند هر ماشین دیگری، میتواند بشکند یا به هر علتی خراب شود. ضمناً آنها ماشینهای قدرتمندی هستند که به ما اجازه میدهند کارهای معینی را کنترل کنیم.
خوشبختانه خرابی رباتها بسیار نادر است زیرا سیستم رباتیک با مشخصههای امنیتی زیادی طراحی میشود که میتواند آسیب آنها را محدود کند.
در این حوزه نیز مشکلاتی در رابطه با انسانهای شرور و استفاده از رباتها برای مقاصد شیطانی داریم. مطمئناً رباتها میتوانند در جنگهای آینده استفاده شوند. این میتواند هم خوب و هم بد باشد. اگر انسانها اعمال خشونت آمیز را با فرستادن ماشینها به جنگ یکدیگر نمایش دهند، ممکن است بهتر از فرستادن انسانها به جنگ با یکدیگر باشد. رباتها میتوانند برای دفاع از یک کشور در مقابل حملات استفاده میشوند تا تلفات انسانی را کاهش دهد. آیا جنگهای آینده میتواند فقط یک بازی ویدئویی باشد که رباتها را کنترل میکند؟
مزایای رباتیک:
مزایا کاملاً آشکار است. معمولاً یک ربات میتواند کارهایی که ما انسانها میخواهیم انجام دهیم را ارزانتر انجام دهد. علاوه بر این رباتها میتوانند کارهای خطرناک مانند نظارت بر تأسیسات انرژی هستهای یا کاوش یک آتشفشان را انجام دهند. رباتها میتوانند کارها را دقیقتر از انسانها انجام دهند و روند پیشرفت در علم پزشکی و سایر علوم کاربردی را سرعت بخشند. رباتها به ویژه در امور تکراری و خسته کننده مانند ساختن صفحه مدار، ریختن چسب روی قطعات یدکی و… سودمند هستند.
تاثیرات شغلی:
بسیاری از مردم از اینکه رباتها تعداد شغلها را کاهش دهد و افراد زیادی شغل خود را از دست دهند، نگرانند. این تقریباً هرگز قضیهای بر خلاف تکنولوژی جدید نیست. در حقیقت اثر پیشرفت تکنولوژی مانند رباتها (اتومبیل و دستگاه کپی و…) بر جوامع ، آن است که انسان بهرهورتر میشود.
آینده رباتیک:
جمعیت رباتها به سرعت در حال افزایش است. این رشد توسط ژاپنیها که رباتهای آنها تقریباً دو برابر تعداد رباتهای آمریکا است، هدایت شده است.
همه ارزیابیها بر این نکته تأکید دارد که رباتها نقش فزایندهای در جوامع مدرن ایفا خواهند کرد. آن ها به انجام کارهای خطرناک، تکراری، پر هزینه و دقیق ادامه میدهند تا انسانها را از انجام آنها باز دارند.
ربات چیست؟ قسمت 1
ربات چیست؟ قسمت 2
ربات چیست؟ قسمت 3
ربات چیست؟ قسمت 4
ربات چیست؟ قسمت 5
ربات چیست؟ قسمت 6
ربات چیست؟ قسمت 7
ربات چیست؟ قسمت 8


























![{\displaystyle [1,\cdots ,d]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1f0cb2b735303a718bd517e38e758ac6d49ef6a9)












![{\displaystyle y_{i}\in [1,\cdots ,K]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7be8cb4ab377a7ad30972f691d5c72247d873131)